1 前后端分离
2 使用docker准备数据库
00.介绍
docker优势:通过命令可以实现各种服务的部署功能
docker基于linux:一般建议centos7,centos6不稳定
docker要求centos7内核版本>=3.10,查看系统内核#uname -r
01.准备docker容器
a.下载docker
yum -y install docker
b.启动
systemctl start docker
c.开启自启
systemctl enable docker
02.在docker容器中安装各个服务镜像
a.下载mysql镜像
docker pull 镜像名字:版本号
docker pull mysql:5.5.61d
docker pull registry.docker-cn.com/mysql:5.5.61
docker pull daocloud.io/library/mysql:5.5.61
b.安装mysql镜像
docker run -di --name=micro_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=4023615 daocloud.io/library/mysql:5.5.61
c.检查安装的镜像
docker ps -a
d.命令mysql
docker start 80576e5ea74a --启动
docker stop 80576e5ea74a --停止
docker restart 80576e5ea74a --重启
docker rm 80576e5ea74a --卸载
e.进入容器bash
docker exec -it micro_mysql bash
3 SpringBoot整合SSM / SSS
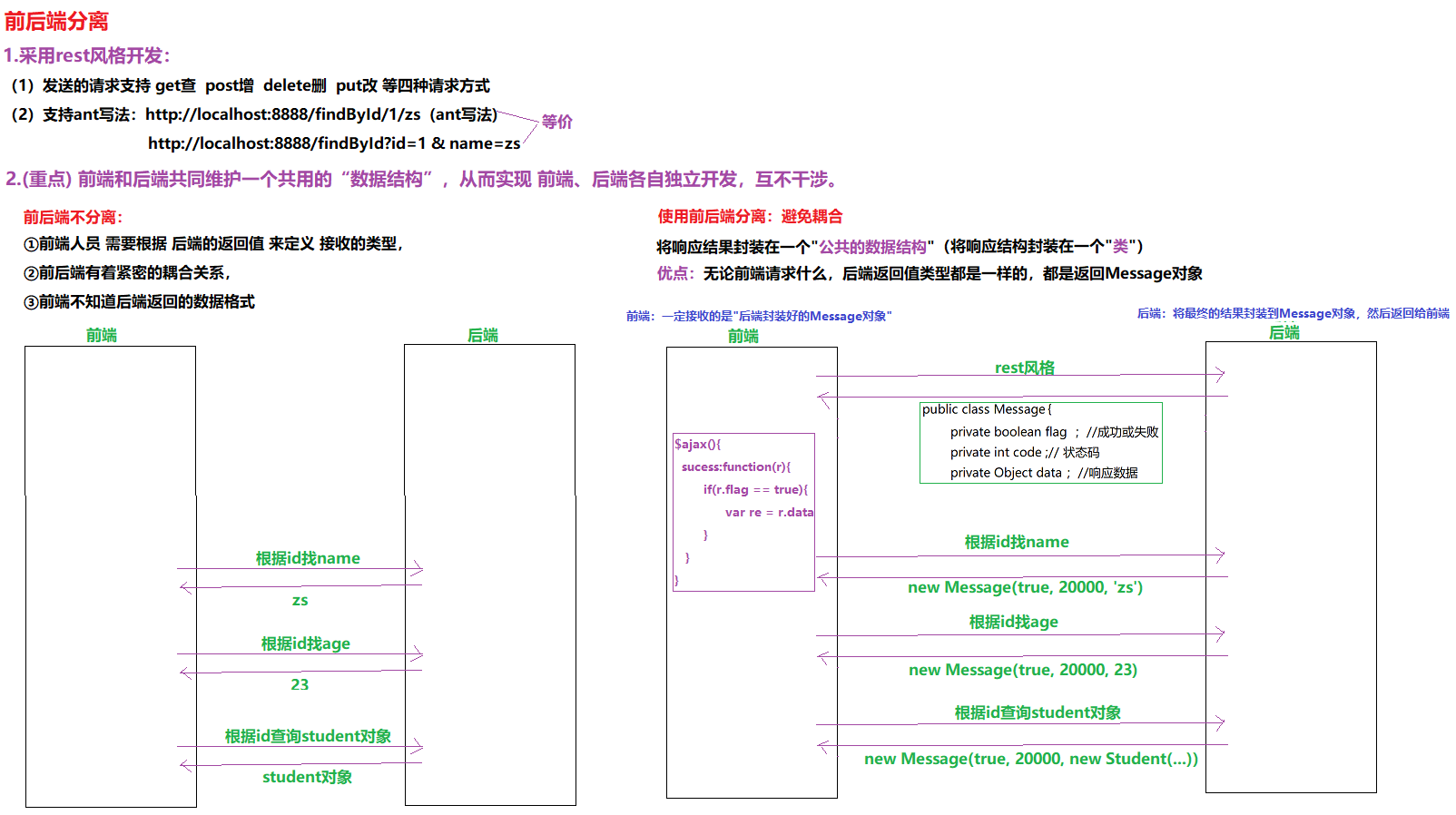
3.1 micro_city:springboot+ssm+注解
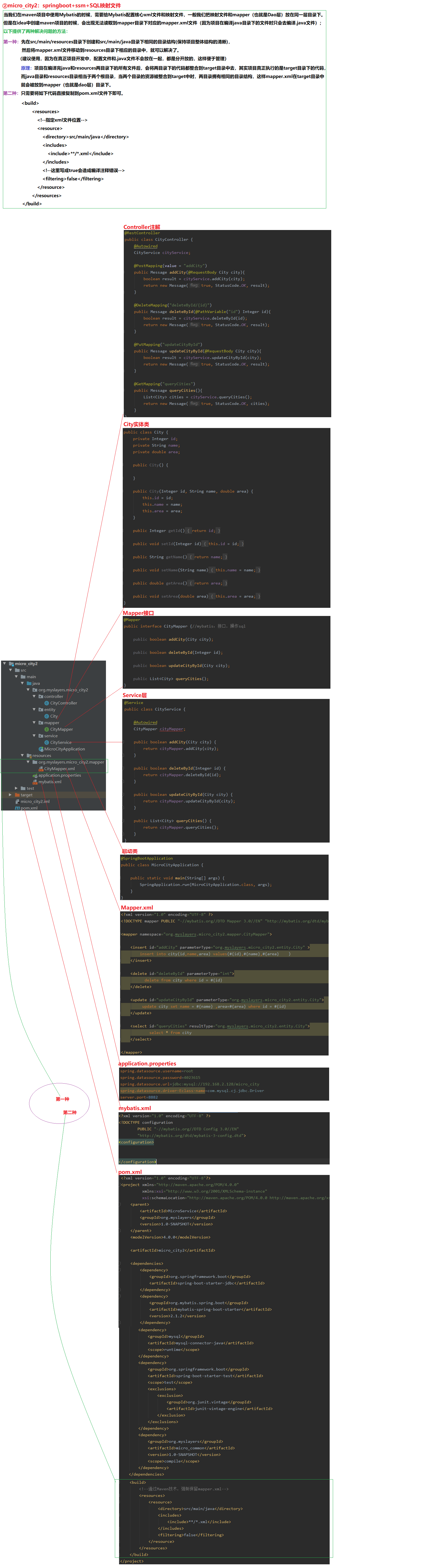
3.2 micro_city2:springboot+ssm+SQL映射文件
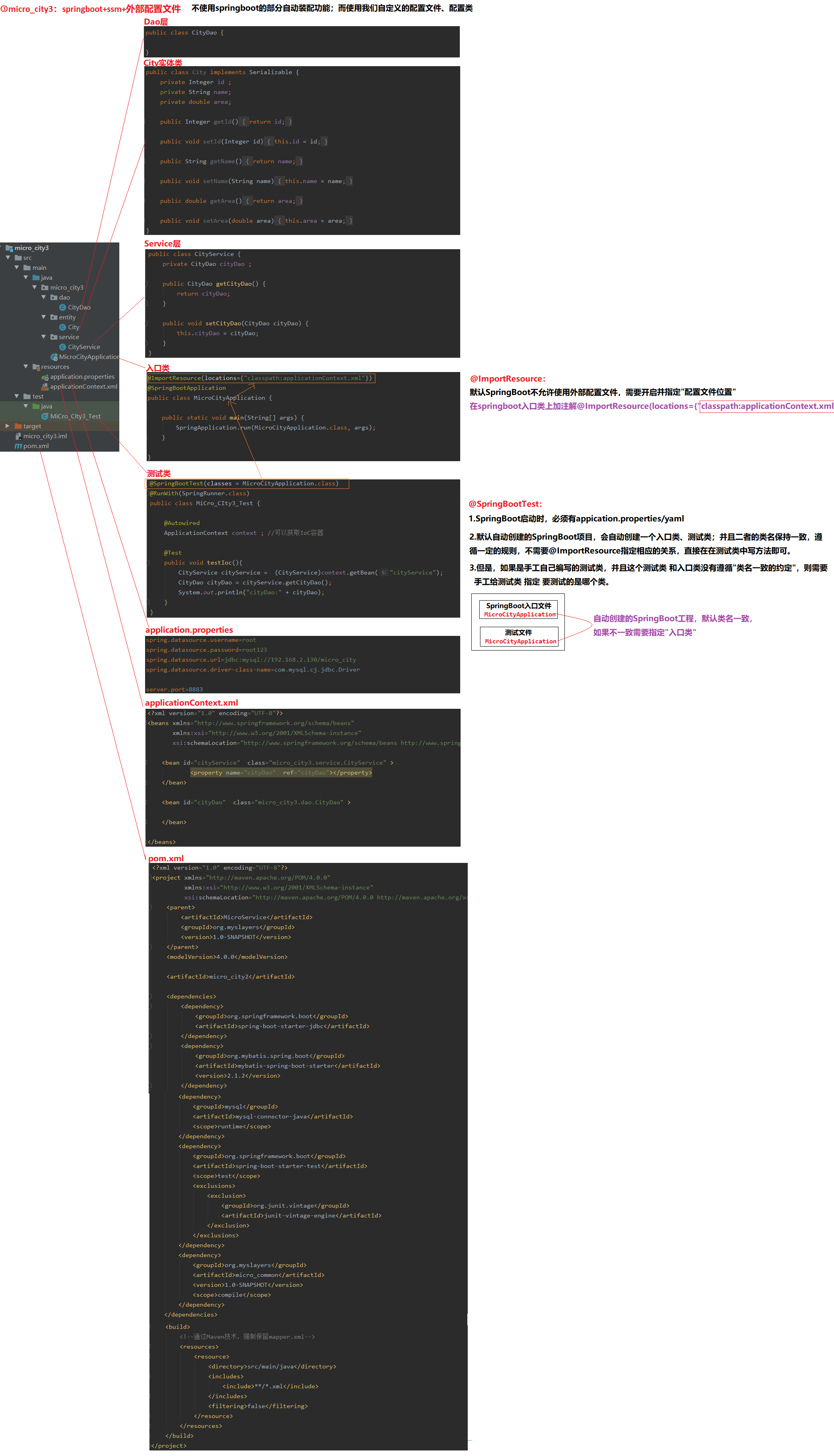
3.3 micro_city3:springboot+ssm+外部配置文件
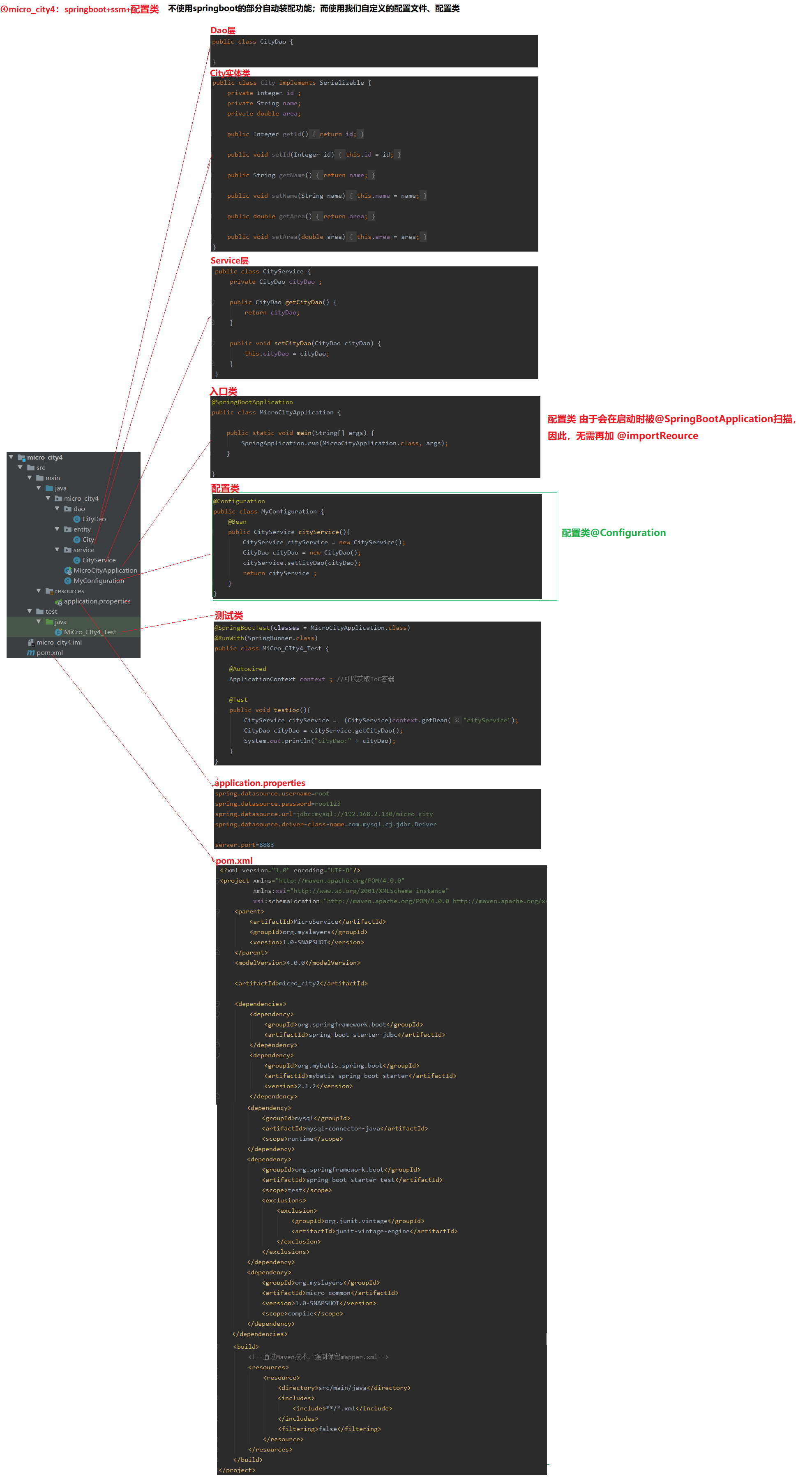
3.4 micro_city4:springboot+ssm+配置类
3.5 micro_person:springboot+ss(springdata+jpa)
4 SpringBoot整合HttpClient
4.1 单体框架HttpClient
4.2 SpringBoot整合HttpClient
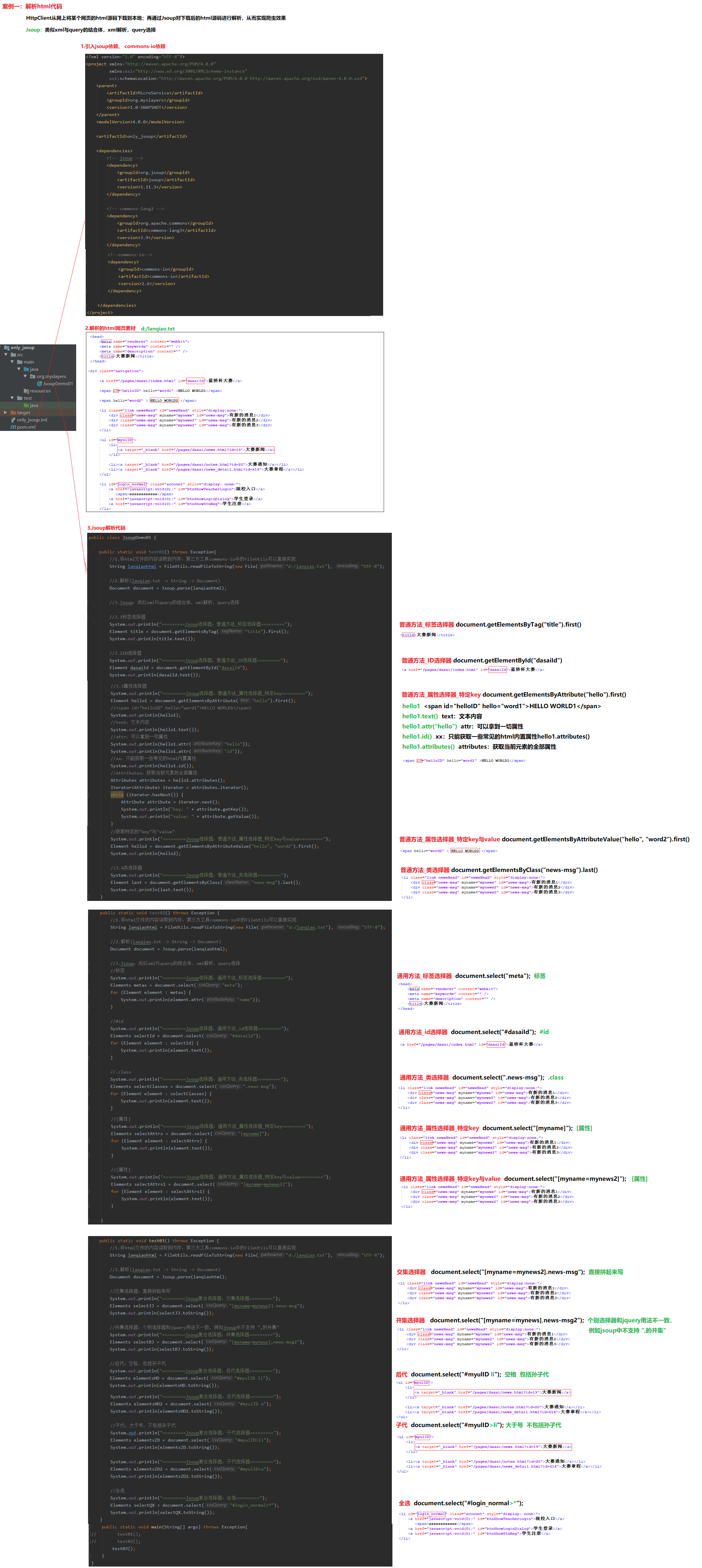
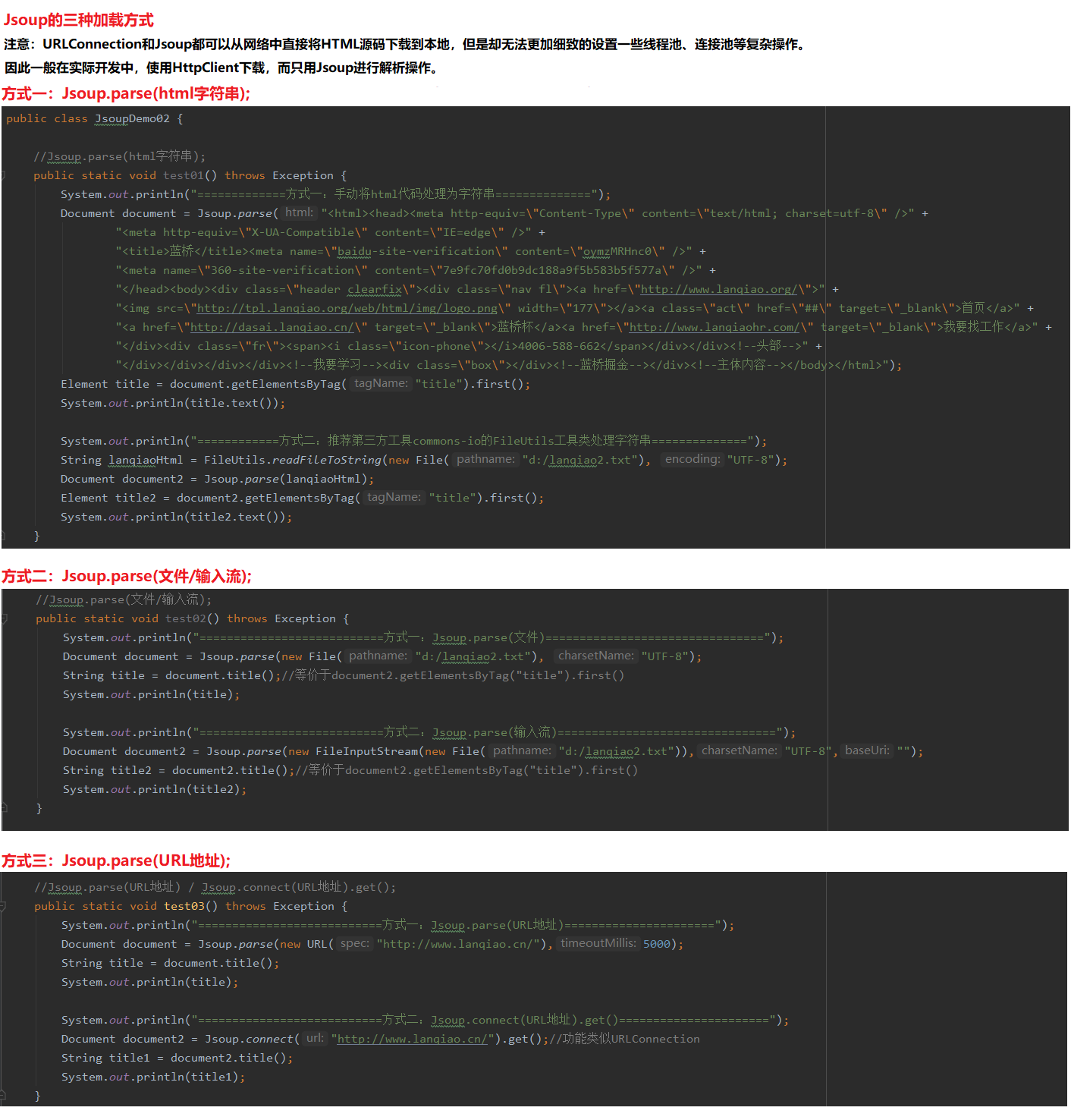
5 Jsoup解析html代码
5.1 普通、通用、复合选择器
5.2 Jsoup三种加载方式
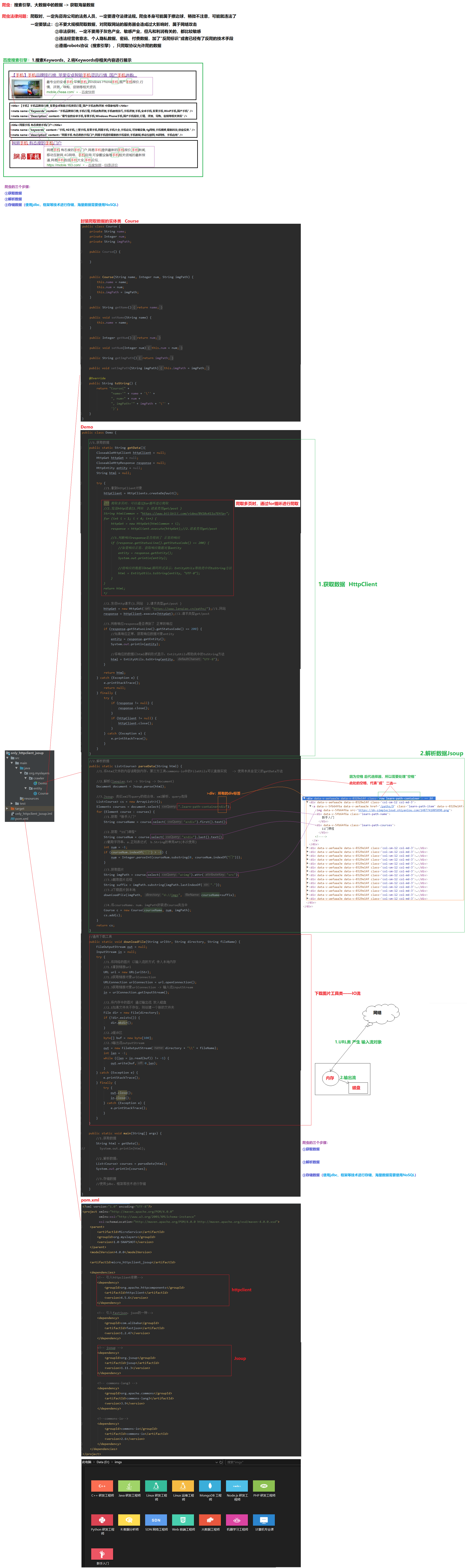
6 爬虫案例
6.1 爬虫=HttpClient+Jsoup
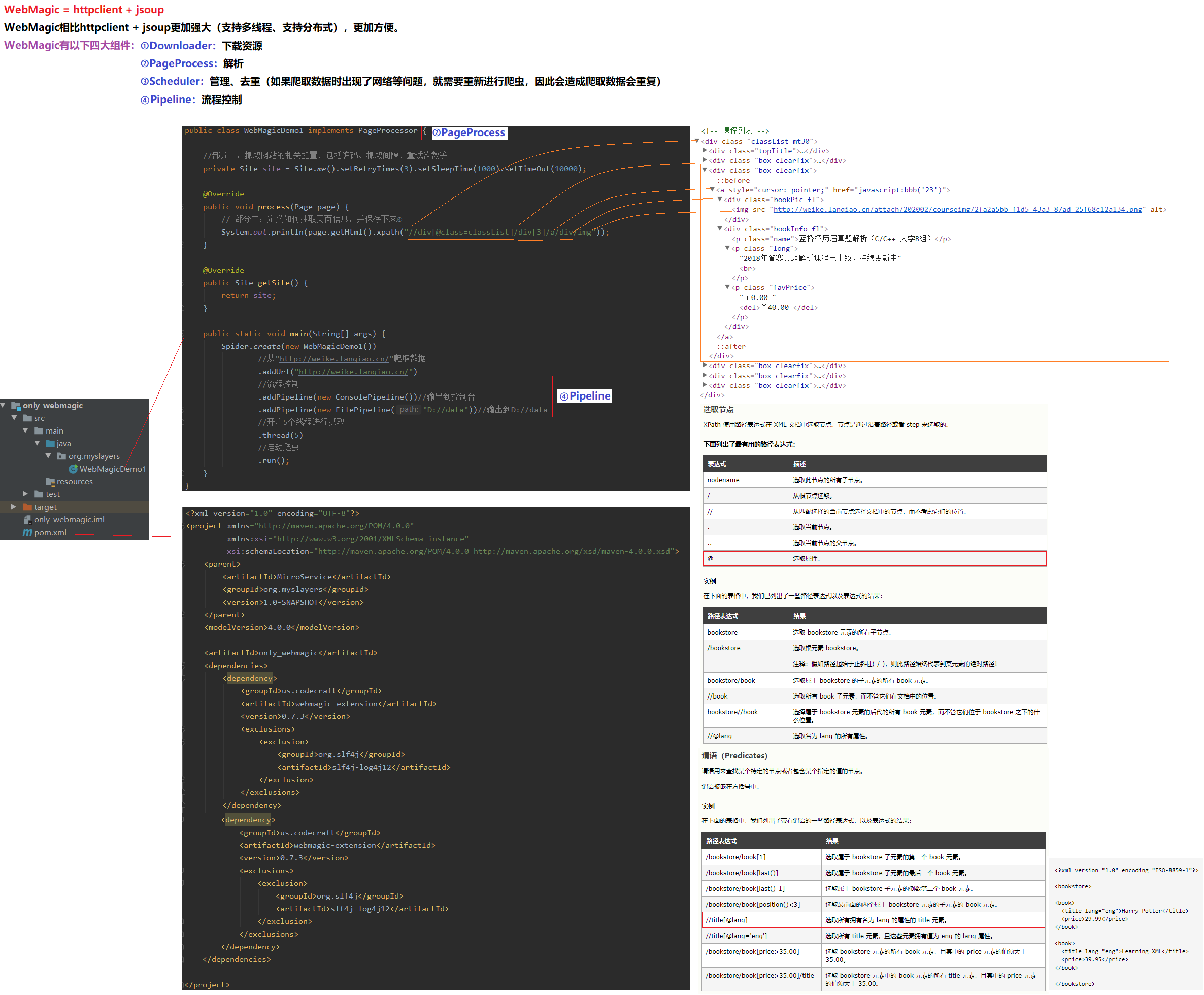
6.2 WebMagic爬虫框架
7 Redis数据库
7.1 redis环境搭建
01.打开目录、下载、解压、重命名
a.打开目录
cd /usr
b.下载
wget http://download.redis.io/releases/redis-6.0.1.tar.gz
c.解压
tar -zxvf redis-6.0.1.tar.gz
d.重命名
mv redis-6.0.1 redis
02.配置文件前需要编译
a.打开目录
cd redis/
b.编译
make
c.编译make后,如果报错/bin/sh: cc: command not found
yum install gcc-c++
d.安装c++后,如果报错error: jemalloc/jemalloc.h: No such file or directory
make MALLOC=libc
e.再次尝试后,如果报错‘struct redisServer’ has no member named ‘cached_master’
可能gcc(4.8.5)与redis(4.x)版本冲突
f.升级gcc
gcc -v
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
g.再次尝试
make MALLOC=libc
03.配置redis.conf
daemonize yes
04.测试
a.打开目录
cd /usr/redis
b.启动服务端,默认端口6379
src/redis-server redis.conf
c.启动客户端连接服务端
src/redis-cli -p 6379
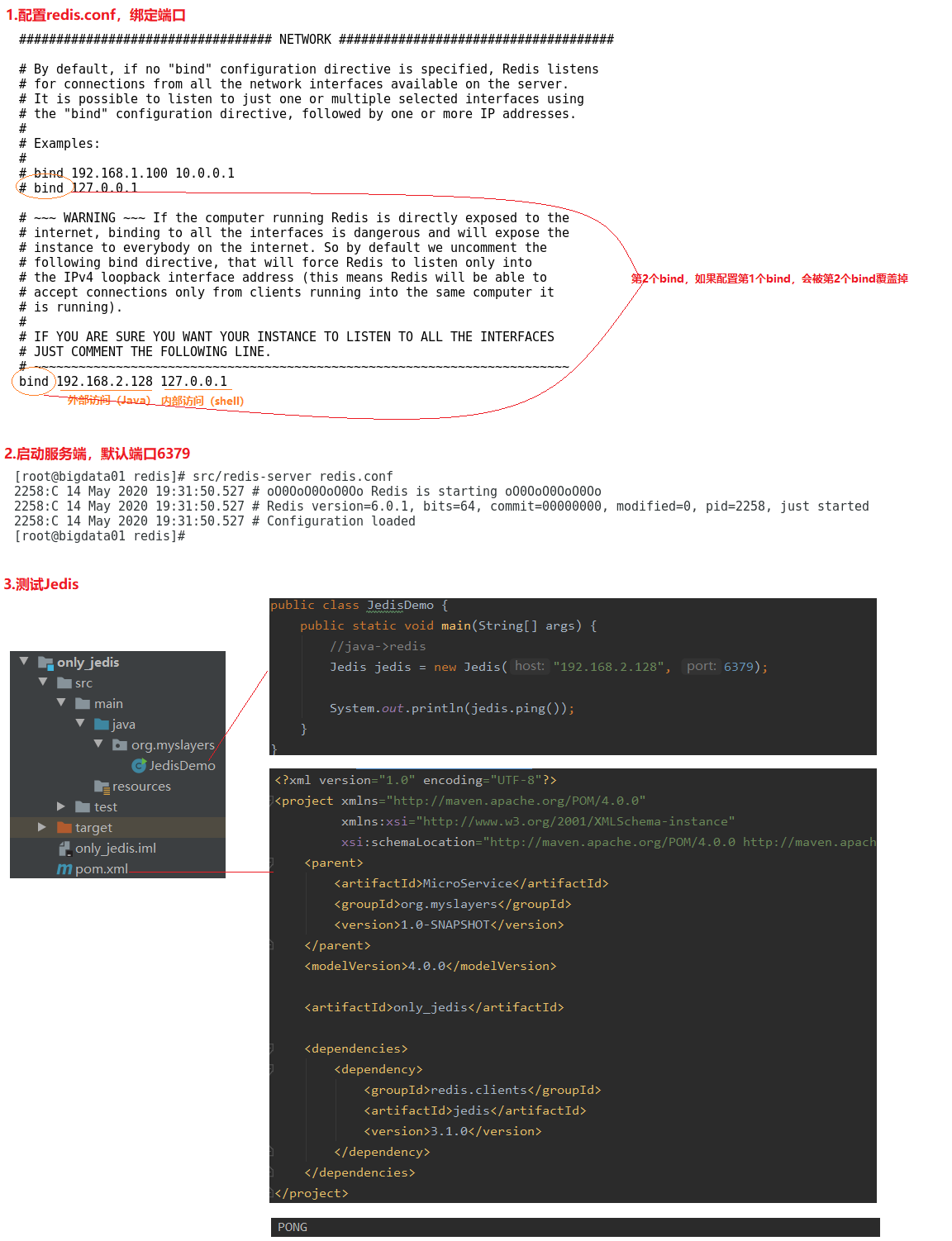
7.2 Jedis环境搭建
01.配置redis.conf,绑定端口
bind 192.168.2.128 127.0.0.1
02.启动服务端,默认端口6379
src/redis-server redis.conf
03.测试Jedis
a.引入jedis依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
b.测试代码
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.2.128", 6379);
System.out.println(jedis.ping());
}
7.3 Redis数据库
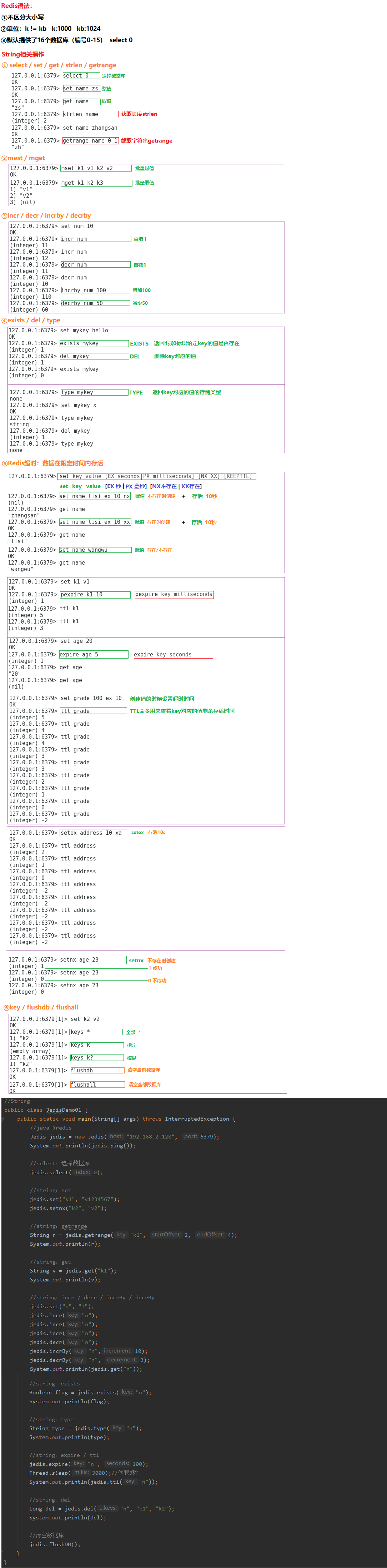
7.3.1 字符串Strings
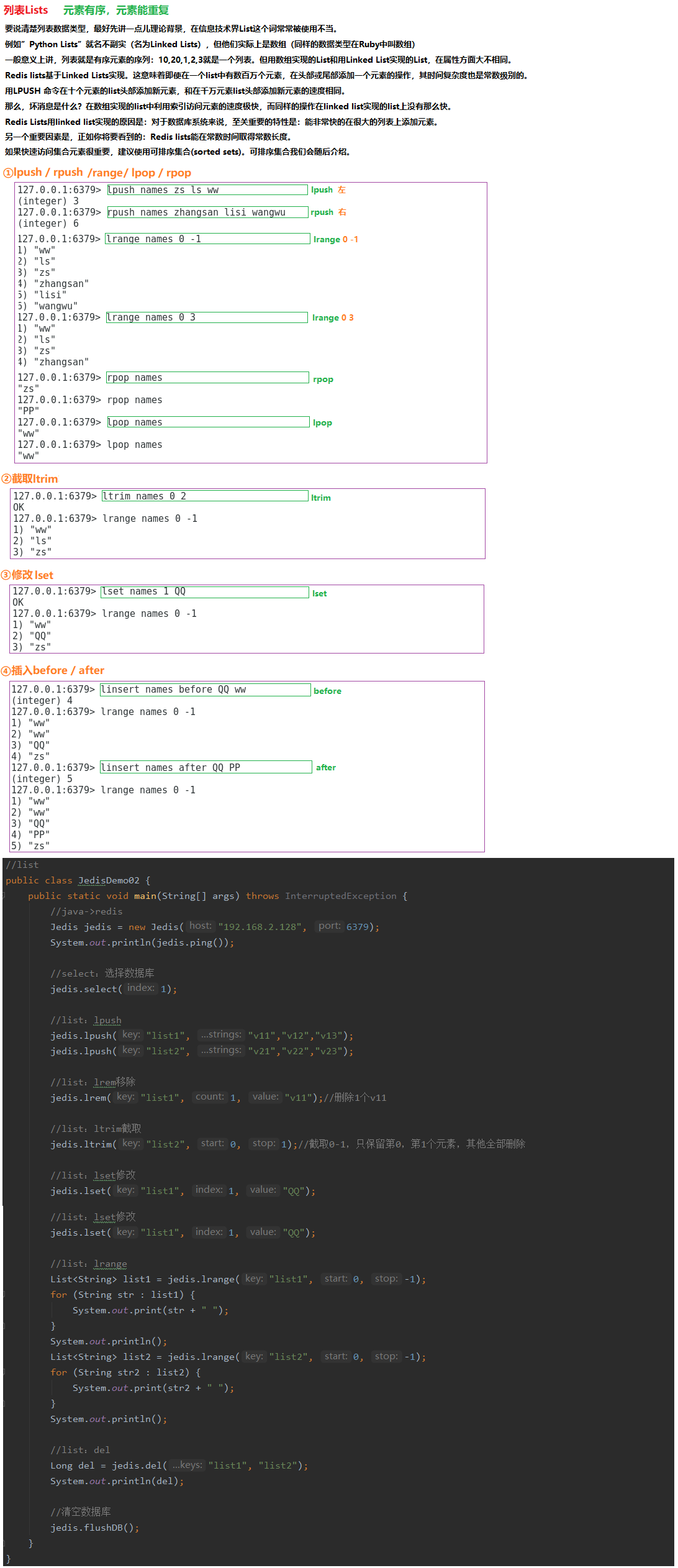
7.3.2 列表Lists
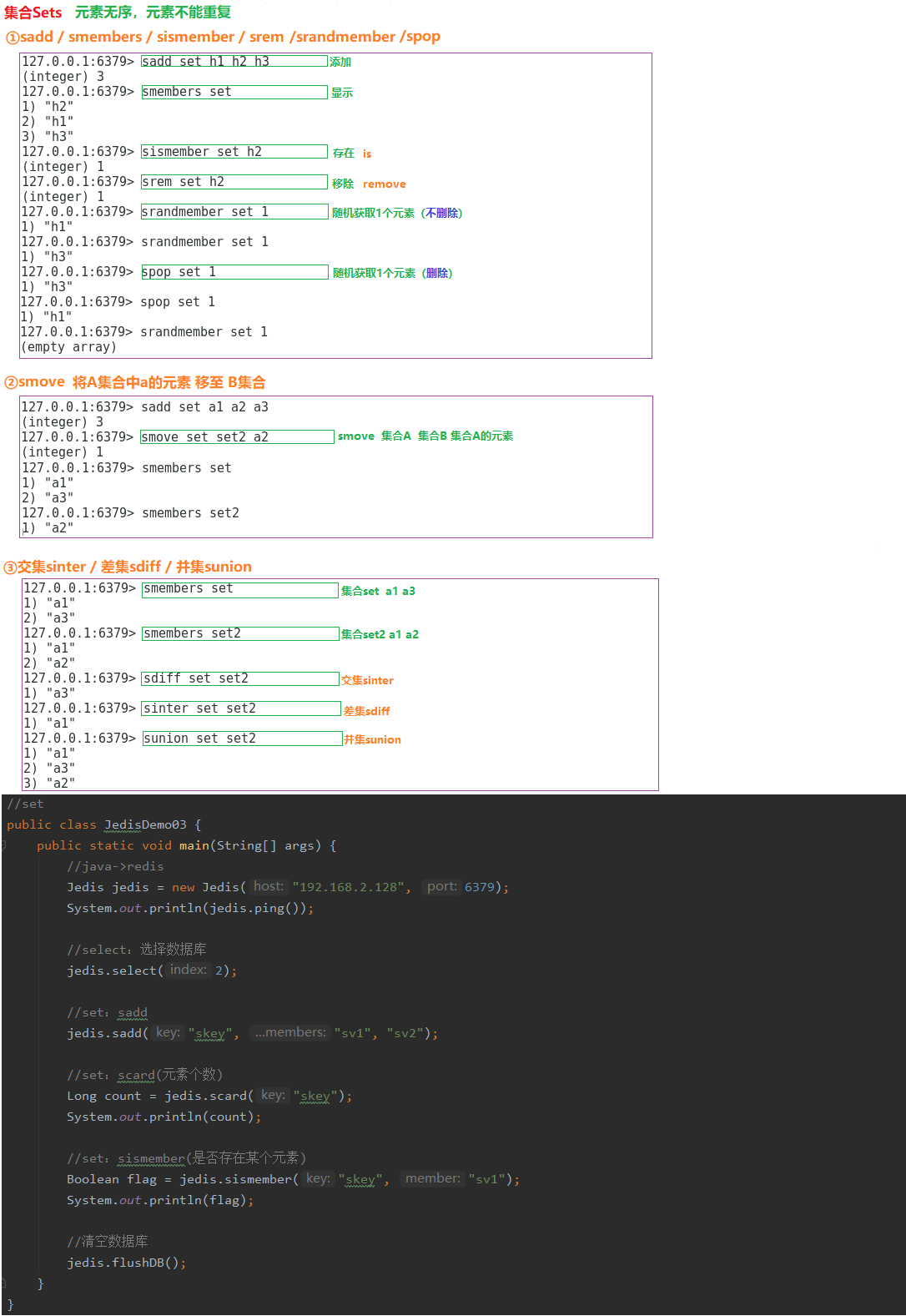
7.3.3 集合Sets
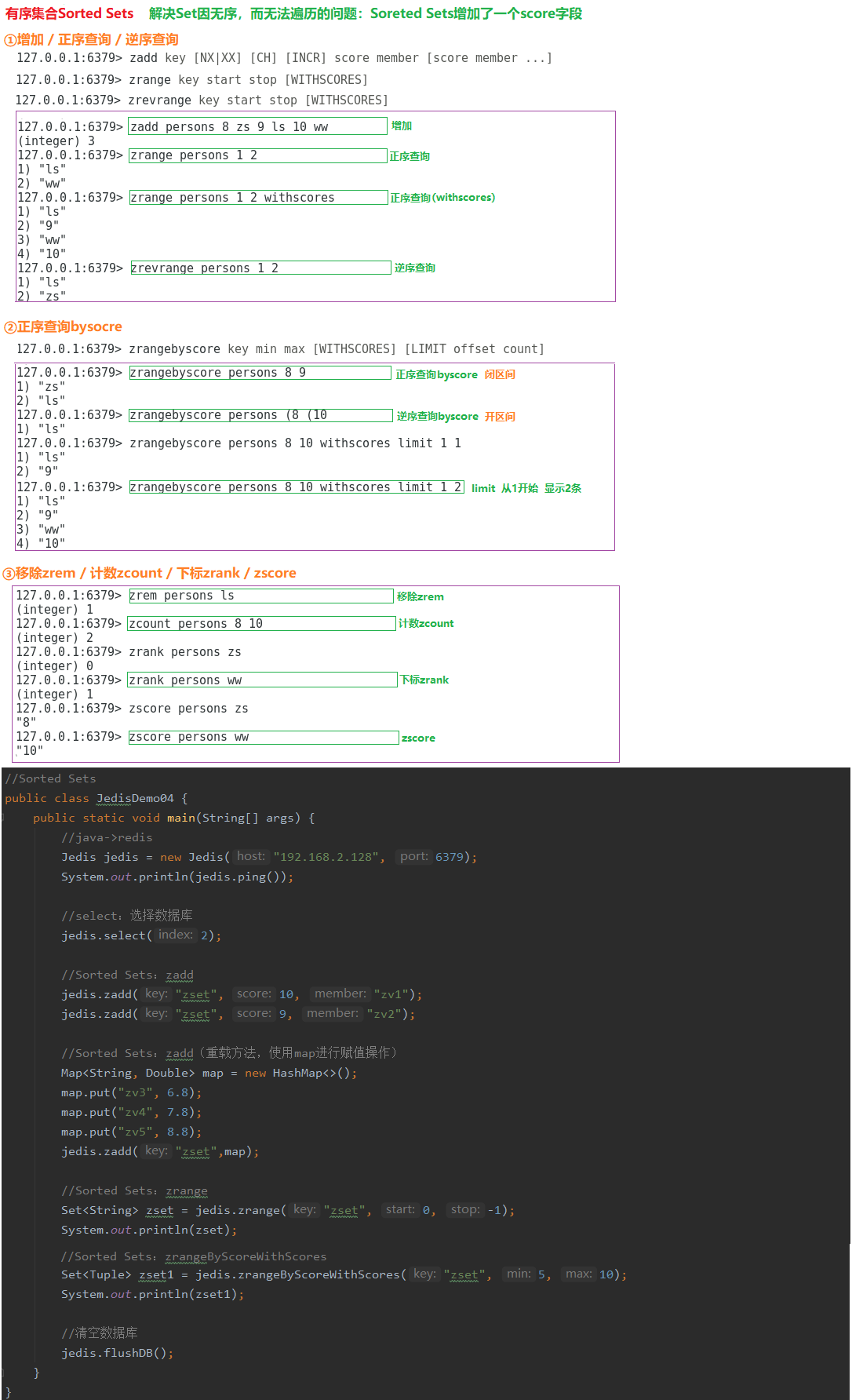
7.3.4 有序集合Sorted Sets
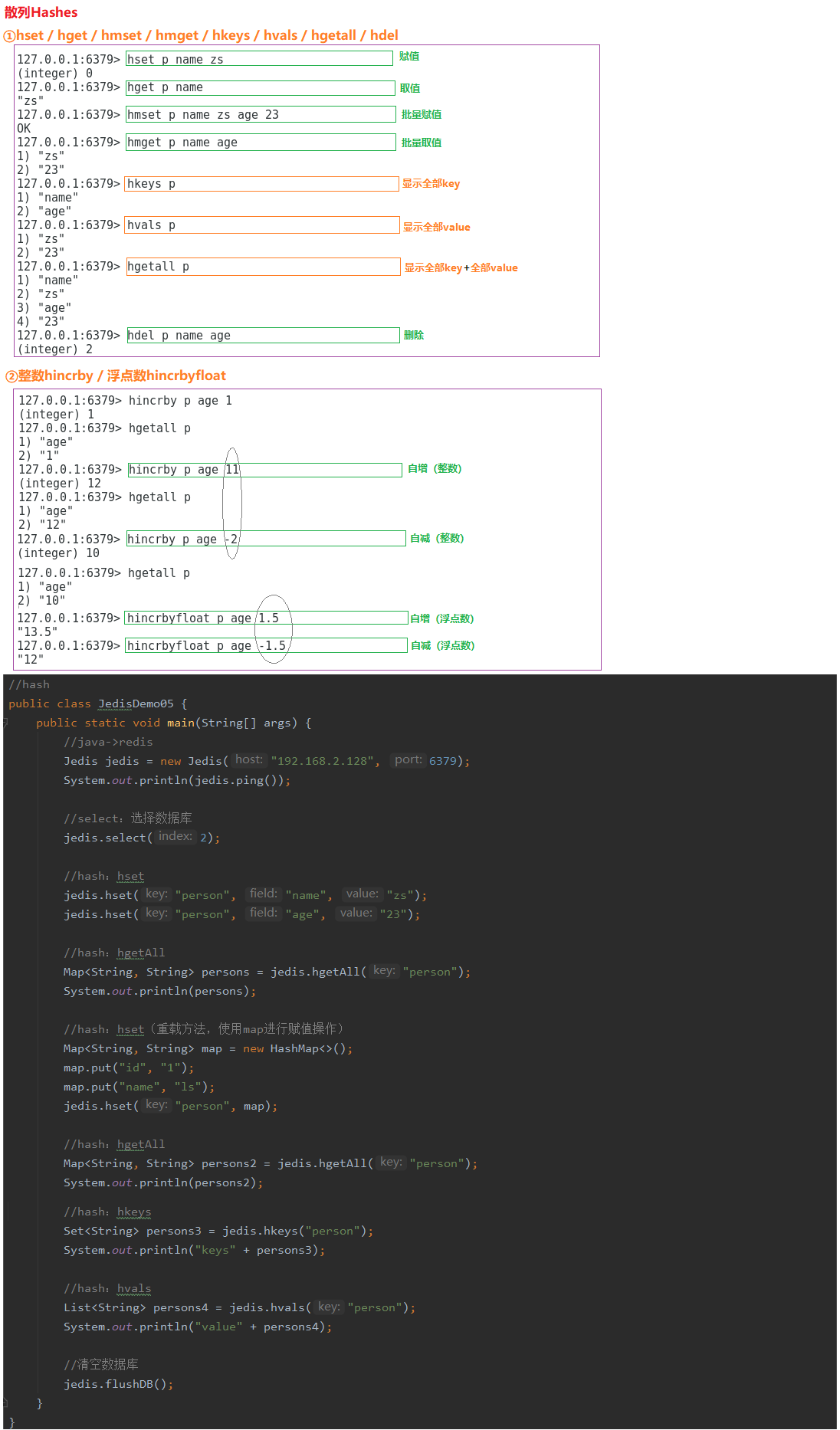
7.3.5 散列Hashes
7.4 Redis存储/读取爬虫数据
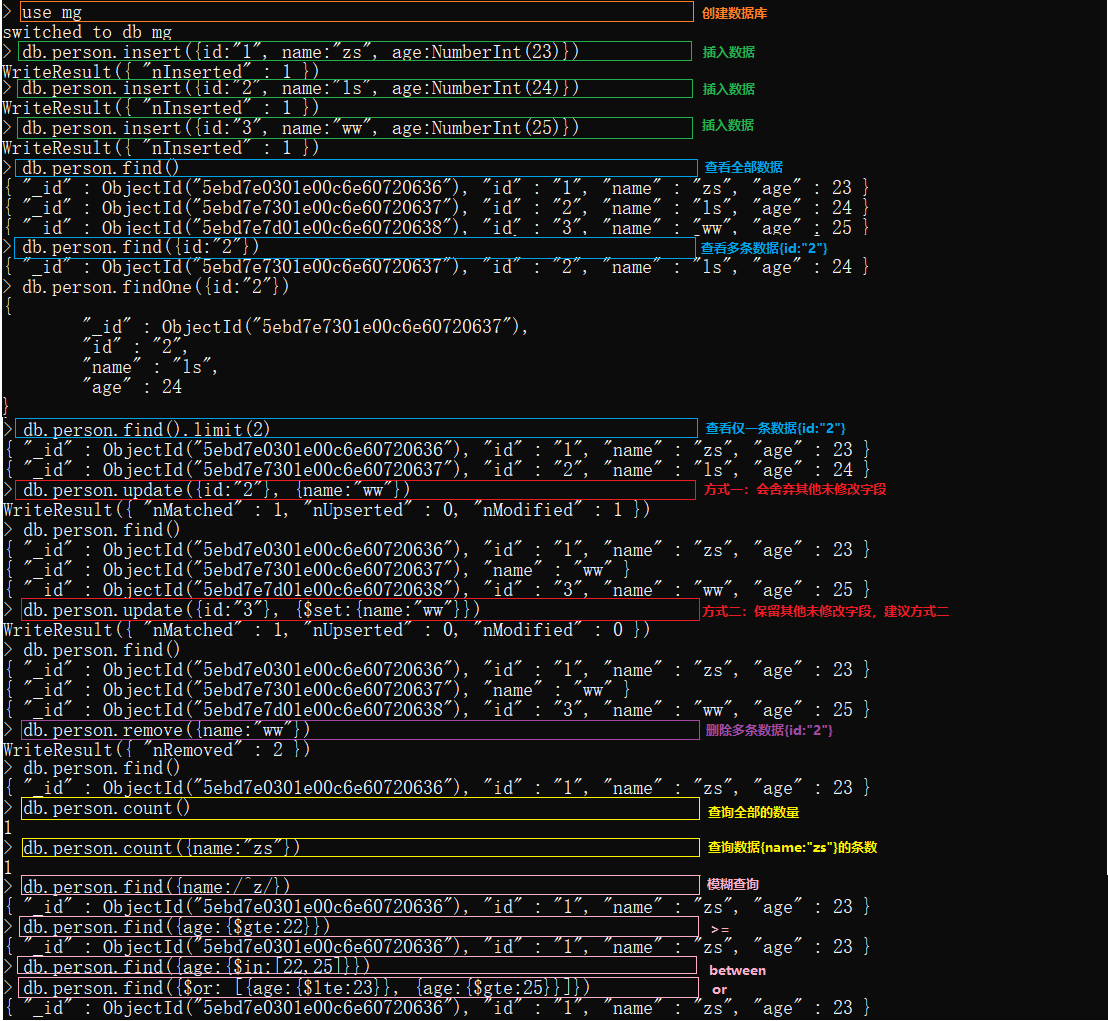
8 MongoDB数据库
8.1 MongoDB环境搭建
8.2 MongoDB数据库
8.3 MongoDB存储/读取爬虫数据
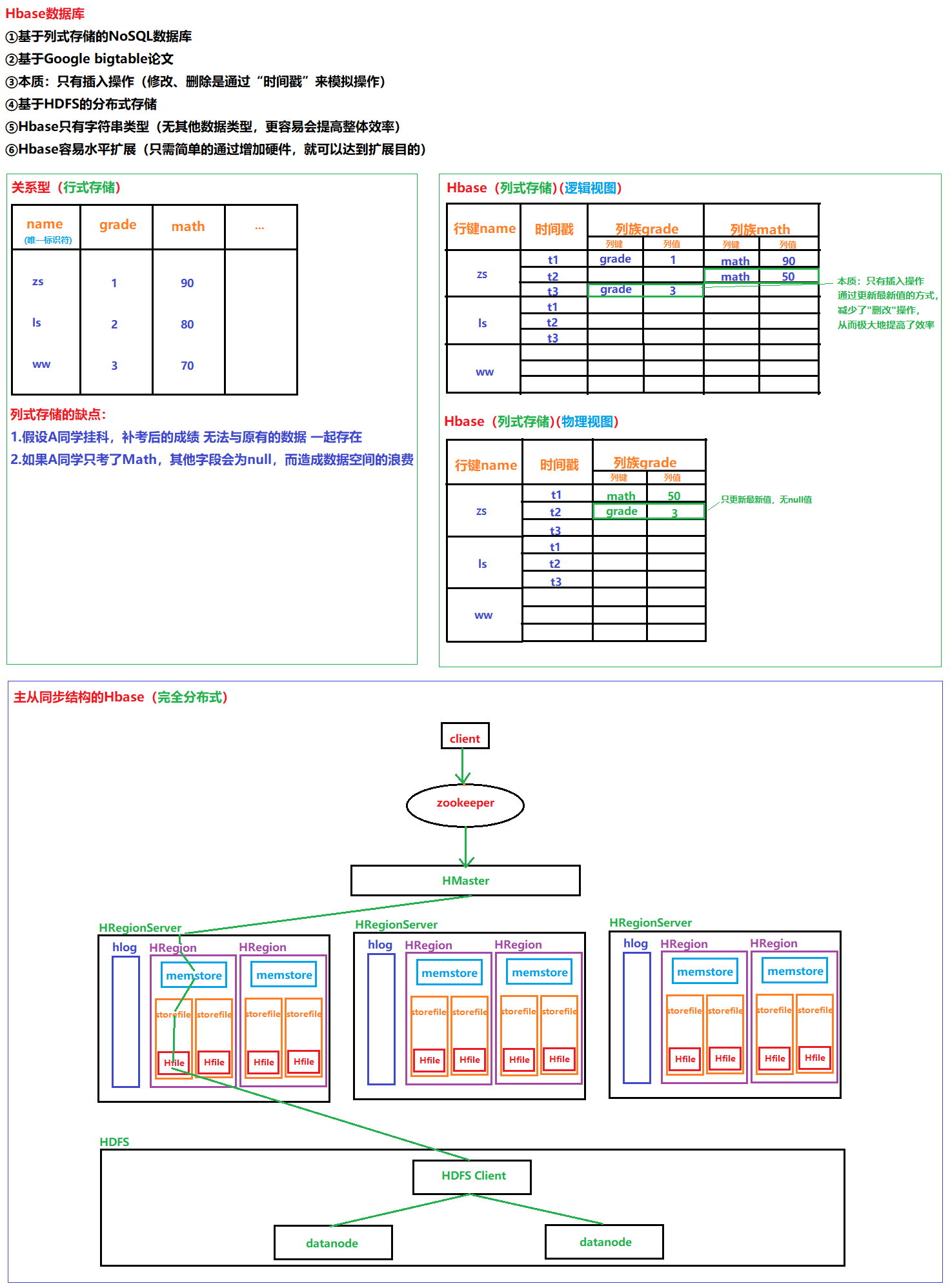
9 Hbase数据库
9.1 Hbase架构设计
9.2 Hbase环境搭建
9.2.1 MapReduce完全分布式
01.安装hadoop
a.上传、解压、重命名
cd /usr/local
tar -zxvf hadoop-2.9.2.tar.gz
mv hadoop-2.9.2 hadoop292
b.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
c.刷新环境变量
source /etc/profile
02.配置hadoop /usr/local/hadoop292/etc/hadoop,共7个
1.slaves:配置从节点
bigdata02
bigdata03
2.hadoop-env.sh:追加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
3.yarn-env.sh:追加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
4.core-site.xml
<configuration>
<!--hdfs -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop292/temp</value>
</property>
</configuration>
5.hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop292/temp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop292/temp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
6.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata01:19888</value>
</property>
</configuration>
7.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bigdata01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bigdata01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bigdata01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata01:8088</value>
</property>
</configuration>
01.bigdata01
cd /usr/local
scp -r hadoop292/ root@bigdata02:/usr/local/
scp -r hadoop292/ root@bigdata03:/usr/local/
02.bigdata02
a.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
b.刷新环境变量
source /etc/profile
03.bigdata03
a.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
b.刷新环境变量
source /etc/profile
01.第一次使用,bigdata01格式化hdfs
a.打开目录
cd /usr/local/hadoop292
b.只格式化bigdata01
bin/hdfs namenode -format
c.重启
reboot
02.主节点启动hadoop
a.打开目录
cd /usr/local/hadoop292
b.启动hadoop
sbin/start-dfs.sh --启动Hdfs
sbin/start-yarn.sh --启动MapReduce
03.测试是否启动成功
a.jps
bigdata01:NameNode(hdfs主节点) 、 SecondaryNameNode(hdfs备份节点)
bigdata02:DataNode(hdfs从节点)
bigdata03:DataNode(hdfs从节点)
b.浏览器
http://192.168.2.128:50070/
c.通过命令查看状态
cd /usr/local/hadoop292
bin/hdfs dfsadmin -report
04.主节点关闭hadoop
a.打开目录
cd /usr/local/hadoop292
b.关闭hadoop
sbin/stop-dfs.sh --关闭Hdfs
sbin/stop-yarn.sh --关闭MapReduce
05.免密钥登陆
1.生成密钥
ssh-keygen -t rsa
2.发送私钥(本机)
ssh-copy-id localhost
3.发送公钥(其他计算机)
ssh-copy-id bigdata02
4.测试免密钥登陆
ssh bigdata02
06.防火墙
systemctl stop firewalld
systemctl disable firewalld
07.日志级别
export HADOOP_ROOT_LOGGER=DEBUG,console
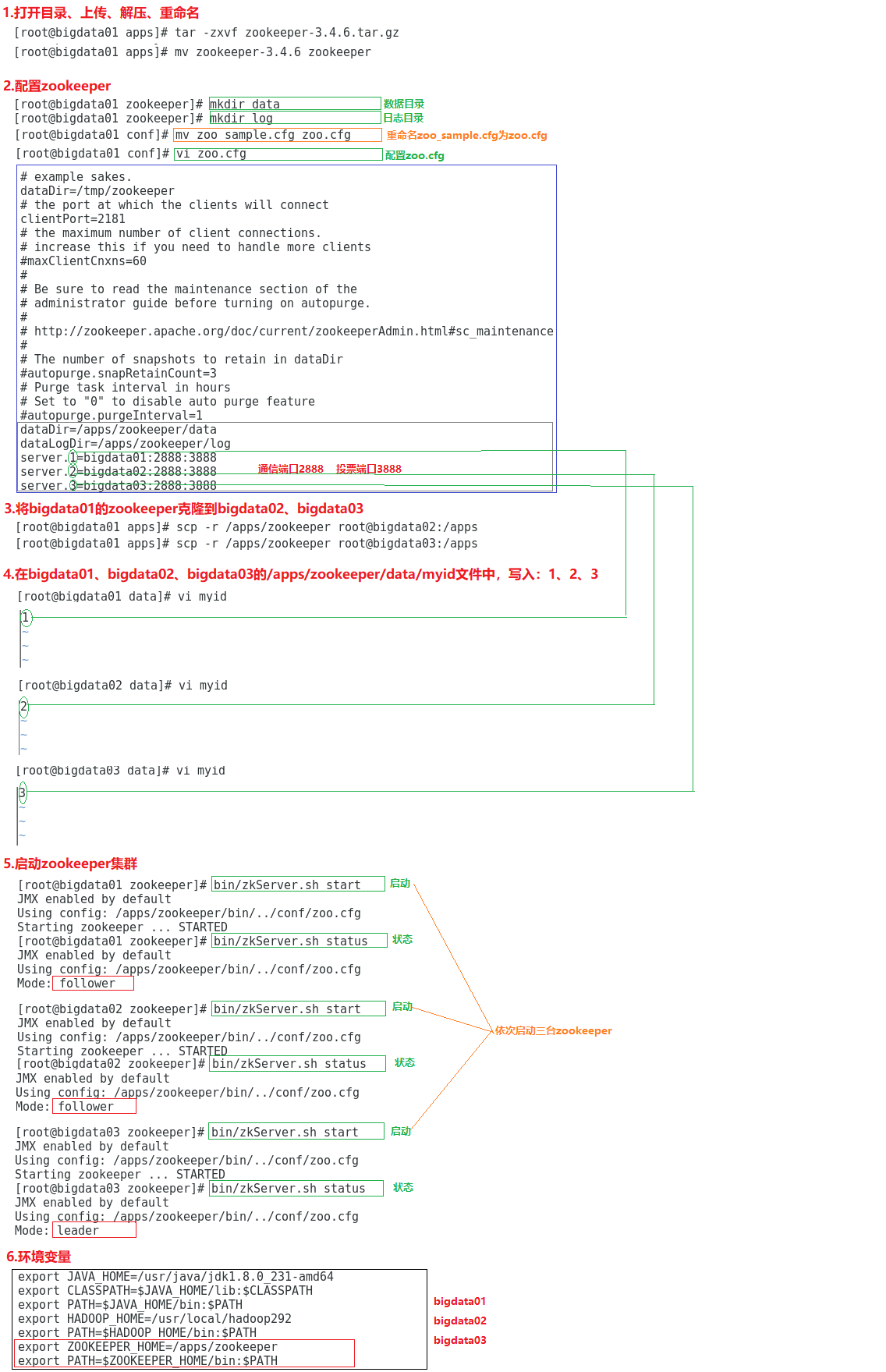
9.2.2 Zookeeper集群
01.打开目录、上传、解压、重命名
a.打开目录
cd /apps
b.解压
tar -zxvf zookeeper-3.4.6.tar.gz
d.重命名
mv zookeeper-3.4.6 zookeeper
02.配置zookeeper
a.打开目录
cd /apps/zookeeper
b.新建目录
mkdir data
mkdir log
c.打开目录
cd /apps/zookeeper/conf
d.配置zoo.cfg
mv zoo_sample.cfg zoo.cfg --重命名
dataDir=/apps/zookeeper/data
dataLogDir=/apps/zookeeper/log
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
03.将bigdata01的zookeeper克隆到bigdata02、bigdata03
scp -r /apps/zookeeper root@bigdata02:/apps
scp -r /apps/zookeeper root@bigdata03:/apps
04.在bigdata01、bigdata02、bigdata03的/apps/zookeeper/data/myid文件中,分别写入:1、2、3
a.打开目录
cd /apps/zookeeper/data
b.新建myid
vi myid
1
2
3
05.启动zookeeper集群
a.打开目录
cd /apps/zookeeper/
b.启动
bin/zkServer.sh start --启动
bin/zkServer.sh status --状态
bin/zkServer.sh stop --停止
06.环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/apps/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
07.防火墙
systemctl stop firewalld
systemctl disable firewalld
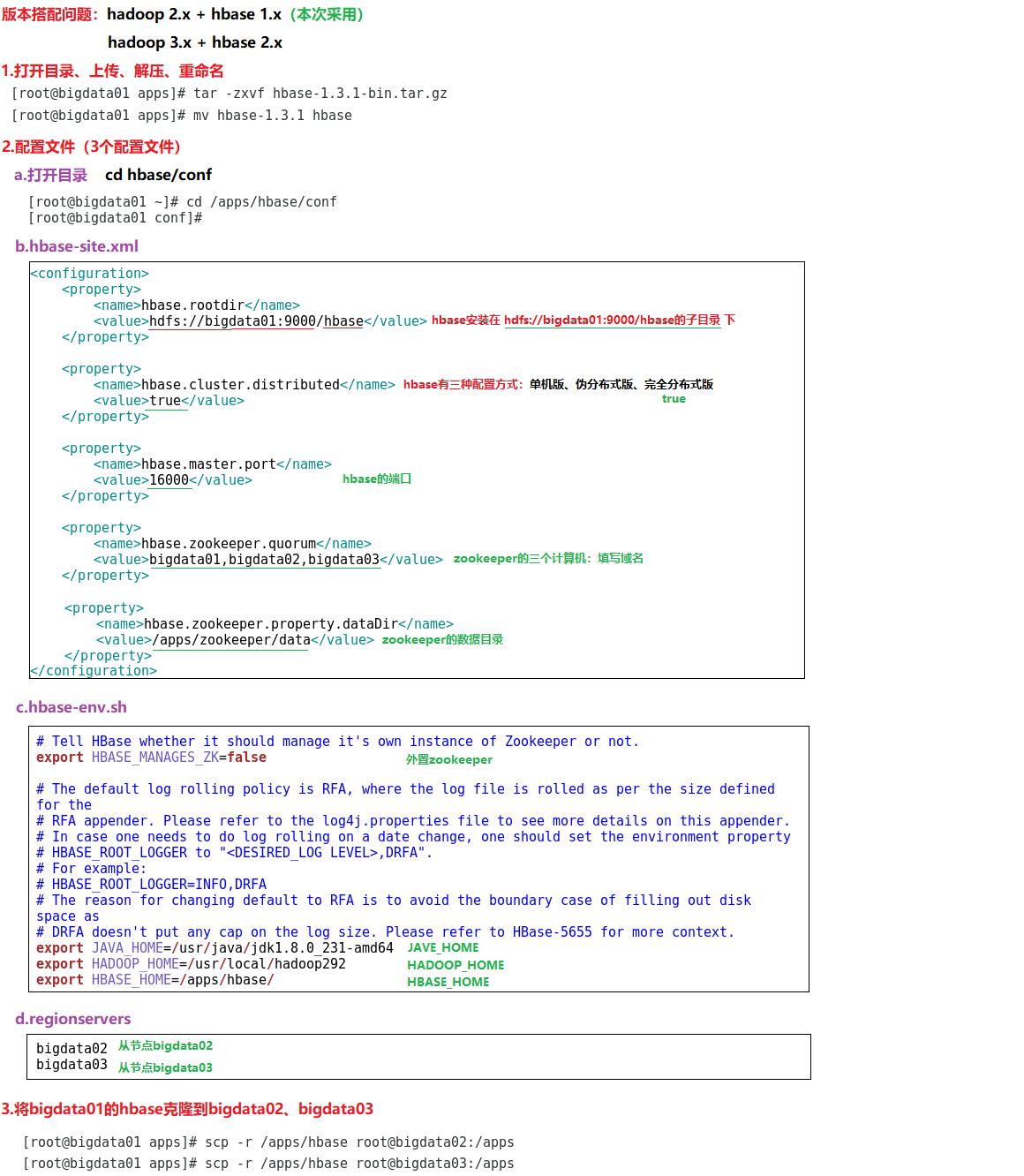
9.2.3 Hbase完全分布式
01.打开目录、上传、解压、重命名
a.打开目录
cd /apps
b.解压
tar -zxvf hbase-1.3.1-bin.tar.gz
d.重命名
mv hbase-1.3.1 hbase
02.配置文件(3个配置文件)
a.打开目录
cd /apps/hbase/conf
b.hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://bigdata01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata01,bigdata02,bigdata03</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/apps/zookeeper/data</value>
</property>
</configuration>
c.hbase-env.sh
export HBASE_MANAGES_ZK=false --外置zookeeper
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
export HADOOP_HOME=/usr/local/hadoop292
export HBASE_HOME=/apps/hbase/
d.regionservers
bigdata02
bigdata03
03.将bigdata01的hbase克隆到bigdata02、bigdata03
scp -r /apps/hbase root@bigdata02:/apps
scp -r /apps/hbase root@bigdata03:/apps
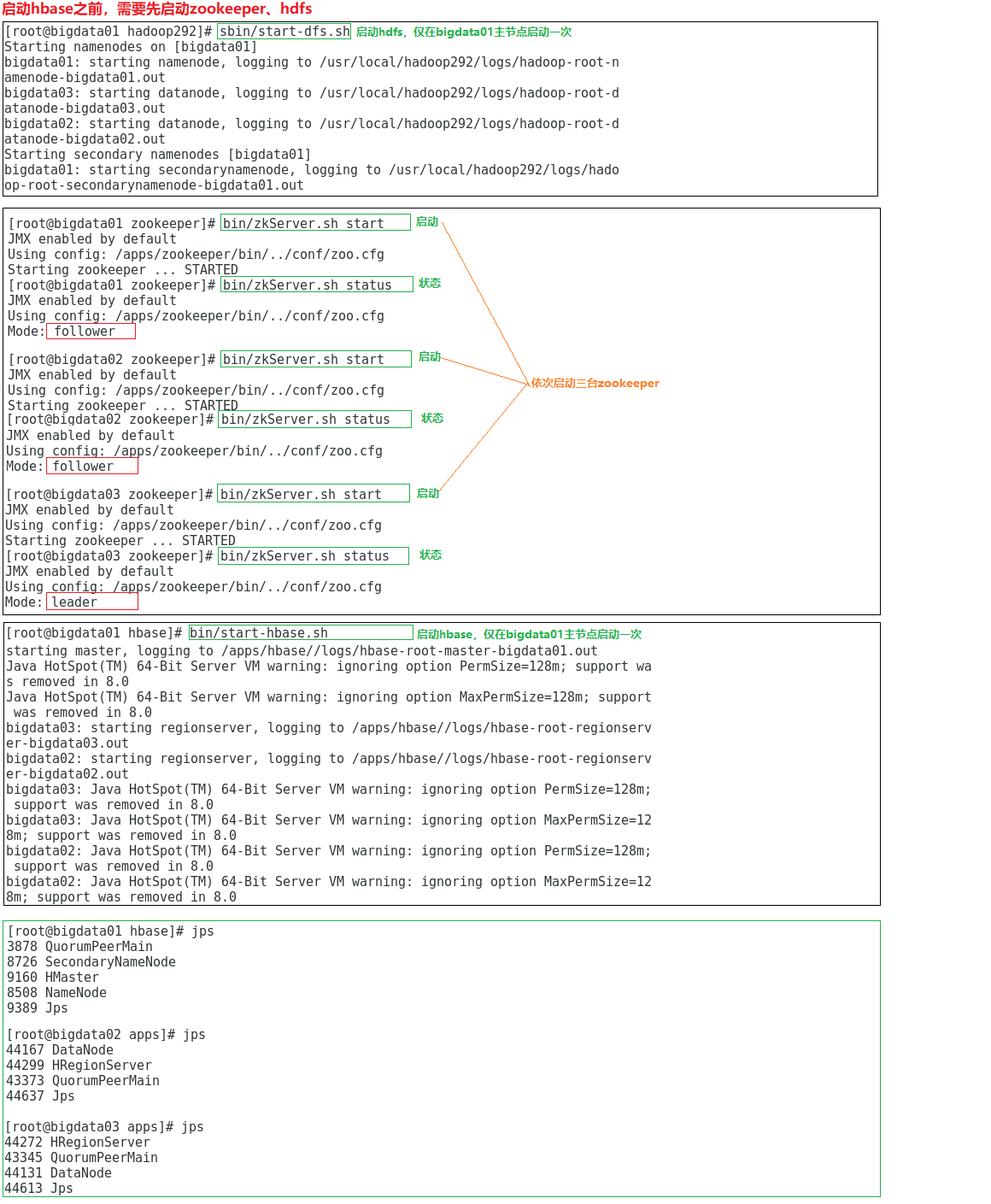
9.2.4 Hbase环境启动
00.启动hbase之前,需要先启动zookeeper、hdfs
a.启动hdfs
/usr/local/hadoop292/sbin/start-dfs.sh --启动hdfs,仅在bigdata01主节点启动一次
b.启动zookeeper
/apps/zookeeper/bin/zkServer.sh start --启动zookeeper,需要在每台机器中启动,共三次
c.启动hbase
/apps/hbase/bin/start-hbase.sh --启动hbase,仅在bigdata01主节点启动一次
/apps/hbase/bin/hbase shell --启动hbase的shell命令
9.3 Hbase数据库——Shell
9.4 Hbase数据库——Java
9.5 Hbase存储/读取爬虫数据
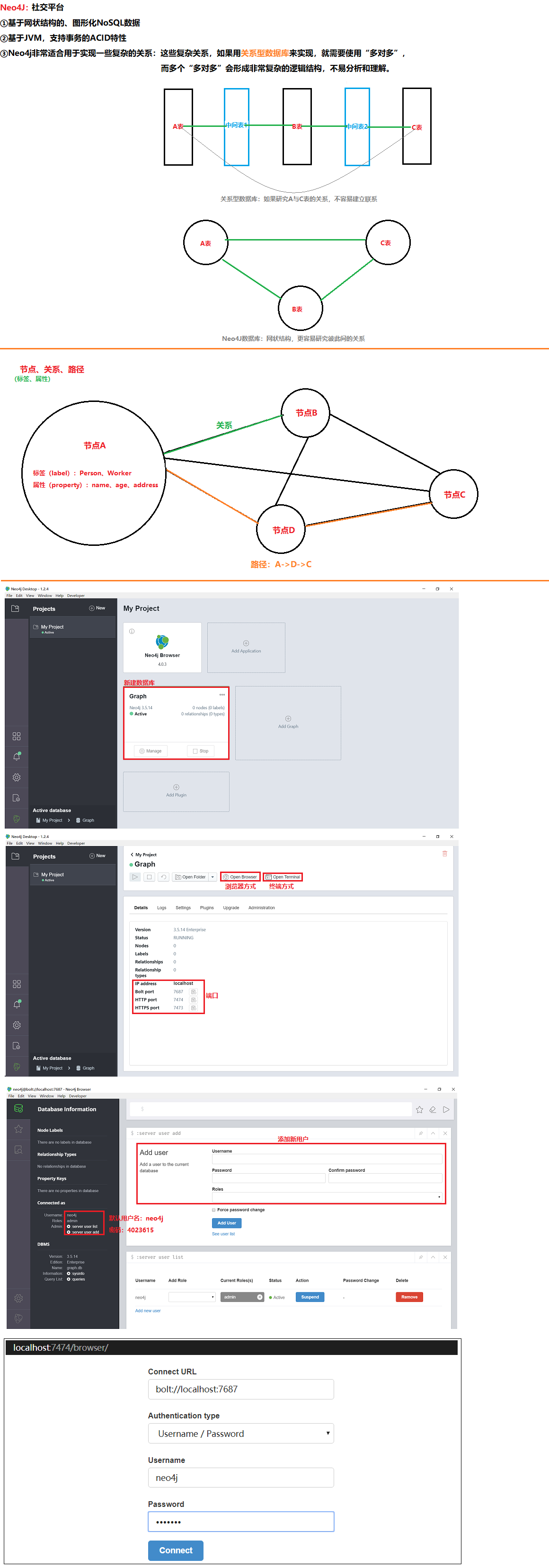
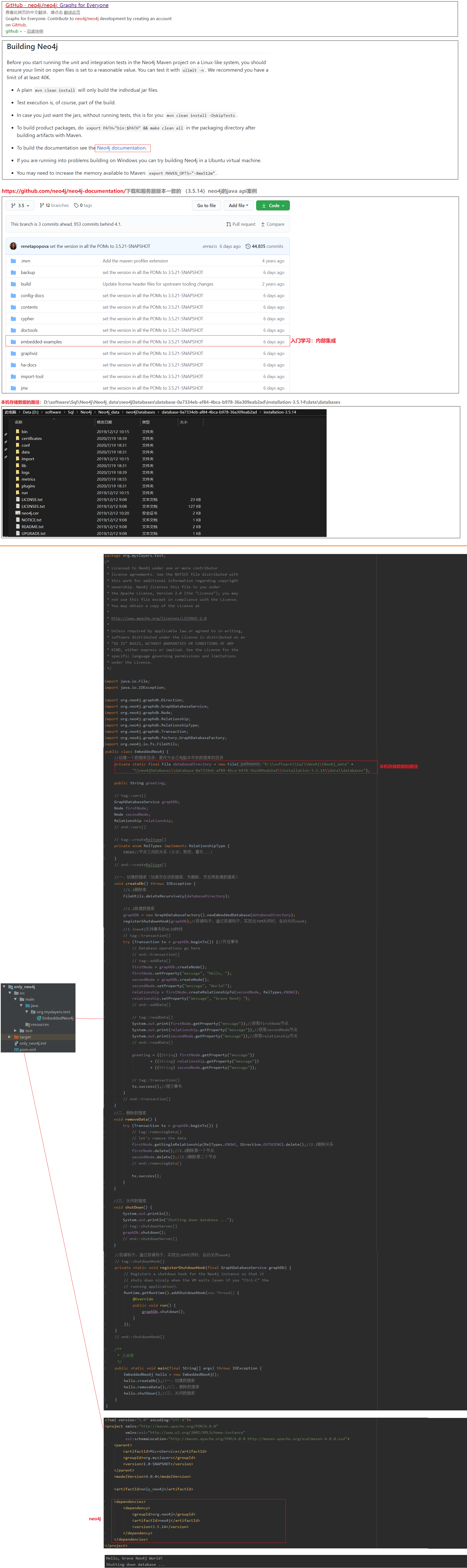
10 Neo4J数据库
10.1 Neo4J环境搭建
01.下载
https://neo4j.com/
02.数据库版本
Neo4j 3.5.14
03.登录数据库
http://localhost:7474/
默认用户名:neo4j
密码:4023615
04.更多API文档
http://neo4j.com/docs/
10.2 Neo4J数据库——Browser
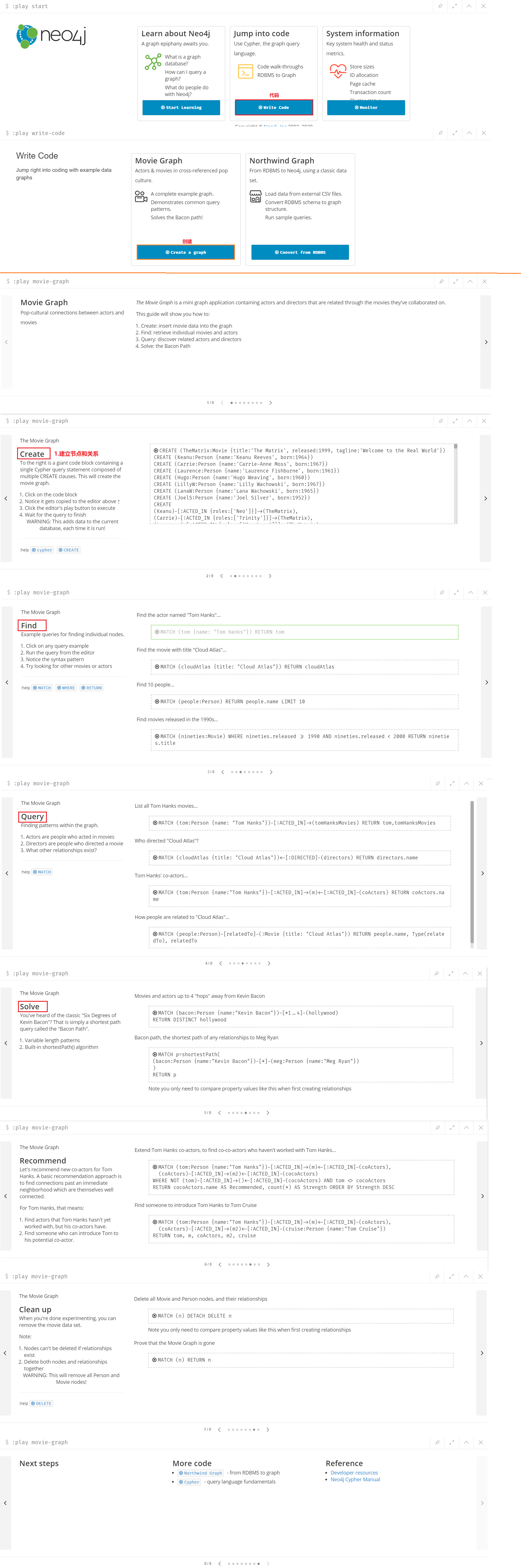
01.创建节点和关系
CREATE (标签:标签 {属性名1:'属性值1', 属性名2:'属性值2',属性名3:'属性值3'})
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
02.建立关系
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix)
03.查询节点
a.查询全部节点
MATCH (n) RETURN n
b.查询名为Tom Hanks的人,参演过哪些电影
MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(tomHanksMovies) RETURN tom,tomHanksMovies
c.查询谁导演了Cloud Atals电影?
MATCH (cloudAtlas {title: "Cloud Atlas"})<-[:DIRECTED]-(directors) RETURN directors.name
d.查询名为Tom Hanks的人,然后以别名tom返回
MATCH (tom {name: "Tom Hanks"}) RETURN tom
04.删除全部的节点和关系
match (n)
optional match (n)-[r]-()
delete n,r
05.删除
match (p:Person),(m:Movie) --查询某个节点
optional match (p)-[r1]-() , (m)-[r2]-() --路径r1:从p到全部、路径r2:从m到全部
delete p,m,r1,r2 --删除:人、电影、路径
10.3 Neo4J数据库——Java
01.下载和服务器版本一致的(3.5.14)neo4j的java api案例
https://github.com/neo4j/neo4j-documentation/tree/3.5
02.引入依赖
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>3.5.14</version>
</dependency>
03.测试官方示例
EmbeddedNeo4j.java
11 SpringCloud
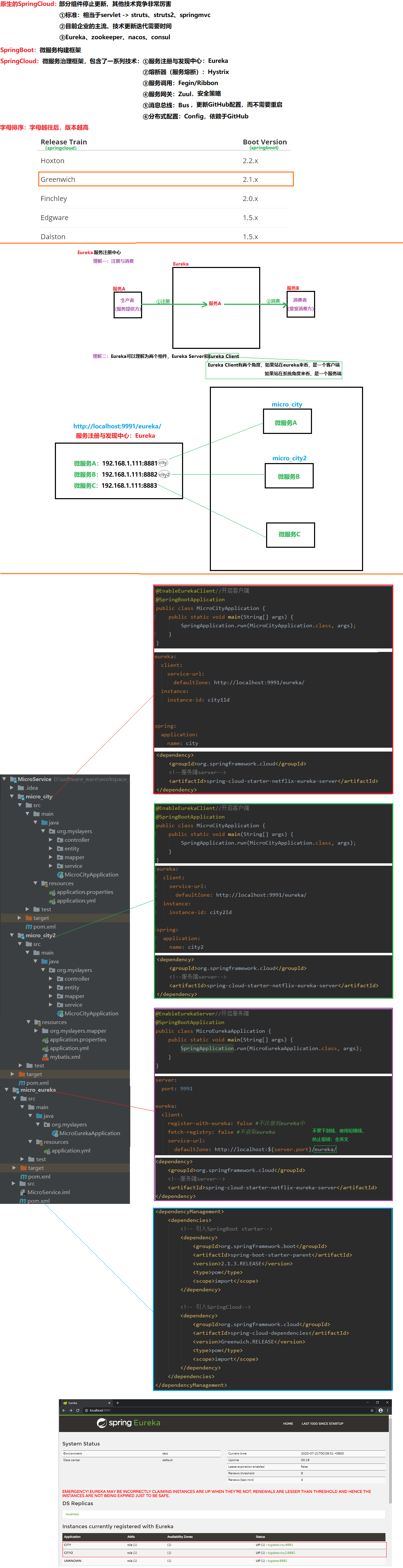
11.1 服务注册与发现中心:Eureka
00.场景
micro_eureka(服务注册与发现中心) -> micro_city、micro_city2(注册的两个微服务)
01.依赖
<dependencyManagement>
<dependencies>
<!-- 引入SpringBoot starter-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 引入SpringCloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
02.服务端
a.pom.xml(依赖)
<!--Eureka服户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
b.application.yml(配置)
server:
port: 9991
eureka:
client:
register-with-eureka: false #不注册到eureka中
fetch-registry: false #不获取eureka
service-url:
defaultZone: http://localhost:${server.port}/eureka/
c.启动类(编码)
@EnableEurekaServer//启动Eureka服务端
@SpringBootApplication
public class MicroEurekaApplication {
public static void main(String[] args) {
SpringApplication.run(MicroEurekaApplication.class, args);
}
}
03.客户端(micro_city)
a.pom.xml(依赖)
<!--Eureka服户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
b.application.yml(配置)
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: city1Id
spring:
application:
name: city
c.启动类(编码)
@EnableEurekaClient//开启客户端
@SpringBootApplication
public class MicroCityApplication {
public static void main(String[] args) {
SpringApplication.run(MicroCityApplication.class, args);
}
}
04.客户端(micro_city2)
a.pom.xml(依赖)
<!--Eureka服户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
b.application.yml(配置)
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: city2Id
spring:
application:
name: city2
c.启动类(编码)
@EnableEurekaClient//开启客户端
@SpringBootApplication
public class MicroCityApplication {
public static void main(String[] args) {
SpringApplication.run(MicroCityApplication.class, args);
}
}
11.2 服务调用:Feign-面向接口
00.场景
micro_city3(消费者/客户端) -> CityClient接口 -> micro_city(生产者/服务端)
01.micro_city3
a.pom.xml(依赖)
<!--Eureka服户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<!--开启服务调用:Feign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
b.配置(SpringCloud底层已经帮我们实现了,不需要有关于Feign的配置)
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: city3Id
spring:
application:
name: city3
c.启动类(@EnableDiscoveryClien、@EnableFeignClients开启两个注解)
@EnableDiscoveryClient//开启Discovery
@EnableFeignClients//开启Feign
@EnableEurekaClient//开启Eureka
@SpringBootApplication
public class MicroCityApplication {
public static void main(String[] args) {
SpringApplication.run(MicroCityApplication.class, args);
}
}
d.CityClient接口
@FeignClient("city")
public interface CityClient {
@PostMapping("addCity")
public Message addCity(@RequestBody City city);
@DeleteMapping("deleteById/{id}")
public Message deleteById(@PathVariable("id") Integer id);
@PutMapping("updateCityById")
public Message updateCityById(@RequestBody City city);
@GetMapping("queryCities")
public Message queryCities();
}
e.CityController3控制器
@RestController
public class CityController2 {
/**
* 二、通过CityClient接口,调用远程的micro_city的CityController层
*/
@Autowired
CityClient cityClient;
@PostMapping("addCity")
public Message addCity(@RequestBody City city){
return cityClient.addCity(city);
}
@DeleteMapping("deleteById/{id}")
public Message deleteById(@PathVariable("id") Integer id){
return cityClient.deleteById(id);
}
@PutMapping("updateCityById")
public Message updateCityById(@RequestBody City city){
return cityClient.updateCityById(city);
}
@GetMapping("queryCities")
public Message queryCities(){
return cityClient.queryCities();
}
}
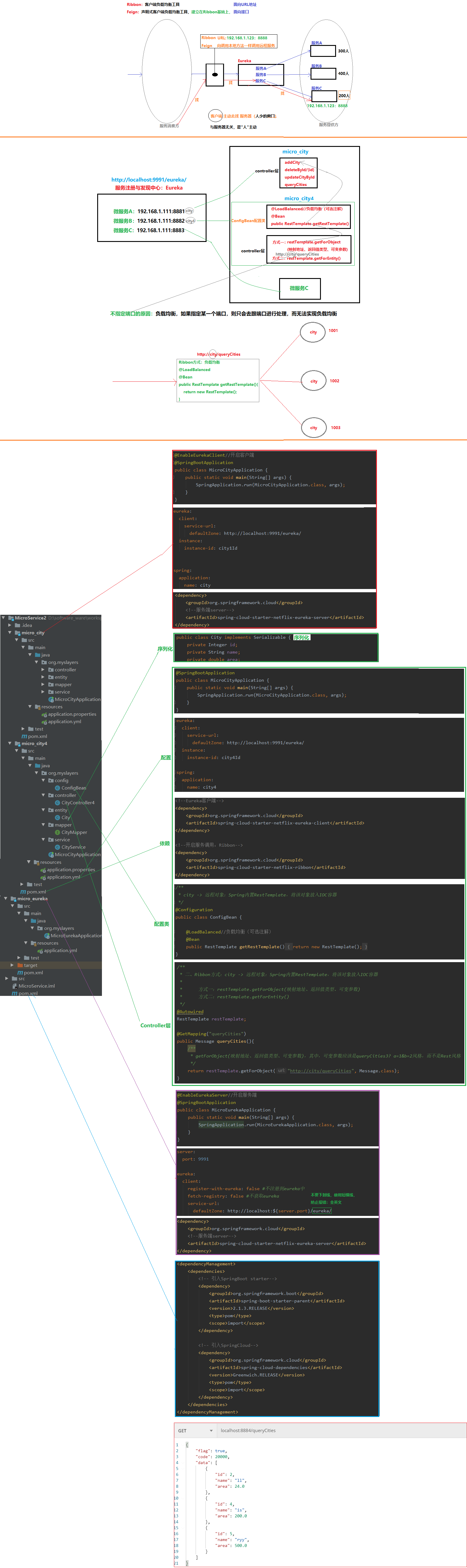
11.3 服务调用:Ribbon-面向URL
00.场景
micro_city4(消费者/客户端) -> RestTemplate对象 -> micro_city(生产者/服务端)
01.micro_city4
a.pom.xml(依赖)
<!--Eureka客户端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--开启服务调用:Ribbon-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
b.配置
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: city4Id
spring:
application:
name: city4
c.启动类
相比Feign方式,无注解
d.RestTemplate对象
/**
* city -> 远程对象:Spring内置RestTemplate,将该对象放入IOC容器
*/
@Configuration
public class ConfigBean {
@LoadBalanced//负载均衡(可选注解)
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
e.CityController4控制器
/**
* 二、Ribbon方式:city -> 远程对象:Spring内置RestTemplate,将该对象放入IOC容器
* 方式一:restTemplate.getForObject(映射地址、返回值类型、可变参数)
* 方式二:restTemplate.getForEntity()
*/
@Autowired
RestTemplate restTemplate;
@GetMapping("queryCities")
public Message queryCities(){
/**
* getForObject(映射地址、返回值类型、可变参数)
*/
return restTemplate.getForObject("http://city/queryCities", Message.class);
}
11.4 服务熔断:Hystrix
00.场景
micro_city5(Feign + Hystrix)
01.代码实现
a.pom.xml(当前版本2.1.3.RELEASE与Greenwich.RELEASE,Fegin内部已支持Hystrix,不需要Hystrix依赖)
<!--Eureka服务端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<!--开启服务调用:Feign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
b.配置(city5(开启Hystrix)-> city1)
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: city5Id
spring:
application:
name: city5
feign:
hystrix:
enabled: true #开启熔断器
c.启动类
@EnableDiscoveryClient//开启Discovery
@EnableFeignClients//开启Feign
@EnableEurekaClient//开启Eureka客户端
@SpringBootApplication
public class MicroCityApplication {
public static void main(String[] args) {
SpringApplication.run(MicroCityApplication.class, args);
}
}
d.CityClient接口(开启熔断器注解)
@FeignClient(value = "city", fallback = CityClientImpl.class)
public interface CityClient {
@PostMapping("addCity")
public Message addCity(@RequestBody City city);
@DeleteMapping("deleteById/{id}")
public Message deleteById(@PathVariable("id") Integer id);
@PutMapping("updateCityById")
public Message updateCityById(@RequestBody City city);
@GetMapping("queryCities")
public Message queryCities();
}
e.CityClientImpl(实现CityClient接口,触发本地熔断器后,返回失败消息)
@Component
public class CityClientImpl implements CityClient {
@Override
public Message addCity(City city) {
return new Message(true, StatusCode.OK, "请求失败,触发了本地熔断器");
}
@Override
public Message deleteById(Integer id) {
return new Message(true, StatusCode.OK, "请求失败,触发了本地熔断器");
}
@Override
public Message updateCityById(City city) {
return new Message(true, StatusCode.OK, "请求失败,触发了本地熔断器");
}
@Override
public Message queryCities() {
return new Message(true, StatusCode.OK, "请求失败,触发了本地熔断器");
}
}
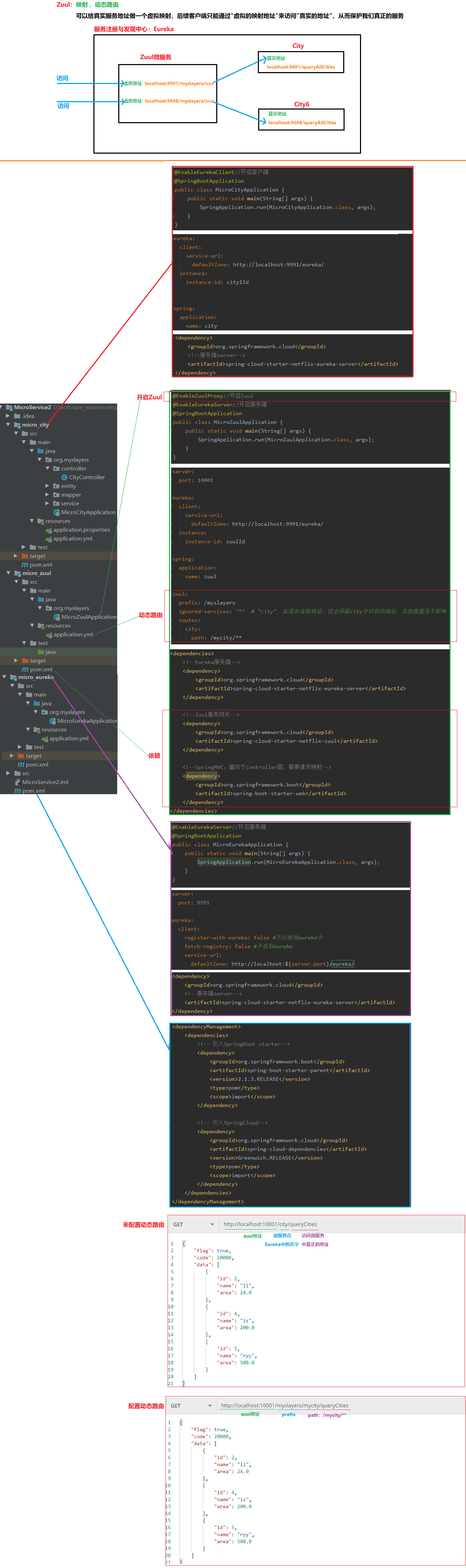
11.5 服务网关:Zuul
00.场景
micor_zuul(动态路由)
01.代码实现
a.pom.xml(依赖)
<!--Eureka服务端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<!--Zuul服务网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
<!--SpringMVC:偏向于Controller层,需要请求映射-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
b.配置
server:
port: 10001
eureka:
client:
service-url:
defaultZone: http://localhost:9991/eureka/
instance:
instance-id: zuulId
spring:
application:
name: zuul
zuul:
prefix: /myslayers
ignored-services: "*" # "city" 如果有虚拟地址,仅会屏蔽city中以前的地址,其他微服务不影响
routes:
city:
path: /mycity/**
c.启动类(编码)
@EnableZuulProxy//开启Zuul
@EnableEurekaServer//开启服务端
@SpringBootApplication
public class MicroZuulApplication {
public static void main(String[] args) {
SpringApplication.run(MicroZuulApplication.class, args);
}
}
11.6 分布式配置中心:Config
00.场景
micro_config(分布式配置中心) -> micro_city6(使用分布式配置)
00.Github(Config约定,文件命名必须为A-B.properties/yml)
https://github.com/wohenguaii/micro_config_rep.git
micro-application.properties
micro-application.yml
01.micro_city5(使用分布式配置)
a.pom.xml(依赖)
<!--分布式配置中心:config-server-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
b.application.yml(配置)
eureka:
instance:
instance-id: config
server:
port: 10010
spring:
cloud:
config:
server:
git:
uri: https://github.com/wohenguaii/micro_config_rep.git
c.启动类(编码)
@EnableConfigServer //开启Config
@SpringBootApplication
public class MicroConfigApplication {
public static void main(String[] args) {
SpringApplication.run(MicroConfigApplication.class, args);
}
}
02.micro_city6(使用分布式配置)
a.pom.xml(依赖)
<!--分布式配置中心:starter-config-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
b.bootstrap.yml(建议将云端配置命名为bootstrap.yml/properties,bootstrap优先级高于application)
spring:
cloud:
config:
uri: http://127.0.0.1:10010
label: master
name: micro #A
profile: application #B
c.编码
使用分布式配置中心Config
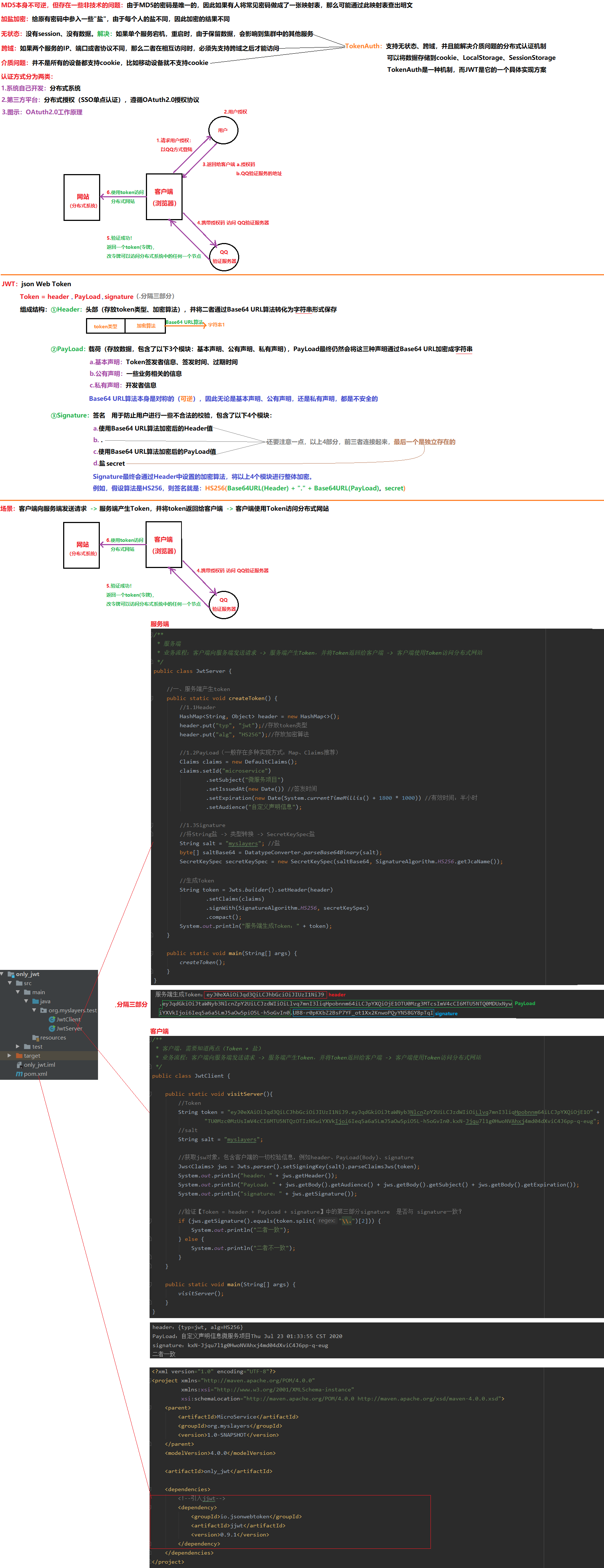
12 分布式认证
12.1 单体框架JWT
12.2 SpringBoot整合JWT
00.场景
第一次登录时(生成Token),获取token;以后登录时(校验Token),拿着token进行校验
自定义请求头Header(key:authentication、value:myslayers-token)
01.micro_jwt
a.pom.xml(依赖)
<dependencies>
<!--引入jjwt-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
<!--解决报错提示:注解ConfigurationProperties-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!--解决报错提示:注解ConfigurationProperties-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
</dependencies>
b.JwtUtil(编码)
public class JwtUtil {
private String key = "myslayers"; //盐
private long ttl = 18000000; //过期时间
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public long getTtl() {
return ttl;
}
public void setTtl(long ttl) {
this.ttl = ttl;
}
//(生成Token)服务端生成jwt的Token方法
public String createJWT(String id, String subject, String roles) {
return Jwts.builder().setId(id)
.setSubject(subject)
.setIssuedAt(new Date())
.setExpiration(new Date(System.currentTimeMillis() + ttl)) //有效时间
.signWith(SignatureAlgorithm.HS256, key) //signature签名
.claim("roles", roles) //设置权限
.compact();
}
//(检验Token)客户端发送jwt的Token时校验方法
public Claims parseJWT(String token) {
return Jwts.parser().setSigningKey(key).parseClaimsJws(token).getBody();
}
}
02.micro_city7(生成Token)
a.pom.xml(依赖)
<dependency>
<groupId>org.myslayers</groupId>
<artifactId>micro_jwt</artifactId>
<version>1.0-SNAPSHOT</version>
<scope>compile</scope>
</dependency>
b.ConfigBean(配置类)
/**
* 将JwtUtil放入该项目springboot的IOC容器
*/
@Configuration
public class ConfigBean {
@Bean
public JwtUtil getJwtUtil() {
return new JwtUtil();
}
}
c.CityController(编码:生成token)
@RestController
public class CityController {
/**
* SpringBoot整合jwt:
* 场景:第一次登录,客户端向服务端发送请求,然后,客户端将生成的token返回给客户端
* 第一次登录时(生成Token),获取token
*/
@Autowired
private JwtUtil jwtUtil;
@PostMapping("login")
public Message login(@RequestBody Map<String, String> login) {
//模拟数据库操作(zs、abc、10001、theme、admin...)
String uname = login.get("username");
String upwd = login.get("password");
if ("zs".equals(uname) && "abc".equals(upwd)) {
System.out.println("登录成功!");
//登录成功后,用map进行封装返回token、用户名
String token = jwtUtil.createJWT("1001", "theme", "admin");
Map<String, Object> map = new HashMap<>();
map.put("token", token);
map.put("username", uname);
//返回Message
return new Message(true, StatusCode.OK, map);
} else {
System.out.println("登录失败!");
return new Message(false, StatusCode.ERROR, "登录失败!");
}
}
}
03.micro_city7(解析Token:减少代码冗余,将解析操作放到拦截器中,一个微服务对应一个拦截器)
a.JwtInterceptor(拦截器:解析Token)
/**
* 例如,删除之前,需要先通过jwt进行权限校验(用户验证)
* 场景:假设此时,客户端postman已经将携带token的jwt传递过来,现在需要对jwt进行解析
* 以后登录时(校验Token),拿着token进行校验
*/
@Component
//请求 -> 拦截器(pre) -> 校验一般为“增删改”
public class JwtInterceptor extends HandlerInterceptorAdapter {
@Autowired
private JwtUtil jwtUtil;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截器...");
//从header中获取authentication对应的key值(key值 = myslayers-token)
String key = request.getHeader("authentication");
//根据获取的key值,对token进行截取判断
if (key != null && key.startsWith("myslayers-")) {
String token = key.substring(10);//myslayers-token:从第10位开始截取token
Claims claims = jwtUtil.parseJWT(token);//解析token
String roles = (String) claims.get("roles");//根据键值对,用键roles获取对应的值
//校验判断
if (roles.equals("admin")) {
System.out.println("管理员admin校验成功!");
request.setAttribute("claims", claims);//将request域中,放入claims,然后拦截器进行放行
}
}
//放行
return true;
}
}
b.JwtConfig(对拦截请求进行再一步处理:排除登录login时,需要进行校验)
/**
* 对拦截请求进行再一步处理:排除登录login时,需要进行校验
*/
@Configuration
public class JwtConfig extends WebMvcConfigurationSupport {
@Autowired
JwtInterceptor jwtInterceptor;
@Override
protected void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(jwtInterceptor)
.addPathPatterns("/**") //拦截全部请求
.excludePathPatterns("/**/login"); //排除login登录请求
}
}
c.CityController(编码:利用拦截器处理不同的请求)
@RestController
public class CityController {
@Autowired
CityService cityService;
@Autowired
HttpServletRequest request;
private Message checkToken() {
//如果拦截器判断权限足够,则会在request中放入一个claims参数,否则,则没有claims参数
Claims claims = (Claims) request.getAttribute("claims");
//判断是否存在claims参数
if (claims == null) {
return new Message(false, StatusCode.ERROR, "权限不足!");
}
return new Message(false, StatusCode.ERROR, "获得权限!");
}
@PostMapping(value = "addCity7")
public Message addCity7(@RequestBody City city){
//校验
checkToken();
boolean result = cityService.addCity(city);
return new Message(true, StatusCode.OK, result);
}
@DeleteMapping("deleteById7/{id}")
public Message deleteById7(@PathVariable("id") Integer id){
//校验
checkToken();
//校验(admin用户)成功!进行删除操作
boolean result = cityService.deleteById(id);
return new Message(true, StatusCode.OK, result);
}
@PutMapping("updateCityById7")
public Message updateCityById7(@RequestBody City city){
//校验
checkToken();
boolean result = cityService.updateCityById(city);
return new Message(true, StatusCode.OK, result);
}
@GetMapping("queryCities7")
public Message queryCities7(){
List<City> cities = cityService.queryCities();
return new Message(true, StatusCode.OK, cities);
}
}
13 分布式
13.1 CAP原则
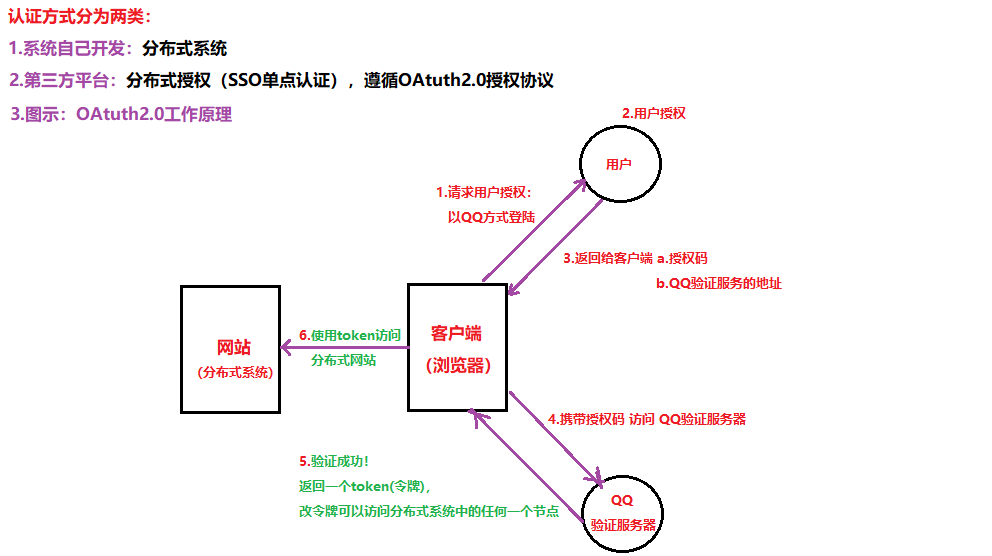
01.CAP原则又称CAP定理,指的是在一个分布式系统中,存在Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可同时保证,最多只能保证其中的两者。
一致性(C):在分布式系统中的所有数据备份,在同一时刻都是同样的值(所有的节点无论何时访问都能拿到最新的值)
可用性(A):系统中非故障节点收到的每个请求都必须得到响应(比如我们之前使用的服务降级和熔断,其实就是一种维持可用性的措施,虽然服务返回的是没有什么意义的数据,但是不至于用户的请求会被服务器忽略)
分区容错性(P):一个分布式系统里面,节点之间组成的网络本来应该是连通的,然而可能因为一些故障(比如网络丢包等,这是很难避免的),使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中(这样就可能出现某些被分区节点存放的数据访问失败,我们需要来容忍这些不可靠的情况)
02.只能存在以下三种方案
a.AC(可用性+一致性)
要同时保证可用性和一致性,代表着某个节点数据更新之后,需要立即将结果通知给其他节点,并且要尽可能的快,
这样才能及时响应保证可用性,这就对网络的稳定性要求非常高,但是实际情况下,网络很容易出现丢包等情况,
并不是一个可靠的传输,如果需要避免这种问题,就只能将节点全部放在一起,但是这显然违背了分布式系统的概念,
所以对于我们的分布式系统来说,很难接受。
b.CP(一致性+分区容错性)
为了保证一致性,那么就得将某个节点的最新数据发送给其他节点,并且需要等到所有节点都得到数据才能进行响应,
同时有了分区容错性,那么代表我们可以容忍网络的不可靠问题,所以就算网络出现卡顿,
那么也必须等待所有节点完成数据同步,才能进行响应,因此就会导致服务在一段时间内完全失效,
所以可用性是无法得到保证的。
c.AP(可用性+分区容错性)
既然CP可能会导致一段时间内服务得不到任何响应,那么要保证可用性,就只能放弃节点之间数据的高度统一,
也就是说可以在数据不统一的情况下,进行响应,因此就无法保证一致性了。
虽然这样会导致拿不到最新的数据,但是只要数据同步操作在后台继续运行,
一定能够在某一时刻完成所有节点数据的同步,那么就能实现最终一致性,所以AP实际上是最能接受的一种方案。
比如我们实现的Eureka集群,它使用的就是AP方案,Eureka各个节点都是平等的,少数节点挂掉不会影响正常节点的工作,
剩余的节点依然可以提供注册和查询服务。而Eureka客户端在向某个Eureka服务端注册时如果发现连接失败,
则会自动切换至其他节点。只要有一台Eureka服务器正常运行,那么就能保证服务可用(A),
只不过查询到的信息可能不是最新的(C)
03.并发VS并行
a.并发是同时处理很多的事情,同时处理一下四个并发步骤:
1. 把书装到车上;
2. 把推车运到火炉旁;
3. 把书卸到火炉里;
4. 运回空推车。
b.说明
并行是同时做很多的事情,分为两组同时执行同一任务
01.分布式
基于分布式:大数据、人工智能、区块链、边缘计算、微服务
核心:"拆"
微服务与分布式:分布式->拆了就行(横向、纵向)
微服务->纵向拆分,最小化拆分
横向拆分:jsp/servlet->service -dap
纵向拆分:按照业务逻辑拆分,电商:用户、支付、购物…
02.CPA理论:任何一个分布式系统都必须重点考虑的原则
内容:在任何分布式系统中,C、A、P不能够同时共存,只能存在两个;一般而言,至少要保证P可行,因为分布式中经常会出现“弱网环境”,因此就需要在C和A之间二选一
C:强一致性,子节点中的数据时刻需要保持一致,如果满足一致性,则数据会造成回滚,不会提交,则数据不可用
A:可用性,整体能够使用(在合理的时间范围内,系统能够提供正常的服务)
P:分区容错性,允许部分失败(当分布式系统中的一个或多个节点发生网络故障(网络分区),从而脱离整个系统的网络环境时,系统仍然能够提供可靠的服务)
03.BASE理论:Basically Available
内容:弥补CAP的不足,尽最大努力近似地实现CAP三者共同实现
核心:用“最终一致性”代替“强一致性”,首选满足A\P,因此不能满足C,但是可以用最终一致性代替C
注意:软状态:多个节点时,允许中间某个时刻数据不一致
强一致性:多个节点时,时时刻刻保持一致
最终一致性:多个节点时,最后一致就行
04.高并发原则
场景:双十一、春晚发红包、12306购票
解决方案:①垂直扩展:通过软件技术或者升级硬件,来提高单机的能力
②水平扩展:通过增加服务器的节点个数,来横向扩充系统的性能。常用:集群(失败迁移、负载均衡)/分布式
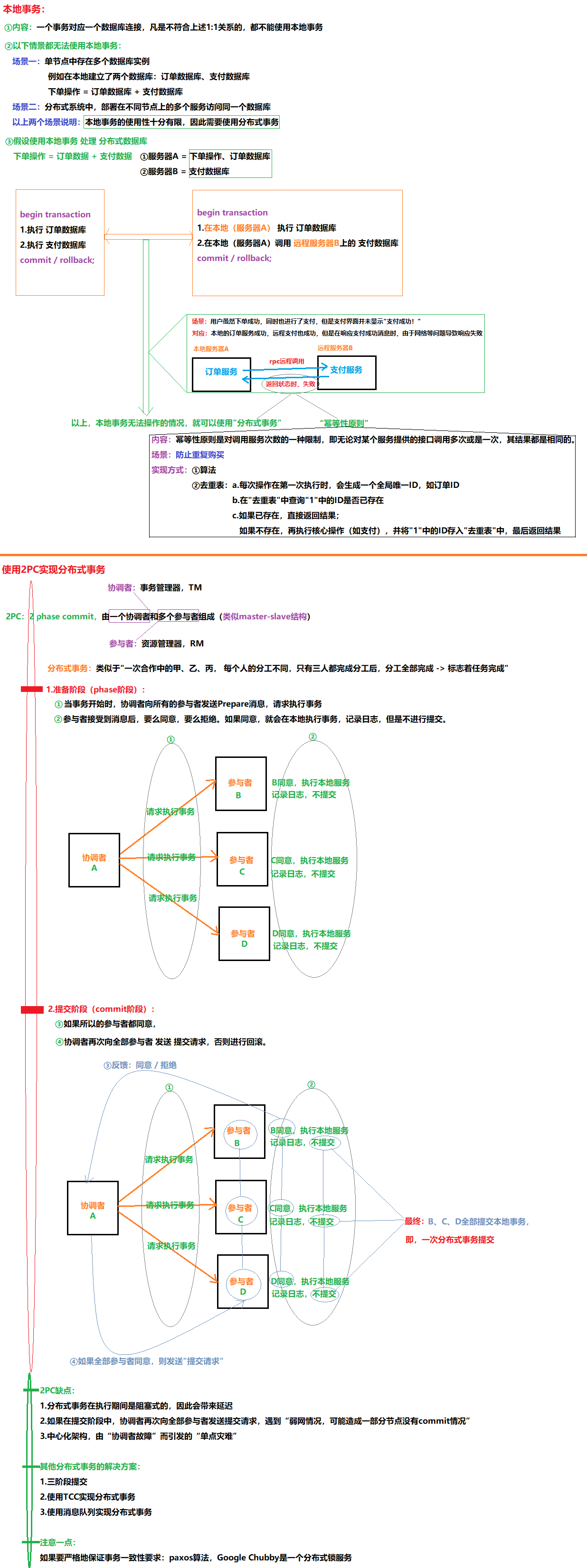
05.幂等性原则
内容:幂等性原则是对调用服务次数的一种限制,即无论对某个服务提供的接口调用多次或是一次,其结果都是相同的。
场景:防止重复购买
实现方式:①算法
②去重表:a.每次操作在第一次执行时,会生成一个全局唯一D,如订单D
b.在"去重表"中查询"1"中的1D是否已存在
c.如果已存在,直接返回结果;如果不存在,再执行核心操作(如支付),并将”1"中的D存入"去重表"中,最后返回结果
06.数据共享原则
①Session Replication:在客户端第一次发出请求后,
处理该请求的服务端就会创建一个与之对应的Session?对象,用于保存客户端的状态信息,
之后为了让其他服务器也能保存一份此Session对象,就需要将此Session对象在各个服务端节点之间进行同步
优点:数据共享后,客户端只要向该集群中的任何一台机器成功发送过一次请求,就能够在全部的集群节点进行访问
②Session Stidky:Session Stidky:通过Nginx等负载均衡工具对各个用户进行标记(例如对Cookie标记),
使每个用户在经过负载工具后都请求固定的服务节点
优点:固定的请求节点
缺点:不支持高可用,每份数据都需要单独处理
③独立Session服务器:将系统中所有的Session对象都存放到一个独立的Session服务中,
之后各个应用服务器再分别从这个Session服务中获取需要的Session对象
步骤:①查询redis中的session是否存在
②如果存在,则登陆!如果不存在,则不登陆!
07.无状态原则
内容:将“状态建立存储,从而实现应用服务的”无状态”
优点:①在“无状态“的服务中,单个服务的宕机、重启等都不会影响到集群中的其他服务,并且很容易对应用服务进行横向扩展
②另一方面,将带有数据的服务设置为"有状态”,并进行集群的"集中部署”(如ySQL集群),可以降低集群内部数据同步带来的延迟
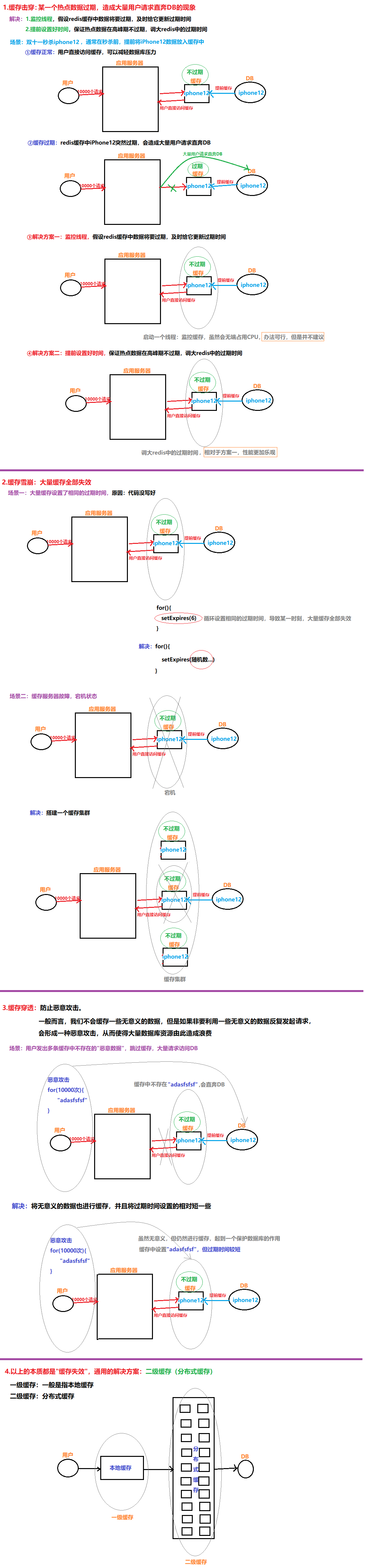
13.2 缓存问题
01.缓存击穿:某一个热点数据过期,造成大量用户请求直奔DB的现象
解决:1.监控线程,假设redis缓存中数据将要过期,及时给它更新过期时间
2.提前设置好时间,保证热点数据在高峰期不过期,调大redis中的过期时间
场景:双十一秒杀iphone12,通常在秒杀前,提前将iPhone12数据放入缓存中
①缓存正常:用户直接访问缓存,可以减轻数据库压力
②缓存过期:redis缓存中iPhone12突然过期,会造成大量用户请求直奔DB
02.缓存雪崩:大量缓存全部失效
场景一:大量缓存设置了相同的过期时间,原因:代码没写好
场景二:缓存服务器故障,宕机状态
03.缓存穿透:防止恶意攻击。
一般而言,我们不会缓存一些无意义的数据,但是如果非要利用一些无意义的数据反复发起请求,
会形成一种恶意攻击,从而使得大量数据库资源由此造成浪费
场景:用户发出多条缓存中不存在的"恶意数据”,跳过缓存,大量请求访问DB
解决:将无意义的数据也进行缓存,并且将过期时间设置的相对短一些
以上的本质都是"缓存失效”,通用的解决方案:二级缓存(分布式缓存)
一级缓存:一般是指本地缓存
二级缓存:分布式缓存
01.什么是redis击穿?
用户请求透过redis去请求mysql服务器,导致mysql压力过载。但一个web服务里,极容易出现瓶颈的就是mysql,所以才让redis去分担mysql 的压力,所以这种问题是万万要避免的
解决方法:
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
02.什么是redis雪崩?
redis服务由于负载过大而宕机,导致mysql的负载过大也宕机,最终整个系统瘫痪
解决方法:
redis集群,将原来一个人干的工作,分发给多个人干
缓存预热(关闭外网访问,先开启mysql,通过预热脚本将热点数据写入缓存中,启动缓存。开启外网服务)
数据不要设置相同的生存时间,不然过期时,redis压力会大
03.什么是redis雪崩?
高并发下,由于一个key失效,而导致多个线程去mysql查同一业务数据并存到redis(并发下,存了多份数据),而一段时间后,多份数据同时失效。导致压力骤增
分级缓存(缓存两份数据,第二份数据生存时间长一点作为备份,第一份数据用于被请求命中,如果第二份数据被命中说明第一份数据已经过期,要去mysql请求数据重新缓存两份数据)
计划任务(假如数据生存时间为30分钟,计划任务就20分钟执行一次更新缓存数据)
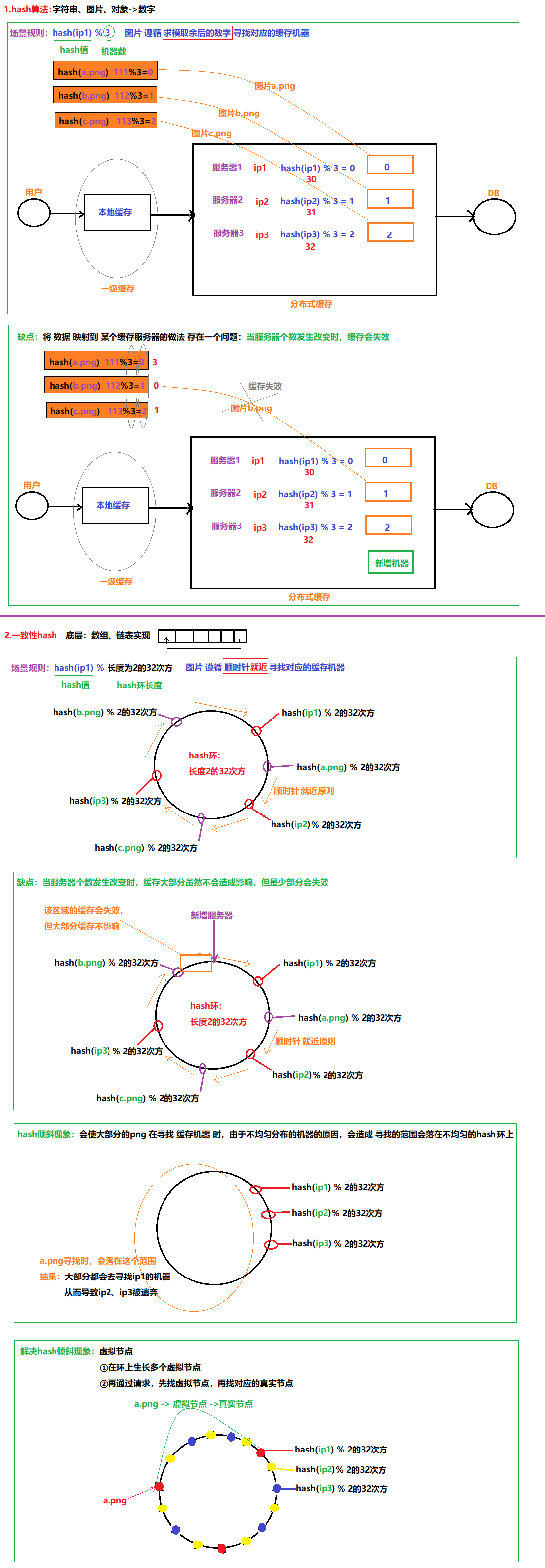
13.3 一致性hash
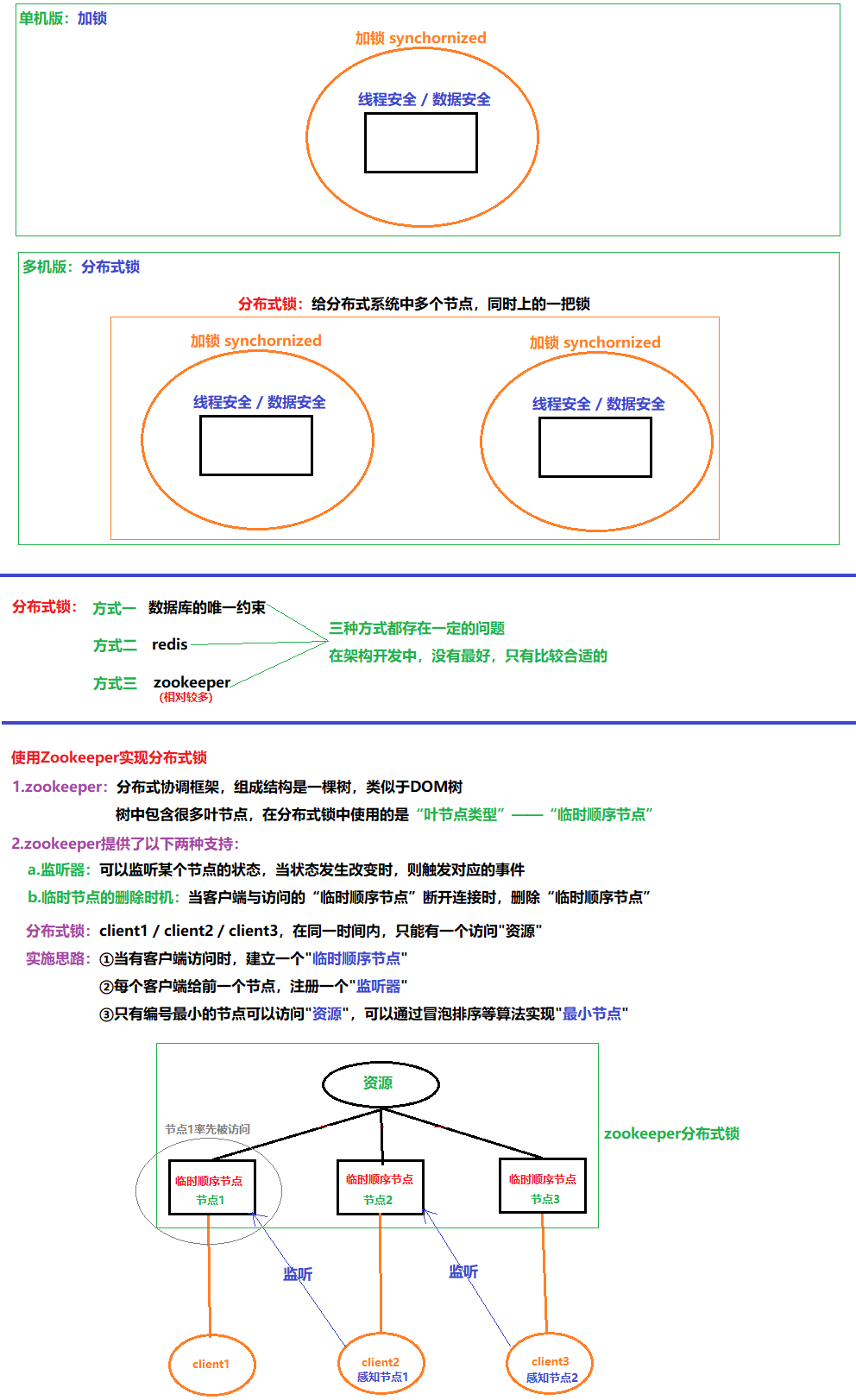
13.4 使用zookeeper实现分布式锁
13.5 缓存一致性
00.如何保证缓存与数据库的双写一致性?
四种同步策略:
想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略:
先更新缓存,再更新数据库;
先更新数据库,再更新缓存;
先删除缓存,再更新数据库;
先更新数据库,再删除缓存。
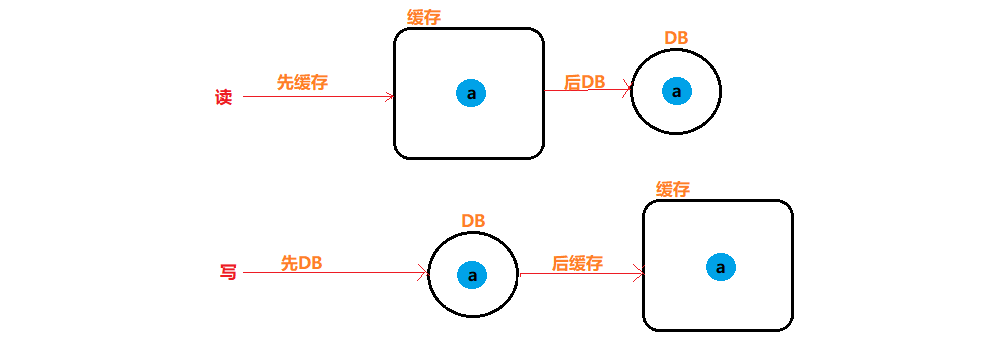
应该先操作数据库还是先操作缓存?
先更新数据库、再删除缓存是影响更小的方案
13.5.1 读和写的执行顺序
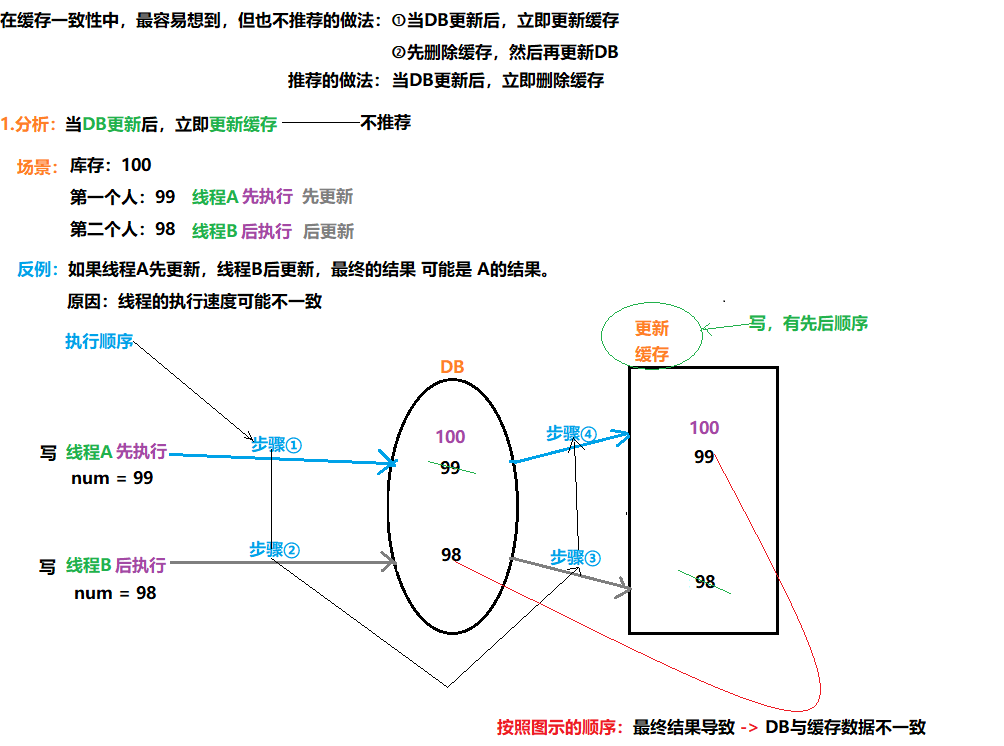
13.5.2 当DB更新后,立即更新缓存
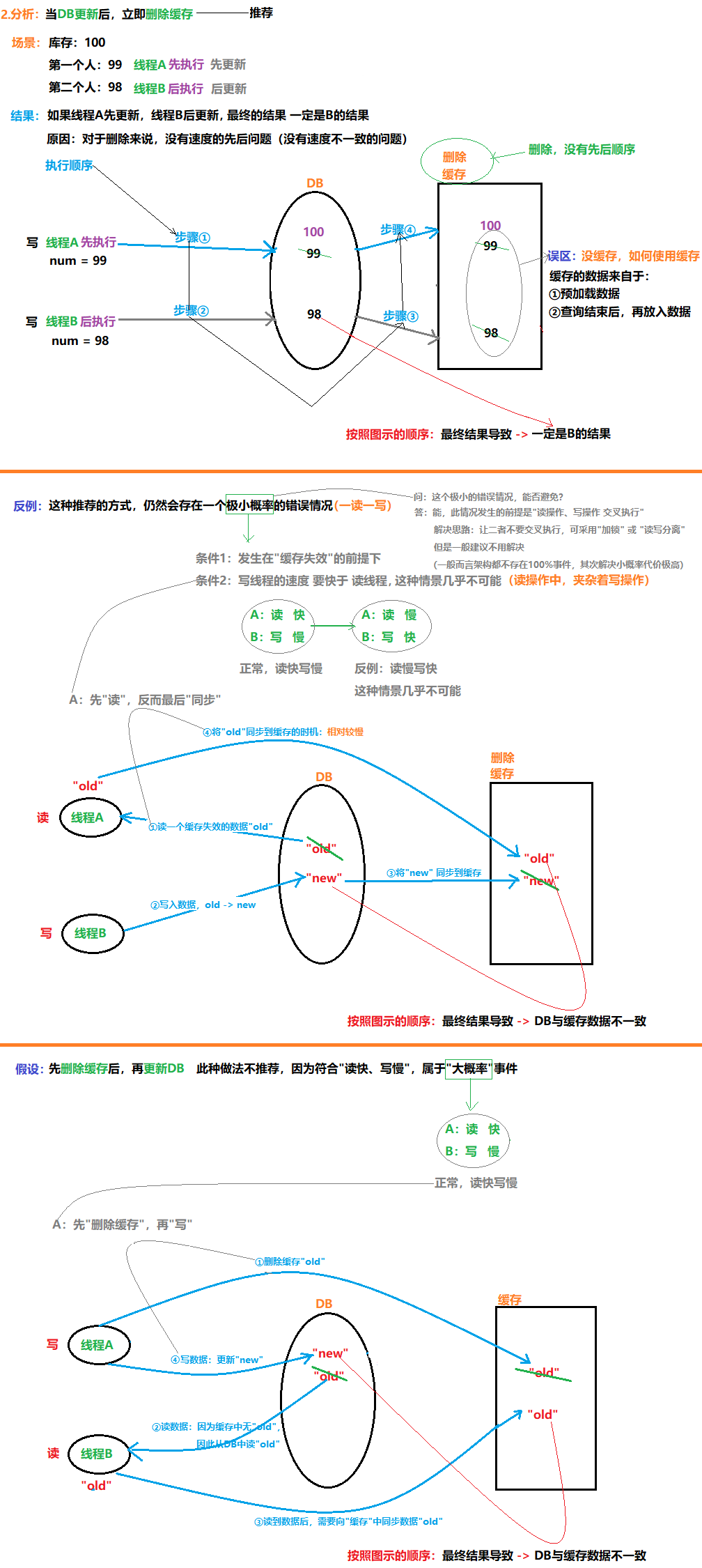
13.5.3 当DB更新后,立即删除缓存
13.6 使用2PC实现分布式事务
13.7 分布式认证&分布式授权