1 Redis基础概念
01.Redis有哪些数据类型?
高性能key-value非关系缓存数据库
Redis支持5种核心的数据类型,分别是字符串、哈希、列表、集合、有序集合;
Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的;
Redis在5.0新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
02.Redis有哪些优缺点?
优点
读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
支持数据持久化,支持AOF和RDB两种持久化方式。
支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,
因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,
需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
03.使用redis有哪些好处?
a.速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都很低
b.支持丰富数据类型,支持string,list,set,sorted set,hash
c.支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
d.丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
04.Redis可以用来做什么?
Redis最常用来做缓存,是实现分布式缓存的首先中间件;
Redis可以作为数据库,实现诸如点赞、关注、排行等对性能要求极高的互联网需求;
Redis可以作为计算工具,能用很小的代价,统计诸如PV/UV、用户在线天数等数据;
Redis还有很多其他的使用场景,例如:可以实现分布式锁,可以作为消息队列使用。
05.Redis和传统的关系型数据库有什么不同?
Redis是一种基于键值对的NoSQL数据库,而键值对的值是由多种数据结构和算法组成的。
Redis的数据都存储于内存中,因此它的速度惊人,读写性能可达10万/秒,远超关系型数据库。
关系型数据库是基于二维数据表来存储数据的,它的数据格式更为严谨,并支持关系查询。
关系型数据库的数据存储于磁盘上,可以存放海量的数据,但性能远不如Redis。
06.为什么要用Redis
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
07.Redis是单线程的,为什么还能这么快?
Redis的大部分操作是在内存上完成的,这是它实现高性能的一个重要原因;
Redis采用了IO多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率。
采用单线程,避免了不必要的上下文切换和竞争条件
数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
08.Redis为什么存的快,内存断电数据怎么恢复?
Redis存的快是因为它的数据都存放在内存里,并且为了保证数据的安全性,
Redis还提供了三种数据的持久化机制,即RDB持久化、AOF持久化、RDB-AOF混合持久化。
若服务器断电,那么我们可以利用持久化文件,对数据进行恢复。
理论上来说,AOF/RDB-AOF持久化可以将丢失数据的窗口控制在1S之内。
2 Redis之客户端
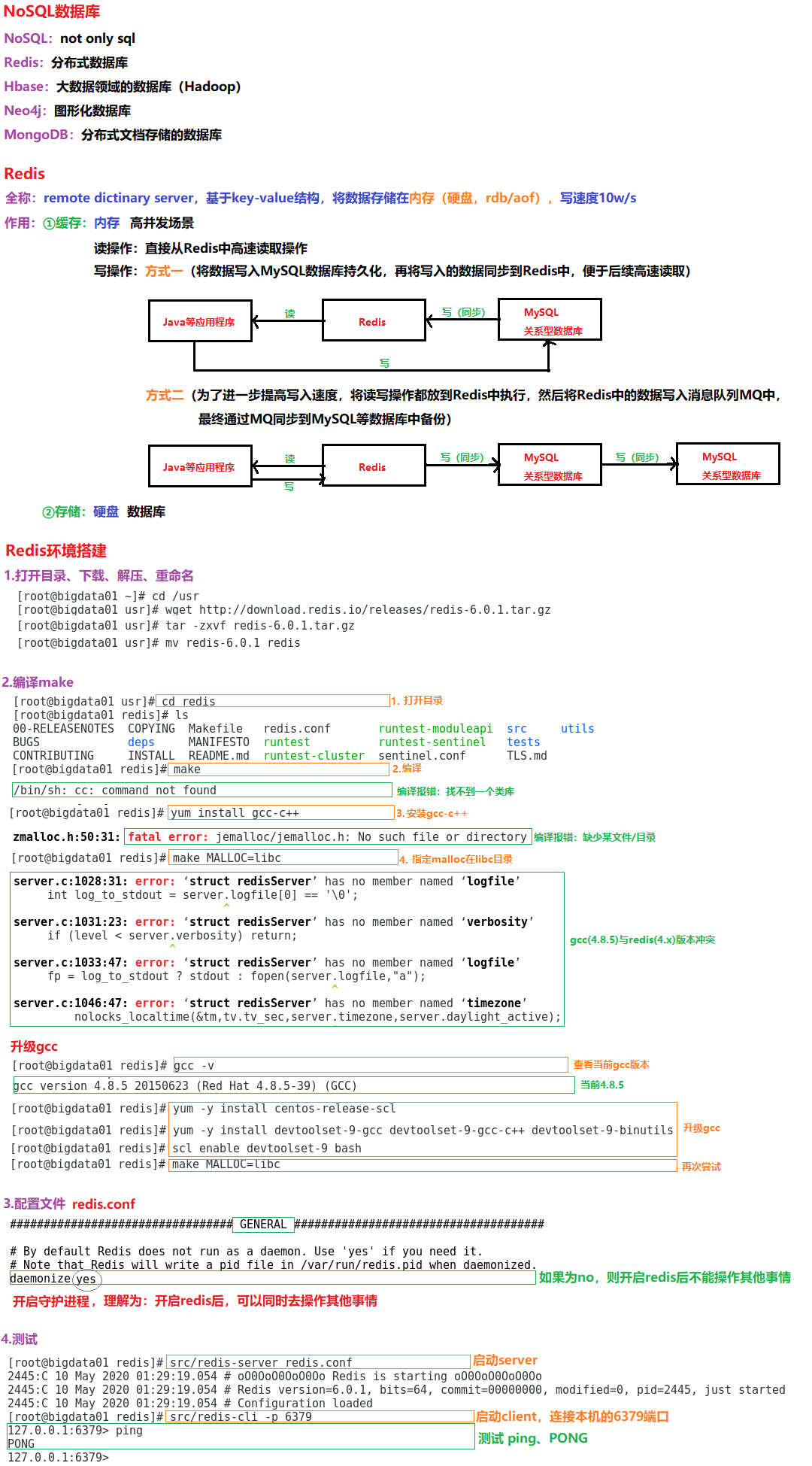
2.1 redis环境搭建
1.打开目录、下载、解压、重命名
a.打开目录
cd /usr
b.下载
wget http://download.redis.io/releases/redis-6.0.1.tar.gz
c.解压
tar -zxvf redis-6.0.1.tar.gz
d.重命名
mv redis-6.0.1 redis
2.配置文件前需要编译
a.打开目录
cd redis/
b.编译
make
c.编译make后,如果报错/bin/sh: cc: command not found
yum install gcc-c++
d.安装c++后,如果报错error: jemalloc/jemalloc.h: No such file or directory
make MALLOC=libc
e.再次尝试后,如果报错‘struct redisServer’ has no member named ‘cached_master’
可能gcc(4.8.5)与redis(4.x)版本冲突
f.升级gcc
gcc -v
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
g.再次尝试
make MALLOC=libc
3.配置redis.conf
daemonize yes --守护进程、后台运行
protected-mode no --外部网络可以直接访问,关闭保护模式
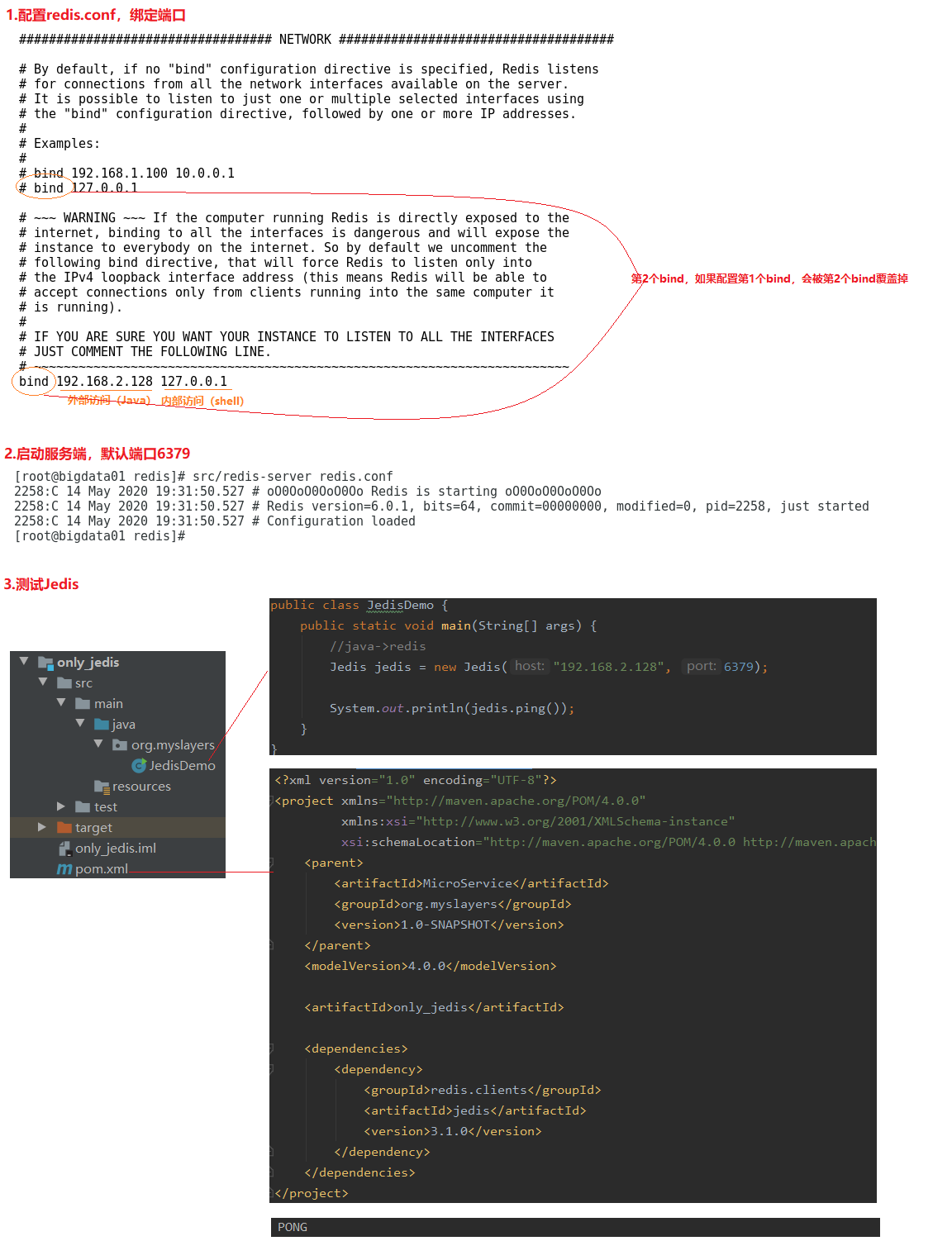
bind 192.168.2.128 127.0.0.1 --绑定端口
maxclients 10000 --默认最大客户端数量10000
requirepass myslayers --永久设置密码
masterauth myslayers --设置主节点密码
config set requirepass myslayers --临时设置密码:命令行(设置)
config get requirepass --临时设置密码:命令行(查看)
4.测试
a.打开目录
cd /usr/redis
b.启动服务端,默认端口6379
src/redis-server redis.conf
c.启动客户端连接服务端
src/redis-cli -p 6379 -a myslayers
d.查看服务
ps -ef | grep redis
kill -9 pid
5.常见配置——内存管理(合理地将有效数据放入内存,并且保证内存容量不会超额)
a.maxmemory <bytes>
最大内存容量,单位byte,如果设置为0则表示没有限制
b.maxmemory-policy noeviction
内存淘汰策略,当往Redis内存中存放的数据大于maxmemory时,则需要使用一种淘汰策略将一部分数据从内存中移除。Redis提供了以下几种淘汰策略:
volatile-lru:在设置了过期时间的key中,使用LPU算法从内存中移除
volatile-lru:在全部范围的key中,使用LPU算法从内存中移除
volatile-random:在设置了过期时间的key中,从内存中随机移除
allkeys-random:在全部范围的key中,从内存中随机移除
allkeys-ttl:移除ttl值中最小的key(即最快过期的key)
noeviction:默认,永不过期,如果溢出就返回error信息
c.maxmemory-samples 5
样本数量,由于maxmemory-policy中使用的LPU等算法都是基于临近的部分数据计算而来的,并不是基于Redis中全部数据计算(为了提高效率),那么“临近的部分数据”有多少呢?maxmemory-samples:默认5,数值越小,计算速度越快,但准确率越低
2.2 Jedis环境搭建
1.配置redis.conf,绑定端口
bind 192.168.2.128 127.0.0.1
2.启动服务端,默认端口6379
src/redis-server redis.conf
3.测试Jedis
a.引入jedis依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
b.测试代码
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.2.128", 6379);
System.out.println(jedis.ping());
}
2.3 Redis数据库
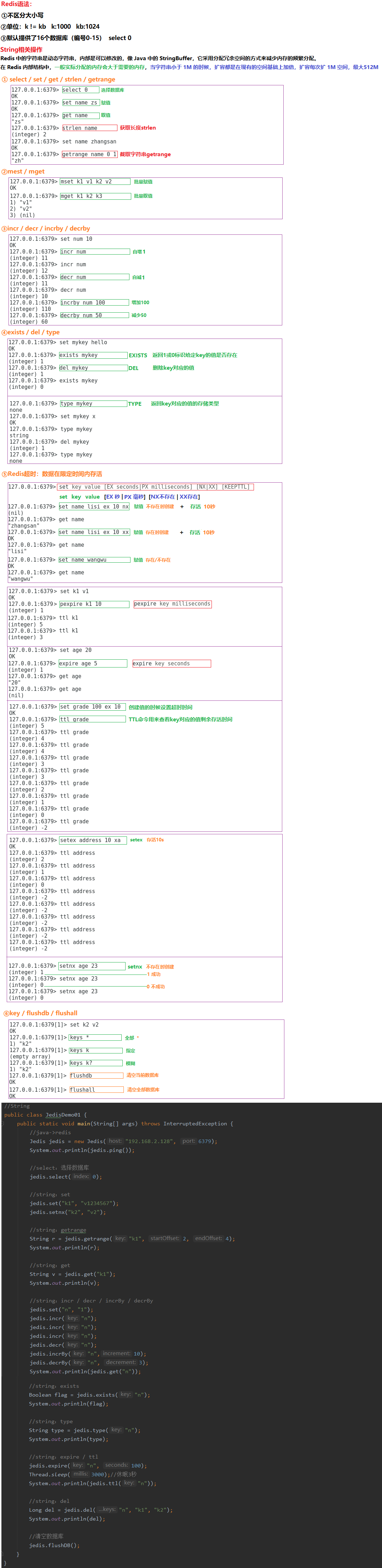
2.3.1 字符串Strings
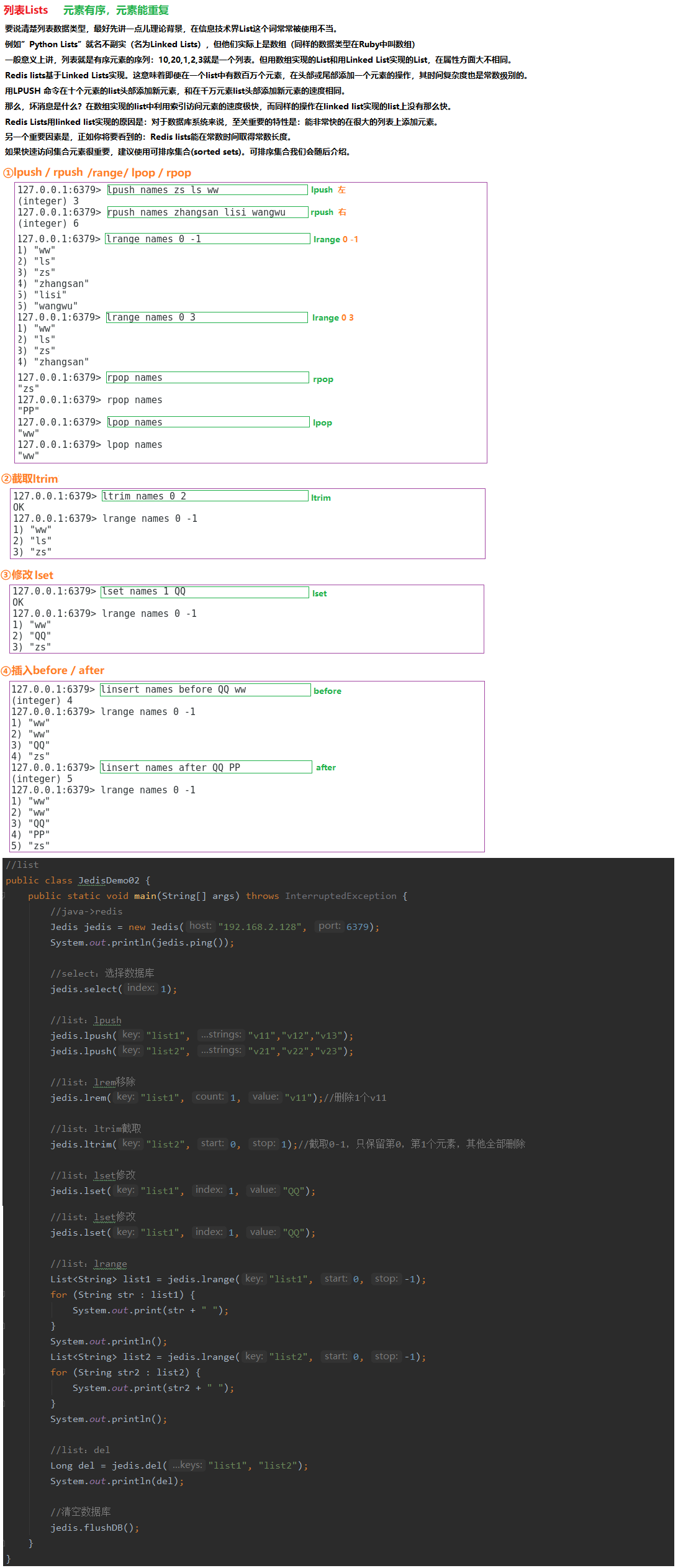
2.3.2 列表Lists
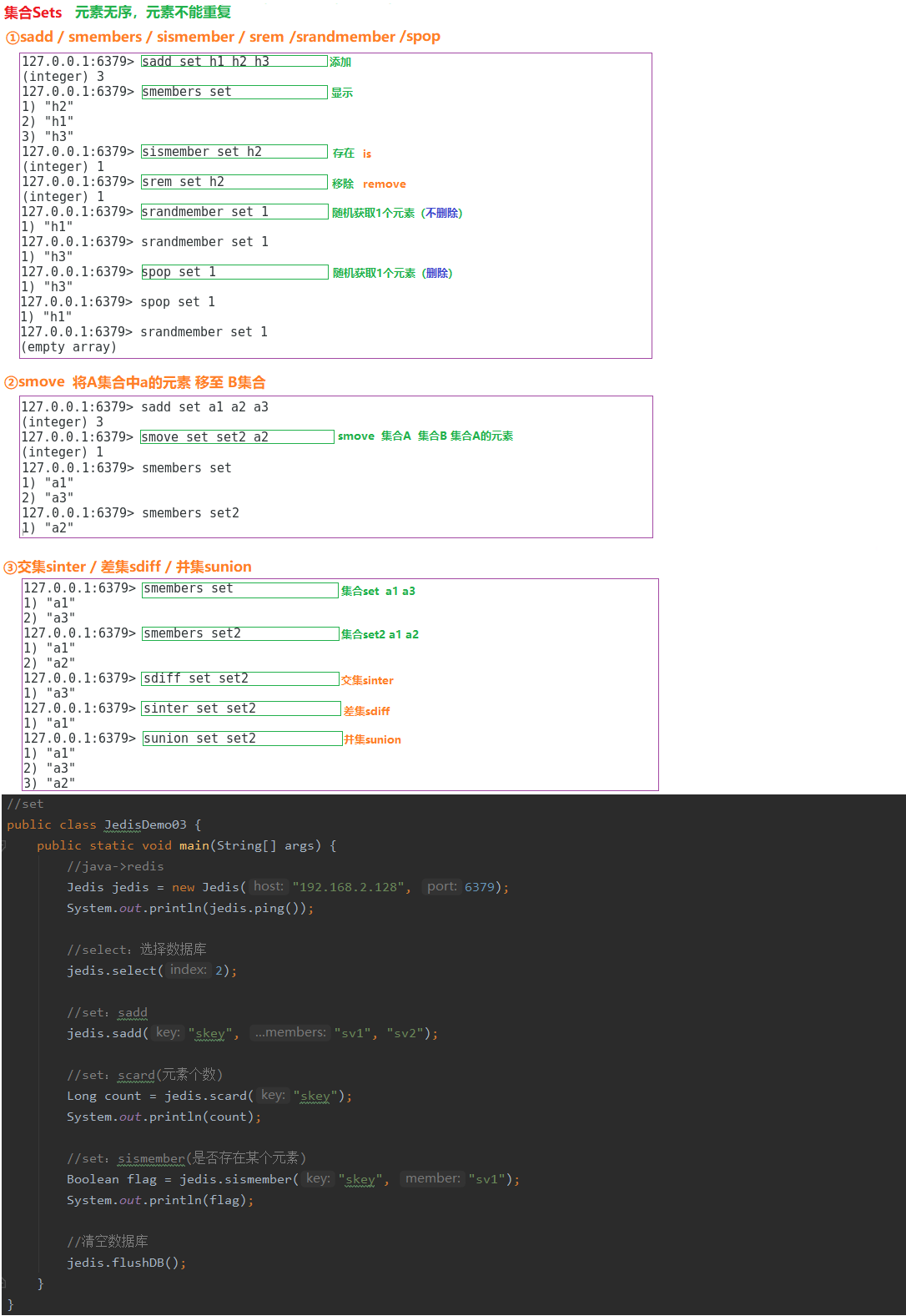
2.3.3 无序集合Sets
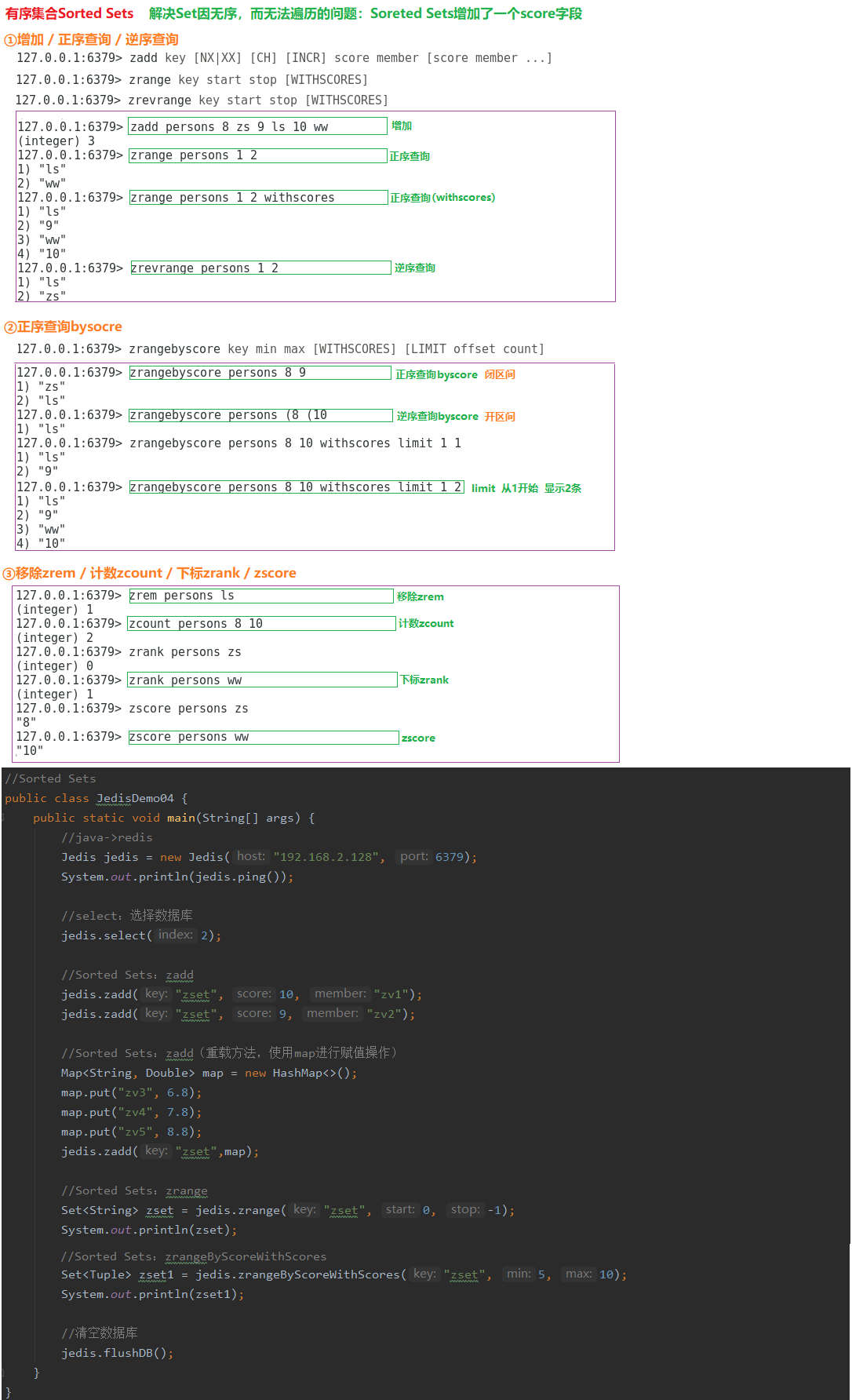
01.set和zset有什么区别?
set:
集合中的元素是无序、不可重复的,一个集合最多能存储232-1个元素;
集合除了支持对元素的增删改查之外,还支持对多个集合取交集、并集、差集。
zset:
有序集合保留了集合元素不能重复的特点;
有序集合会给每个元素设置一个分数,并以此作为排序的依据;
有序集合不能包含相同的元素,但是不同元素的分数可以相同。
02.说说Redis中List结构的相关操作
列表是线性有序的数据结构,它内部的元素是可以重复的,并且一个列表最多能存储2^32-1个元素。列表包含如下的常用命令:
lpush/rpush:从列表的左侧/右侧添加数据;
lrange:指定索引范围,并返回这个范围内的数据;
lindex:返回指定索引处的数据;
lpop/rpop:从列表的左侧/右侧弹出一个数据;
blpop/brpop:从列表的左侧/右侧弹出一个数据,若列表为空则进入阻塞状态。
2.3.4 有序集合Sorted Sets
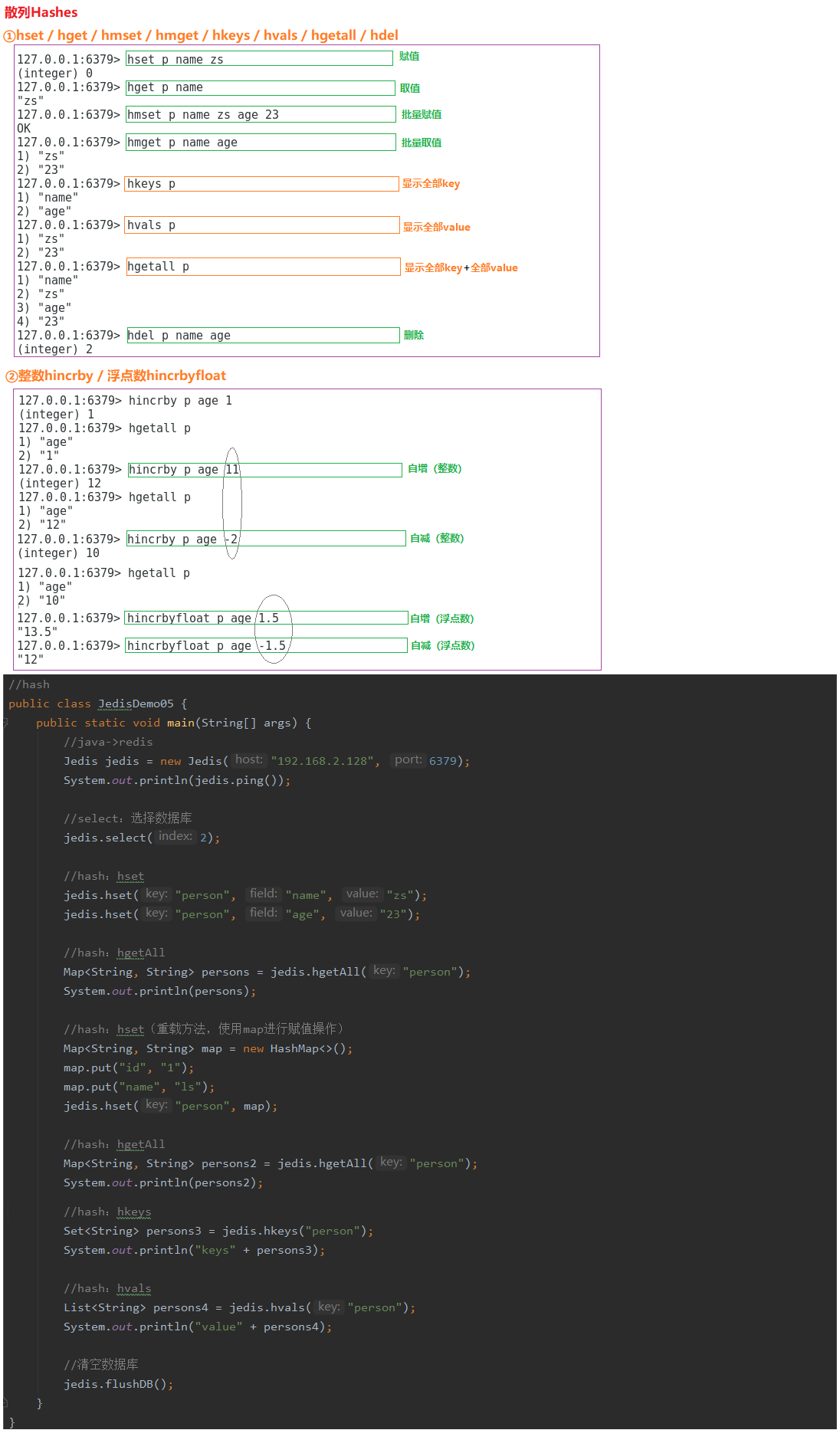
2.3.5 散列Hashes
2.4 Redis存储/读取爬虫数据
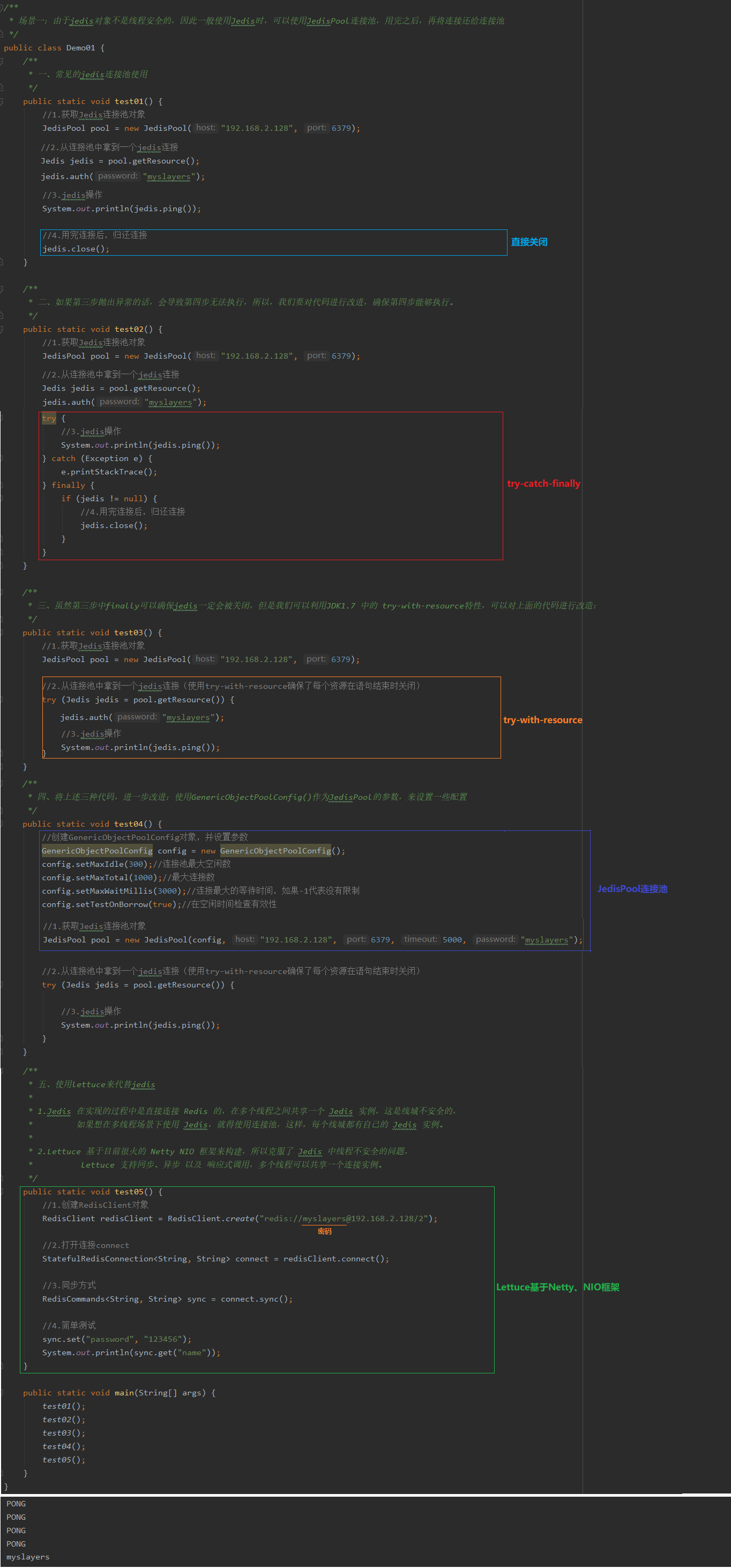
2.5 JedisPool连接池
<!--chapter01:Jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<!--chapter01:Lettuce-->
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.2.2.RELEASE</version>
</dependency>
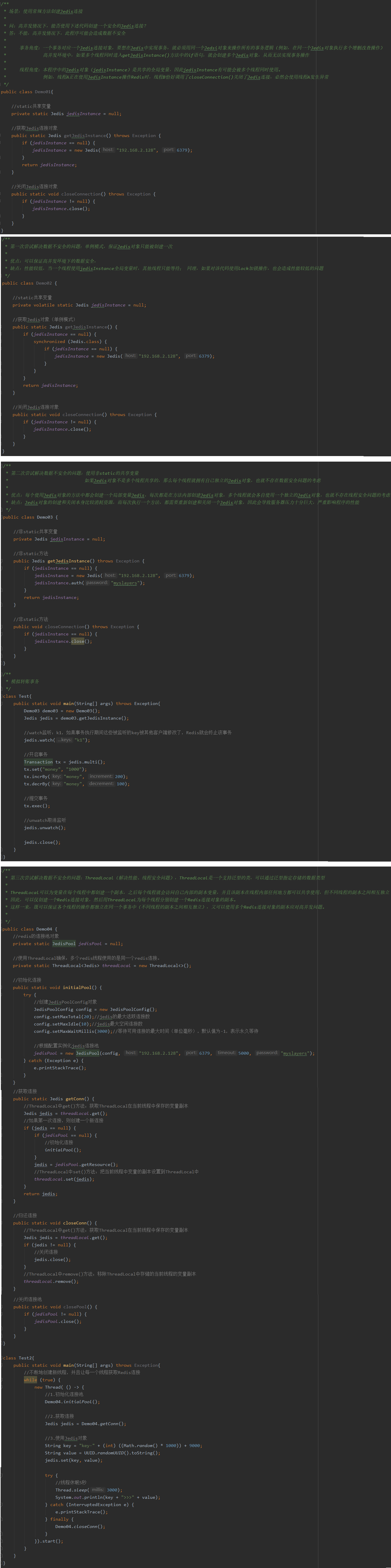
2.6 ThreadLocal高并发
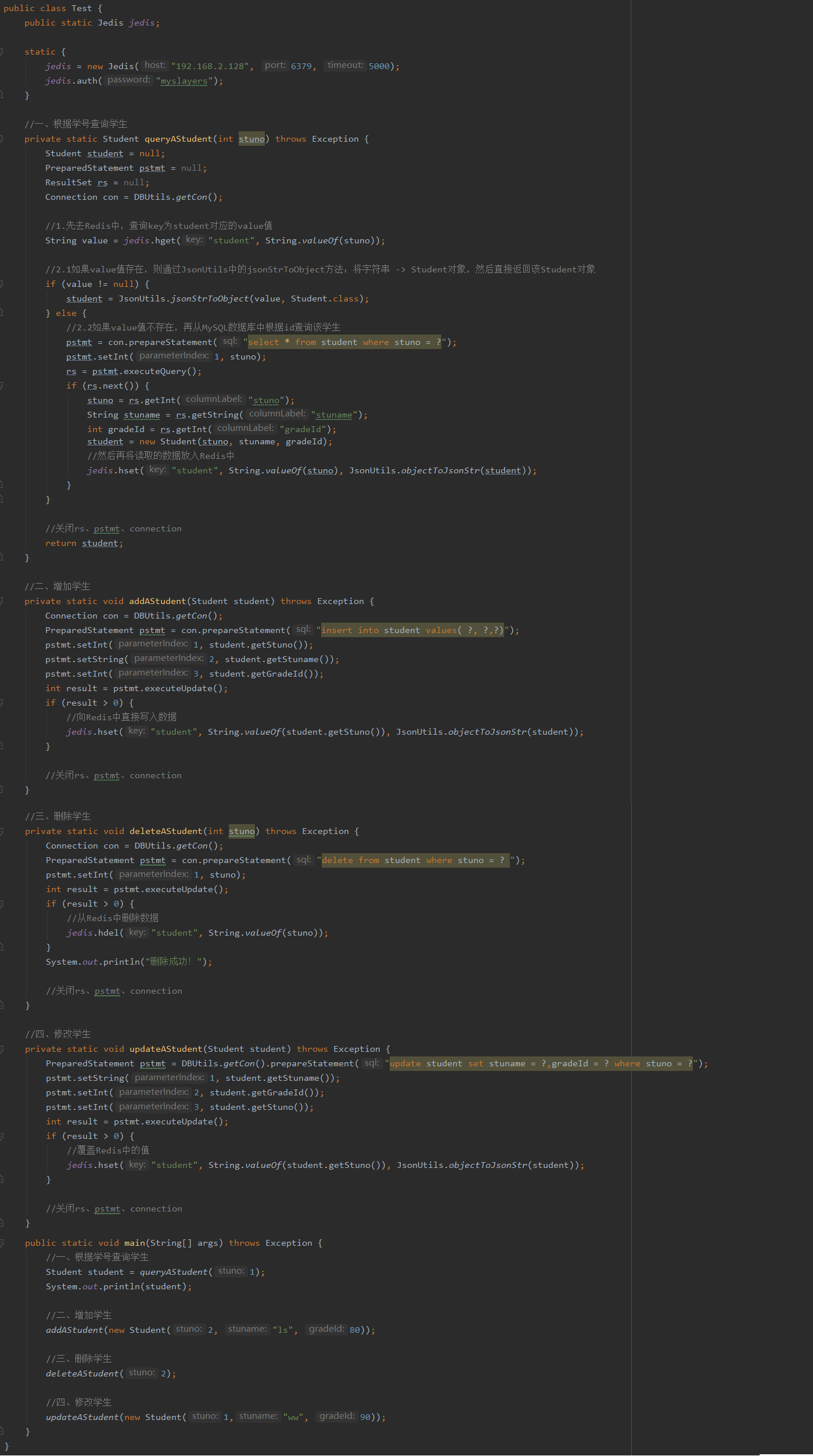
2.7 MySQL高速缓存
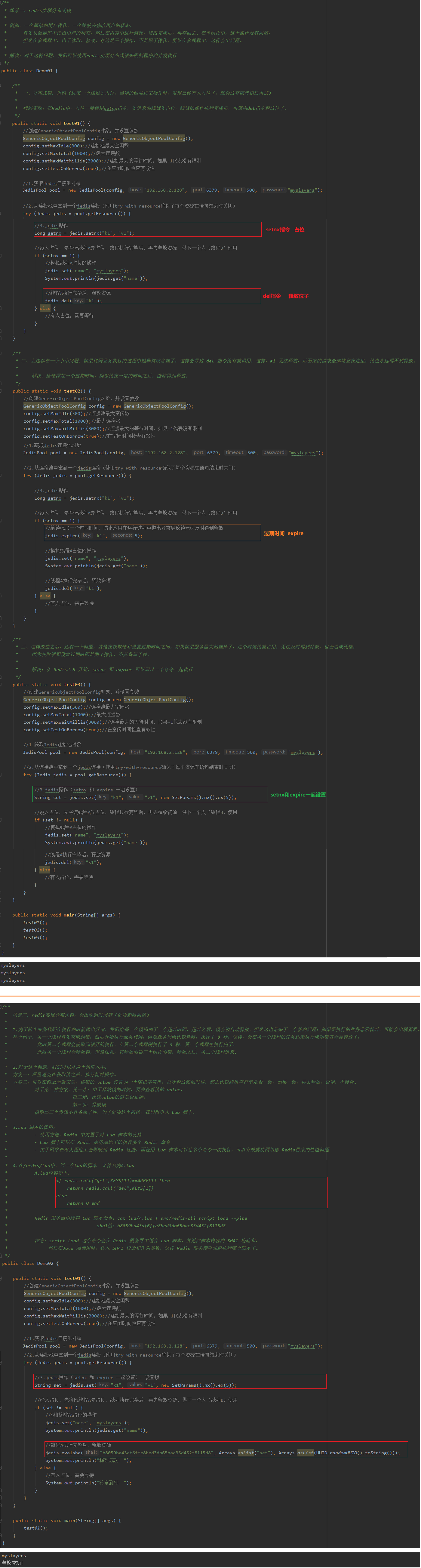
3 Redis之分布式锁
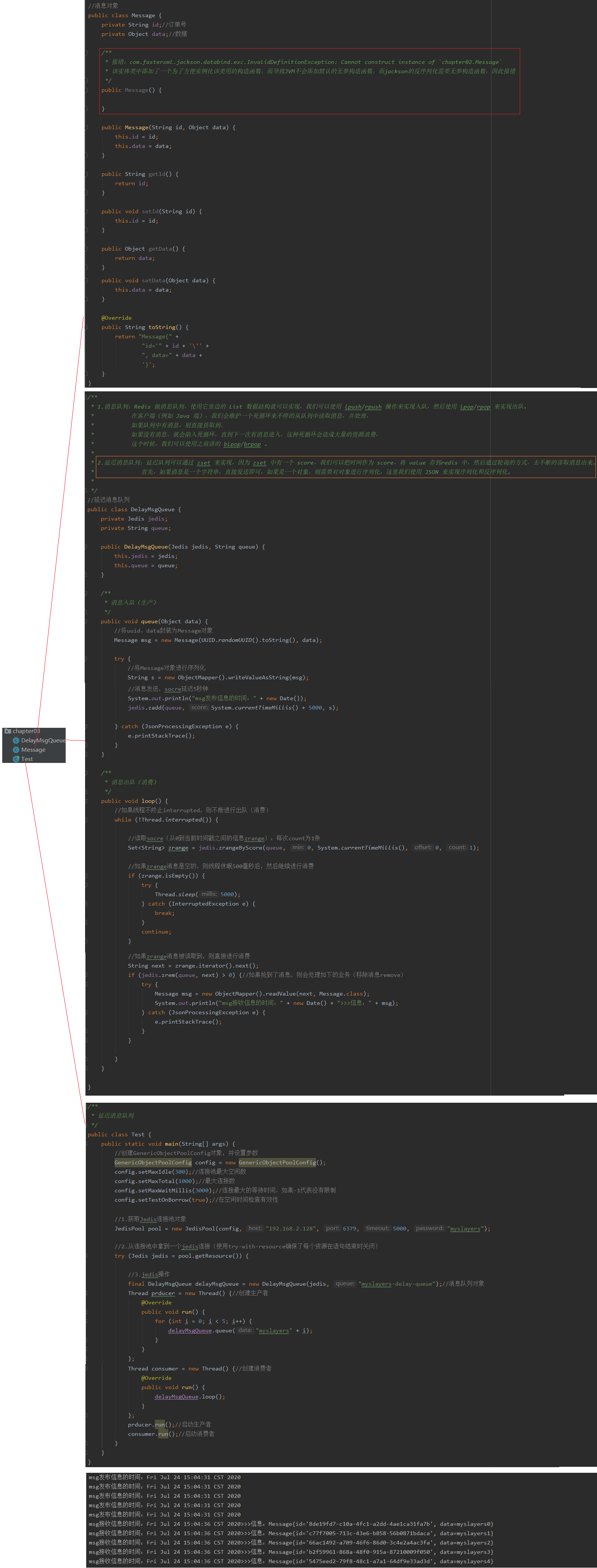
4 Redis之延迟消息队列
<!--chapter03:Json依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.3</version>
</dependency>
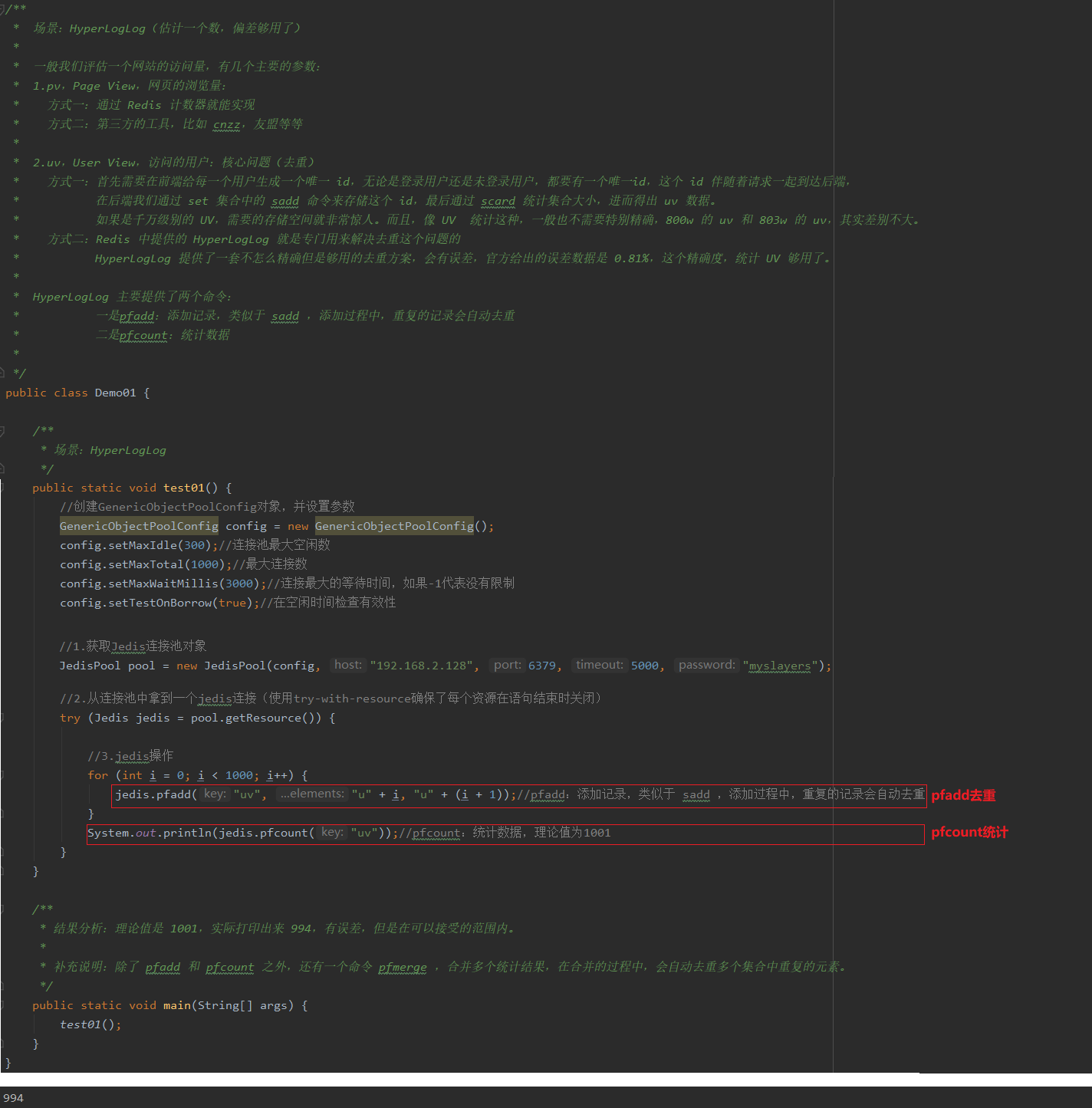
5 Redis之HyperLogLog
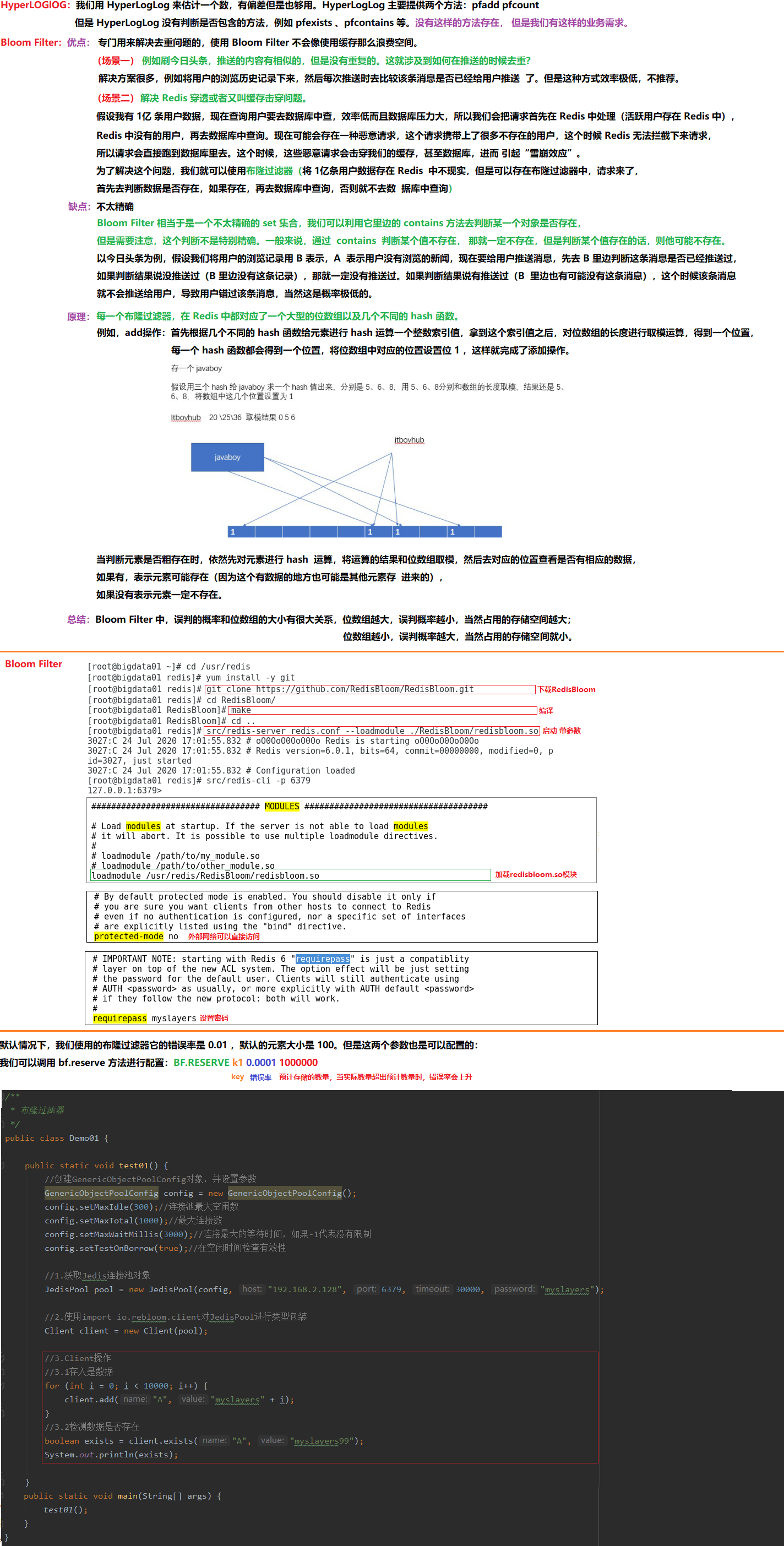
6 Redis之BloomFilter
一、Bloom Filter安装
1.打开目录
cd /user/redis
2.下载
yum install -y git
git clone https://github.com/RedisBloom/RedisBloom.git
3.编译
cd RedisBloom/
make
4.启动
cd ..
src/redis-server redis.conf --loadmodule ./RedisBloom/redisbloom.so
5.可以将加载模块配置到redis.conf
loadmodule /usr/redis/RedisBloom/redisbloom.so
二、Bloom Filter方法
1.添加
bf.add --添加
bf.madd --批量添加
2.判断是否存在
bf.exists --判断是否存在
bf.mexists --批量判断
三、Bloom Filter依赖
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.2.0</version>
</dependency>
四、BF.RESERVE命令
BF.RESERVE k1 0.0001 1000000 --布隆过滤器的错误率、默认元素大小
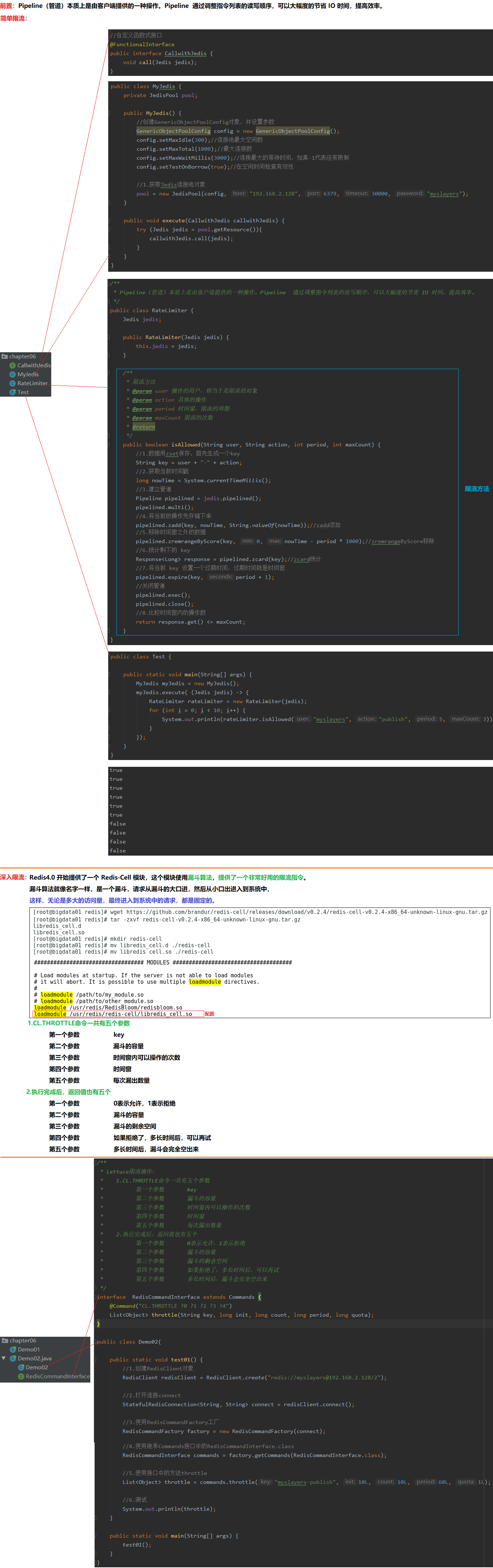
7 Redis之Cell
漏斗算法 https://github.com/brandur/redis-cell
一、Redis-Cell模块
1.打开目录
cd /user/redis
2.下载
wget https://github.com/brandur/redis-cell/releases/download/v0.2.4/redis-cell-v0.2.4-x86_64-unknown-linux-gnu.tar.gz
tar -zxvf redis-cell-v0.2.4-x86_64-unknown-linux-gnu.tar.gz
3.移动文件
mkdir redis-cell
mv libredis_cell.d ./redis-cell
mv libredis_cell.so ./redis-cell
4.将加载模块配置到redis.conf
loadmodule /usr/redis/redis-cell/libredis_cell.so
5.启动
src/redis-server redis.conf
src/redis-server redis.conf --loadmodule ./redis-cell/libredis_cell.so
二、CL.THROTTLE命令
1.CL.THROTTLE命令一共有五个参数
第一个参数 key
第二个参数 漏斗的容量
第三个参数 时间窗内可以操作的次数
第四个参数 时间窗
第五个参数 每次漏出数量
2.执行完成后,返回值也有五个
第一个参数 0表示允许,1表示拒绝
第二个参数 漏斗的容量
第三个参数 漏斗的剩余空间
第四个参数 如果拒绝了,多长时间后,可以再试
第五个参数 多长时间后,漏斗会完全空出来
8 Redis之Geo
Geo模块
a.输入两个地址
GEOADD city 116.3980007200 39.9053908600 beijing
GEOADD city 114.0592002900 22.5536230800 shenzhen
b.查看两个地址之间的距离
GEODIST city beijing shenzhen km
c.获取元素的位置
GEOPOS city beijing
d.获取元素hash值
GEOHASH city beijing
e.以北京为中心,方圆200km以内的城市找出来3个,按照远近顺序排列,这个命令不会排除北京
GEORADIUSBYMEMBER city beijing 200 km count 3 asc
f.根据经纬度来查询(将member换成对应的经纬度)
GEORADIUS city 116.3980007200 39.9053908600 2000 km withdist withhash withcoord count 4 desc
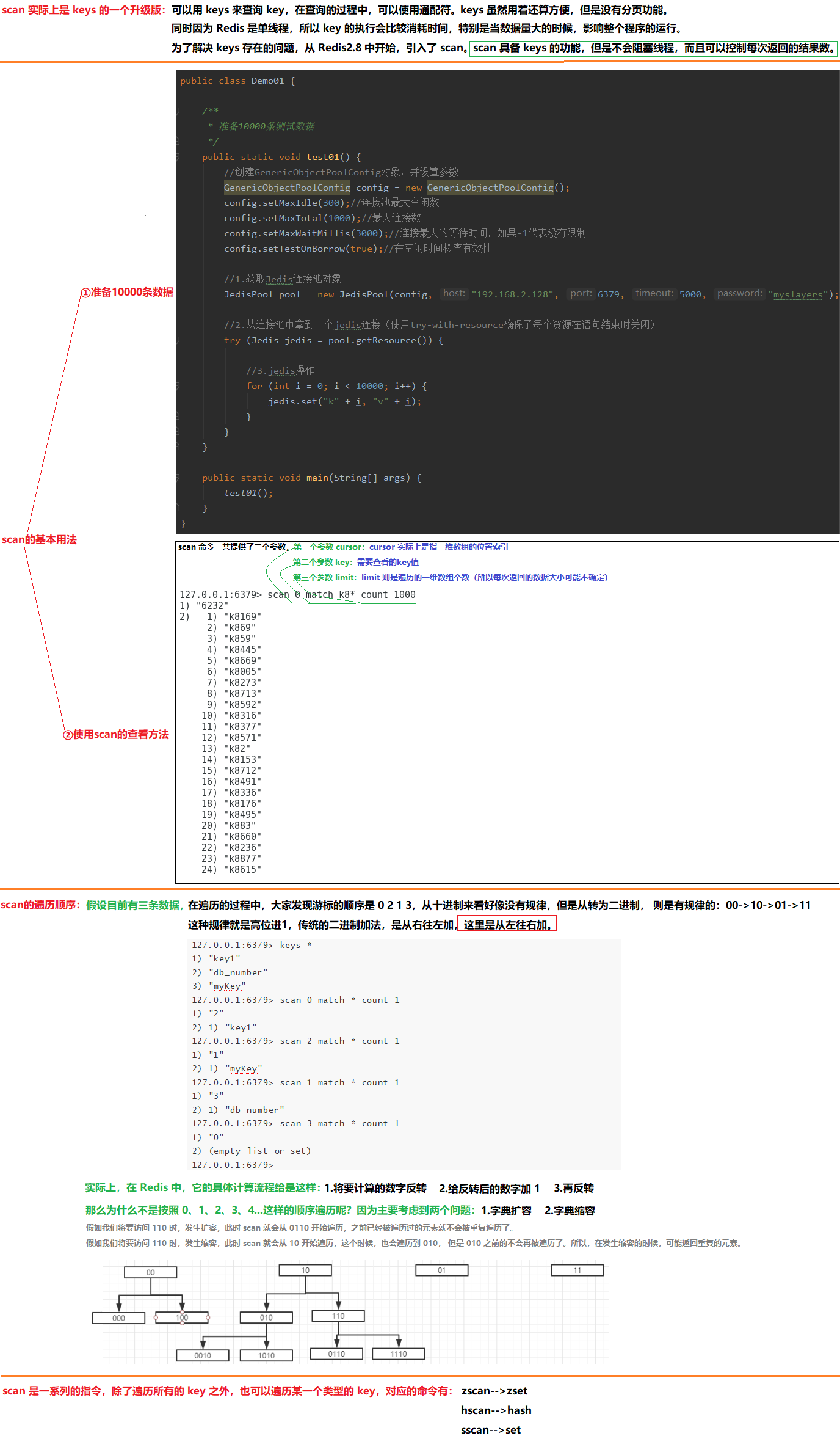
9 Redis之Scan
10 Redis之高并发
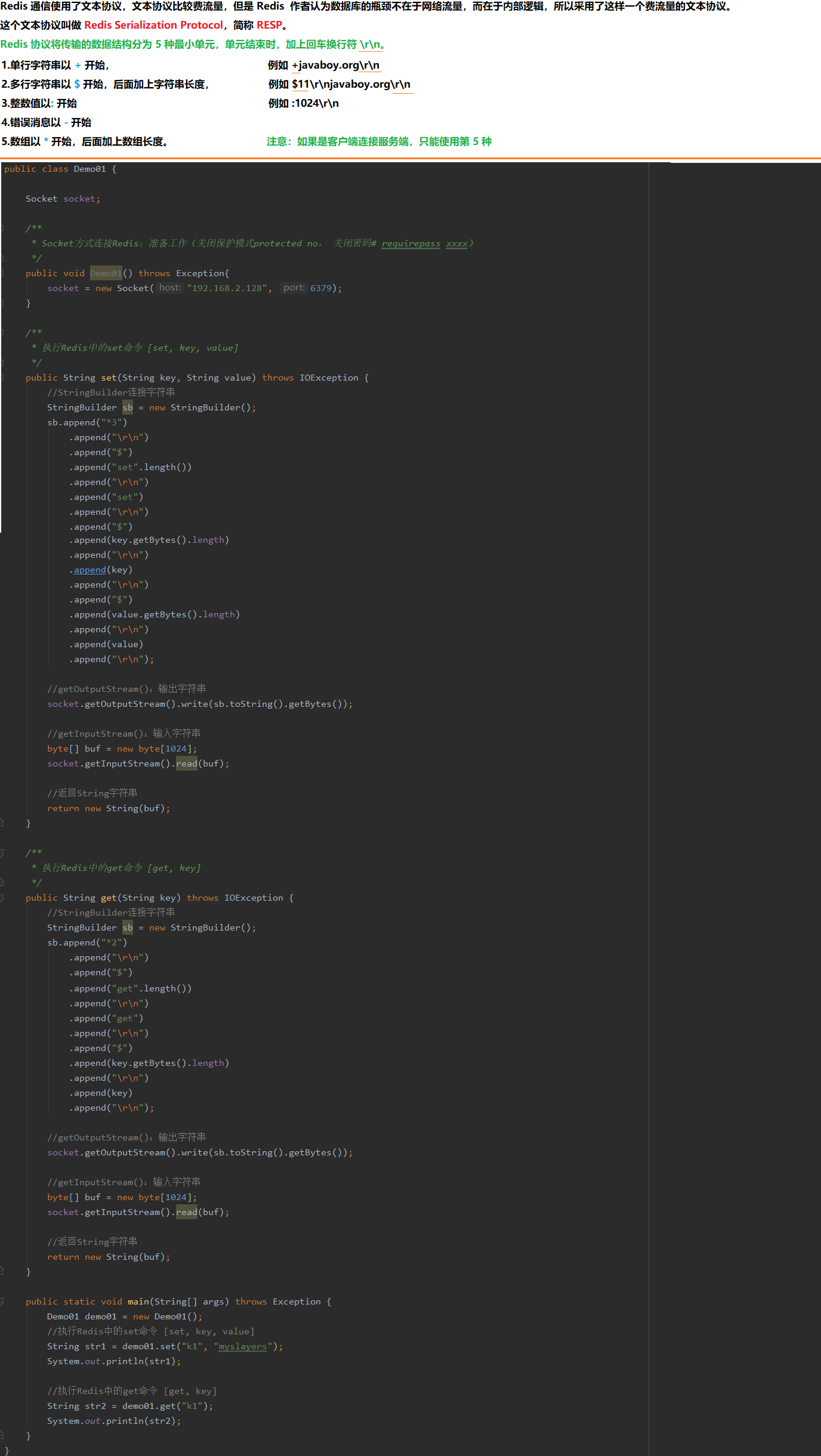
11 Redis之通信协议
12 Redis之持久化
00.什么是Redis持久化?
持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 的持久化机制是什么?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
01.RDB(Redis DataBase)
a.redis.conf中SNAPSHOTTING(默认开启)
# 表示快照的频率,可以设置多个备份条件
save 900 1
save 300 10 --300秒内进行了10次写操作,那么在第300秒时刻,会将内存数据同步到硬盘文件
save 60 10000
# 快照最后一次备份数据失败后,是否继续处理客户端的写命令来接收数据,默认yes,推荐yes
stop-writes-on-bgsave-error yes
# 是否对快照文件进行压缩,默认yes,但会消耗CPU
rdbcompression yes
# 是否对备份文件使用CRC64算法进行数据校验,默认yes,但校验会增加约10%的性能消耗
rdbchecksum yes
# 表示生成的快照文件名,默认dump.rdb
dbfilename dump.rdb
# 表示生成的快照文件位置
dir ./
b.手动备份
save --将当前内存的数据以RDB文件的形式保存到硬盘中,但此操作会阻塞所有客户端,不建议使用
bgsave --Redis会在后台异步进行备份操作,同时还可以响应客户端请求,并且通过lastsave命令获取最后一次成功备份的时间,用来判断bgsave是否执行成功
c.注意
flushall命令会产生一个新的dump.rdb空文件,因此使用该命令,之前RDB方式备份的数据会被清空
shutdown命令会关闭Redis服务,但也会在关闭之前备份一次RDB数据(产生一个新的dump.rdb文件)
d.停止自动备份
src/redis-cli config set save
02.AOF(Append Only File)
a.redis.conf中APPEND ONLY MODE(默认不开启,需要手动将appendonly no变yes,同时关闭默认快照)
# 开启 aof 配置
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# 备份的时机,下面的配置表示每秒钟备份一次
appendfsync everysec
# 表示 aof 文件在压缩时,是否还继续进行同步操作
no-appendfsync-on-rewrite no
# 表示当目前 aof 文件大小超过上一次重写时的 aof 文件大小的百分之多少的时候,再次进行重写
auto-aof-rewrite-percentage 100
# 如果之前没有重写过,则以启动时的 aof 大小为依据,同时要求 aof 文件至少要大于 64M
auto-aof-rewrite-min-size 64mb
b.为了避免快照备份的影响,将默认快照备份关闭
#save 900 1
#save 300 10
#save 60 10000
c.使用日志
上述配置,每秒钟备份一次
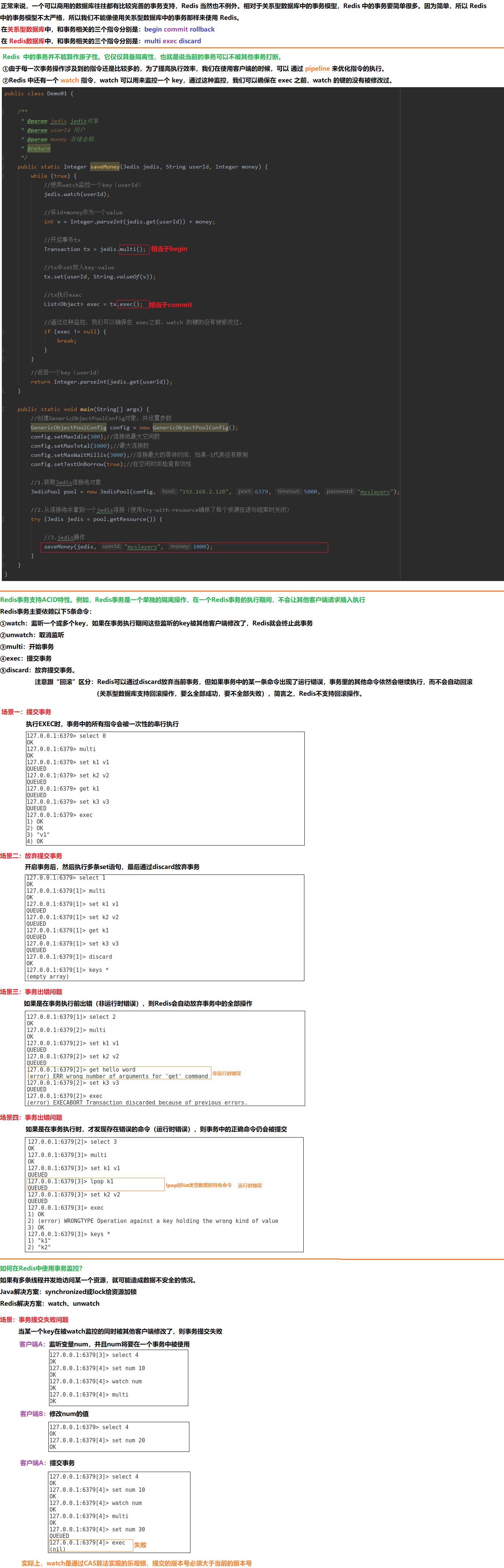
13 Redis之事务
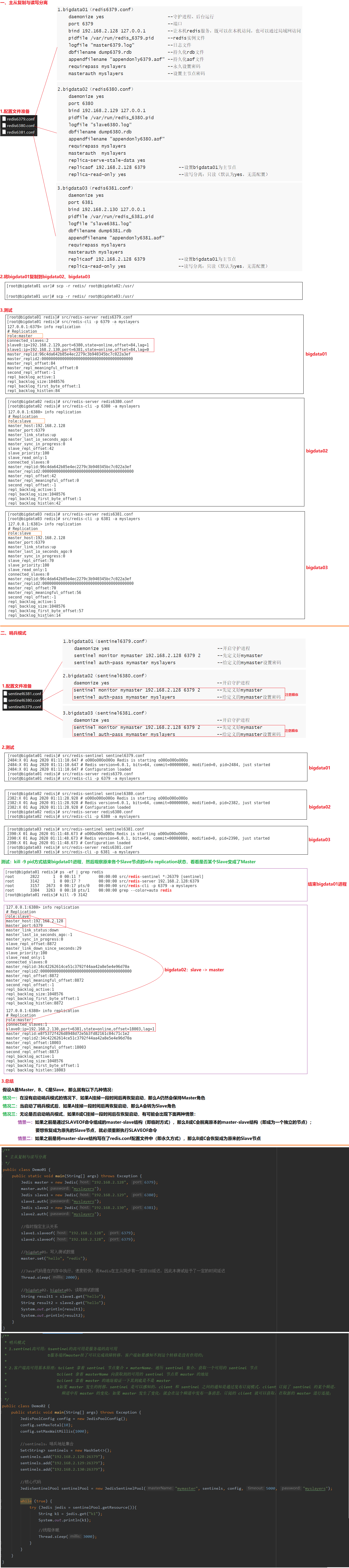
14 Redis之主从同步
01.Redis支持三种集群方案
主从复制模式
Sentinel(哨兵)模式
Cluster 模式
02.主从复制机制的目的有两个
一个是读写分离,分担 "master" 的读写压力
一个是方便做容灾恢复
03.Sentinel哨兵模式
哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例。
通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器;
当哨兵监测到 master 宕机,会自动将 slave 切换成 master ,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机;
04.Cluster模式
根据官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。
-------------------------------------------------------------------------------------------------------------
一、主从复制与读写分离
1.bigdata01(redis6379.conf)
daemonize yes --守护进程、后台运行
port 6379 --端口
bind 192.168.2.128 127.0.0.1 --让本机redis服务,既可以在本机访问,也可以通过局域网访问
pidfile /var/run/redis_6379.pid --redis实例文件
logfile "master6379.log" --日志文件
dbfilename dump6379.rdb --持久化rdb文件
appendfilename "appendonly6379.aof" --持久化aof文件
requirepass myslayers --永久设置密码
masterauth myslayers --设置主节点密码
2.bigdata02(redis6380.conf)
daemonize yes
port 6380
bind 192.168.2.129 127.0.0.1
pidfile /var/run/redis_6380.pid
logfile "slave6380.log"
dbfilename dump6380.rdb
appendfilename "appendonly6380.aof"
requirepass myslayers
masterauth myslayers
replica-serve-stale-data yes
replicaof 192.168.2.128 6379 --设置bigdata01为主节点
replica-read-only yes --读写分离:只读(默认为yes,无需配置)
3.bigdata03(redis6381.conf)
daemonize yes
port 6381
bind 192.168.2.130 127.0.0.1
pidfile /var/run/redis_6381.pid
logfile "slave6381.log"
dbfilename dump6381.rdb
appendfilename "appendonly6381.aof"
requirepass myslayers
masterauth myslayers
replicaof 192.168.2.128 6379 --设置bigdata01为主节点
replica-read-only yes --读写分离:只读(默认为yes,无需配置)
4.将bigdata01复制到bigdata02、bigdata03
scp -r redis/ root@bigdata02:/usr/
scp -r redis/ root@bigdata03:/usr/
5.测试
cd /usr/redis
src/redis-server redis6379.conf
src/redis-cli -p 6379 -a myslayers
info replication --打印信息
src/redis-server redis6380.conf
src/redis-cli -p 6380 -a myslayers
info replication --打印信息
src/redis-server redis6381.conf
src/redis-cli -p 6381 -a myslayers
info replication --打印信息
ps -ef | grep redis
kill -9 pid
6.登录客户端,命令行配置
a.设置主从关系(临时设置)
SLAVEOF 192.168.2.129 6380
b.将使得这个从属服务器关闭复制功能,从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃
SLAVEOF NO ONE
二、哨兵模式
1.bigdata01(sentinel6379.conf)
daemonize yes --开启守护进程
sentinel monitor mymaster 192.168.2.128 6379 2 --先定义好mymaster
sentinel auth-pass mymaster myslayers --给定义的mymaster设置密码
2.bigdata02(sentinel6380.conf)
daemonize yes --开启守护进程
sentinel monitor mymaster 192.168.2.128 6379 2 --先定义好mymaster
sentinel auth-pass mymaster myslayers --给定义的mymaster设置密码
3.bigdata03(sentinel6381.conf)
daemonize yes --开启守护进程
sentinel monitor mymaster 192.168.2.128 6379 2 --先定义好mymaster
sentinel auth-pass mymaster myslayers --给定义的mymaster设置密码
4.测试
cd /usr/redis
src/redis-sentinel sentinel6379.conf --哨兵服务1
src/redis-server redis6379.conf --Redis服务1
src/redis-cli -p 6379 -a myslayers
info replication --打印信息
src/redis-sentinel sentinel6380.conf --哨兵服务2
src/redis-server redis6380.conf --Redis服务2
src/redis-cli -p 6380 -a myslayers
info replication --打印信息
src/redis-sentinel sentinel6381.conf --哨兵服务3
src/redis-server redis6381.conf --Redis服务3
src/redis-cli -p 6381 -a myslayers
info replication --打印信息
ps -ef | grep redis
kill -9 pid
测试:kill -9 pid方式结束bigdata01进程,然后观察原来各个Slave节点的info replication状态,看看是否某个Slave变成了Master
5.总结
假设A是Master,B、C是Slave,那么就有以下几种情况:
情况一:在没有启动哨兵模式的情况下,如果A挂掉一段时间后再恢复启动,那么A仍然会保持Master角色
情况二:当启动了哨兵模式后,如果A挂掉一段时间后再恢复启动,那么A会转为Slave角色
情况三:无论是否启动哨兵模式,如果B或C挂掉一段时间后在恢复启动,有可能会出现下面两种情景:
情景一:如果之前是通过SLAVEOF命令组成的master-slave结构(即临时方式),那么B或C会脱离原本的master-slave结构(即成为一个独立的节点);要想恢复成为原先的Slave节点,就必须重新执行SLAVEOF命令
情景二:如果之前是将master-slave结构写在了redis.conf配置文件中(即永久方式),那么B或C会恢复成为原来的Slave节点
15 Redis之集群
一、搭建集群
1.redis7001.conf
daemonize yes --守护进程、后台运行
port 7001 --端口
bind 192.168.2.128 127.0.0.1 --让本机redis服务,既可以在本机访问,也可以通过局域网访问
pidfile /var/run/redis_7001.pid --redis实例文件
logfile "redis_7001.log" --日志文件
dbfilename "dump_7001.rdb" --持久化rdb文件
appendfilename "appendonly_7001.aof"--持久化aof文件
requirepass myslayers --永久设置密码
masterauth myslayers --设置主节点密码
cluster-enabled yes --开启集群功能
cluster-config-file nodes-7001.conf --集群配置文件,节点自动维护
cluster-require-full-coverage no --集群能够运行不需要集群中所有节点都成功
2.redis7002.conf
daemonize yes
port 7002
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7002.pid
logfile "redis_7002.log"
dbfilename "dump_7002.rdb"
appendfilename "appendonly_7002.aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7002.conf
cluster-require-full-coverage no
3.redis7003.conf
daemonize yes
port 7003
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7003.pid
logfile "redis_7003.log"
dbfilename "dump_7003.rdb"
appendfilename "appendonly_7003.aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7003.conf
cluster-require-full-coverage no
4.redis7004.conf
daemonize yes
port 7004
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7004.pid
logfile "redis_7004.log"
dbfilename "dump_7004.rdb"
appendfilename "appendonly_7004.aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7004.conf
cluster-require-full-coverage no
5.redis7005.conf
daemonize yes
port 7005
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7005.pid
logfile "redis_7005.log"
dbfilename "dump_7005.rdb"
appendfilename "appendonly_7005.aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7005.conf
cluster-require-full-coverage no
6.redis7006.conf
daemonize yes
port 7006
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7006.pid
logfile "redis_7006.log"
dbfilename "dump_7006.rdb"
appendfilename "appendonly_7006.aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7006.conf
cluster-require-full-coverage no
7.启动服务
cd /usr/redis
src/redis-server redis7001.conf --Redis服务1
src/redis-server redis7002.conf --Redis服务2
src/redis-server redis7003.conf --Redis服务3
src/redis-server redis7004.conf --Redis服务4
src/redis-server redis7005.conf --Redis服务5
src/redis-server redis7006.conf --Redis服务6
ps -ef | grep redis
kill -9 pid
8.建立各个节点通信(前三个:主节点,后三个:从节点)
src/redis-cli -a myslayers --cluster create 192.168.2.128:7001 192.168.2.128:7002 192.168.2.128:7003 192.168.2.128:7004 192.168.2.128:7005 192.168.2.128:7006 --cluster-replicas 1
9.验证
src/redis-cli -p 7001 -a myslayers -c --参数c,表示以集群方式连接
127.0.0.1:7001> cluster info
127.0.0.1:7001> cluster nodes
二、集群扩容
1.redis7007.conf(主节点)
daemonize yes
port 7007
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7007.pid
logfile "redis_7007log"
dbfilename "dump_7007rdb"
appendfilename "appendonly_7007aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7007conf
cluster-require-full-coverage no
2.redis7008.conf(从节点)
daemonize yes
port 7008
bind 192.168.2.128 127.0.0.1
pidfile /var/run/redis_7008.pid
logfile "redis_7008log"
dbfilename "dump_7008rdb"
appendfilename "appendonly_7008aof"
requirepass myslayers
masterauth myslayers
cluster-enabled yes
cluster-config-file nodes-7008conf
cluster-require-full-coverage no
3.启动服务(扩容)
cd /usr/redis
src/redis-server redis7007.conf --Redis服务7(新增主节点7007)
src/redis-server redis7008.conf --Redis服务8(新增从节点7008)
4.将新增主节点、从节点加入集群中
src/redis-cli -p 7001 -a myslayers --cluster add-node 192.168.2.128:7007 192.168.2.128:7001 --Redis服务7(新增主节点7007)
src/redis-cli -p 7001 -a myslayers --cluster add-node 192.168.2.128:7008 192.168.2.128:7001 --Redis服务8(新增从节点7008)
5.为新增主节点分配槽位
src/redis-cli -p 7001 -a myslayers --cluster reshard 192.168.2.128:7001 --重新分配
How many slots do you want to move (from 1 to 16384)? 2000 --分配槽位
What is the receiving node ID? e198ea4b31f8911a08b6b5a443b8fb740943cdc1 --主节点nodeId
Source node #1: all --所有master节点都拿出一部分槽位分配给新增节点
6.建立主从关系
src/redis-cli -p 7008 -a myslayers cluster replicate e198ea4b31f8911a08b6b5a443b8fb740943cdc1 --从节点端口7008 + 主节点nodeId
7.验证
src/redis-cli -p 7001 -a myslayers -c --参数c,表示以集群方式连接
127.0.0.1:7001> cluster info
127.0.0.1:7001> cluster nodes
三、集群收缩
1.迁移待移除节点的槽位(例如,将端口7007的槽位 移除2000 给 端口7001的槽位)
src/redis-cli -p 7001 -a myslayers --cluster reshard --cluster-from e198ea4b31f8911a08b6b5a443b8fb740943cdc1 --cluster-to 4c96c1dd8651fbb7e1ad31e35924936212725fda --cluster-slots 2000 192.168.2.128:7001
2.移除待删除出主从节点
注意:要首先移除从节点,然后再移除主节点,因为如果你先移除主节点,会触发集群的故障转移。所以,我们应该先移除 7008 从节点,然后在移除 7007 主节点。
删除 7008 从节点:
src/redis-cli -p 7001 -a myslayers --cluster del-node 192.168.2.128:7008 98a6342e8ab1c1c988081684cbe20d993fe7b156
删除 7007 主节点:
src/redis-cli -p 7001 -a myslayers --cluster del-node 192.168.2.128:7007 e198ea4b31f8911a08b6b5a443b8fb740943cdc1