1 MongoDB介绍
1.1 定义
01.介绍1
a.概念
MongoDB 是一个文档型数据库,数据以类似 JSON 的文档形式存储。
MongoDB 的设计理念是为了应对大数据量、高性能和灵活性需求。
MongoDB使用集合(Collections)来组织文档(Documents),每个文档都是由键值对组成的。
MongoDB是一个基于分布式文件存储的数据库
-----------------------------------------------------------------------------------------------------
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组
-----------------------------------------------------------------------------------------------------
由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引
b.主要特点
数据是 JSON 结构
支持结构化、半结构化数据模型
可以动态响应结构变化
通过副本机制提供高可用
通过分片提供扩容能力
-----------------------------------------------------------------------------------------------------
文档导向的存储:MongoDB 是一个面向文档的数据库,它以 JSON-like 的格式存储数据,使得数据结构更加灵活和丰富。
索引优化查询:MongoDB 允许用户为文档中的任意属性创建索引,例如 FirstName 和 Address,从而提高查询效率和排序性能。
数据镜像与扩展性:通过本地或网络创建数据的副本,MongoDB 实现了强大的数据冗余和扩展能力。
水平扩展与分片:面对增加的负载,MongoDB 可以通过分片技术将数据分布到计算机网络中的其他节点上,实现水平扩展。
强大的查询语言:MongoDB 使用 JSON 格式的查询语法,支持复杂的查询表达式,包括对内嵌对象和数组的查询。
数据更新:利用 update() 命令,MongoDB 能够替换整个文档或更新指定的数据字段,提供了灵活的数据更新方式。
MapReduce 批量处理:MongoDB 的 MapReduce 功能专为大规模数据处理和聚合操作设计,通过 Map 函数的 emit(key, value) 调用和 Reduce 函数的逻辑处理,实现高效的数据汇总。
MapReduce 脚本编写:Map 和 Reduce 函数使用 JavaScript 编写,可以通过 db.runCommand 或 mapreduce 命令在 MongoDB 中执行。
GridFS 大文件存储:GridFS 是 MongoDB 内置的功能,用于存储和检索大于 BSON 文档大小限制的文件,如图片和视频。
服务端脚本执行:MongoDB 允许在服务端执行 JavaScript 脚本,提供了直接在服务端执行或存储函数定义以供后续调用的能力。
多语言支持:MongoDB 提供了对多种编程语言的支持,包括但不限于 RUBY、PYTHON、JAVA、C++、PHP 和 C#。
安装简单:MongoDB 的安装过程简单直观,便于用户快速部署和使用。
c.业务应用场景
传统的关系型数据库(如MySQL),在数据操作的三高需求以及应对Web2.0的网站需求面前,显得力不从心,而 MongoDB可应对“三高“需求
High performance:对数据库高并发读写的需求
Huge Storage:对海量数据的高效率存储和访问的需求
High Scalability && High Availability:对数据库的高可扩展性和高可用性的需求
-----------------------------------------------------------------------------------------------------
应用不需要事务及复杂join支持
新应用,需求会变,数据模型无法确定,想快速迭代开发
应用需要2000-3000以上的读写QPS(更高也可以)
应用需要TB甚至PB级别数据存储
应用要求存储的数据不丢失
应用需要99.999%高可用
应用需要大量的地理位置查询、文本查
-----------------------------------------------------------------------------------------------------
社交场景,使用 MongoDB存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
游戏场景,使用 MongoDB存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
物流场景,使用 MongoDB存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来
物联网场景,使用 MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
视频直播,使用 MongoDB存储用户信息、点赞互动信息等。
-----------------------------------------------------------------------------------------------------
这些应用场景中,数据操作方面的共同特点是:
(1)数据量大
(2)写入操作频繁(读写都很频繁)
(3)价值较低的数据,对事务性要求不高
02.介绍2
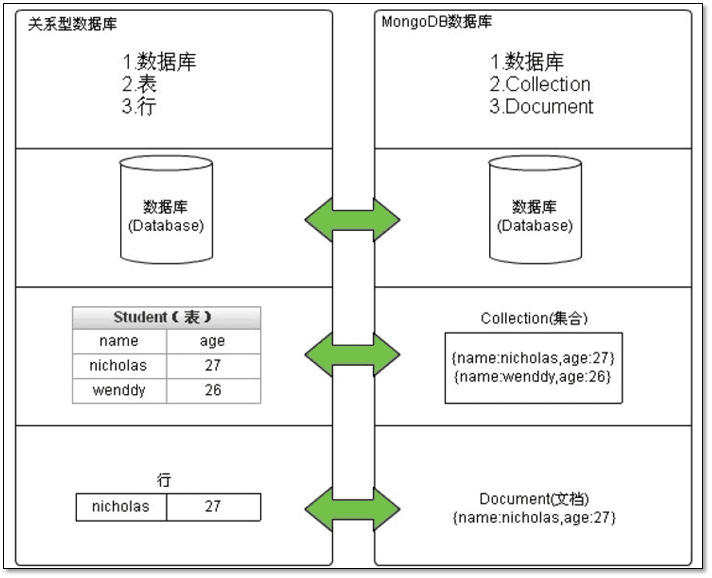
a.对比
MySQL MongoDB
行 文档(document)
表 集合(collections)
数据库 数据库(databases)
-----------------------------------------------------------------------------------------------------
SQL MongoDB 说明
database database 数据库
table collection 数据库表/集合
row document 数据记录行/文档
column field 数据字段/域
index index 索引
primary key primary key 主键,默认String,因此在插入数字时,可以使用内置的函数NumberInt将数字进行转换自动生成唯一标识符_id
table joins 嵌入文档 表连接,MongoDB通过嵌入式文档来替代多表连接
b.术语
文档(Document):MongoDB 的基本数据单元,通常是一个 JSON-like 的结构,可以包含多种数据类型。
集合(Collection):类似于关系型数据库中的表,集合是一组文档的容器。在 MongoDB 中,一个集合中的文档不需要有一个固定的模式。
数据库(Database):包含一个或多个集合的 MongoDB 实例。
BSON:Binary JSON 的缩写,是 MongoDB 用来存储和传输文档的二进制形式的 JSON。
索引(Index):用于优化查询性能的数据结构,可以基于集合中的一个或多个字段创建索引。
分片(Sharding):一种分布数据到多个服务器(称为分片)的方法,用于处理大数据集和高吞吐量应用。
副本集(Replica Set):一组维护相同数据集的 MongoDB 服务器,提供数据的冗余备份和高可用性。
主节点(Primary):副本集中负责处理所有写入操作的服务器。
从节点(Secondary):副本集中的服务器,用于读取数据和在主节点故障时接管为主节点。
MongoDB Shell:MongoDB 提供的命令行界面,用于与 MongoDB 实例交互。
聚合框架(Aggregation Framework):用于执行复杂的数据处理和聚合操作的一系列操作。
Map-Reduce:一种编程模型,用于处理大量数据集的并行计算。
GridFS:用于存储和检索大于 BSON 文档大小限制的文件的规范。
ObjectId:MongoDB 为每个文档自动生成的唯一标识符。
CRUD 操作:创建(Create)、读取(Read)、更新(Update)、删除(Delete)操作。
事务(Transactions):从 MongoDB 4.0 开始支持,允许一组操作作为一个原子单元执行。
操作符(Operators):用于查询和更新文档的特殊字段。
连接(Join):MongoDB 允许在查询中使用 $lookup 操作符来实现类似 SQL 的连接操作。
TTL(Time-To-Live):可以为集合中的某些字段设置 TTL,以自动删除旧数据。
存储引擎(Storage Engine):MongoDB 用于数据存储和管理的底层技术,如 WiredTiger 和 MongoDB 的旧存储引擎 MMAPv1。
MongoDB Compass:MongoDB 的图形界面工具,用于可视化和管理 MongoDB 数据。
MongoDB Atlas:MongoDB 提供的云服务,允许在云中托管 MongoDB 数据库。
c.元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:dbname.system.*
在 MongoDB 数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),如下:
| 集合命名空间 | 描述 |
|--------------------------|-------------------------|
| dbname.system.namespaces | 列出所有名字空间。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含数据库概要(profile)信息。 |
| dbname.system.users | 列出所有可访问数据库的用户。 |
| dbname.local.sources | 包含复制对端(slave)的服务器信息和状态。 |
对于修改系统集合中的对象有如下限制。
在 system.indexes 插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的 drop index 命令将自动更新相关信息)。system.users 是可修改的。system.profile 是可删除的。
03.最新动态
a.版本
1.x - 支持复制和分片
2.x - 更丰富的数据库功能
3.x - WiredTiger 和周边生态
4.x - 支持分布式事务
7.x - 聚合
b.服务
MongoDB Atlas:用于云中 MongoDB 部署的完全托管服务
MongoDB Enterprise:基于订阅、自我管理的 MongoDB 版本
MongoDB Community:源代码可用、免费使用且可自行管理的 MongoDB 版本
c.MongoDB Atlas Search
Atlas Search 是 MongoDB Atlas 中内置的全文搜索解决方案,为构建基于相关性的应用功能提供了无缝且可扩展的体验。
Atlas Search 基于 Apache Lucene 构建,让用户无需在运行数据库的同时再运行一个单独的搜索系统。
d.Atlas Vector Search
您可以使用 Atlas Vector Search 对 Atlas 中的数据执行向量搜索。当您在集合上定义 Atlas Vector Search 索引时,
可以无缝地将向量数据与其他数据一起索引,然后对索引字段执行向量搜索查询。
Atlas Vector Search 支持各种搜索应用场景,包括语义搜索、混合搜索和生成搜索。
通过将向量嵌入与其他数据一起存储在 Atlas 中,您可以过滤集合中其他字段的语义搜索查询,
并将语义搜索与全文搜索相结合。通过使用 Atlas 作为向量数据库,
您还可以在 AI 应用程序中利用向量搜索并将其与常用的 AI 框架和服务集成。
1.2 安装
01.MongoDB-3.4.24
a.环境变量
C:\software\SQL\MongoDB-3.4.24\bin
b.配置(mongodb.conf)
dbpath=C:\software\MongoDB-3.4.24\data
logpath=C:\software\MongoDB-3.4.24\logs\mongo.log
port=27017
logappend=true
c.服务
mongod --config "C:\software\MongoDB-3.4.24\mongodb.conf" --install --serviceName "MongoDB"
net start MongoDB2
db.version();
d.配置用户
mongo
db.createUser({ user:'root',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'}]});
db.auth('root', '123456')
e.Navicat连接
连接名:MongoDB
连接:Standalone
主机:localhost
端口:27017
验证数据库:test
用户名:root
密码:123456
02.MongoDB-8.0.3
a.位置
C:\Program Files\MongoDB\Server\8.0
b.端口说明
27017 mongod 和 mongos 实例的默认端口。您可以使用 port 或 --port 更改此端口。
27018 使用 --shardsvr 命令行选项运行时 mongod 的默认端口,或配置文件中 clusterRole 设置的 shardsvr 值。
27019 使用 --configsvr 命令行选项运行时 mongod 的默认端口,或配置文件中 clusterRole 设置的 configsvr 值。
27020 mongocryptd 从中侦听消息的默认端口。mongocryptd 与 MongoDB Enterprise Server 一起安装,并支持自动加密操作。
c.查看版本
db.version();
d.配置用户
打开MongoDB Compass
db.createUser({ user:'root',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'}]});
db.auth('root', '123456')
e.配置用户结束,才可以Navicat连接
连接名:MongoDB
连接:Standalone
主机:localhost
端口:27017
验证数据库:test
用户名:root
密码:123456
f.配置用户结束,才可以mongosh连接
d:
cd C:\software\mongosh-2.3.2\bin
mongosh mongodb://localhost:27017
03.MongoDB连接
a.连接
mongo ip:port/数据库名 -u user -p password
mongo -u root -p 123456
mongo 127.0.0.1:27017/test -u root -p 123456
b.命令
show dbs --显示数据库列表
show collections --显示当前数据库中的集合
show users --显示用户
use <db name> --切换当前数据库
db.help() --显示数据库操作命令
db.foo.help() --显示集合操作命令,foo代指当前数据库
db.foo.find() --当前集合数据查找
db.foo.find({a:1}) --当前集合数据查找,条件查询
db.foo.find({a:1},{column:0}) --当前集合数据查找,条件查询
1.3 复制
01.副本和可用性
a.介绍1
副本可以提供冗余并提高数据可用性。在不同数据库服务器上使用多个数据副本,
可以提供一定程度的容错能力,以防止单个数据库服务器宕机时,数据丢失。
b.介绍2
在某些情况下,副本还可以提供更大的读取吞吐量。
因为客户端可以将读取操作发送到不同的服务器。
在不同数据中心中维护数据副本可以提高数据本地性和分布式应用程序的可用性。
您还可以维护其他副本以用于专用目的:例如灾难恢复,报告或备份。
02.MongoDB副本
a.介绍
MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。
一个副本集包含多个数据承载节点和一个仲裁器节点(可选)。
在数据承载节点中,只有一个成员被视为主要节点,而其他节点则被视为次要节点。
b.主节点
主节点负责接收所有写操作。副本集只能有一个主副本,
能够以 { w: "majority" } (opens new window)来确认集群中节点的写操作成功情况;
尽管在某些情况下,另一个 MongoDB 实例可能会暂时认为自己也是主要的。
主节点在其操作日志(即 oplog (opens new window))中记录了对其数据集的所有更改。
c.从节点
从节点复制主节点的操作日志,并将操作应用于其数据集,以便同步主节点的数据。
如果主节点不可用,则符合条件的从节点将选举新的主节点。
d.说明
在某些情况下(例如,有一个主节点和一个从节点,但由于成本限制,禁止添加另一个从节点),
您可以选择将 mongod 实例作为仲裁节点添加到副本集。仲裁节点参加选举但不保存数据(即不提供数据冗余)。
-----------------------------------------------------------------------------------------------------
仲裁节点将永远是仲裁节点。在选举期间,主节点可能会降级成为次节点,而次节点可能会升级成为主节点。
03.异步复制
a.慢操作
从节点复制主节点的操作日志,并将操作异步应用于其数据集。
通过从节点同步主节点的数据集,即使一个或多个成员失败,副本集(MongoDB 集群)也可以继续运行。
-----------------------------------------------------------------------------------------------------
从 4.2 版本开始,副本集的从节点记录慢操作(操作时间比设置的阈值长)的日志条目。
这些慢操作在 REPL (opens new window)组件下的 诊断日志 (opens new window)中记录了日志消息,
并使用了文本 op: <oplog entry> 花费了 <num>ms。这些慢操作日志条目仅取决于慢操作阈值,
而不取决于日志级别(在系统级别或组件级别),配置级别或运行缓慢的采样率。探查器不会捕获缓慢的操作日志条目。
b.复制延迟和流控
复制延迟(Replication lag (opens new window))是指将主节点上的写操作复制到从节点上所花费的时间。较短的延迟时间是可以接受的,但是随着复制延迟的增加,可能会出现严重的问题:比如在主节点上的缓存压力。
从 MongoDB 4.2 开始,管理员可以限制主节点的写入速率,使得大多数延迟时间保持在可配置的最大值 flowControlTargetLagSeconds (opens new window)以下。
默认情况下,流控是开启的。
启用流控后,随着延迟时间越来越接近 flowControlTargetLagSeconds (opens new window),主对象上的写操作必须先获得令牌,然后才能进行锁定并执行写操作。通过限制每秒发出的令牌数量,流控机制尝试将延迟保持在目标以下。
04.故障转移
a.说明1
当主节点与集群中的其他成员通信的时间超过配置的 electionTimeoutMillis(默认为 10 秒)时,
符合选举要求的从节点将要求选举,并提名自己为新的主节点。集群尝试完成选举新主节点并恢复正常工作。
b.说明2
选举完成前,副本集无法处理写入操作。如果将副本集配置为:在主节点处于脱机状态时,在次节点上运行,则副本集可以继续提供读取查询。
假设副本配置 (opens new window)采用默认配置,则集群选择新节点的时间通常不应超过 12 秒,这包括:将主节点标记为不可用并完成选举所需的时间。可以通过修改 settings.electionTimeoutMillis (opens new window)配置选项来调整此时间。网络延迟等因素可能会延长完成选举所需的时间,进而影响集群在没有主节点的情况下可以运行的时间。这些因素取决于集群实际的情况。
将默认为 10 秒的 electionTimeoutMillis (opens new window)选项数值缩小,可以更快地检测到主要故障。但是,由于网络延迟等因素,集群可能会更频繁地进行选举,即使该主节点实际上处于健康状态。这可能导致 w : 1 (opens new window)写操作的回滚次数增加。
应用程序的连接逻辑应包括对自动故障转移和后续选举的容错处理。从 MongoDB 3.6 开始,MongoDB 驱动程序可以检测到主节点的失联,并可以自动重试一次某些写入操作。
从 MongoDB4.4 开始,MongoDB 提供镜像读取:将可选举的从节点的最近访问的数据,预热为缓存。预热从节点的缓存可以帮助在选举后更快地恢复。
05.读操作
a.读优先
默认情况下,客户端从主节点读取数据;但是,客户端可以指定读取首选项,以将读取操作发送到从节点。
异步复制到从节点意味着向从节点读取数据可能会返回与主节点不一致的数据。
包含读取操作的多文档事务必须使用读取主节点优先。给定事务中的所有操作必须路由到同一成员。
b.数据可见性
根据读取的关注点,客户端可以在持久化写入前查看写入结果:
不管写的 write concern (opens new window)如何设置,其他使用 "local" (opens new window)或 "available" (opens new window)的读配置的客户端都可以向发布客户端确认写操作之前看到写操作的结果。
使用 "local" (opens new window)或 "available" (opens new window)读取配置的客户端可以读取数据,这些数据随后可能会在副本集故障转移期间回滚。
-----------------------------------------------------------------------------------------------------
对于多文档事务中的操作,当事务提交时,在事务中进行的所有数据更改都将保存,并在事务外部可见。也就是说,事务在回滚其他事务时将不会提交其某些更改。在提交事务前,事务外部看不到在事务中进行的数据更改。
但是,当事务写入多个分片时,并非所有外部读操作都需要等待已提交事务的结果在所有分片上可见。例如,如果提交了一个事务,并且在分片 A 上可以看到写 1,但是在分片 B 上还看不到写 2,则在 "local" (opens new window)读配置级别,外部读取可以读取写 1 的结果而看不到写 2。
06.镜像读取
a.介绍
从 MongoDB 4.4 开始,MongoDB 提供镜像读取以预热可选从节点(即优先级大于 0 的成员)的缓存。
使用镜像读取(默认情况下已启用),主节点可以镜像它接收到的一部分操作,并将其发送给可选择的从节点的子集。
子集的大小是可配置的。
1.4 分片
01.分片集群
a.概念
当 MongoDB 需要存储海量数据时,单节点不足以存储全量数据,且可能无法提供令人满意的吞吐量。
所以,可以通过 MongoDB 分片机制来支持水平扩展。
b.特点
对应用完全透明
数据自动均衡
动态扩容
提供三种分片方式
c.分片集群组件
shard (opens new window):每个分片包含分片数据的子集。每个分片都可以部署为副本集。
mongos (opens new window):mongos 充当查询路由器,在客户端应用程序和分片集群之间提供接口。从 MongoDB 4.4 开始,mongos 可以支持 hedged reads (opens new window)以最大程度地减少延迟。
config servers (opens new window):提供集群元数据存储和分片数据分布的映射。
d.分片集群的分布
MongoDB 复制集以 collection 为单位,将数据分布在集群中的各个分片上。最多允许 1024 个分片。
MongoDB 复制集的分片之间数据不重复,只有当所有分片都正常时,才能完整工作。
MongoDB 数据库可以同时包含分片和未分片的集合的 collection。分片 collection 会分布在集群中各节点上。而未分片的 collection 存储在主节点上。每个数据库都有其自己的主节点。
e.路由节点 mongos
要连接 MongoDB 分片集群 (opens new window),必须连接到 mongos (opens new window)路由器。这包括分片和未分片的 collection。客户端不应该连接到单个分片节点进行读写操作。
连接 mongos (opens new window)的方式和连接 mongod (opens new window)相同,例如通过 mongo (opens new window)shell 或 MongoDB 驱动程序 (opens new window)。
-----------------------------------------------------------------------------------------------------
路由节点的作用:
提供集群的单一入口
转发应用端请求
选择合适数据节点进行读写
合并多个数据节点的返回
-----------------------------------------------------------------------------------------------------
一般,路由节点 mongos 建议至少 2 个。
02.分片 Key
a.MongoDB 使用分片 Key 在各个分片之间分发 collection 的 document。分片 Key 由 document 中的一个或多个字段组成。
从 MongoDB 4.4 开始,分片 collection 中的 document 可能缺少分片 Key 字段。在跨分片分布文档时,缺少分片 Key 字段将被视为具有空值,但在路由查询时则不会。
在 MongoDB 4.2 及更早版本中,分片 Key 字段必须在每个 document 中存在一个分片 collection。
b.在分片 collection 时选择分片 Key。
从 MongoDB 4.4 开始,您可以通过在现有 Key 中添加一个或多个后缀字段来优化 collection 的分片 Key。
在 MongoDB 4.2 和更低版本中,无法在分片后更改分片 Key 的选择。
c.document 的分片键值决定了其在各个分片中的分布
从 MongoDB 4.2 开始,除非您的分片 Key 字段是不可变的_id 字段,否则您可以更新 document 的分片键值。
在 MongoDB 4.0 及更低版本中,文档的分片 Key 字段值是不可变的。
d.总结
分片 Key 索引:要对已填充的 collection 进行分片,该 collection 必须具有以分片 Key 开头的索引。分片一个空 collection 时,如果该 collection 还没有针对指定分片 Key 的适当索引,则 MongoDB 会创建支持索引。
分片 Key 策略:分片 Key 的选择会影响分片集群的性能,效率和可伸缩性。分片 Key 及其后备索引的选择也会影响集群可以使用的分片策略。
MongoDB 分区将数据分片。每个分块都有基于分片 Key 的上下限。
为了在整个集群中的所有分片上实现块的均匀分布,均衡器在后台运行,并在各分片上迁移块。
03.分片策略
a.介绍
MongoDB 支持两种分片策略:Hash 分片和范围分片。
b.Hash 分片
Hash 分片策略会先计算分片 Key 字段值的哈希值;然后,根据分片键值为每个 chunk (opens new window)分配一个范围。
注意:使用哈希索引解析查询时,MongoDB 会自动计算哈希值,应用程序不需要计算哈希。
尽管分片 Key 范围可能是“接近”的,但它们的哈希值不太可能在同一 chunk (opens new window)上。基于 Hash 的数据分发有助于更均匀的数据分布,尤其是在分片 Key 单调更改的数据集中。
但是,Hash 分片意味着对分片 Key 做范围查询时不太可能针对单个分片,从而导致更多的集群范围内的广播操作。
c.范围分片
范围分片根据分片 Key 值将数据划分为多个范围。然后,根据分片 Key 值为每个 chunk (opens new window)分配一个范围。
值比较近似的一系列分片 Key 更有可能驻留在同一 chunk (opens new window)上。范围分片的效率取决于选择的分片 Key。分片 Key 考虑不周全会导致数据分布不均,这可能会削弱分片的某些优势或导致性能瓶颈。
04.分片集群中的区域
区域可以提高跨多个数据中心的分片集群的数据局部性。
在分片集群中,可以基于分片 Key 创建分片数据区域 (opens new window)。可以将每个区域与集群中的一个或多个分片关联。分片可以与任意数量的区域关联。在平衡的集群中,MongoDB 仅将区域覆盖的 chunk (opens new window)迁移到与该区域关联的分片。
每个区域覆盖一个或多个分片 Key 值范围。区域覆盖的每个范围始终包括其上下边界。
在定义要覆盖的区域的新范围时,必须使用分片 Key 中包含的字段。如果使用复合分片 Key,则范围必须包含分片 Key 的前缀。
选择分片 Key 时,应考虑将来可能使用的区域。
2 MongoDB组成
2.1 数据库
01.介绍
a.说明
一个 MongoDB 中可以建立多个数据库。
MongoDB 的默认数据库为"db",该数据库存储在 data 目录中。
MongoDB 的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
b.命名规范
数据库也通过名字来标识。数据库名可以是满足以下条件的任意 UTF-8 字符串。
不能是空字符串("")
不得含有 ' '(空格)、.、\$、/、\和 \0 (空字符)
应全部小写
最多 64 字节
c.保留数据库名
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config:当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息。
02.命令
a.分类
show dbs --查看数据库列表
show collections --显示当前数据库中的集合
show users --显示用户
-----------------------------------------------------------------------------------------------------
use myDatabase --创建或切换数据库(若不存在,创建)
db --显示当前数据库
db.dropDatabase() --删除当前数据库
-----------------------------------------------------------------------------------------------------
db.help() --显示数据库操作命令
db.foo.help() --显示集合操作命令,foo代指当前数据库
db.foo.find() --当前集合数据查找
db.foo.find({a:1}) --当前集合数据查找,条件查询
db.foo.find({a:1},{column:0}) --当前集合数据查找,条件查询
b.入门示例
插入数据
db.users.insertOne({ name: "Alice", age: 25 })
db.users.insertMany([{ name: "Bob", age: 30 }, { name: "Charlie", age: 35 }])
-----------------------------------------------------------------------------------------------------
查询数据
db.users.find({ age: { $gt: 20 } })
db.users.findOne({ name: "Alice" })
db.users.find()
db.users.find().pretty() --美化
-----------------------------------------------------------------------------------------------------
更新数据
db.users.updateOne({ name: "Alice" }, { $set: { age: 26 } })
db.users.updateMany({ age: { $lt: 30 } }, { $inc: { age: 1 } })
-----------------------------------------------------------------------------------------------------
删除数据
db.users.deleteOne({ name: "Alice" })
db.users.deleteMany({ age: { $gt: 30 } })
-----------------------------------------------------------------------------------------------------
查看集合列表
show collections
2.2 集合:表集合+表设计
01.介绍
a.说明
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
b.命名规范
集合名不能是空字符串""。
集合名不能含有 \0 字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现 $。
02.命令
a.分类
show collections --查看集合
db.createCollection("collection") --创建集合
db.collection.drop() --删除集合
-----------------------------------------------------------------------------------------------------
db.adminCommand({ --必须管理员权限
renameCollection: "myDatabase.collection", --集合必须存在:若集合不存在,命令将会失败。
to: "myDatabase.newCollection" --目标名称不可重复:目标名称的集合若已存在,命令也会失败。
})
b.创建集合参数
db.createCollection(name, options)
db.createCollection("collection") --创建集合
-----------------------------------------------------------------------------------------------------
参数说明:
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
-----------------------------------------------------------------------------------------------------
options 可以是如下参数:
字段 类型 描述
capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。
autoIndexId 布尔 (废弃)3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。
size 数值 (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。
max 数值 (可选)指定固定集合中包含文档的最大数量。
-----------------------------------------------------------------------------------------------------
| 参数名 | 类型 | 描述 | 示例值
|--------------------------------------|------------|-----------------------------------------------------------|-------------------------------
| capped | 布尔值 | 是否创建一个固定大小的集合。 | true
| size | 数值 | 集合的最大大小(以字节为单位)。仅在 capped 为 true 时有效。 | 10485760 (10MB)
| max | 数值 | 集合中允许的最大文档数。仅在 capped 为 true 时有效。 | 5000
| validator | 对象 | 用于文档验证的表达式。 | { $jsonSchema: { ... }}
| validationLevel | 字符串 | 指定文档验证的严格程度。
| "off":不进行验证。
| "strict":插入和更新操作都必须通过验证(默认)。
| "moderate":仅现有文档更新时必须通过验证,插入新文档时不需要。
| validationAction | 字符串 | 指定文档验证失败时的操作。
| "error":阻止插入或更新(默认)
| "warn":允许插入或更新,但会发出警告
| storageEngine | 对象 | 为集合指定存储引擎配置。 | { wiredTiger: { ... }}
| collation | 对象 | 指定集合的默认排序规则。 | { locale: "en", strength: 2 }
c.示例
db.createCollection("myComplexCollection", {
capped: true,
size: 10485760,
max: 5000,
validator: { $jsonSchema: {
bsonType: "object",
required: ["name", "email"],
properties: {
name: {
bsonType: "string",
description: "必须为字符串且为必填项"
},
email: {
bsonType: "string",
pattern: "^.+@.+$",
description: "必须为有效的电子邮件地址"
}
}
}},
validationLevel: "strict",
validationAction: "error",
storageEngine: {
wiredTiger: { configString: "block_compressor=zstd" }
},
collation: { locale: "en", strength: 2 }
});
-----------------------------------------------------------------------------------------------------
db.myComplexCollection.insertOne({
name: "Alice",
email: "alice@example.com"
})
-----------------------------------------------------------------------------------------------------
db.myComplexCollection.insertMany([
{
name: "Bob",
email: "bob@example.com"
},
{
name: "Charlie",
email: "charlie@example.com"
}
])
-----------------------------------------------------------------------------------------------------
db.adminCommand({ --重命名
renameCollection: "myDatabase.myComplexCollection",
to: "myDatabase.newCollectionName"
})
-----------------------------------------------------------------------------------------------------
db.myComplexCollection.find()
db.myComplexCollection.find().pretty() --美化
2.3 文档:行,一条数据
00.介绍
a.说明
文档是一组键值(key-value)对(即 BSON)。
MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,
也是 MongoDB 非常突出的特点。
b.特点
文档中的键/值对是有序的
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)
MongoDB 区分类型和大小写
MongoDB 的文档不能有重复的键
文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符
c.命名规范
键不能含有 \0 (空字符)。这个字符用来表示键的结尾。
. 和 $ 有特别的意义,只有在特定环境下才能使用。
以下划线 _ 开头的键是保留的(不是严格要求的)。
01.INSERT
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
如果要插入的 collection 当前不存在,则插入操作会自动创建 collection。
在 MongoDB 中,存储在集合中的每个文档都需要一个唯一的 _id (opens new window)字段作为主键。如果插入的文档省略 _id 字段,则 MongoDB 驱动程序会自动为 _id 字段生成 ObjectId。
可以 MongoDB 写入操作的确认级别来控制写入行为。
-----------------------------------------------------------------------------------------------------
db.collection.insertOne() :插入一条 document
db.collection.insertMany() :插入多条 document
b.insert方法
a.语法
db.集合名.insert(json数据)
集合存在则直接插入数据,不存在则隐式创建集合并插入数据
json数据格式要求key得加"",但这里为了方便查看,对象的key统一不加"";查看集合数据时系统会自动给key加""
mongodb会自动给每条数据创建全球唯一的_id键(我们也可以自定义_id的值,只要给插入的json数据增加_id键即可覆盖,但是不推荐这样做)
b.示例
db.users.insert({"name": "Alice","age": 24,"city": "New York"});
db.users.insert([{ "_id": 1, "name": "Bob", "age": 30, "city": "Los Angeles" },{ "_id": 2, "name": "Charlie", "age": 28, "city": "Chicago" }]);
for(var i=1;i<10;i++){
db.users.insert({name:"a"+i,age:i})
}
c.insertOne:插入一条
db.inventory.insertOne({
item: 'canvas',
qty: 100,
tags: ['cotton'],
size: { h: 28, w: 35.5, uom: 'cm' }
})
d.insertMany:插入多条
db.inventory.insertMany([
{
item: 'journal',
qty: 25,
tags: ['blank', 'red'],
size: { h: 14, w: 21, uom: 'cm' }
},
{
item: 'mat',
qty: 85,
tags: ['gray'],
size: { h: 27.9, w: 35.5, uom: 'cm' }
}
])
02.QUERY
a.find方法
a.语法
db.集合名.find(条件 [,查询的列])
db.集合名.find(条件 [,查询的列]).pretty() #格式化查看
-------------------------------------------------------------------------------------------------
# 条件
- 查询所有数据 {}或不写
- 查询指定要求数据 {key:value}或{key:{运算符:value}}
# 查询的列(可选参数)
- 不写则查询全部列
- {key:1} 只显示key列
- {key:0} 除了key列都显示
- 注意:_id列都会存在
b.示例
db.inventory.find() --查看全部数据
db.inventory.find({id:"2"}) --查看多条数据{id:"2"}
db.inventory.find().limit(2) --limit:2条
b.$type:筛选具有特定数据类型的文档
a.语法
{ "field": { "$type": "type" } }
b.数据类型的表示
字符串类型:例如 "string" 表示字符串。
数字类型:例如 "double" 表示双精度浮点数。
整数类型:例如 "int" 表示整数。
对象类型:例如 "object" 表示文档。
数组类型:例如 "array" 表示数组。
布尔类型:例如 "bool" 表示布尔值。
日期类型:例如 "date" 表示日期。
null 类型:例如 "null" 表示 null 值。
-------------------------------------------------------------------------------------------------
除了使用类型的名称外,还可以使用 BSON 类型的数字表示。例如,1 表示 double,2 表示 string,3 表示 object,以此类推。
c.示例
a.数据
{ "_id": 1, "name": "Alice", "age": 30, "isActive": true, "birthdate": ISODate("1990-01-01") }
{ "_id": 2, "name": "Bob", "age": "twenty-five", "isActive": false, "birthdate": null }
{ "_id": 3, "name": "Charlie", "age": 25, "isActive": true, "birthdate": ISODate("1995-05-15") }
b.查询所有年龄为整数类型的文档:
db.people.find({ "age": { "$type": "int" } })
c.查询所有出生日期为日期类型的文档:
db.people.find({ "birthdate": { "$type": "date" } })
d.查询所有活动状态为布尔类型的文档:
db.people.find({ "isActive": { "$type": "bool" } })
e.查询所有名称为字符串类型的文档:
db.people.find({ "name": { "$type": 2 } }) // 2 表示字符串
f.例如,查询年龄为整数且活动状态为布尔值的文档
db.people.find({
"age": { "$type": "int" },
"isActive": { "$type": "bool" }
})
c.findAndModify()、findOneAndUpdate()、findOneAndReplace()
a.准备数据
db.users.insertMany([
{ name: "Alice", age: 24 },
{ name: "Bob", age: 29 },
{ name: "Charlie", age: 34 }
]);
b.使用 db.collection.findAndModify() 和 upsert: true
findAndModify 方法用于查找符合指定条件的文档并对其进行修改。
当与 upsert: true 一起使用时,如果指定条件的文档不存在,MongoDB会创建一个新的文档,并根据提供的更新操作进行设置。
此外,findAndModify 还可以指定返回更新前或更新后的文档,便于获取最终结果。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "David" 的文档。如果找不到该文档,则会创建新文档
db.users.findAndModify({
query: { name: "David" },
update: { $set: { age: 28 } },
upsert: true,
new: true
});
结果:name: "David" 的文档不存在,因此会创建新的 { name: "David", age: 28 } 文档。
c.使用 db.collection.findOneAndUpdate() 和 upsert: true
findOneAndUpdate 方法用于查找符合条件的单个文档并对其进行更新操作。
当设置 upsert: true 时,MongoDB在文档不存在的情况下会插入一个新文档。
此方法通常用于需要在符合条件的文档不存在时自动插入的场景。
findOneAndUpdate 也可以通过 returnDocument 参数指定是否返回更新前或更新后的文档。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "Alice" 的文档。如果找到,将更新其 age 字段;如果找不到,则会创建新文档:
db.users.findOneAndUpdate(
{ name: "Alice" },
{ $set: { age: 26 } },
{ upsert: true, returnDocument: "after" }
);
结果:name: "Alice" 的文档存在,因此 age 字段会更新为 26。
d.使用 db.collection.findOneAndReplace() 和 upsert: true
findOneAndReplace 方法查找符合条件的单个文档并将其完全替换为新的文档内容。
当 upsert: true 被设置时,如果指定条件的文档不存在,MongoDB会创建一个新文档,且该文档的内容会完全按照提供的替换内容设置。
此方法适用于需要按特定结构完全替换文档,或在不存在时创建该结构的场景。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "Eve" 的文档。如果找到,将完全替换该文档;如果找不到,将创建新文档:
db.users.findOneAndReplace(
{ name: "Eve" },
{ name: "Eve", age: 22 },
{ upsert: true, returnDocument: "after" }
);
结果:name: "Eve" 的文档不存在,因此会创建新的 { name: "Eve", age: 22 } 文档。
e.最终结果
[
{ "_id": ObjectId("..."), "name": "Alice", "age": 26 },
{ "_id": ObjectId("..."), "name": "Bob", "age": 29 },
{ "_id": ObjectId("..."), "name": "Charlie", "age": 34 },
{ "_id": ObjectId("..."), "name": "David", "age": 28 },
{ "_id": ObjectId("..."), "name": "Eve", "age": 22 }
]
03.UPDATE
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
一旦设置了,就无法更新或替换 _id (opens new window)字段。
除以下情况外,MongoDB 会在执行写操作后保留文档字段的顺序:
_id 字段始终是文档中的第一个字段。
包括重命名字段名称的更新可能导致文档中字段的重新排序。
如果更新操作中包含 upsert : true 并且没有 document 匹配过滤器,MongoDB 会新插入一个 document;如果有匹配的 document,MongoDB 会修改或替换这些 document。
-----------------------------------------------------------------------------------------------------
db.collection.updateOne():更新一条 document
db.collection.updateMany():更新多条 document
db.collection.replaceOne():替换一条 document
-----------------------------------------------------------------------------------------------------
db.collection.updateOne(<filter>, <update>, <options>)
db.collection.updateMany(<filter>, <update>, <options>)
db.collection.replaceOne(<filter>, <update>, <options>)
b.update方法
a.语法1
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
-------------------------------------------------------------------------------------------------
query : update 的查询条件,类似 sql update 查询内 where 后面的。
update : update 的对象和一些更新的操作符(如$,$inc...)等,也可以理解为 sql update 查询内 set 后面的
upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入 objNew, true 为插入,默认是 false不插入
multi : 可选,mongodb 默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
b.语法2
db.集合名.update(条件, 新数据 [,是否新增, 是否修改多条])
-------------------------------------------------------------------------------------------------
# 新数据
- 默认是对原数据进行替换
- 若要进行修改,格式为 {修改器:{key:value}}
# 是否新增
- 条件匹配不到数据时是否插入: true插入,false不插入(默认)
# 是否修改多条
- 条件匹配成功的数据是否都修改: true都修改,false只修改一条(默认)
c.示例
a.默认,只更新第一条记录:
db.collection.update({ count: { $gt: 1 } }, { $set: { test2: 'OK' } })
b.全部更新:
db.collection.update(
{ count: { $gt: 3 } },
{ $set: { test2: 'OK' } },
false,
true
)
c.只添加第一条:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
d.全部添加进去:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
e.全部更新:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
f.只更新第一条记录:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
c.$set、$unset、$inc
a.说明
$set:添加或更新字段
$unset:删除字段
$rename:重命名字段
$inc:递增,用来增加已有键的值,如果该键不存在就新创建一个
b.准备数据
{ "_id": 1, "name": "Alice", "age": 24, "city": "New York" }
c.使用 $set 添加或更新字段
db.users.updateOne(
{ _id: 1 },
{ $set: { age: 25, country: "USA" } }
);
d.使用 $unset 删除字段
db.users.updateOne(
{ _id: 1 },
{ $unset: { city: "" } }
);
e.使用 $inc 递增字段
使用 $inc 可以将 age 字段递增 1,将 score 字段递增 10:
db.users.updateOne(
{ _id: 1 },
{ $inc: { age: 1, score: 10 } }
);
f.使用 $rename 重命名字段
db.users.updateOne(
{ _id: 1 },
{ $rename: { "city": "location" } }
);
d.数组修改器
a.说明
$push:向数组添加一个元素。
$each:一次性添加多个元素。
$slice:限制数组长度。
$sort:对数组进行排序。
$addToSet:向数组添加唯一元素。
$pop:删除数组的第一个或最后一个元素。
$pull:从数组中删除指定元素。
b.准备数据
{
"_id": 1,
"name": "Alice",
"hobbies": ["reading", "swimming"],
"scores": [10, 20, 30]
}
c.$push 操作符用于向数组字段添加一个新元素
db.users.updateOne(
{ _id: 1 },
{ $push: { hobbies: "cycling" } }
);
d.$each 和 $push 一起使用时可以一次性添加多个元素
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [40, 50] } } }
);
e.$slice 可以在 $push 和 $each 之后使用,控制数组长度。例如,将 scores 数组限制为最多3个元素。
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [60], $slice: -3 } } }
);
f.$sort 可以与 $push 和 $each 一起使用,对数组进行排序。比如对 scores 数组进行降序排列
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [], $sort: -1 } } }
);
g.$addToSet 用于向数组中添加元素,如果该元素不存在。重复元素不会被添加。
db.users.updateOne(
{ _id: 1 },
{ $addToSet: { hobbies: "swimming" } }
);
h.$pop 可以删除数组中的第一个或最后一个元素。使用 1 表示删除最后一个元素,-1 表示删除第一个元素
db.users.updateOne(
{ _id: 1 },
{ $pop: { scores: 1 } }
);
i.$pull 用于删除数组中指定的元素。比如,删除 hobbies 数组中的 "swimming"
db.users.updateOne(
{ _id: 1 },
{ $pull: { hobbies: "swimming" } }
);
j.$ 既然是数组,我们当然可以通过下标来访问
db.posts.insertOne({
"_id": 1,
"title": "MongoDB Array Update",
"comments": [100, 200, 300]
});
-------------------------------------------------------------------------------------------------
db.posts.updateOne(
{ _id: 1 },
{ $set: { "comments.0": 999 } }
);
-------------------------------------------------------------------------------------------------
将 comments 数组中下标为 0 的元素(即第一个元素)更新为 999
"comments.0":通过数组的下标访问 comments 数组中的第一个元素。
$set:将指定位置的元素值设置为 999。
e.updateOne、updateMany、replaceOne
a.准备数据
db.inventory.insertMany([
{
item: 'canvas',
qty: 100,
size: { h: 28, w: 35.5, uom: 'cm' },
status: 'A'
},
{ item: 'journal', qty: 25, size: { h: 14, w: 21, uom: 'cm' }, status: 'A' },
{ item: 'mat', qty: 85, size: { h: 27.9, w: 35.5, uom: 'cm' }, status: 'A' },
{
item: 'mousepad',
qty: 25,
size: { h: 19, w: 22.85, uom: 'cm' },
status: 'P'
},
{
item: 'notebook',
qty: 50,
size: { h: 8.5, w: 11, uom: 'in' },
status: 'P'
},
{ item: 'paper', qty: 100, size: { h: 8.5, w: 11, uom: 'in' }, status: 'D' },
{
item: 'planner',
qty: 75,
size: { h: 22.85, w: 30, uom: 'cm' },
status: 'D'
},
{
item: 'postcard',
qty: 45,
size: { h: 10, w: 15.25, uom: 'cm' },
status: 'A'
},
{
item: 'sketchbook',
qty: 80,
size: { h: 14, w: 21, uom: 'cm' },
status: 'A'
},
{
item: 'sketch pad',
qty: 95,
size: { h: 22.85, w: 30.5, uom: 'cm' },
status: 'A'
}
])
b.更新一条 document
db.inventory.updateOne(
{ item: 'paper' },
{
$set: { 'size.uom': 'cm', status: 'P' },
$currentDate: { lastModified: true }
}
)
c.更新多条 document
db.inventory.updateMany(
{ qty: { $lt: 50 } },
{
$set: { 'size.uom': 'in', status: 'P' },
$currentDate: { lastModified: true }
}
)
d.替换一条 document
db.inventory.replaceOne(
{ item: 'paper' },
{
item: 'paper',
instock: [
{ warehouse: 'A', qty: 60 },
{ warehouse: 'B', qty: 40 }
]
}
)
04.DELETE
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
-----------------------------------------------------------------------------------------------------
db.collection.deleteOne():删除一条 document
db.collection.deleteMany():删除多条 document
b.remove
db.集合名.remove(条件 [,是否删除一条])
# 是否删除一条
- false删除多条,即全部删除(默认)
- true删除一条
-----------------------------------------------------------------------------------------------------
db.inventory.remove({}, true) --删除一条
db.inventory.remove({}, false) --删除全部
b.deleteOne、deleteMany、deleteMany
db.inventory.deleteOne({ status: "A" }) --删除 status 为 "A" 的第一条文档
db.inventory.deleteMany({ status: "D" }) --删除 status 为 "D" 的所有文档
db.inventory.deleteMany({}) --删除全部
2.4 字段:列,字段的值
01.介绍
a.概念
MongoDB中每条记录称作一个文档,这个文档和我们平时用的JSON有点像,但也不完全一样。
JSON是一种轻量级的数据交换格式。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,
JSON易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,
-----------------------------------------------------------------------------------------------------
但是JSON也有它的局限性,
比如它只有null、布尔、数字、字符串、数组和对象这几种数据类型,没有日期类型,
只有一种数字类型,无法区分浮点数和整数,也没法表示正则表达式或者函数。
-----------------------------------------------------------------------------------------------------
由于这些局限性,BSON闪亮登场啦,
BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,
它和JSON一样,支持内嵌的文档对象和数组对象,
但是BSON有JSON没有的一些数据类型,如Date和BinData类型,
-----------------------------------------------------------------------------------------------------
MongoDB使用BSON做为文档数据存储和网络传输格式。
b.汇总
| 数据类型 | 描述
|--------------------|-------------------------------------------------------------
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
| Boolean | 布尔值。用于存储布尔值(真/假)。
| Double | 双精度浮点值。用于存储浮点值。
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
| Array | 用于将数组或列表或多个值存储为一个键。
| Timestamp | 时间戳。记录文档修改或添加的具体时间。
| Object | 用于内嵌文档。
| Null | 用于创建空值。
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
| Object ID | 对象 ID。用于创建文档的 ID。
| Binary Data | 二进制数据。用于存储二进制数据。
| Code | 代码类型。用于在文档中存储 JavaScript 代码。
| Regular expression | 正则表达式类型。用于存储正则表达式。
c.示例
| 数据类型 | 示例
|--------------------|-------------------------------------------------------------
| String | "name": "Alice"
| Integer | "age": 30
| Boolean | "isActive": true
| Double | "rating": 4.5
| Min/Max keys | MinKey 和 MaxKey
| Array | "tags": ["mongodb", "database", "NoSQL"]
| Timestamp | "createdAt": Timestamp()
| Object | "address": { "city": "New York", "zip": "10001" }
| Null | "middleName": null
| Symbol | "symbol": Symbol("uniqueSymbol")
| Date | "dob": new Date("1990-01-01")
| Object ID | "_id": ObjectId("507f1f77bcf86cd799439011")
| Binary Data | "fileData": BinData(0, "binaryDataInBase64")
| Code | "jsFunction": Code("function() { return 'Hello, World!'; }")
| Regular expression | "pattern": /abc/i
02.命令
a.切换数据库
use myDatabase;
b.创建集合并插入包含各种数据类型的文档
db.allDataTypesCollection.insertOne({
// String
name: "Alice",
// Integer
age: 30,
// Boolean
isActive: true,
// Double
rating: 4.5,
// Min/Max keys
minKeyField: MinKey(),
maxKeyField: MaxKey(),
// Array
tags: ["mongodb", "database", "NoSQL"],
// Timestamp
createdAt: Timestamp(),
// Object
address: {
city: "New York",
zip: "10001"
},
// Null
middleName: null,
// Symbol
symbol: Symbol("uniqueSymbol"),
// Date
dob: new Date("1990-01-01"),
// Object ID
customId: ObjectId("507f1f77bcf86cd799439011"),
// Binary Data
fileData: BinData(0, "binaryDataInBase64"),
// Code
jsFunction: Code("function() { return 'Hello, World!'; }"),
// Regular Expression
pattern: /abc/i
});
c.查看数据
db.allDataTypesCollection.find()
2.5 bulkWrite
01.有序和无序的操作
a.介绍
批量写操作可以有序或无序。
对于有序列表,MongoDB 串行执行操作。如果在写操作的处理过程中发生错误,MongoDB 将不处理列表中剩余的写操作。
对于无序列表,MongoDB 可以并行执行操作,但是不能保证此行为。如果在写操作的处理过程中发生错误,MongoDB 将继续处理列表中剩余的写操作。
在分片集合上执行操作的有序列表通常比执行无序列表要慢,因为对于有序列表,每个操作必须等待上一个操作完成。
b.说明
默认情况下,bulkWrite() (opens new window)执行有序操作。
要指定无序写操作,请在选项文档中设置 ordered : false。
02.bulkWrite()方法
a.bulkWrite()支持以下写操作:
insertOne
updateOne
updateMany
replaceOne
deleteOne
deleteMany
b.示例
try {
db.characters.bulkWrite([
{
insertOne: {
document: {
_id: 4,
char: 'Dithras',
class: 'barbarian',
lvl: 4
}
}
},
{
insertOne: {
document: {
_id: 5,
char: 'Taeln',
class: 'fighter',
lvl: 3
}
}
},
{
updateOne: {
filter: { char: 'Eldon' },
update: { $set: { status: 'Critical Injury' } }
}
},
{ deleteOne: { filter: { char: 'Brisbane' } } },
{
replaceOne: {
filter: { char: 'Meldane' },
replacement: { char: 'Tanys', class: 'oracle', lvl: 4 }
}
}
])
} catch (e) {
print(e)
}
03.批量写操作策略
a.介绍
大量的插入操作(包括初始数据插入或常规数据导入)可能会影响分片集群的性能。对于批量插入,请考虑以下策略:
b.预拆分 collection
如果分片集合为空,则该集合只有一个初始 chunk (opens new window),
该 chunk (opens new window)位于单个分片上。然后,MongoDB 必须花一些时间来接收数据,
创建拆分并将拆分的块分发到可用的分片。为了避免这种性能成本,
您可以按照拆分群集中的拆分块中的说明预拆分 collection。
c.无序写操作
要提高对分片集群的写入性能,请使用 bulkWrite() (opens new window),
并将可选参数顺序设置为 false。mongos (opens new window)可以尝试同时将写入操作发送到多个分片。
对于空集合,首先按照分片群集中的分割 chunk (opens new window)中的说明预拆分 collection。
c.避免单调节流
如果在一次插入操作中,分片 key 单调递增,那么所有的插入数据都会存入 collection 的最后一个 chunk,
也就是存入一个分片中。因此,集群的插入容量将永远不会超过该单个分片的插入容量。
-----------------------------------------------------------------------------------------------------
如果插入量大于单个分片可以处理的插入量,并且无法避免单调递增的分片键,那么请考虑对应用程序进行以下修改:
反转分片密钥的二进制位。这样可以保留信息,并避免将插入顺序与值序列的增加关联起来。
交换第一个和最后一个 16 位字以“随机”插入。
2.6 MapReduce
01.介绍
a.概念
MongoDB中的MapReduce可以用来实现更复杂的聚合命令,
使用MapReduce主要实现两个函数:map函数和reduce函数,map函数用来生成键值对序列,
map函数的结果作为reduce函数的参数,reduce函数中再做进一步的统计
b.runCommand实现
db.runCommand(
{
mapReduce: <collection>,
map: <function>,
reduce: <function>,
finalize: <function>,
out: <output>,
query: <document>,
sort: <document>,
limit: <number>,
scope: <document>,
jsMode: <boolean>,
verbose: <boolean>,
bypassDocumentValidation: <boolean>,
collation: <document>
}
)
-----------------------------------------------------------------------------------------------------
| 参数 | 含义
|--------------------------|----------------------------------------------
| mapReduce | 表示要操作的集合
| map | map函数
| reduce | reduce函数
| finalize | 最终处理函数
| out | 输出的集合
| query | 对结果进行过滤
| sort | 对结果排序
| limit | 返回的结果数
| scope | 设置参数值,在这里设置的值在map、reduce、finalize函数中可见
| jsMode | 是否将map执行的中间数据由javascript对象转换成BSON对象,默认为false
| verbose | 是否显示详细的时间统计信息
| bypassDocumentValidation | 是否绕过文档验证
| collation | 其他一些校对
02.示例
a.准备数据
首先,创建一个名为 sang_books 的集合,并插入以下文档:
db.sang_books.insertMany([
{ "_id" : ObjectId("59fa71d71fd59c3b2cd908d7"), "name" : "鲁迅", "book" : "呐喊", "price" : 38.0, "publisher" : "人民文学出版社" },
{ "_id" : ObjectId("59fa71d71fd59c3b2cd908d8"), "name" : "曹雪芹", "book" : "红楼梦", "price" : 22.0, "publisher" : "人民文学出版社" },
{ "_id" : ObjectId("59fa71d71fd59c3b2cd908d9"), "name" : "钱钟书", "book" : "宋诗选注", "price" : 99.0, "publisher" : "人民文学出版社" },
{ "_id" : ObjectId("59fa71d71fd59c3b2cd908da"), "name" : "钱钟书", "book" : "谈艺录", "price" : 66.0, "publisher" : "三联书店" },
{ "_id" : ObjectId("59fa71d71fd59c3b2cd908db"), "name" : "鲁迅", "book" : "彷徨", "price" : 55.0, "publisher" : "花城出版社" }
]);
b.统计每位作者的书籍总价
var mapPrice = function() {
emit(this.name, this.price);
};
var reducePrice = function(key, values) {
return Array.sum(values);
};
var optionsPrice = { out: "totalPrice" };
db.sang_books.mapReduce(mapPrice, reducePrice, optionsPrice);
db.totalPrice.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : 22.0 }
{ "_id" : "钱钟书", "value" : 165.0 }
{ "_id" : "鲁迅", "value" : 93.0 }
c.统计每位作者的书籍数量
var mapCount = function() {
emit(this.name, 1);
};
var reduceCount = function(key, values) {
return Array.sum(values);
};
var optionsCount = { out: "bookNum" };
db.sang_books.mapReduce(mapCount, reduceCount, optionsCount);
db.bookNum.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : 1.0 }
{ "_id" : "钱钟书", "value" : 2.0 }
{ "_id" : "鲁迅", "value" : 2.0 }
d.列出每位作者的书籍名称
var mapBooks = function() {
emit(this.name, this.book);
};
var reduceBooks = function(key, values) {
return values.join(',');
};
var optionsBooks = { out: "books" };
db.sang_books.mapReduce(mapBooks, reduceBooks, optionsBooks);
db.books.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : "红楼梦" }
{ "_id" : "钱钟书", "value" : "宋诗选注,谈艺录" }
{ "_id" : "鲁迅", "value" : "呐喊,彷徨" }
e.查询售价在¥40以上的书籍
var mapExpensiveBooks = function() {
emit(this.name, this.book);
};
var reduceExpensiveBooks = function(key, values) {
return values.join(',');
};
var optionsExpensiveBooks = { query: { price: { $gt: 40 } }, out: "expensiveBooks" };
db.sang_books.mapReduce(mapExpensiveBooks, reduceExpensiveBooks, optionsExpensiveBooks);
db.expensiveBooks.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "钱钟书", "value" : "宋诗选注,谈艺录" }
{ "_id" : "鲁迅", "value" : "彷徨" }
f.使用 runCommand 执行 MapReduce
var map = function() {
emit(this.name, this.book);
};
var reduce = function(key, value) {
return value.join(',');
};
db.runCommand({
mapReduce: 'sang_books',
map: map,
reduce: reduce,
out: "books",
limit: 4,
verbose: true
});
db.books.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : "红楼梦" }
{ "_id" : "钱钟书", "value" : "宋诗选注,谈艺录" }
{ "_id" : "鲁迅", "value" : "呐喊" }
g.使用 finalize 函数
可以通过 finalize 函数来对 MapReduce 的结果进行最终处理:
-----------------------------------------------------------------------------------------------------
var finalize = function(key, reduceValue) {
var obj = {};
obj.author = key;
obj.books = reduceValue;
return obj;
};
db.runCommand({
mapReduce: 'sang_books',
map: map,
reduce: reduce,
out: "books",
finalize: finalize
});
db.books.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : { "author" : "曹雪芹", "books" : "红楼梦" } }
{ "_id" : "钱钟书", "value" : { "author" : "钱钟书", "books" : "宋诗选注,谈艺录" } }
{ "_id" : "鲁迅", "value" : { "author" : "鲁迅", "books" : "呐喊,彷徨" } }
h.使用 scope 定义全局变量
可以使用 scope 定义在 map、reduce 和 finalize 中可用的全局变量:
var scope = { sang: "haha" };
var finalizeWithScope = function(key, reduceValue) {
var obj = {};
obj.author = key;
obj.books = reduceValue;
obj.sang = scope.sang;
return obj;
};
db.runCommand({
mapReduce: 'sang_books',
map: map,
reduce: reduce,
out: "books",
finalize: finalizeWithScope,
scope: scope
});
db.books.find().pretty();
-----------------------------------------------------------------------------------------------------
{ "_id" : "曹雪芹", "value" : { "author" : "曹雪芹", "books" : "红楼梦", "sang" : "haha" } }
{ "_id" : "钱钟书", "value" : { "author" : "钱钟书", "books" : "宋诗选注,--haha--,谈艺录", "sang" : "haha" } }
{ "_id" : "鲁迅", "value" : { "author" : "鲁迅", "books" : "呐喊,--haha--,彷徨", "sang" : "haha" } }
3 MongoDB使用
3.1 命令
00.说明
a.对比1
MySQL MongoDB
行 文档(document)
表 集合(collections)
数据库 数据库(databases)
b.对比2
SQL MongoDB 说明
database database 数据库
table collection 数据库表/集合
row document 数据记录行/文档
column field 数据字段/域
index index 索引
primary key primary key 主键,默认String,因此在插入数字时,可以使用内置的函数NumberInt将数字进行转换自动生成唯一标识符_id
table joins 嵌入文档 表连接,MongoDB通过嵌入式文档来替代多表连接
00.从 MongoDB 3.2 开始,推荐使用更明确的 insertOne 和 insertMany 代替 insert
a.创建数据库
use mg
b.插入数据
db.person.insert({id:"1", name:"zs", age:NumberInt(23)})
db.person.insert({id:"2", name:"ls", age:NumberInt(24)})
db.person.insert({id:"3", name:"ww", age:NumberInt(25)})
c.查询数据
db.person.find() --查看全部数据
db.person.find({id:"2"}) --查看多条数据{id:"2"}
db.person.findOne({id:"2"}) --查看仅一条数据{id:"2"}
db.person.find().limit(2) --limit
d.修改数据
方式一:会舍弃其他未修改字段
db.person.update({id:"2"}, {name:"ww"})
方式二:保留其他未修改字段,建议方式二
db.person.update({id:"3"}, {$set:{name:"ww"}})
e.删除数据
db.person.remove({}) --删除全部数据
db.person.remove({id:"2"}) --删除多条数据{id:"2"}
db.person.drop() --删除表
db.dropDatabase() --删除数据库
f.统计数据
db.person.count() --查询全部的数量
db.person.count({name:"zs"}) --查询数据{name:"zs"}的条数
g.模糊查询
db.person.find({name:/^z/})
h.条件查询1
> $gt
>= $gte
< $lt
<= $lte
!= $ne
between $in/$nin
and $and
or $or:[{}, {}]
i.条件查询2
db.collection.find({age:{$gt:18}}); --示例:》
db.collection.find({age:{$ne:18}}); --示例:!=
db.collection.find({field:{$in:array}}); --示例:in
db.collection.find({field:{$nin:array}}); --示例:not in
db.collection.find({title:{$exists:true}}); --示例:is exist
db.collection.find( { name : /acme.*corp/i } ); --示例:reg
db.collection.find( { name : { $not : /acme.*corp/i } } ); --示例:not
01.数据库
show dbs --查看数据库列表
show collections --显示当前数据库中的集合
show users --显示用户
---------------------------------------------------------------------------------------------------------
use myDatabase --创建或切换数据库(若不存在,创建)
show collections --查看集合
db --显示当前数据库
db.dropDatabase() --删除数据库(先选中数据库)
---------------------------------------------------------------------------------------------------------
db.help() --显示数据库操作命令
db.foo.help() --显示集合操作命令,foo代指当前数据库
db.foo.find() --当前集合数据查找
db.foo.find({a:1}) --当前集合数据查找,条件查询
db.foo.find({a:1},{column:0}) --当前集合数据查找,条件查询
02.集合:表集合+表设计
show collections --查看集合
db.createCollection("collection") --创建集合
db.collection.drop() --删除集合
---------------------------------------------------------------------------------------------------------
db.adminCommand({ --必须管理员权限
renameCollection: "myDatabase.collection", --集合必须存在:若集合不存在,命令将会失败。
to: "myDatabase.newCollection" --目标名称不可重复:目标名称的集合若已存在,命令也会失败。
})
---------------------------------------------------------------------------------------------------------
db.createCollection("myComplexCollection", {
capped: true,
size: 10485760,
max: 5000,
validator: { $jsonSchema: {
bsonType: "object",
required: ["name", "email"],
properties: {
name: {
bsonType: "string",
description: "必须为字符串且为必填项"
},
email: {
bsonType: "string",
pattern: "^.+@.+$",
description: "必须为有效的电子邮件地址"
}
}
}},
validationLevel: "strict",
validationAction: "error",
storageEngine: {
wiredTiger: { configString: "block_compressor=zstd" }
},
collation: { locale: "en", strength: 2 }
});
03.文档:行,一条数据
01.INSERT
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
如果要插入的 collection 当前不存在,则插入操作会自动创建 collection。
在 MongoDB 中,存储在集合中的每个文档都需要一个唯一的 _id (opens new window)字段作为主键。如果插入的文档省略 _id 字段,则 MongoDB 驱动程序会自动为 _id 字段生成 ObjectId。
可以 MongoDB 写入操作的确认级别来控制写入行为。
-----------------------------------------------------------------------------------------------------
db.collection.insertOne() :插入一条 document
db.collection.insertMany() :插入多条 document
b.insert方法
a.语法
db.集合名.insert(json数据)
集合存在则直接插入数据,不存在则隐式创建集合并插入数据
json数据格式要求key得加"",但这里为了方便查看,对象的key统一不加"";查看集合数据时系统会自动给key加""
mongodb会自动给每条数据创建全球唯一的_id键(我们也可以自定义_id的值,只要给插入的json数据增加_id键即可覆盖,但是不推荐这样做)
b.示例
db.users.insert({"name": "Alice","age": 24,"city": "New York"});
db.users.insert([{ "_id": 1, "name": "Bob", "age": 30, "city": "Los Angeles" },{ "_id": 2, "name": "Charlie", "age": 28, "city": "Chicago" }]);
for(var i=1;i<10;i++){
db.users.insert({name:"a"+i,age:i})
}
c.insertOne:插入一条
db.inventory.insertOne({
item: 'canvas',
qty: 100,
tags: ['cotton'],
size: { h: 28, w: 35.5, uom: 'cm' }
})
d.insertMany:插入多条
db.inventory.insertMany([
{
item: 'journal',
qty: 25,
tags: ['blank', 'red'],
size: { h: 14, w: 21, uom: 'cm' }
},
{
item: 'mat',
qty: 85,
tags: ['gray'],
size: { h: 27.9, w: 35.5, uom: 'cm' }
}
])
02.QUERY
a.find方法
a.语法
db.集合名.find(条件 [,查询的列])
db.集合名.find(条件 [,查询的列]).pretty() #格式化查看
-------------------------------------------------------------------------------------------------
# 条件
- 查询所有数据 {}或不写
- 查询指定要求数据 {key:value}或{key:{运算符:value}}
# 查询的列(可选参数)
- 不写则查询全部列
- {key:1} 只显示key列
- {key:0} 除了key列都显示
- 注意:_id列都会存在
b.示例
db.inventory.find() --查看全部数据
db.inventory.find({id:"2"}) --查看多条数据{id:"2"}
db.inventory.find().limit(2) --limit:2条
b.$type:筛选具有特定数据类型的文档
a.语法
{ "field": { "$type": "type" } }
b.数据类型的表示
字符串类型:例如 "string" 表示字符串。
数字类型:例如 "double" 表示双精度浮点数。
整数类型:例如 "int" 表示整数。
对象类型:例如 "object" 表示文档。
数组类型:例如 "array" 表示数组。
布尔类型:例如 "bool" 表示布尔值。
日期类型:例如 "date" 表示日期。
null 类型:例如 "null" 表示 null 值。
-------------------------------------------------------------------------------------------------
除了使用类型的名称外,还可以使用 BSON 类型的数字表示。例如,1 表示 double,2 表示 string,3 表示 object,以此类推。
c.示例
a.数据
{ "_id": 1, "name": "Alice", "age": 30, "isActive": true, "birthdate": ISODate("1990-01-01") }
{ "_id": 2, "name": "Bob", "age": "twenty-five", "isActive": false, "birthdate": null }
{ "_id": 3, "name": "Charlie", "age": 25, "isActive": true, "birthdate": ISODate("1995-05-15") }
b.查询所有年龄为整数类型的文档:
db.people.find({ "age": { "$type": "int" } })
c.查询所有出生日期为日期类型的文档:
db.people.find({ "birthdate": { "$type": "date" } })
d.查询所有活动状态为布尔类型的文档:
db.people.find({ "isActive": { "$type": "bool" } })
e.查询所有名称为字符串类型的文档:
db.people.find({ "name": { "$type": 2 } }) // 2 表示字符串
f.例如,查询年龄为整数且活动状态为布尔值的文档
db.people.find({
"age": { "$type": "int" },
"isActive": { "$type": "bool" }
})
c.findAndModify()、findOneAndUpdate()、findOneAndReplace()
a.准备数据
db.users.insertMany([
{ name: "Alice", age: 24 },
{ name: "Bob", age: 29 },
{ name: "Charlie", age: 34 }
]);
b.使用 db.collection.findAndModify() 和 upsert: true
findAndModify 方法用于查找符合指定条件的文档并对其进行修改。
当与 upsert: true 一起使用时,如果指定条件的文档不存在,MongoDB会创建一个新的文档,并根据提供的更新操作进行设置。
此外,findAndModify 还可以指定返回更新前或更新后的文档,便于获取最终结果。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "David" 的文档。如果找不到该文档,则会创建新文档
db.users.findAndModify({
query: { name: "David" },
update: { $set: { age: 28 } },
upsert: true,
new: true
});
结果:name: "David" 的文档不存在,因此会创建新的 { name: "David", age: 28 } 文档。
c.使用 db.collection.findOneAndUpdate() 和 upsert: true
findOneAndUpdate 方法用于查找符合条件的单个文档并对其进行更新操作。
当设置 upsert: true 时,MongoDB在文档不存在的情况下会插入一个新文档。
此方法通常用于需要在符合条件的文档不存在时自动插入的场景。
findOneAndUpdate 也可以通过 returnDocument 参数指定是否返回更新前或更新后的文档。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "Alice" 的文档。如果找到,将更新其 age 字段;如果找不到,则会创建新文档:
db.users.findOneAndUpdate(
{ name: "Alice" },
{ $set: { age: 26 } },
{ upsert: true, returnDocument: "after" }
);
结果:name: "Alice" 的文档存在,因此 age 字段会更新为 26。
d.使用 db.collection.findOneAndReplace() 和 upsert: true
findOneAndReplace 方法查找符合条件的单个文档并将其完全替换为新的文档内容。
当 upsert: true 被设置时,如果指定条件的文档不存在,MongoDB会创建一个新文档,且该文档的内容会完全按照提供的替换内容设置。
此方法适用于需要按特定结构完全替换文档,或在不存在时创建该结构的场景。
-------------------------------------------------------------------------------------------------
将尝试查找 name: "Eve" 的文档。如果找到,将完全替换该文档;如果找不到,将创建新文档:
db.users.findOneAndReplace(
{ name: "Eve" },
{ name: "Eve", age: 22 },
{ upsert: true, returnDocument: "after" }
);
结果:name: "Eve" 的文档不存在,因此会创建新的 { name: "Eve", age: 22 } 文档。
e.最终结果
[
{ "_id": ObjectId("..."), "name": "Alice", "age": 26 },
{ "_id": ObjectId("..."), "name": "Bob", "age": 29 },
{ "_id": ObjectId("..."), "name": "Charlie", "age": 34 },
{ "_id": ObjectId("..."), "name": "David", "age": 28 },
{ "_id": ObjectId("..."), "name": "Eve", "age": 22 }
]
03.UPDATE
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
一旦设置了,就无法更新或替换 _id (opens new window)字段。
除以下情况外,MongoDB 会在执行写操作后保留文档字段的顺序:
_id 字段始终是文档中的第一个字段。
包括重命名字段名称的更新可能导致文档中字段的重新排序。
如果更新操作中包含 upsert : true 并且没有 document 匹配过滤器,MongoDB 会新插入一个 document;如果有匹配的 document,MongoDB 会修改或替换这些 document。
-----------------------------------------------------------------------------------------------------
db.collection.updateOne():更新一条 document
db.collection.updateMany():更新多条 document
db.collection.replaceOne():替换一条 document
-----------------------------------------------------------------------------------------------------
db.collection.updateOne(<filter>, <update>, <options>)
db.collection.updateMany(<filter>, <update>, <options>)
db.collection.replaceOne(<filter>, <update>, <options>)
b.update方法
a.语法1
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
-------------------------------------------------------------------------------------------------
query : update 的查询条件,类似 sql update 查询内 where 后面的。
update : update 的对象和一些更新的操作符(如$,$inc...)等,也可以理解为 sql update 查询内 set 后面的
upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入 objNew, true 为插入,默认是 false不插入
multi : 可选,mongodb 默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
b.语法2
db.集合名.update(条件, 新数据 [,是否新增, 是否修改多条])
-------------------------------------------------------------------------------------------------
# 新数据
- 默认是对原数据进行替换
- 若要进行修改,格式为 {修改器:{key:value}}
# 是否新增
- 条件匹配不到数据时是否插入: true插入,false不插入(默认)
# 是否修改多条
- 条件匹配成功的数据是否都修改: true都修改,false只修改一条(默认)
c.示例
a.默认,只更新第一条记录:
db.collection.update({ count: { $gt: 1 } }, { $set: { test2: 'OK' } })
b.全部更新:
db.collection.update(
{ count: { $gt: 3 } },
{ $set: { test2: 'OK' } },
false,
true
)
c.只添加第一条:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
d.全部添加进去:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
e.全部更新:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
f.只更新第一条记录:
db.collection.update(
{ count: { $gt: 4 } },
{ $set: { test5: 'OK' } },
true,
false
)
c.$set、$unset、$inc
a.说明
$set:添加或更新字段
$unset:删除字段
$rename:重命名字段
$inc:递增,用来增加已有键的值,如果该键不存在就新创建一个
b.准备数据
{ "_id": 1, "name": "Alice", "age": 24, "city": "New York" }
c.使用 $set 添加或更新字段
db.users.updateOne(
{ _id: 1 },
{ $set: { age: 25, country: "USA" } }
);
d.使用 $unset 删除字段
db.users.updateOne(
{ _id: 1 },
{ $unset: { city: "" } }
);
e.使用 $inc 递增字段
使用 $inc 可以将 age 字段递增 1,将 score 字段递增 10:
db.users.updateOne(
{ _id: 1 },
{ $inc: { age: 1, score: 10 } }
);
f.使用 $rename 重命名字段
db.users.updateOne(
{ _id: 1 },
{ $rename: { "city": "location" } }
);
d.数组修改器
a.说明
$push:向数组添加一个元素。
$each:一次性添加多个元素。
$slice:限制数组长度。
$sort:对数组进行排序。
$addToSet:向数组添加唯一元素。
$pop:删除数组的第一个或最后一个元素。
$pull:从数组中删除指定元素。
b.准备数据
{
"_id": 1,
"name": "Alice",
"hobbies": ["reading", "swimming"],
"scores": [10, 20, 30]
}
c.$push 操作符用于向数组字段添加一个新元素
db.users.updateOne(
{ _id: 1 },
{ $push: { hobbies: "cycling" } }
);
d.$each 和 $push 一起使用时可以一次性添加多个元素
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [40, 50] } } }
);
e.$slice 可以在 $push 和 $each 之后使用,控制数组长度。例如,将 scores 数组限制为最多3个元素。
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [60], $slice: -3 } } }
);
f.$sort 可以与 $push 和 $each 一起使用,对数组进行排序。比如对 scores 数组进行降序排列
db.users.updateOne(
{ _id: 1 },
{ $push: { scores: { $each: [], $sort: -1 } } }
);
g.$addToSet 用于向数组中添加元素,如果该元素不存在。重复元素不会被添加。
db.users.updateOne(
{ _id: 1 },
{ $addToSet: { hobbies: "swimming" } }
);
h.$pop 可以删除数组中的第一个或最后一个元素。使用 1 表示删除最后一个元素,-1 表示删除第一个元素
db.users.updateOne(
{ _id: 1 },
{ $pop: { scores: 1 } }
);
i.$pull 用于删除数组中指定的元素。比如,删除 hobbies 数组中的 "swimming"
db.users.updateOne(
{ _id: 1 },
{ $pull: { hobbies: "swimming" } }
);
j.$ 既然是数组,我们当然可以通过下标来访问
db.posts.insertOne({
"_id": 1,
"title": "MongoDB Array Update",
"comments": [100, 200, 300]
});
-------------------------------------------------------------------------------------------------
db.posts.updateOne(
{ _id: 1 },
{ $set: { "comments.0": 999 } }
);
-------------------------------------------------------------------------------------------------
将 comments 数组中下标为 0 的元素(即第一个元素)更新为 999
"comments.0":通过数组的下标访问 comments 数组中的第一个元素。
$set:将指定位置的元素值设置为 999。
e.updateOne、updateMany、replaceOne
a.准备数据
db.inventory.insertMany([
{
item: 'canvas',
qty: 100,
size: { h: 28, w: 35.5, uom: 'cm' },
status: 'A'
},
{ item: 'journal', qty: 25, size: { h: 14, w: 21, uom: 'cm' }, status: 'A' },
{ item: 'mat', qty: 85, size: { h: 27.9, w: 35.5, uom: 'cm' }, status: 'A' },
{
item: 'mousepad',
qty: 25,
size: { h: 19, w: 22.85, uom: 'cm' },
status: 'P'
},
{
item: 'notebook',
qty: 50,
size: { h: 8.5, w: 11, uom: 'in' },
status: 'P'
},
{ item: 'paper', qty: 100, size: { h: 8.5, w: 11, uom: 'in' }, status: 'D' },
{
item: 'planner',
qty: 75,
size: { h: 22.85, w: 30, uom: 'cm' },
status: 'D'
},
{
item: 'postcard',
qty: 45,
size: { h: 10, w: 15.25, uom: 'cm' },
status: 'A'
},
{
item: 'sketchbook',
qty: 80,
size: { h: 14, w: 21, uom: 'cm' },
status: 'A'
},
{
item: 'sketch pad',
qty: 95,
size: { h: 22.85, w: 30.5, uom: 'cm' },
status: 'A'
}
])
b.更新一条 document
db.inventory.updateOne(
{ item: 'paper' },
{
$set: { 'size.uom': 'cm', status: 'P' },
$currentDate: { lastModified: true }
}
)
c.更新多条 document
db.inventory.updateMany(
{ qty: { $lt: 50 } },
{
$set: { 'size.uom': 'in', status: 'P' },
$currentDate: { lastModified: true }
}
)
d.替换一条 document
db.inventory.replaceOne(
{ item: 'paper' },
{
item: 'paper',
instock: [
{ warehouse: 'A', qty: 60 },
{ warehouse: 'B', qty: 40 }
]
}
)
04.DELETE
a.说明
MongoDB 中的所有写操作都是单个文档级别的原子操作。
-----------------------------------------------------------------------------------------------------
db.collection.deleteOne():删除一条 document
db.collection.deleteMany():删除多条 document
b.remove
db.集合名.remove(条件 [,是否删除一条])
# 是否删除一条
- false删除多条,即全部删除(默认)
- true删除一条
-----------------------------------------------------------------------------------------------------
db.inventory.remove({}, true) --删除一条
db.inventory.remove({}, false) --删除全部
b.deleteOne、deleteMany、deleteMany
db.inventory.deleteOne({ status: "A" }) --删除 status 为 "A" 的第一条文档
db.inventory.deleteMany({ status: "D" }) --删除 status 为 "D" 的所有文档
db.inventory.deleteMany({}) --删除全部
04.列,字段的值
a.概念
MongoDB中每条记录称作一个文档,这个文档和我们平时用的JSON有点像,但也不完全一样。
JSON是一种轻量级的数据交换格式。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,
JSON易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,
-----------------------------------------------------------------------------------------------------
但是JSON也有它的局限性,
比如它只有null、布尔、数字、字符串、数组和对象这几种数据类型,没有日期类型,
只有一种数字类型,无法区分浮点数和整数,也没法表示正则表达式或者函数。
-----------------------------------------------------------------------------------------------------
由于这些局限性,BSON闪亮登场啦,
BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,
它和JSON一样,支持内嵌的文档对象和数组对象,
但是BSON有JSON没有的一些数据类型,如Date和BinData类型,
-----------------------------------------------------------------------------------------------------
MongoDB使用BSON做为文档数据存储和网络传输格式。
b.汇总
| 数据类型 | 描述
|--------------------|-------------------------------------------------------------
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
| Boolean | 布尔值。用于存储布尔值(真/假)。
| Double | 双精度浮点值。用于存储浮点值。
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
| Array | 用于将数组或列表或多个值存储为一个键。
| Timestamp | 时间戳。记录文档修改或添加的具体时间。
| Object | 用于内嵌文档。
| Null | 用于创建空值。
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
| Object ID | 对象 ID。用于创建文档的 ID。
| Binary Data | 二进制数据。用于存储二进制数据。
| Code | 代码类型。用于在文档中存储 JavaScript 代码。
| Regular expression | 正则表达式类型。用于存储正则表达式。
c.示例
| 数据类型 | 示例
|--------------------|-------------------------------------------------------------
| String | "name": "Alice"
| Integer | "age": 30
| Boolean | "isActive": true
| Double | "rating": 4.5
| Min/Max keys | MinKey 和 MaxKey
| Array | "tags": ["mongodb", "database", "NoSQL"]
| Timestamp | "createdAt": Timestamp()
| Object | "address": { "city": "New York", "zip": "10001" }
| Null | "middleName": null
| Symbol | "symbol": Symbol("uniqueSymbol")
| Date | "dob": new Date("1990-01-01")
| Object ID | "_id": ObjectId("507f1f77bcf86cd799439011")
| Binary Data | "fileData": BinData(0, "binaryDataInBase64")
| Code | "jsFunction": Code("function() { return 'Hello, World!'; }")
| Regular expression | "pattern": /abc/i
05.bulkWrite()方法
a.bulkWrite()支持以下写操作:
insertOne
updateOne
updateMany
replaceOne
deleteOne
deleteMany
b.示例
try {
db.characters.bulkWrite([
{
insertOne: {
document: {
_id: 4,
char: 'Dithras',
class: 'barbarian',
lvl: 4
}
}
},
{
insertOne: {
document: {
_id: 5,
char: 'Taeln',
class: 'fighter',
lvl: 3
}
}
},
{
updateOne: {
filter: { char: 'Eldon' },
update: { $set: { status: 'Critical Injury' } }
}
},
{ deleteOne: { filter: { char: 'Brisbane' } } },
{
replaceOne: {
filter: { char: 'Meldane' },
replacement: { char: 'Tanys', class: 'oracle', lvl: 4 }
}
}
])
} catch (e) {
print(e)
}
3.2 查询
01.介绍
a.find方法
db.<集合>.find(<JSON>)
b.查询条件
等于 $eq
不等于 $ne
大于 $gt
大于或等于 $gte
小于 $lt
小于或等于 $lte
在指定的数组中 $in
不在指定的数组中 $nin
c.逻辑条件
a.and 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
-------------------------------------------------------------------------------------------------
db.col.find({key1:value1, key2:value2}).pretty()
b.or 条件
MongoDB OR 条件语句使用了关键字 $or
-------------------------------------------------------------------------------------------------
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
d.模糊查询
a.查询 title 包含"教"字的文档
db.col.find({ title: /教/ })
b.查询 title 字段以"教"字开头的文档
db.col.find({ title: /^教/ })
c.查询 titl e 字段以"教"字结尾的文档:
db.col.find({ title: /教$/ })
e.排序
a.语法
db.集合名.find().sort(json数据)
b.说明
# json数据(key:value)
- key就是要排序的字段
- value为1表示升序,-1表示降序
f.分页
a.语法
db.集合名.find().sort().skip(数字).limit(数字)[.count()]
b.说明
# skip(数字)
- 指定跳过的数量(可选)
# limit(数字)
- 限制查询的数量
# count()
- 统计数量
g.skip(), limilt(), sort()
a.总结
skip(), limilt(), sort()三个放在一起执行的时候,
执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
-------------------------------------------------------------------------------------------------
db.集合名.find().sort().skip(数字).limit(数字)[.count()]
b.Limit():读取指定数量的数据
db.COLLECTION_NAME.find().limit(NUMBER)
c.Skip():跳过指定数量的数据
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
d.Sort():对数据进行排序,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列
db.COLLECTION_NAME.find().sort({KEY:1})
h.游标
游标用于处理查询结果集。查询返回的结果不是直接的文档,而是一个游标对象,游标对象允许你逐个访问查询结果中的文档
i.其他
null、正则、数组、嵌套文档、游标
02.示例
a.find方法
a.语法
db.集合名.find(条件 [,查询的列])
db.集合名.find(条件 [,查询的列]).pretty() #格式化查看
-------------------------------------------------------------------------------------------------
# 条件
- 查询所有数据 {}或不写
- 查询指定要求数据 {key:value}或{key:{运算符:value}}
# 查询的列(可选参数)
- 不写则查询全部列
- {key:1} 只显示key列
- {key:0} 除了key列都显示
- 注意:_id列都会存在
b.示例
db.inventory.find() --查看全部数据
db.inventory.find({id:"2"}) --查看多条数据{id:"2"}
db.inventory.find().limit(2) --limit:2条
b.查询条件
a.数据准备
db.products.insertMany([
{ "_id": 1, "name": "Product A", "price": 30, "category": "Electronics" },
{ "_id": 2, "name": "Product B", "price": 20, "category": "Books" },
{ "_id": 3, "name": "Product C", "price": 50, "category": "Electronics" },
{ "_id": 4, "name": "Product D", "price": 15, "category": "Books" },
{ "_id": 5, "name": "Product E", "price": 25, "category": "Clothing" }
]);
b.等于 $eq
查询价格等于 30 的产品:
db.products.find({ "price": { $eq: 30 } });
c.不等于 $ne
查询价格不等于 20 的产品:
db.products.find({ "price": { $ne: 20 } });
d.大于 $gt
查询价格大于 25 的产品:
db.products.find({ "price": { $gt: 25 } });
e.大于或等于 $gte
查询价格大于或等于 30 的产品:
db.products.find({ "price": { $gte: 30 } });
f.小于 $lt
查询价格小于 30 的产品:
db.products.find({ "price": { $lt: 30 } });
g.小于或等于 $lte
查询价格小于或等于 25 的产品:
db.products.find({ "price": { $lte: 25 } });
h.在指定的数组中 $in
查询价格在 20 或 30 的产品:
db.products.find({ "price": { $in: [20, 30] } });
i.不在指定的数组中 $nin
查询价格不在 15 和 20 的产品:
db.products.find({ "price": { $nin: [15, 20] } });
c.逻辑条件
a.准备数据
db.students.insertMany([
{ "_id": 1, "name": "Alice", "age": 20, "major": "Computer Science" },
{ "_id": 2, "name": "Bob", "age": 22, "major": "Mathematics" },
{ "_id": 3, "name": "Charlie", "age": 23, "major": "Computer Science" },
{ "_id": 4, "name": "David", "age": 21, "major": "Engineering" },
{ "_id": 5, "name": "Eva", "age": 20, "major": "Mathematics" }
]);
b.使用 AND 条件
在 MongoDB 中,AND 条件可以通过在 find() 方法中传入多个键值对来实现。这种情况下,所有条件都必须满足。
查询年龄为 20 并且专业为 "Computer Science" 的学生:
db.students.find({ "age": 20, "major": "Computer Science" }).pretty();
c.使用 OR 条件
使用 $or 关键字来组合多个条件,只需满足其中一个条件即可。
查询专业为 "Mathematics" 或者年龄为 22 的学生:
db.students.find(
{
$or: [
{ "major": "Mathematics" },
{ "age": 22 }
]
}
).pretty();
该查询会返回专业为 "Mathematics" 的学生,或者年龄为 22 的学生。
d.模糊查询
a.准备数据
db.books.insertMany([
{ "_id": 1, "title": "数学教科书" },
{ "_id": 2, "title": "历史教科书" },
{ "_id": 3, "title": "物理基础教案" },
{ "_id": 4, "title": "化学实验指导" },
{ "_id": 5, "title": "教与学的思考" },
{ "_id": 6, "title": "教父" },
{ "_id": 7, "title": "计算机教案" }
]);
b.查询 title 包含 "教" 字的文档
db.books.find({ title: /教/ }).pretty();
c.查询 title 字段以 "教" 字开头的文档
db.books.find({ title: /^教/ }).pretty();
d.查询 title 字段以 "教" 字结尾的文档
db.books.find({ title: /教$/ }).pretty();
e.排序
a.数据准备
for(var i=1;i<5;i++){
db.person.insert({_id:i, name:"p"+i, age:10+i})
}
b.按年龄降序排列
db.person.find().sort({age: -1})
c.降序查询两条数据
db.person.find().sort({age: -1}).limit(2)
d.降序跳过两条数据,查询两条数据
db.person.find().sort({age: -1}).skip(2).limit(2)
f.分页
a.skip计算公式: (当前页-1)*每页显示的条数
页数 起始 终止 跳过数
1页 1 2 0
2页 3 4 2
3页 5 6 4
4页 7 8 6
5页 9 10 8
b.数据准备
for(var i=1;i<11;i++){
db.page.insert({_id:i,name:"p"+i})
}
c.分5页,每页2条显示
for(var i=0;i<10;i=i+2){
db.page.find().skip(i).limit(2)
}
g.skip(), limilt(), sort()
a.准备数据
db.products.insertMany([
{ "_id": 1, "name": "Product A", "price": 30 },
{ "_id": 2, "name": "Product B", "price": 20 },
{ "_id": 3, "name": "Product C", "price": 50 },
{ "_id": 4, "name": "Product D", "price": 15 },
{ "_id": 5, "name": "Product E", "price": 25 },
{ "_id": 6, "name": "Product F", "price": 35 },
{ "_id": 7, "name": "Product G", "price": 45 },
{ "_id": 8, "name": "Product H", "price": 10 },
{ "_id": 9, "name": "Product I", "price": 60 },
{ "_id": 10, "name": "Product J", "price": 5 }
]);
b.使用 sort()
该查询将所有产品按价格升序排列(1 表示升序)
db.products.find().sort({ price: 1 }).pretty();
c.使用 limit()
要读取前 5 个产品,可以使用 limit() 方法
db.products.find().limit(5).pretty();
d.使用 skip()
如果我们希望跳过前 3 个产品,并获取接下来的 5 个产品,可以组合使用 skip() 和 limit():
db.products.find().skip(3).limit(5).pretty();
e.组合使用 sort()、skip() 和 limit()
将这三者结合在一起,首先按价格升序排序,跳过前 2 个产品,然后限制返回的数量为 3:
db.products.find().sort({ price: 1 }).skip(2).limit(3).pretty();
h.游标
a.准备数据
db.products.insertMany([
{ "_id": 1, "name": "Product A", "price": 30 },
{ "_id": 2, "name": "Product B", "price": 20 },
{ "_id": 3, "name": "Product C", "price": 50 },
{ "_id": 4, "name": "Product D", "price": 15 },
{ "_id": 5, "name": "Product E", "price": 25 }
]);
b.基本游标
当你使用 find() 方法查询数据时,它返回一个游标。你可以使用游标的方法来逐个访问文档。
const cursor = db.products.find();
// 遍历游标
cursor.forEach(function(doc) {
printjson(doc);
});
c.使用 limit() 和游标
你该查询将返回前 3 个产品,并通过 forEach 遍历并打印这些产品。
const cursor = db.products.find().limit(3);
// 遍历游标
cursor.forEach(function(doc) {
printjson(doc);
});
d.使用 skip() 和游标
结合 skip() 和游标可以实现分页查询:
const cursor = db.products.find().skip(2).limit(3);
// 遍历游标
cursor.forEach(function(doc) {
printjson(doc);
});
该查询将跳过前 2 个产品,返回接下来的 3 个产品。
e.游标还提供其他方法,如 sort()、count() 等,可以结合使用:
const cursor = db.products.find().sort({ price: -1 }).limit(5);
// 打印总数
print("Total Count: " + cursor.count());
// 遍历游标
cursor.forEach(function(doc) {
printjson(doc);
});
i.其他
a.准备数据
db.users.insertMany([
{ "_id": 1, "name": "Alice", "age": 30, "hobbies": ["reading", "hiking"], "address": { "city": "New York", "zip": null } },
{ "_id": 2, "name": "Bob", "age": 22, "hobbies": ["gaming", "sports"], "address": { "city": "Los Angeles", "zip": "90001" } },
{ "_id": 3, "name": "Charlie", "age": 25, "hobbies": ["music", "reading"], "address": { "city": "Chicago", "zip": "60601" } },
{ "_id": 4, "name": "David", "age": 28, "hobbies": ["sports"], "address": { "city": "New York", "zip": "10001" } },
{ "_id": 5, "name": "Eva", "age": 27, "hobbies": ["music", "hiking"], "address": { "city": "San Francisco", "zip": null } }
]);
b.null:查询 zip 为 null 的用户
db.users.find({ "address.zip": null }).pretty();
c.正则:查询名字以 "A" 开头的用户
db.users.find({ name: /^A/ }).pretty();
d.数组:查询爱好中包含 "music" 的用户:
db.users.find({ hobbies: "music" }).pretty();
e.嵌套文档:查询住在 "New York" 的用户
db.users.find({ "address.city": "New York" }).pretty();
3.3 聚合
01.介绍
a.概念
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),
并返回计算后的数据结果。有点类似 sql 语句中的 count(*)。
b.管道
整个聚合运算过程称为管道,它是由多个步骤组成,每个管道
1.接受一系列文档(原始数据);
2.每个步骤对这些文档进行一系列运算;
3.结果文档输出给下一个步骤;
c.聚合操作的基本格式
pipeline = [$stage1, $stage1, ..., $stageN];
db.<集合>.aggregate(pipeline, {options});
d.常用管道
步骤 作用 SQL等价运算符
$match 过滤 WHERE
$project 投影 AS
$sort 排序 ORDER BY
$group 分组 GROUP BY
$skip / $limit 结果限制 SKIP / LIMIT
$lookup 左外连接 LEFT OUTER JOIN
$unwind 展开数组
$graphLookup 图搜索
$facet / $bucket 分面搜索
-----------------------------------------------------------------------------------------------------
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
e.常用管道
| SQL | MongoDB Aggregation Operators
|------------------------------------|------------------------------
| WHERE | $match
| GROUP BY | $group
| HAVING | $match
| SELECT | $project
| ORDER BY | $sort
| LIMIT | $limit
| SUM() | $sum
| COUNT() | $sum $sortByCount
| JOIN | $lookup
| SELECT INTO NEW_TABLE | $out
| MERGE INTO TABLE | $merge
| UNION ALL | $unionWith
f.常用表达式
| 表达式 | 描述 | 实例
|-----------|--------------------------------------------|---------------------------------------------------------------------------------------
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
g.聚合示例
> db.collection.insertMany([{"title":"MongoDB Overview","description":"MongoDB is no sql database","by_user":"collection","tagsr":["mongodb","database","NoSQL"],"likes":"100"},{"title":"NoSQL Overview","description":"No sql database is very fast","by_user":"collection","tagsr":["mongodb","database","NoSQL"],"likes":"10"},{"title":"Neo4j Overview","description":"Neo4j is no sql database","by_user":"Neo4j","tagsr":["neo4j","database","NoSQL"],"likes":"750"}])
> db.collection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
-----------------------------------------------------------------------------------------------------
{ "_id" : null, "num_tutorial" : 3 }
{ "_id" : "Neo4j", "num_tutorial" : 1 }
{ "_id" : "collection", "num_tutorial" : 2 }
02.示例1
a.数据准备
db.people.insert({_id:1,name:"a",sex:"男",age:21})
db.people.insert({_id:2,name:"b",sex:"男",age:20})
db.people.insert({_id:3,name:"c",sex:"女",age:20})
db.people.insert({_id:4,name:"d",sex:"女",age:18})
db.people.insert({_id:5,name:"e",sex:"男",age:19})
b.统计男生、女生的总年龄
db.people.aggregate([
{$group:{_id:"$sex",age_sum:{$sum:"$age"}}}
])
c.统计男生女生的总人数
db.people.aggregate([
{$group:{_id:"$sex",sum:{$sum:1}}}
])
d.求学生总数和平均年龄
db.people.aggregate([
{$group:{_id:null,total_num:{$sum:1},total_avg:{$avg:"$age"}}}
])
e.查询男生、女生人数,按人数升序
db.people.aggregate([
{$group:{_id:"$sex",rs:{$sum:1}}},
{$sort:{rs:1}}
])
03.示例2
a.数据准备
// 创建 sales 集合并插入数据
db.sales.insertMany([
{ _id: 1, item: "Apple", quantity: 10, price: 1.0, category: "Fruits", store: "Store A" },
{ _id: 2, item: "Banana", quantity: 5, price: 0.5, category: "Fruits", store: "Store A" },
{ _id: 3, item: "Carrot", quantity: 7, price: 0.8, category: "Vegetables", store: "Store B" },
{ _id: 4, item: "Apple", quantity: 8, price: 1.0, category: "Fruits", store: "Store B" },
{ _id: 5, item: "Banana", quantity: 2, price: 0.5, category: "Fruits", store: "Store B" },
{ _id: 6, item: "Eggplant", quantity: 4, price: 1.2, category: "Vegetables", store: "Store C" },
{ _id: 7, item: "Tomato", quantity: 6, price: 0.6, category: "Vegetables", store: "Store A" }
]);
b.$match
过滤出所有 Fruits 类别的销售记录。
db.sales.aggregate([
{ $match: { category: "Fruits" } }
]);
c.$project
修改输入文档的结构,只保留 item 和 price 字段,并将 price 字段重命名为 cost。
db.sales.aggregate([
{ $project: { item: 1, cost: "$price" } }
]);
d.$sort
对销售记录按 quantity 降序排序。
db.sales.aggregate([
{ $sort: { quantity: -1 } }
]);
e.$group
按 item 字段分组,计算每个项目的总销售数量和总收入。
db.sales.aggregate([
{
$group: {
_id: "$item",
totalQuantity: { $sum: "$quantity" },
totalRevenue: { $sum: { $multiply: ["$quantity", "$price"] } }
}
}
]);
f.$skip 和 $limit
跳过前 2 条记录,并限制返回 3 条记录。
db.sales.aggregate([
{ $sort: { price: 1 } }, // 先排序
{ $skip: 2 }, // 跳过前 2 条
{ $limit: 3 } // 限制返回 3 条记录
]);
g.$unwind
将 sales 文档中的某个数组类型字段展开为多条记录。假设我们在 sales 中有一个 tags 字段。
db.sales.insertMany([
{ _id: 8, item: "Cucumber", quantity: 10, price: 0.4, tags: ["vegetable", "salad"] },
{ _id: 9, item: "Spinach", quantity: 5, price: 0.5, tags: ["vegetable", "healthy"] }
]);
db.sales.aggregate([
{ $unwind: "$tags" } // 将 tags 字段展开
]);
h.$lookup
执行左外连接,连接到另一个集合,假设我们有一个 stores 集合。
// 创建 stores 集合
db.stores.insertMany([
{ _id: "Store A", location: "City Center" },
{ _id: "Store B", location: "North Side" },
{ _id: "Store C", location: "South Side" }
]);
db.sales.aggregate([
{
$lookup: {
from: "stores",
localField: "store",
foreignField: "_id",
as: "storeDetails"
}
}
]);
i.$facet 和 $bucket
db.sales.aggregate([
{
$facet: {
fruits: [
{ $match: { category: "Fruits" } },
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } }
],
vegetables: [
{ $match: { category: "Vegetables" } },
{ $group: { _id: "$item", totalQuantity: { $sum: "$quantity" } } }
]
}
}
]);
3.4 事务
01.介绍
a.介绍
在 MongoDB 中,对单个文档的操作具有原子性。
由于您可以使用嵌入式文档和数组来捕获单个文档结构中数据之间的关系,
而无需跨多个文档和集合进行标准化,因此这种单文档原子性消除了许多实际使用案例使用分布式事务的必要性。
-----------------------------------------------------------------------------------------------------
对于需要对多个文档(在单个或多个集合中)的读写操作具有原子性的情况,MongoDB 支持多文档事务。
利用分布式事务,可以跨多个操作、集合、数据库、文档和分片使用事务。
-----------------------------------------------------------------------------------------------------
MongoDB 支持多文档事务,使得你可以在多个集合中原子性地执行多个操作。
事务提供了确保操作的 ACID(原子性、一致性、隔离性、持久性)特性。
b.writeConcern 可以决定写操作到达多少个节点才算成功。
默认:多节点复制集不做任何设定,所以是有可能丢失数据。
w: "majority":大部分节点确认,就视为写成功
w: "all":全部节点确认,才视为写成功
c.journal 则定义如何才算成功。取值包括:
true:写操作落到 journal 文件中才算成功;
false:写操作达到内存即算作成功。
02.示例1
a.在集群中使用 writeConcern 参数
db.transaction.insert({ count: 1 }, { writeConcern: { w: 'majoriy' } })
db.transaction.insert({ count: 1 }, { writeConcern: { w: '4' } })
db.transaction.insert({ count: 1 }, { writeConcern: { w: 'all' } })
b.配置延迟节点,模拟网络延迟
conf=rs.conf()
conf.memebers[2].slaveDelay=5
conf.memebers[2].priority=0
rs.reconfig(conf)
03.示例2
a.准备数据
首先,创建一个数据库和两个集合,并插入一些示例数据。
我们将创建两个集合:accounts 和 transactions,用来模拟资金转账的场景。
-----------------------------------------------------------------------------------------------------
// 切换到测试数据库
use testDB;
// 创建 accounts 集合并插入数据
db.accounts.insertMany([
{ _id: 1, name: "Alice", balance: 1000 },
{ _id: 2, name: "Bob", balance: 500 }
]);
// 创建 transactions 集合
db.createCollection("transactions");
b.使用事务
我们将进行一个简单的资金转账操作,将 Alice 的 100 元转账给 Bob。我们将使用事务来确保操作的原子性
-----------------------------------------------------------------------------------------------------
// 开始一个会话
const session = db.getMongo().startSession();
session.startTransaction();
try {
// 从 Alice 的账户中扣除 100 元
db.accounts.updateOne(
{ _id: 1 }, // 查找 Alice 的账户
{ $inc: { balance: -100 } }, // 扣除 100 元
{ session } // 指定会话
);
// 向 Bob 的账户中添加 100 元
db.accounts.updateOne(
{ _id: 2 }, // 查找 Bob 的账户
{ $inc: { balance: 100 } }, // 添加 100 元
{ session } // 指定会话
);
// 插入交易记录
db.transactions.insertOne(
{
from: "Alice",
to: "Bob",
amount: 100,
date: new Date()
},
{ session } // 指定会话
);
// 提交事务
session.commitTransaction();
print("Transaction committed.");
} catch (error) {
// 发生错误,回滚事务
session.abortTransaction();
print("Transaction aborted due to error: " + error);
} finally {
// 结束会话
session.endSession();
}
c.查询结果
事务完成后,我们可以检查 accounts 集合和 transactions 集合的结果,以确认资金转账是否成功。
// 查询 accounts 集合
print("Accounts:");
db.accounts.find().pretty();
// 查询 transactions 集合
print("Transactions:");
db.transactions.find().pretty();
-----------------------------------------------------------------------------------------------------
查询结果示例:
accounts 集合:
{ "_id": 1, "name": "Alice", "balance": 900 }
{ "_id": 2, "name": "Bob", "balance": 600 }
transactions 集合:
{ "_id": ObjectId("..."), "from": "Alice", "to": "Bob", "amount": 100, "date": ISODate("...") }
3.5 索引
00.总结
a.创建索引
db.集合名.createIndex({key1:方式,key2:方式} [,额外选项])
b.查看索引
db.集合名.getIndexes()
c.删除索引
# 删除全部索引
db.集合名.dropIndexes()
# 删除指定索引
db.集合名.dropIndex(索引名)
d.索引分类
单字段索引:基于单个字段的索引
复合索引:基于多个字段组合的索引
文本索引:用于支持全文搜索
地理空间索引:用于地理空间数据的查询
哈希索引:用于对字段值进行哈希处理的索引
e.如何选择合适的列创建索引?
为常做条件、排序、分组的字段建立索引
选择唯一性索引
选择较小的数据列,为较长的字符串使用前缀索引
f.三种扫描方式
COLLSCAN:全盘扫描
INSCAN:索引扫描
FETCH:根据索引去检索指定document
01.索引
a.概念
索引通常能够极大的提高查询的效率,
如果没有索引,MongoDB 在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,
查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,
索引是对数据库表中一列或多列的值进行排序的一种结构。
-----------------------------------------------------------------------------------------------------
MongoDB 支持多文档事务,使得你可以在多个集合中原子性地执行多个操作。
事务提供了确保操作的 ACID(原子性、一致性、隔离性、持久性)特性。
以下是如何在 MongoDB 中使用事务的示例,包括数据准备和事务执行。
-----------------------------------------------------------------------------------------------------
索引是一种排序好的便于快速查询数据的数据结构,用于帮助数据库高效的查询数据
优点:
提高数据查询的效率,降低数据库的IO成本
通过索引对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
占用磁盘空间
大量索引影响SQL语句的执行效率,因为每次插入和修改数据都要更新索引
b.语法
a.创建
# 创建索引
db.集合名.createIndex(待创建索引的列:方式 [,额外选项])
# 创建复合索引
db.集合名.createIndex({key1:方式,key2:方式} [,额外选项])
# 参数说明:
- `待创建索引的列:方式`:{key:1}/{key:-1}
1表示升序,-1表示降序; 例如{age:1}表示创建age索引并按照升序方法排列
- `额外选项`:设置索引的名称或者唯一索引等
设置名称:{name:索引名}
唯一索引:{unique:列名}
b.查看索引
db.集合名.getIndexes()
c.删除索引
# 删除全部索引
db.集合名.dropIndexes()
# 删除指定索引
db.集合名.dropIndex(索引名)
d.索引分类
单字段索引:基于单个字段的索引
复合索引:基于多个字段组合的索引
文本索引:用于支持全文搜索
地理空间索引:用于地理空间数据的查询
哈希索引:用于对字段值进行哈希处理的索引
e.如何选择合适的列创建索引?
为常做条件、排序、分组的字段建立索引
选择唯一性索引
选择较小的数据列,为较长的字符串使用前缀索引
f.三种扫描方式
COLLSCAN:全盘扫描
INSCAN:索引扫描
FETCH:根据索引去检索指定document
c.createIndex
a.说明
MongoDB 使用 createIndex() 方法来创建索引。
-------------------------------------------------------------------------------------------------
createIndex()方法基本语法格式如下所示:
db.collection.createIndex(keys, options)
-------------------------------------------------------------------------------------------------
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可
db.col.createIndex({"title":1})
-------------------------------------------------------------------------------------------------
createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)
>db.col.createIndex({"title":1,"description":-1})
b.createIndex()接收可选参数,可选参数列表如下:
| Parameter | Type | Description
|--------------------|---------------|----------------------------------------------------------------------------------------
| background | Boolean | 建索引过程会阻塞其它数据库操作,background 可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。
| unique | Boolean | 建立的索引是否唯一。指定为 true 创建唯一索引。默认值为false.
| name | string | 索引的名称。如果未指定,MongoDB 的通过连接索引的字段名和排序顺序生成一个索引名称。
| dropDups | Boolean | **3.0+版本已废弃。**在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false。
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为 true 的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false.
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间。
| v | index version | 索引的版本号。默认的索引版本取决于 mongod 创建索引时运行的版本。
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的 language,默认值为 language.
02.索引计划
a.基本用法
a.语法
db.sang_collect.find({x:1}).explain()
b.结果
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "sang.sang_collect",
"indexFilterSet" : false,
"parsedQuery" : {
"x" : {
"$eq" : 1.0
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"x" : {
"$eq" : 1.0
}
},
"direction" : "forward"
},
"rejectedPlans" : []
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "3.4.9",
"gitVersion" : "876ebee8c7dd0e2d992f36a848ff4dc50ee6603e"
},
"ok" : 1.0
}
c.说明
返回结果包含两大块信息,一个是queryPlanner,即查询计划,还有一个是serverInfo,即MongoDB服务的一些信息。
-------------------------------------------------------------------------------------------------
| 参数 | 含义
|----------------|------------------------------------------------------------------------------
| plannerVersion | 查询计划版本
| namespace | 要查询的集合
| indexFilterSet | 是否使用索引
| parsedQuery | 查询条件,此处为x=1
| winningPlan | 最佳执行计划
| stage | 查询方式,常见的有COLLSCAN/全表扫描、IXSCAN/索引扫描、FETCH/根据索引去检索文档、SHARD_MERGE/合并分片结果、IDHACK/针对_id进行查询
| filter | 过滤条件
| direction | 搜索方向
| rejectedPlans | 拒绝的执行计划
| serverInfo | MongoDB服务器信息
b.explain()也接收不同的参数
a.queryPlanner
queryPlanner是默认参数,添加queryPlanner参数的查询结果就是我们上文看到的查询结果
b.executionStats
executionStats会返回最佳执行计划的一些统计信息,如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "sang.sang_collect",
"indexFilterSet" : false,
"parsedQuery" : {},
"winningPlan" : {
"stage" : "COLLSCAN",
"direction" : "forward"
},
"rejectedPlans" : []
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 10000,
"executionTimeMillis" : 4,
"totalKeysExamined" : 0,
"totalDocsExamined" : 10000,
"executionStages" : {
"stage" : "COLLSCAN",
"nReturned" : 10000,
"executionTimeMillisEstimate" : 0,
"works" : 10002,
"advanced" : 10000,
"needTime" : 1,
"needYield" : 0,
"saveState" : 78,
"restoreState" : 78,
"isEOF" : 1,
"invalidates" : 0,
"direction" : "forward",
"docsExamined" : 10000
}
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "3.4.9",
"gitVersion" : "876ebee8c7dd0e2d992f36a848ff4dc50ee6603e"
},
"ok" : 1.0
}
-------------------------------------------------------------------------------------------------
| 参数 | 含义
|-----------------------------|-----------------------------
| executionSuccess | 是否执行成功
| nReturned | 返回的结果数
| executionTimeMillis | 执行耗时
| totalKeysExamined | 索引扫描次数
| totalDocsExamined | 文档扫描次数
| executionStages | 这个分类下描述执行的状态
| stage | 扫描方式,具体可选值与上文的相同
| nReturned | 查询结果数量
| executionTimeMillisEstimate | 预估耗时
| works | 工作单元数,一个查询会分解成小的工作单元
| advanced | 优先返回的结果数
| docsExamined | 文档检查数目,与totalDocsExamined一致
c.allPlansExecution
allPlansExecution用来获取所有执行计划,结果参数基本与上文相同
03.索引示例
a.API
a.创建索引
db.集合名.createIndex({key1:方式,key2:方式} [,额外选项])
b.查看索引
db.集合名.getIndexes()
c.删除索引
# 删除全部索引
db.集合名.dropIndexes()
# 删除指定索引
db.集合名.dropIndex(索引名)
d.索引分类
单字段索引:基于单个字段的索引
复合索引:基于多个字段组合的索引
文本索引:用于支持全文搜索
地理空间索引:用于地理空间数据的查询
哈希索引:用于对字段值进行哈希处理的索引
b.单字段索引
描述:基于单个字段的索引,适用于单个字段的查询。
-----------------------------------------------------------------------------------------------------
首先,插入一些数据:
db.users.insertMany([
{ name: "Alice", age: 25 },
{ name: "Bob", age: 30 },
{ name: "Charlie", age: 35 }
]);
-----------------------------------------------------------------------------------------------------
创建单字段索引:
db.users.createIndex({ name: 1 }); // 1 表示升序索引
-----------------------------------------------------------------------------------------------------
查询时使用索引:
db.users.find({ name: "Alice" });
c.唯一索引
唯一索引:用于确保集合中的某个字段或字段组合的值是唯一的
-----------------------------------------------------------------------------------------------------
db.users.insertMany([
{ username: "alice", email: "alice@example.com" },
{ username: "bob", email: "bob@example.com" },
{ username: "charlie", email: "charlie@example.com" }
]);
-----------------------------------------------------------------------------------------------------
创建一个唯一索引,例如在 username 字段上:
db.users.createIndex({ username: 1 }, { unique: true });
d.复合索引
描述:基于多个字段组合的索引,适用于多个字段的查询。
-----------------------------------------------------------------------------------------------------
创建复合索引:
db.users.createIndex({ name: 1, age: 1 }); // 先按 name 排序,再按 age 排序
-----------------------------------------------------------------------------------------------------
查询时使用复合索引:
db.users.find({ name: "Alice", age: 25 });
e.文本索引
描述:用于支持全文搜索,适合对字符串内容的搜索。
-----------------------------------------------------------------------------------------------------
插入包含文本的文档:
db.articles.insertMany([
{ title: "MongoDB Basics", content: "Learn MongoDB in this tutorial." },
{ title: "Advanced MongoDB", content: "Dive deeper into MongoDB features." }
]);
-----------------------------------------------------------------------------------------------------
创建文本索引:
db.articles.createIndex({ content: "text" });
-----------------------------------------------------------------------------------------------------
查询包含特定词的文档:
db.articles.find({ $text: { $search: "MongoDB" } });
f.地理空间索引
描述:用于地理空间数据的查询,支持地理位置的查询和距离计算。
-----------------------------------------------------------------------------------------------------
插入带有地理坐标的文档:
db.places.insertMany([
{ name: "Place A", location: { type: "Point", coordinates: [102.0, 0.5] } },
{ name: "Place B", location: { type: "Point", coordinates: [103.0, 1.5] } }
]);
-----------------------------------------------------------------------------------------------------
创建地理空间索引:
db.places.createIndex({ location: "2dsphere" });
-----------------------------------------------------------------------------------------------------
查询靠近某个点的地方:
db.places.find({
location: {
$near: {
$geometry: {
type: "Point",
coordinates: [102.0, 0.5]
},
$maxDistance: 10000 // 单位为米
}
}
});
g.哈希索引
描述:用于对字段值进行哈希处理的索引,适用于具有唯一性且需要快速查找的场景。
-----------------------------------------------------------------------------------------------------
创建哈希索引:
db.users.createIndex({ name: "hashed" });
-----------------------------------------------------------------------------------------------------
查询使用哈希索引:
db.users.find({ name: "Alice" });
04.全文检索
a.概念
全文检索对每一个词建立一个索引,指明该词在文章中出现的次数和位置,
当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
这个过程类似于通过字典中的检索字表查字的过程。
b.MongoDB 从 2.4 版本开始支持全文检索,目前支持15种语言的全文索引。
danish
dutch
english
finnish
french
german
hungarian
italian
norwegian
portuguese
romanian
russian
spanish
swedish
turkish
c.启用全文检索
MongoDB 在 2.6 版本以后是默认开启全文检索的,如果你使用之前的版本,你需要使用以下代码来启用全文检索:
>db.adminCommand({setParameter:true,textSearchEnabled:true})
或者使用命令:
mongod --setParameter textSearchEnabled=true
d.创建全文索引
考虑以下 posts 集合的文档数据,包含了文章内容(post_text)及标签(tags):
{
"post_text": "enjoy the mongodb articles on Runoob",
"tags": [
"mongodb",
"runoob"
]
}
-----------------------------------------------------------------------------------------------------
我们可以对 post_text 字段建立全文索引,这样我们可以搜索文章内的内容:
>db.posts.ensureIndex({post_text:"text"})
e.使用全文索引
现在我们已经对 post_text 建立了全文索引,我们可以搜索文章中的关键词 runoob:
>db.posts.find({$text:{$search:"runoob"}})
-----------------------------------------------------------------------------------------------------
以下命令返回了如下包含 runoob 关键词的文档数据:
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on Runoob",
"tags" : [ "mongodb", "runoob" ]
}
-----------------------------------------------------------------------------------------------------
如果你使用的是旧版本的 MongoDB,你可以使用以下命令:
>db.posts.runCommand("text",{search:"runoob"})
使用全文索引可以提高搜索效率。
f.删除全文索引
删除已存在的全文索引,可以使用 find 命令查找索引名:
>db.posts.getIndexes()
-----------------------------------------------------------------------------------------------------
通过以上命令获取索引名,本例的索引名为post_text_text,执行以下命令来删除索引:
>db.posts.dropIndex("post_text_text")
g.示例
a.准备数据
db.posts.insertMany([
{
"post_text": "Enjoy learning MongoDB and its features at Runoob.",
"tags": ["mongodb", "runoob"]
},
{
"post_text": "MongoDB is a NoSQL database that uses JSON-like documents.",
"tags": ["database", "nosql"]
},
{
"post_text": "Learn the basics of MongoDB in a few minutes.",
"tags": ["mongodb", "tutorial"]
},
{
"post_text": "Runoob provides a great platform to learn MongoDB.",
"tags": ["runoob", "mongodb"]
}
]);
b.创建全文索引
在 post_text 字段上创建一个全文索引,以便可以对该字段进行搜索:
db.posts.createIndex({ post_text: "text" });
c.使用全文索引进行查询
现在可以使用 $text 操作符来搜索包含特定关键词的文档。例如,查找包含 "Runoob" 的文章:
db.posts.find({ $text: { $search: "Runoob" } });
-----------------------------------------------------------------------------------------------------
查询结果将返回包含 "Runoob" 的文档:
{
"_id": ObjectId("53493d14d852429c10000004"),
"post_text": "Runoob provides a great platform to learn MongoDB.",
"tags": ["runoob", "mongodb"]
}
{
"_id": ObjectId("53493d14d852429c10000001"),
"post_text": "Enjoy learning MongoDB and its features at Runoob.",
"tags": ["mongodb", "runoob"]
}
d.查询多个关键词
如果需要同时搜索多个关键词,可以在 $search 中使用空格分隔关键词。例如,搜索 "mongodb" 和 "Runoob":
db.posts.find({ $text: { $search: "mongodb Runoob" } });
e.删除全文索引
如果需要删除全文索引,可以使用 getIndexes() 查看当前的索引,并确定索引的名称:
db.posts.getIndexes();
-----------------------------------------------------------------------------------------------------
找到索引名称后,使用 dropIndex() 删除索引,例如:
db.posts.dropIndex("post_text_text");
3.6 附:用户管理
01.操作
a.连接
mongosh --host localhost --port 27017
b.切换数据库
use testdb
c.创建testuser用户
db.createUser({
user: "testuser",
pwd: "123456",
roles: [{ role: "readWrite", db: "testdb" }]
})
d.验证用户
db.auth("testuser", "123456")
e.启用身份验证并重启 MongoDB 实例
a.编辑 mongod.conf 文件,添加以下内容
security:
authorization: "enabled"
b.重启 MongoDB 服务
略
f.使用 testuser 用户进行身份验证连接
mongosh --host localhost --port 27017 -u "testuser" -p "123456" --authenticationDatabase "testdb"
g.删除 testuser 用户
db.dropUser("testuser")
02.说明
a.安全管理
MongoDB中的账号是在某一个库里边进行设置的,我们在哪一个库里边进行设置,就要在哪一个库里边进行验证
创建用户时,我们需要指定用户名、用户密码和用户角色,用户角色表示了该用户的权限
b.假设我给admin数据库创建一个用户,方式如下:
use admin
db.createUser({user:"root",pwd:"123456",roles:[{role:"userAdminAnyDatabase",db:"admin"}]})
-----------------------------------------------------------------------------------------------------
用户的角色,有如下几种:
1.Read:允许用户读取指定数据库
2.readWrite:允许用户读写指定数据库
3.dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile
4.userAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户
5.clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限
6.readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限
7.readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限
8.userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限
9.dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限
10.root:只在admin数据库中可用。超级账号,超级权限
c.需要先进入到admin数据库中,然后授权
use admin
db.auth("root","123")
【我们在哪一个库里边进行设置,就要在哪一个库里边进行验证】
【执行插入操作会提示没有权限,那我们可以创建一个有读写功能的用户执行相应的操作】
3.7 附:备份、导出
01.备份恢复
a.数据备份
a.介绍
在 Mongodb 中,使用 mongodump 命令来备份 MongoDB 数据。该命令可以导出所有数据到指定目录中。
mongodump 命令可以通过参数指定导出的数据量级转存的服务器。
b.mongodump 命令语法如下
mongodump -h dbhost -d dbname -o dbdirectory
-------------------------------------------------------------------------------------------------
-h:MongDB 所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:需要备份的数据库实例,例如:test
-o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在 dump 目录下建立一个 test 目录,这个目录里面存放该数据库实例的备份数据。
c.mongodump 命令可选参数列表如下所示
| 语法 | 描述 | 实例
|---------------------------------------------------|--------------------------------|--------------------------------------------------
| mongodump --host HOST_NAME --port PORT_NUMBER | 该命令将备份所有 MongoDB 数据 | mongodump --host runoob.com --port 27017
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | | mongodump --dbpath /data/db/ --out /data/backup/
| mongodump --collection COLLECTION --db DB_NAME | 该命令将备份指定数据库的集合。 | mongodump --collection mycol --db test
d.【示例】备份全量数据
$ mongodump -h 127.0.0.1 --port 27017 -o test2
...
2020-09-11T11:55:58.086+0800 done dumping test.company (18801 documents)
2020-09-11T11:56:00.725+0800 [#############...........] test.people 559101/1000000 (55.9%)
2020-09-11T11:56:03.725+0800 [###################.....] test.people 829496/1000000 (82.9%)
2020-09-11T11:56:06.725+0800 [#####################...] test.people 884614/1000000 (88.5%)
2020-09-11T11:56:08.088+0800 [########################] test.people 1000000/1000000 (100.0%)
2020-09-11T11:56:08.350+0800 done dumping test.people (1000000 documents)
e.【示例】备份指定数据库
mongodump -h 127.0.0.1 --port 27017 -d admin -o test3
b.数据恢复
a.介绍
mongodb 使用 mongorestore 命令来恢复备份的数据
b.mongorestore 命令语法如下:
mongorestore -h <hostname><:port> -d dbname <path>
-------------------------------------------------------------------------------------------------
--host <:port>, -h <:port>:MongoDB 所在服务器地址,默认为: localhost:27017
--db , -d :需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如 test2
--drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
<path>:mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。你不能同时指定 <path> 和 --dir 选项,--dir 也可以设置备份目录。
--dir:指定备份的目录。你不能同时指定 <path> 和 --dir 选项。
c.示例
$ mongorestore -h 127.0.0.1 --port 27017 -d test --dir test --drop
...
2020-09-11T11:46:16.053+0800 finished restoring test.tweets (966 documents, 0 failures)
2020-09-11T11:46:18.256+0800 [###.....................] test.people 164MB/1.03GB (15.6%)
2020-09-11T11:46:21.255+0800 [########................] test.people 364MB/1.03GB (34.6%)
2020-09-11T11:46:24.256+0800 [############............] test.people 558MB/1.03GB (53.0%)
2020-09-11T11:46:27.255+0800 [###############.........] test.people 700MB/1.03GB (66.5%)
2020-09-11T11:46:30.257+0800 [###################.....] test.people 846MB/1.03GB (80.3%)
2020-09-11T11:46:33.255+0800 [######################..] test.people 990MB/1.03GB (94.0%)
2020-09-11T11:46:34.542+0800 [########################] test.people 1.03GB/1.03GB (100.0%)
2020-09-11T11:46:34.543+0800 no indexes to restore
2020-09-11T11:46:34.543+0800 finished restoring test.people (1000000 documents, 0 failures)
2020-09-11T11:46:34.544+0800 1000966 document(s) restored successfully. 0 document(s) failed to restore.
02.导入导出
a.导入
a.介绍
在 MongoDB 中,使用 mongoimport 来导入数据。
默认情况下,mongoimport 会将数据导入到本地主机端口 27017 上的 MongoDB 实例中。
要将数据导入在其他主机或端口上运行的 MongoDB 实例中,请通过包含 --host 和 --port 选项来指定主机名或端口。
使用 --drop 选项删除集合(如果已经存在)。 这样可以确保该集合仅包含您要导入的数据。
b.语法格式:
mongoimport -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 -c 表名 --type 类型 --headerline --upsert --drop 文件名
c.【示例】导入表数据
$ mongoimport -h 127.0.0.1 --port 27017 -d test -c book --drop test/book.dat
2020-09-11T10:53:56.359+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T10:53:56.372+0800 dropping: test.book
2020-09-11T10:53:56.628+0800 431 document(s) imported successfully. 0 document(s) failed to import.
d.【示例】从 json 文件中导入表数据
$ mongoimport -h 127.0.0.1 --port 27017 -d test -c student --upsert test/student.json
2020-09-11T11:02:55.907+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T11:02:56.068+0800 200 document(s) imported successfully. 0 document(s) failed to import.
e.【示例】从 csv 文件中导入表数据
$ mongoimport -h 127.0.0.1 --port 27017 -d test -c product --type csv --headerline test/product.csv
2020-09-11T11:07:49.788+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T11:07:51.051+0800 11 document(s) imported successfully. 0 document(s) failed to import.
f.【示例】导入部分表字段数据
$ mongoimport -h 127.0.0.1 --port 27017 -d test -c product --type json --upsertFields name,price test/product.json
2020-09-11T11:14:05.410+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T11:14:05.612+0800 11 document(s) imported successfully. 0 document(s) failed to import.
b.导出
a.语法格式
mongoexport -h <IP> --port <端口> -u <用户名> -p <密码> -d <数据库> -c <表名> -f <字段> -q <条件导出> --csv -o <文件名>
-------------------------------------------------------------------------------------------------
-f:导出指字段,以逗号分割,-f name,email,age 导出 name,email,age 这三个字段
-q:可以根查询条件导出,-q '{ "uid" : "100" }' 导出 uid 为 100 的数据
--csv:表示导出的文件格式为 csv 的,这个比较有用,因为大部分的关系型数据库都是支持 csv,在这里有共同点
b.【示例】导出整张表
$ mongoexport -h 127.0.0.1 --port 27017 -d test -c product -o test/product.dat
2020-09-11T10:44:23.161+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T10:44:23.177+0800 exported 11 records
c.【示例】导出表到 json 文件
$ mongoexport -h 127.0.0.1 --port 27017 -d test -c product --type json -o test/product.json
2020-09-11T10:49:52.735+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T10:49:52.750+0800 exported 11 records
d.【示例】导出表中部分字段到 csv 文件
$ mongoexport -h 127.0.0.1 --port 27017 -d test -c product --type csv -f name,price -o test/product.csv
2020-09-11T10:47:33.160+0800 connected to: mongodb://127.0.0.1:27017/
2020-09-11T10:47:33.176+0800 exported 11 records
4 MongoDB场景
4.1 Java操作
01.介绍
a.概念
MongoUtils 实现MongoDB连接,创建,删除数据库,创建,删除,更新文档以及检索所有文档。
b.java依赖
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.6</version>
</dependency>
c.spring依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.10</version>
</dependency>
</dependencies>
-----------------------------------------------------------------------------------------------------
spring.data.mongodb.uri= mongodb://127.0.0.1:27017/mongo
log4j.category.org.springframework.data.mongodb=DEBUG
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %40.40c:%4L - %m%n
02.示例
a.依赖
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.6</version>
</dependency>
b.myschool集合创建student表
package com.ruoyi.mongo;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.MongoIterable;
import com.mongodb.client.model.Filters;
import com.mongodb.client.result.DeleteResult;
import com.mongodb.client.result.UpdateResult;
import java.util.ArrayList;
import java.util.List;
import org.bson.Document;
import org.bson.conversions.Bson;
/**
* myschool集合创建student表
*/
public class Demo01 {
// 获取MongoDB链接对象
private static MongoClient getMongoClient() {
return new MongoClient("localhost", 27017);
}
// 获取数据库对象
private static MongoDatabase getDatabase(MongoClient mongoClient, String dbName) {
return mongoClient.getDatabase(dbName);
}
// 查看MongoDB链接中的所有库
private static void listDatabases(MongoClient mongoClient) {
MongoIterable<String> dbList = mongoClient.listDatabaseNames();
for (String dbName : dbList) {
System.out.println("数据库名称: " + dbName);
}
}
// 使用库查看库中的集合
private static void listCollections(MongoDatabase database) {
MongoIterable<String> collectionList = database.listCollectionNames();
for (String collectionName : collectionList) {
System.out.println("集合名称: " + collectionName);
}
}
// 插入单条数据
private static void insertOne(MongoCollection<Document> collection) {
Document document = new Document();
document.put("name", "老八");
document.put("age", 88);
document.put("sex", "女");
document.put("wanju", "小汽车");
collection.insertOne(document);
System.out.println("插入单条数据: " + document);
}
// 插入多条数据
private static void insertMany(MongoCollection<Document> collection) {
List<Document> documents = new ArrayList<>();
documents.add(new Document("name", "老十").append("age", 55).append("sex", "男").append("wanju", "小汽车"));
documents.add(new Document("name", "老十一").append("age", 66).append("sex", "女").append("wanju", "小火车"));
documents.add(new Document("name", "老十二").append("age", 77).append("sex", "男").append("wanju", "小电车"));
documents.add(new Document("name", "老十三").append("age", 88).append("sex", "女").append("wanju", "小轮船"));
documents.add(new Document("name", "老十四").append("age", 99).append("sex", "男").append("wanju", "小飞机"));
collection.insertMany(documents);
System.out.println("插入多条数据");
}
// 删除单条数据
private static void deleteOne(MongoCollection<Document> collection) {
DeleteResult result = collection.deleteOne(new Document("name", "老十"));
System.out.println("删除单条数据结果: " + result.getDeletedCount() + " 条记录被删除");
}
// 删除多条数据
private static void deleteMany(MongoCollection<Document> collection) {
DeleteResult result = collection.deleteMany(new Document("name", "老八"));
System.out.println("删除多条数据结果: " + result.getDeletedCount() + " 条记录被删除");
}
// 修改单条数据
private static void updateOne(MongoCollection<Document> collection) {
Bson filter = Filters.eq("name", "老八");
UpdateResult result = collection.updateOne(filter, new Document("$set", new Document("age", 100)));
System.out.println("修改单条数据结果: " + result.getModifiedCount() + " 条记录被修改");
}
// 修改多条数据
private static void updateMany(MongoCollection<Document> collection) {
Bson filter = Filters.eq("sex", "男");
UpdateResult result = collection.updateMany(filter, new Document("$set", new Document("sex", "保密")));
System.out.println("修改多条数据结果: " + result.getModifiedCount() + " 条记录被修改");
}
// 查询数据 - 全查
private static void findAll(MongoCollection<Document> collection) {
MongoCursor<Document> cursor = collection.find().iterator();
System.out.println("全查结果:");
while (cursor.hasNext()) {
System.out.println(cursor.next().toJson());
}
}
// 带条件查询
private static void findWithCondition(MongoCollection<Document> collection) {
Bson filter = Filters.eq("name", "老十");
MongoCursor<Document> cursor = collection.find(filter).iterator();
System.out.println("带条件查询结果:");
while (cursor.hasNext()) {
System.out.println(cursor.next().toJson());
}
}
// 模糊查询
private static void fuzzyFind(MongoCollection<Document> collection) {
Bson filter = Filters.regex("name", "老");
MongoCursor<Document> cursor = collection.find(filter).iterator();
System.out.println("模糊查询结果:");
while (cursor.hasNext()) {
System.out.println(cursor.next().toJson());
}
}
public static void main(String[] args) {
// 获取MongoDB连接
MongoClient mongoClient = getMongoClient();
// 获取数据库对象
MongoDatabase database = getDatabase(mongoClient, "myschool");
// 获取集合对象
MongoCollection<Document> studentCollection = database.getCollection("student");
// 查看所有数据库
listDatabases(mongoClient);
// 查看当前数据库中的所有集合
listCollections(database);
// 插入数据
insertOne(studentCollection);
insertMany(studentCollection);
// 删除数据
deleteOne(studentCollection);
deleteMany(studentCollection);
// 修改数据
updateOne(studentCollection);
updateMany(studentCollection);
// 查询数据
findAll(studentCollection);
findWithCondition(studentCollection);
fuzzyFind(studentCollection);
// 关闭连接
mongoClient.close();
}
}
4.2 搜索历史记录
01.搜索历史记录
a.输入关键词:
用户在搜索框中输入关键词。
b.搜索:
系统执行搜索操作,并返回搜索结果给用户。
c.记录关键词(异步请求):
搜索操作的同时,异步记录用户输入的关键词。
d.查询搜索记录:
检查MongoDB中是否已有该用户的搜索记录。
e.判断是否存在:
如果搜索记录存在,则更新到最新时间。
如果搜索记录不存在,则继续下一步。
f.总数据量是否超过10:
检查该用户的搜索记录总量是否超过10条。
g.替换最后一条数据:
如果搜索记录总量超过10条,则删除最早的搜索记录,并保存新的关键词。
h.保存关键词:
将新的关键词添加到用户的搜索记录中。
02.代码
package com.ruoyi.mongo;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.Scanner;
/**
* 搜索历史记录
*/
public class Demo02 {
private static MongoClient mongoClient;
private static MongoDatabase database;
private static MongoCollection<Document> historyCollection;
// 初始化MongoDB连接和集合
private static void initializeMongoDB() {
mongoClient = new MongoClient("localhost", 27017);
database = mongoClient.getDatabase("search_history_db"); // 数据库名
historyCollection = database.getCollection("history"); // 集合名
}
// 保存搜索历史
private static void saveSearch(String searchQuery) {
Document document = new Document("query", searchQuery)
.append("timestamp", System.currentTimeMillis());
historyCollection.insertOne(document);
System.out.println("已保存搜索历史: " + searchQuery);
}
// 查询搜索历史
private static void viewSearchHistory() {
try (MongoCursor<Document> cursor = historyCollection.find().iterator()) {
System.out.println("搜索历史记录:");
while (cursor.hasNext()) {
Document doc = cursor.next();
System.out.println("查询: " + doc.getString("query") + ", 时间戳: " + doc.getLong("timestamp"));
}
}
}
// 关闭MongoDB连接
private static void closeMongoDB() {
if (mongoClient != null) {
mongoClient.close();
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
initializeMongoDB();
while (true) {
System.out.println("请输入搜索查询(或输入'exit'退出,'history'查看历史记录):");
String input = scanner.nextLine();
if ("exit".equalsIgnoreCase(input)) {
break;
} else if ("history".equalsIgnoreCase(input)) {
viewSearchHistory();
} else {
saveSearch(input);
}
}
closeMongoDB();
scanner.close();
}
}
4.3 用户评论、评论点赞、评论回复
01.用户评论、评论点赞、评论回复
a.数据模型
a.评论模型
id: 唯一标识符
userId: 评论者的用户ID
content: 评论内容
timestamp: 评论时间
likes: 点赞数量
replies: 回复列表(可以是嵌套评论对象)
b.用户模型(可选)
id: 用户ID
username: 用户名
profilePicture: 头像等用户信息
b.功能模块
a.添加评论
用户提交评论时,检查用户是否已登录。
将评论存入数据库,记录时间戳和初始点赞数(0)。
b.点赞功能
用户点击“点赞”按钮,更新相应评论的点赞数。
需要处理用户重复点赞的情况,通常可通过记录用户和评论的关系来避免。
c.回复评论
用户在查看评论时,可以选择回复某个评论。
将回复存入相应评论的 replies 列表中,以维护评论的层级结构。
02.代码
package com.ruoyi.mongo;
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 用户评论、评论点赞、评论回复
*/
public class Demo03 {
private static MongoClient mongoClient;
private static MongoDatabase database;
private static MongoCollection<Document> commentCollection;
// 初始化 MongoDB 连接和集合
private static void initializeMongoDB() {
mongoClient = new MongoClient("localhost", 27017);
database = mongoClient.getDatabase("comment_system_db"); // 数据库名
commentCollection = database.getCollection("comments"); // 集合名
}
// 添加评论
private static void addComment(String user, String content) {
Document comment = new Document("user", user)
.append("content", content)
.append("likes", 0)
.append("replies", new ArrayList<Document>());
commentCollection.insertOne(comment);
System.out.println("评论已添加: " + content);
}
// 点赞评论
private static void likeComment(String commentId) {
Document query = new Document("_id", new org.bson.types.ObjectId(commentId));
Document update = new Document("$inc", new Document("likes", 1));
commentCollection.updateOne(query, update);
System.out.println("评论已点赞: " + commentId);
}
// 回复评论
private static void replyToComment(String commentId, String user, String replyContent) {
Document reply = new Document("user", user).append("content", replyContent);
Document query = new Document("_id", new org.bson.types.ObjectId(commentId));
Document update = new Document("$push", new Document("replies", reply));
commentCollection.updateOne(query, update);
System.out.println("回复已添加: " + replyContent);
}
// 查看所有评论
private static void viewComments() {
try (MongoCursor<Document> cursor = commentCollection.find().iterator()) {
while (cursor.hasNext()) {
Document comment = cursor.next();
System.out.println("用户: " + comment.getString("user"));
System.out.println("评论: " + comment.getString("content"));
System.out.println("点赞数: " + comment.getInteger("likes"));
// 查看回复
List<Document> replies = (List<Document>) comment.get("replies");
for (Document reply : replies) {
System.out.println(" 回复用户: " + reply.getString("user"));
System.out.println(" 回复内容: " + reply.getString("content"));
}
System.out.println("----------------------------");
}
}
}
// 关闭 MongoDB 连接
private static void closeMongoDB() {
if (mongoClient != null) {
mongoClient.close();
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
initializeMongoDB();
while (true) {
System.out.println("请选择操作: 1-添加评论 2-点赞评论 3-回复评论 4-查看评论 5-退出");
int choice = scanner.nextInt();
scanner.nextLine(); // consume newline
switch (choice) {
case 1:
System.out.println("请输入用户名:");
String user = scanner.nextLine();
System.out.println("请输入评论内容:");
String content = scanner.nextLine();
addComment(user, content);
break;
case 2:
System.out.println("请输入要点赞的评论 ID:");
String commentId = scanner.nextLine();
likeComment(commentId);
break;
case 3:
System.out.println("请输入要回复的评论 ID:");
String replyCommentId = scanner.nextLine();
System.out.println("请输入用户名:");
String replyUser = scanner.nextLine();
System.out.println("请输入回复内容:");
String replyContent = scanner.nextLine();
replyToComment(replyCommentId, replyUser, replyContent);
break;
case 4:
viewComments();
break;
case 5:
closeMongoDB();
scanner.close();
return;
default:
System.out.println("无效的选择,请重试。");
}
}
}
}