1 vilgob
1.1 开始
00.环境
a.脚本(3分钟)
start-bigdata1
start-bigdata2
start-bigdata-all
stop-bigdata1
stop-bigdata2
stop-bigdata-all
-----------------------------------------------------------------------------------------------------
start-hadoop-cluster
start-hive-metastore
start-hive-server
start-zookeeper-cluster && status-zookeeper-cluster
start-hbase-cluster
--------------------------------------------------
start-kafka-cluster
start-spark
start-flink
start-flume
start-kafka-ui
start-hue
start-oozie
-----------------------------------------------------------------------------------------------------
stop-hadoop-cluster
stop-hive-cluster
stop-zookeeper-cluster
stop-hbase-cluster
stop-kafka-cluster
--------------------------------------------------
stop-spark
stop-flink
stop-flume
stop-kafka-ui
stop-hue
stop-oozie
-----------------------------------------------------------------------------------------------------
status-bigdata-all
status-zookeeper-cluster
-----------------------------------------------------------------------------------------------------
sqlline.py master:2181
sqlline.py master,slave1,slave2:2181
jdbc:phoenix:master,slave1,slave2:2181
-----------------------------------------------------------------------------------------------------
halt -p
ps -ef | grep hue
netstat -lnpt | grep 9870
-----------------------------------------------------------------------------------------------------
rm -rf /usr/local/hue
rm -rf /usr/local/hue/atp.txt
b.访问
http://192.168.185.150:50070 --hdfs
http://192.168.185.150:8088 --yarn -> Tools -> Localogs
http://192.168.185.150:19888 --jobhistory -> Tools -> Localogs
http://192.168.185.150:16010 --hbase
http://192.168.185.150:8085 --hbase(restserver)
http://192.168.185.150:8086 --spark(集群的整体信息和状态)
http://192.168.185.150:8087 --spark(应用程序的详细信息)
http://192.168.185.150:8089 --flink
http://192.168.185.150:8000/hue --hue(root、123456)
http://192.168.185.150:7766 --kafka
01.vilgob
a.启动
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
unset HADOOP_CLIENT_OPTS
b.mapreduce1
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo01
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo02
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo03
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo04
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo05
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo06
c.mapreduce2
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo01
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo02
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo03
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo04
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo05
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce2.Demo06
d.hdfs
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.hdfs.Demo01
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.hdfs.Demo02
e.hive
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.hive.Demo01
02.vilgob2
a.启动
java -jar /workspace/vilgob2-1.0-SNAPSHOT.jar
java -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005 -jar /workspace/vilgob2-1.0-SNAPSHOT.jar
-----------------------------------------------------------------------------------------------------
java -jar /workspace/vilgob2-1.0-SNAPSHOT.jar >> /workspace/vilgob2.log 2>&1 &
java -jar /workspace/vilgob2-1.0-SNAPSHOT.jar --spring.profiles.active=test >> /workspace/vilgob2.log 2>&1 &
-----------------------------------------------------------------------------------------------------
ps -ef | grep vilgob2-1.0-SNAPSHOT.jar | grep -v grep
sh /workspace/project.sh start
sh /workspace/project.sh stop
sh /workspace/project.sh restart
b.mapreduce1
http://192.168.185.150:8080/mapreduce1/demo01
http://192.168.185.150:8080/mapreduce1/demo02
http://192.168.185.150:8080/mapreduce1/demo03
http://192.168.185.150:8080/mapreduce1/demo04
http://192.168.185.150:8080/mapreduce1/demo05
http://192.168.185.150:8080/mapreduce1/demo06
c.mapreduce2
http://192.168.185.150:8080/mapreduce2/demo01
http://192.168.185.150:8080/mapreduce2/demo02
http://192.168.185.150:8080/mapreduce2/demo03
http://192.168.185.150:8080/mapreduce2/demo04
http://192.168.185.150:8080/mapreduce2/demo05
http://192.168.185.150:8080/mapreduce2/demo06
d.hdfs
http://192.168.185.150:8080/hdfs/demo01
http://192.168.185.150:8080/hdfs/demo02
1.2 说明
00.常见问题
a.报错1
find /tmp -type f -mtime +7 -exec rm -f {} \;
-----------------------------------------------------------------------------------------------------
不要删除/tmp,hadoop会初始化一些文件,会出现如下报错:有 8 个缺失的块。以下文件可能已损坏
There are 8 missing blocks. The following files may be corrupted:
blk_1073742635 /tmp/hadoop-yarn/staging/root/.staging/job_1724556891583_0002/job.jar
blk_1073742636 /tmp/hadoop-yarn/staging/root/.staging/job_1724556891583_0002/job.split
blk_1073742637 /tmp/hadoop-yarn/staging/root/.staging/job_1724556891583_0002/job.splitmetainfo
blk_1073742638 /tmp/hadoop-yarn/staging/root/.staging/job_1724556891583_0002/job.xml
blk_1073742639 /tmp/hadoop-yarn/staging/root/.staging/job_1724556891583_0002/job_1724556891583_0002_1_conf.xml
blk_1073742859 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1724576926068_0001.summary
blk_1073742860 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1724576926068_0001-1724576947404-root-word+count-1724576975737-2-1-SUCCEEDED-default-1724576957159.jhist
blk_1073742861 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1724576926068_0001_conf.xml
Please check the logs or run fsck in order to identify the missing blocks. See the Hadoop FAQ for common causes and potential solutions.
-----------------------------------------------------------------------------------------------------
hadoop fsck / --检查坏的块
hdfs fsck / -delete --直接删除命令,只会删除坏块,正常的块不会删除
b.报错2
KeeperErrorCode = NoNode for /hbase/master
-----------------------------------------------------------------------------------------------------
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
at org.apache.hadoop.hbase.master.HMaster.checkInitialized(HMaster.java:2739)
at org.apache.hadoop.hbase.master.HMaster.disableTable(HMaster.java:2310)
at org.apache.hadoop.hbase.master.MasterRpcServices.disableTable(MasterRpcServices.java:802)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:395)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:338)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:318)
-----------------------------------------------------------------------------------------------------
解决1:集群中的节点时间不同步,可以在启动的集群中使用命令行:date,查看各个节点的时间是否同步,
如果不同步,可以参考这篇博客进行集群离线状态时间同步的修改
https://blog.csdn.net/m0_46413065/article/details/116378004
-----------------------------------------------------------------------------------------------------
解决2:如果以上方式仍然没有效果,可能报错的原因二是:HDFS中和Zookeeper中的HBase没有删除,
所以这里需要将其进行删除,具体的命令如下:注意:删除Zookeeper中的 /hbase 目录,
需要保证zookeeper已经开启,否则无法连接上。
01.常见插件
a.安装
Flink,从 IDE 监控和提交 Flink 作业
Spark,使用 IDE 中的运行配置提交 Spark/PySpark 作业
Cap-Hadoop,从 IDE 执行各种 HDFS 操作,以表格形式预览大型结构化文件,监控 Hadoop YARN 应用
Big Data Tools,直接从您的 IDE 运行和监控 Spark 或 Flink 作业,查看大数据文件,使用 Kafka 生成和使用消息,预览 Hive Metastore 数据库
b.Cap BigData
集群名称:192.168.185.150:9000
HDFS地址:192.168.185.150:9000
用户名:root
c.BigData Tools
a.yarn
http://192.168.185.150:8088
b.hdfs
http://192.168.185.150:9000
c.hive
thrift://192.168.185.150:9083
d.PrettyZoo
192.168.185.150
2181
e.HDFS explorer
192.168.185.150
9870 / 50070
root
f.HBase Assistant
连接名:192.168.185.150
Transport:HTTP TRANSPORT
Thrift主机:192.168.185.150
端口:9090
g.Datagrip
a.hive
jdbc:hive2://192.168.185.150:10000
192.168.185.150
10000
hive
hive
b.spark
略
h.DBeaver
a.hive
jdbc:hive2://192.168.185.150:10000
192.168.185.150
10000
hive
hive
b.Phoenix
jdbc:phoenix:master:2181
phoenix -> 驱动属性 -> phoenix.schema.isNamespaceMappingEnabled true
phoenix -> 驱动属性 -> phoenix.schema.mapSystemTablesToNamespace true
phoenix -> 驱动编辑 -> 库 -> C:\software\datagrip\.idea\jar\phoenix-client-hbase-2.4-5.1.3.jar
02.环境说明
a.环境1
hadoop-2.7.7
hive-2.3.4
zookeeper-3.4.10
kafka-2.1.0
flume-1.8.0
hbase-2.1.1
spark-2.4.0
storm-1.2.2
flink-1.18.1
hue-4.10.0
oozie-4.0.0
sqoop-1.4.7
impala-4.3.0
phoenix-5.1.3
pig-0.16.0
scala-2.11.8
b.环境2
hadoop-3.3.6
hive-3.1.3
zookeeper-3.7.1
kafka-3.4.0
flume-1.11.0
hbase-2.4.17
spark-3.3.2
storm-2.4.0
flink-1.18.1
hue-4.10.0
oozie-5.2.1
sqoop-1.4.7
impala-4.3.0
phoenix-5.1.3
pig-0.17.0
scala-2.12.0
c.环境3
Hadoop 2.7.7:可以安装,CDH 默认使用的 Hadoop 版本会与 CDH 版本绑定,确保版本兼容性。
Hive 2.3.4:可以安装,CDH 自带 Hive 组件,版本可能不同,但功能上是兼容的。
Zookeeper 3.4.10:可以安装,CDH 自带 Zookeeper,版本可能会不同。
Kafka 2.1.0:CDH 支持安装 Kafka,但 Kafka 通常作为额外安装的服务,不属于 CDH 默认组件,需要手动安装和配置。
Flume 1.8.0:可以安装,CDH 支持 Flume 用于数据收集和传输。
HBase 2.1.1:CDH 自带 HBase,注意版本差异,需确保兼容性。
Spark 2.4.0:CDH 支持 Spark,不过 Spark 的版本会与 CDH 版本绑定,可能需要手动升级或调整配置。
Storm 1.2.2:CDH 并不自带 Storm,安装和配置需要手动进行,但可以集成使用。
Flink 1.18.1:CDH 不自带 Flink,需要手动安装和配置。
Oozie:CDH 自带 Oozie,用于调度工作流任务。
Sqoop:CDH 支持 Sqoop,用于在 Hadoop 和关系型数据库之间传输数据。
Hue:CDH 自带 Hue,这是一个用户友好的界面,用于管理和操作 Hadoop 生态系统。
Impala:CDH 自带 Impala,这是一个高性能的 SQL 查询引擎。
Phoenix:CDH 不直接集成 Phoenix,但可以与 HBase 集成使用,安装和配置需要手动进行。
d.环境4
hadoop-common
hadoop-hdfs
hadoop-mapreduce-client-core
hadoop-mapreduce-client-jobclient
hadoop-client
hive-exec
hive-metastore
zookeeper
kafka-clients
flume-ng-sdk
hbase-client
spark-core_2.11
storm-core
flink-core
commons-cli
e.环境5
libfb303
Dm7JdbcDriver18
lettuce-core
kudu-client
hutool-all
lombok
fastjson
-----------------------------------------------------------------------------------------------------
scala-library
hadoop-client
hadoop-auth
hadoop-hdfs
hadoop-common
-----------------------------------------------------------------------------------------------------
flink-shaded-hadoop-2-uber
flink-java
flink-core
flink-statebackend-rocksdb_2.11
flink-streaming-java_2.11
flink-connector-files
flink-connector-filesystem_2.11
flink-hadoop-fs
flink-table-api-java-bridge_2.11
flink-avro
flink-runtime
flink-table-api-scala-bridge_2.11
flink-sql-client_2.11
flink-clients_2.11
flink-connector-hbase-2.2_2.11
flink-connector-kafka_2.11
flink-connector-files
flink-sequence-file
flink-connector-hive_2.11
flink-json
flink-connector-jdbc_2.11
flink-table-common
flink-table-planner_2.11
-----------------------------------------------------------------------------------------------------
hbase-client
hbase-endpoint
hbase-common
hbase-server
-----------------------------------------------------------------------------------------------------
hive-metastore
hive-exec
03.版本对应
a.Hive
3.3.x Hive 3.1.x
3.2.x Hive 3.1.x
3.1.x Hive 2.3.x, 3.0.x
3.0.x Hive 2.3.x
2.9.x Hive 2.3.x
2.8.x Hive 2.1.x, 2.3.x
2.7.x Hive 1.2.x, 2.0.x, 2.1.x
2.6.x Hive 1.2.x
2.5.x Hive 1.1.x
2.4.x Hive 1.0.x, 1.1.x
b.zookeeper
3.3.x 3.5.x, 3.6.x, 3.7.x
3.2.x 3.4.x, 3.5.x, 3.6.x
3.1.x 3.4.x, 3.5.x
3.0.x 3.4.x, 3.5.x
2.9.x 3.4.x, 3.5.x
2.8.x 3.4.x, 3.5.x
2.7.x 3.4.x
2.6.x 3.4.x
2.5.x 3.4.x
2.4.x 3.4.x
c.kafka
3.3.x 2.6.x, 2.7.x, 2.8.x, 3.0.x, 3.1.x
3.2.x 2.4.x, 2.5.x, 2.6.x, 2.7.x
3.1.x 2.3.x, 2.4.x, 2.5.x
3.0.x 2.1.x, 2.2.x, 2.3.x
2.9.x 2.0.x, 2.1.x, 2.2.x
2.8.x 1.1.x, 2.0.x, 2.1.x
2.7.x 1.0.x, 1.1.x, 2.0.x
2.6.x 1.0.x, 1.1.x
2.5.x 0.11.x, 1.0.x
2.4.x 0.10.x, 0.11.x
d.flume
3.3.x 1.9.x, 1.10.x
3.2.x 1.9.x, 1.10.x
3.1.x 1.8.x, 1.9.x
3.0.x 1.8.x, 1.9.x
2.9.x 1.7.x, 1.8.x
2.8.x 1.7.x, 1.8.x
2.7.x 1.6.x, 1.7.x
2.6.x 1.6.x, 1.7.x
2.5.x 1.5.x, 1.6.x
2.4.x 1.4.x, 1.5.x
e.hbase
3.3.x 2.4.x, 2.5.x
3.2.x 2.3.x, 2.4.x
3.1.x 2.2.x, 2.3.x
3.0.x 2.0.x, 2.1.x
2.9.x 2.0.x, 2.1.x
2.8.x 1.4.x, 2.0.x
2.7.x 1.2.x, 1.3.x, 1.4.x
2.6.x 1.2.x, 1.3.x
2.5.x 1.1.x, 1.2.x
2.4.x 1.0.x, 1.1.x
f.spark
3.3.x 3.2.x, 3.3.x, 3.4.x
3.2.x 3.1.x, 3.2.x
3.1.x 3.0.x, 3.1.x
3.0.x 3.0.x
2.9.x 2.4.x, 3.0.x
2.8.x 2.3.x, 2.4.x
2.7.x 2.2.x, 2.3.x, 2.4.x
2.6.x 2.1.x, 2.2.x, 2.3.x
2.5.x 2.0.x, 2.1.x
2.4.x 1.6.x, 2.0.x
g.storm
3.3.x 2.4.x, 2.5.x
3.2.x 2.3.x, 2.4.x
3.1.x 2.2.x, 2.3.x
3.0.x 2.0.x, 2.1.x
2.9.x 1.2.x, 1.3.x
2.8.x 1.1.x, 1.2.x
2.7.x 1.0.x, 1.1.x
2.6.x 0.9.x, 1.0.x
2.5.x 0.9.x
2.4.x 0.8.x, 0.9.x
h.flink
3.3.x 1.14.x, 1.15.x, 1.16.x
3.2.x 1.12.x, 1.13.x, 1.14.x
3.1.x 1.10.x, 1.11.x, 1.12.x
3.0.x 1.8.x, 1.9.x, 1.10.x
2.9.x 1.7.x, 1.8.x, 1.9.x
2.8.x 1.6.x, 1.7.x, 1.8.x
2.7.x 1.5.x, 1.6.x
2.6.x 1.4.x, 1.5.x
2.5.x 1.3.x
2.4.x 1.2.x
i.hue
3.3.x 4.10.x, 4.11.x
3.2.x 4.8.x, 4.9.x
3.1.x 4.7.x, 4.8.x
3.0.x 4.6.x, 4.7.x
2.9.x 4.5.x, 4.6.x
2.8.x 4.3.x, 4.4.x, 4.5.x
2.7.x 4.2.x, 4.3.x
2.6.x 4.1.x, 4.2.x
2.5.x 4.0.x, 4.1.x
2.4.x 3.12.x, 3.13.x
j.oozie
3.3.x 5.2.x, 5.3.x
3.2.x 5.1.x, 5.2.x
3.1.x 5.0.x, 5.1.x
3.0.x 4.5.x, 4.6.x
2.9.x 4.4.x, 4.5.x
2.8.x 4.2.x, 4.3.x, 4.4.x
2.7.x 4.1.x, 4.2.x
2.6.x 4.0.x, 4.1.x
2.5.x 3.4.x, 3.5.x
2.4.x 3.3.x, 3.4.x
k.sqoop
3.3.x 1.4.x
3.2.x 1.4.x
3.1.x 1.4.x
3.0.x 1.4.x
2.9.x 1.4.x
2.8.x 1.4.x
2.7.x 1.4.x
2.6.x 1.4.x
2.5.x 1.4.x
2.4.x 1.4.x
l.impala
3.3.x 5.0.x, 5.1.x
3.2.x 4.0.x, 4.1.x, 4.2.x
3.1.x 3.4.x, 3.5.x
3.0.x 2.11.x, 2.12.x
2.9.x 2.10.x, 2.11.x
2.8.x 2.9.x, 2.10.x
2.7.x 2.8.x, 2.9.x
2.6.x 2.7.x, 2.8.x
2.5.x 2.6.x
2.4.x 2.5.x
m.phoenix
Hadoop 版本 对应的 Phoenix 版本
3.3.x 5.1.x, 5.2.x
3.2.x 5.0.x, 5.1.x
3.1.x 4.15.x, 4.16.x
3.0.x 4.14.x, 4.15.x
2.9.x 4.13.x, 4.14.x
2.8.x 4.12.x, 4.13.x
2.7.x 4.11.x, 4.12.x
2.6.x 4.10.x
2.5.x 4.9.x
2.4.x 4.8.x
04.业务说明
a.数据采集
flink、kafka、kettle
b.数据存储
大数据平台 -> hive -> 8张表处理 -> 展示表(不遵守范式)
96点缺失
c.数据使用
habse -> ods dwd dws -> dm层
d.总结
Hadoop-2.7.7 mp 拆 reduce 合
Hive-2.3.4 类sql
Hbase-2.1.1 类sql
Impala 3.4.0 基于hbase,操作sql
Phoenix 5.1.2 基于hbase,操作sql
Spark-2.4.0 python结合人工智能,数据分析,补数
Kafka-2.1.0 实时数据处理
Flink-1.18.1 实时数据处理
Flume-1.8.0 日志
kudu 类似hdfs,做存储
e.任务
flink往hbase插数
Hive导入数据到HBase,再与Phoenix映射同步
1.3 路线
2 hadoop
2.1 概念
01.常见信息1
a.环境说明
Map折分、Shuffle、混洗reduce
作为 Hadoop 生态系统的一部分,HBase 可以与其他大数据工具(如 Hadoop、Spark、Hive 等)无缝集成。
a.hadoop-2.7.7(搭配JDK8)
Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HDFS,Hadoop Distributed File System,是一个分布式文件系统,用来存储 Hadoop 集群中所有存储节点上的文件,包含一个 NameNode 和大量 DataNode。NameNode,它在 HDFS 内部提供元数据服务,负责管理文件系统名称空间和控制外部客户机的访问,决定是否将文件映射到 DataNode 上。DataNode,它为 HDFS 提供存储块,响应来自 HDFS 客户机的读写请求。
MapReduce是一种编程模型,用于大规模数据集的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,即指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
b.hive-2.3.4
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过和SQL类似的HiveQL语言快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。所有Hive 的数据都存储在Hadoop兼容的文件系统(例如HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
c.zookeeper-3.4.10
ZooKeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。其目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
那么Zookeeper能做什么事情呢?举个简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。
搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
d.kafka-2.1.0
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即主题(Topic),通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息。
Consumer,即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
e.flume-1.8.0
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中,可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中。
f.hbase-2.1.1
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
g.spark-2.4.0
Apache Spark 是一种用于大数据工作负载的分布式开源处理系统。它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询。它提供使用 Java、Scala、Python 和 R 语言的开发 API,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。您会发现各行业的众多组织都使用它,其中包括 FINRA、Yelp、Zillow、DataXu、Urban Institute 和 CrowdStrike。
h.storm-1.2.2
Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。 Storm有很多使用场景:如实时分析,在线机器学习,持续计算,分布式RPC,ETL等等。 Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理数以百万计的消息)。
i.flink-1.18.1
Apache Flink是一个分布式大数据计算引擎,可以对有界的数据和无界的数据进行有状态的计算,可部署在各种集群环境中,对各种大小数据规模进行快速计算。
Flink 是一个框架,是一个数据处理的引擎;而且是分布式,是为了应付大规模数据的应用场景而诞生;另外, Flink 处理的是数据流。所以, Flink 是一个流式大数据处理引擎。而内存执行速度和任意规模,突出了 Flink 的两个特点:速度快、可扩展性强——这说的自然就是小松鼠的“快速”和“灵巧”了。
j.hue-4.10.0,支持Hive、Impala、HBase、Phoenix
当前环境推荐Hue 4.7.x 或 Hue 4.8.x
-----------------------------------------------------------------------------------------------------
HUE是一个开源的Apache Hadoop UI系统,早期由Cloudera开发,后来贡献给开源社区。它是基于Python Web框架Django实现的。
Apache Hive:用于查询存储在 HDFS 上的结构化数据。
Apache Impala:用于低延迟查询 Hadoop 中的数据。
Apache HBase:用于查询 NoSQL 数据库。
Apache Phoenix:用于在 HBase 上执行 SQL 查询。
Presto、SparkSQL 等。
-----------------------------------------------------------------------------------------------------
通过使用Hue我们可以通过浏览器方式操纵Hadoop集群。例如put、get、执行MapReduce Job等等
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
支持基于Impala的应用进行交互式查询
支持Spark编辑器和仪表板(Dashboard)
支持Pig编辑器,并能够提交脚本任务
支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
支持Job设计器,能够创建MapReduce/Streaming/Java Job
支持Sqoop 2编辑器和仪表板(Dashboard)
支持ZooKeeper浏览器和编辑器
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
k.oozie-4.0.0
Oozie是用于 Hadoop 平台的开源的工作流调度引擎。
是用来管理Hadoop作业。
是属于web应用程序,由Oozie client和Oozie Server两个组件构成。
Oozie Server运行于Java Servlet容器(Tomcat)中的web程序。
Oozie起源于雅虎,主要用于管理与组织Hadoop工作流。Oozie的工作流必须是一个有向无环图,
实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,
只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。
l.sqoop-1.4.7
sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具。
你可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中;
也可以把数据从hdfs中导出到关系型数据库中。sqoop通过Hadoop的MapReduce导入导出,
因此提供了很高的并行性能以及良好的容错性。
-----------------------------------------------------------------------------------------------------
由于Sqoop最早期是Hadoop的模块,所以Sqoop底层做的是MapReduce任务,
通过将我们的导入导出命令翻译成MapReduce程序来完成作业,通过MapReduce将数据从数据库导到HDFS,
或是从HDFS导入数据库。这一点和我们的Hive类似。
-----------------------------------------------------------------------------------------------------
Sqoop发行了两个版本,Sqoop1和Sqoop2,Sqoop1.99.*之后的都是Sqoop2的版本,这两个版本各有优缺点:
Sqoop1:架构部署简单,但是sqoop1的命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏, 安装需要root权限。
Sqoop2:有多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写。但是架构稍复杂,配置部署更繁琐。
m.impala,支持HDFS、HBase、Kudu
一款高效率的sql查询工具,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。
与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN和Sentry)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
Impala将相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)用作Apache Hive,为面向批量或实时查询提供熟悉且统一的平台。
与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。
因此,它减少了使用MapReduce的延迟,这使Impala比Apache Hive快。
-----------------------------------------------------------------------------------------------------
impala是基于hive的大数据分析查询引擎,直接使用hive的源数据库metadata,
意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。
所以安装impala,先安装hive,并且要启动hive的metastore服务。
-----------------------------------------------------------------------------------------------------
hive元数据包含hive创建的database、table等元信息。元数存储在关系型数据库中,如Derby、MySQL等。
客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,
就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
-----------------------------------------------------------------------------------------------------
查询的数据库:Impala 是一个高性能的、分布式的 SQL 查询引擎,专门用于查询存储在 Apache Hadoop 文件系统(HDFS)中的数据。
详细描述:Impala 允许用户使用 SQL 语法查询 Hadoop 中的数据,提供与传统关系型数据库类似的低延迟查询性能。Impala 的设计目标是让用户能够快速地对存储在 HDFS 或 Apache Kudu 中的数据执行分析查询。
n.phoenix-5.1.3,支持HBase
Phoenix是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据
它相当于一个Java中间件,提供jdbc连接,操作hbase数据表。Phoenix是一个HBase的开源SQL引擎。
你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
Phoenix的团队用了一句话概括Phoenix:“We put the SQL back in NoSQL” 意思是:我们把SQL又放回NoSQL去了!
这边说的NoSQL专指HBase,意思是可以用SQL语句来查询Hbase,你可能会说:“Hive和Impala也可以啊!”。
但是Hive和Impala还可以查询文本文件,Phoenix的特点就是,它只能查Hbase,别的类型都不支持!
但是也因为这种专一的态度,让Phoenix在Hbase上查询的性能超过了Hive和Impala!
o.clickhouse
高性能:得益于其列式存储、向量化查询执行和多线程处理,ClickHouse 能够在极短的时间内处理大量数据,即使是复杂的查询也能快速返回结果。
实时分析:支持实时数据的插入和查询,非常适合需要实时分析和决策的场景。
分布式架构:ClickHouse 可以水平扩展,将数据分布在多个节点上,从而提高系统的处理能力和数据冗余性。
列式存储:ClickHouse 采用列式存储,这使得它在数据压缩和查询优化方面表现出色,尤其适合大规模数据分析。
丰富的SQL功能:支持标准SQL语法,并提供了丰富的数据处理功能,例如窗口函数、聚合函数和多种数据类型。
高效的数据压缩:由于采用列式存储,ClickHouse 能够对数据进行高效压缩,从而节省存储空间。
数据存储与计算分离:Hadoop 主要用于分布式存储和计算,通过 HDFS(Hadoop Distributed File System)来存储大规模数据。而 ClickHouse 则作为一个高性能的查询引擎,用于快速处理和分析这些数据。可以将数据存储在 HDFS 中,通过 ClickHouse 读取并进行分析。
-----------------------------------------------------------------------------------------------------
数据导入 ClickHouse:
ETL 工具:可以使用 Apache Spark、Apache Flink、或者其他 ETL 工具,从 HDFS 中提取数据,经过转换后加载到 ClickHouse 中。这些工具可以处理数据清洗、聚合等操作,然后将结果导入到 ClickHouse 进行快速查询。
ClickHouse 外部表:ClickHouse 支持从外部数据源(如 HDFS)直接读取数据。通过 clickhouse-local 工具或设置外部表,可以在 ClickHouse 查询中直接访问 HDFS 上的数据,不需要将数据全部导入到 ClickHouse。
-----------------------------------------------------------------------------------------------------
数据集成与查询:
通过 ClickHouse 访问 HDFS 数据:可以通过 ClickHouse 的分布式表功能,直接查询 HDFS 中的文件,例如 CSV、Parquet、ORC 等格式的数据。
使用 SQL 查询:ClickHouse 提供了丰富的 SQL 查询功能,这使得从 HDFS 加载的数据可以直接用于复杂查询和分析,特别适用于 OLAP 查询。
-----------------------------------------------------------------------------------------------------
数据管道:
结合使用 Apache Kafka:Hadoop 和 ClickHouse 可以通过 Kafka 实现数据实时流动,Hadoop 处理批量数据,ClickHouse 处理实时分析。数据可以先写入 Kafka,然后通过流式处理(如 Flink 或 Spark Streaming)写入 ClickHouse,以进行实时数据分析。
-----------------------------------------------------------------------------------------------------
机器学习支持:
ClickHouse 可以作为 Hadoop 生态系统中机器学习任务的数据输入源。Hadoop 上的机器学习框架(如 Apache Mahout、H2O)可以从 ClickHouse 中快速读取数据进行训练,并将结果存储回 ClickHouse 供分析使用。
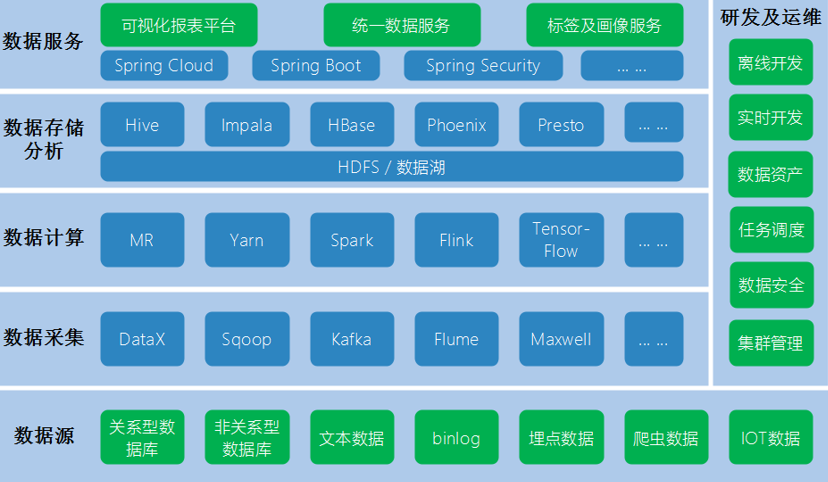
p.DataX
阿里云 DataWorks 数据集成的开源版本,主要就是用于实现数据间的离线同步。
DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等
各种异构数据源(即不同的数据库) 间稳定高效的数据同步功能。
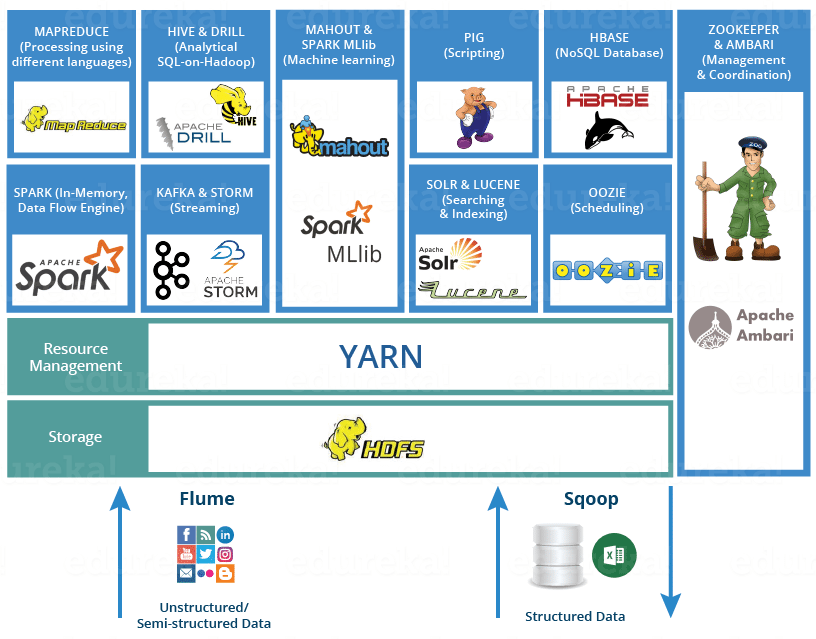
b.常见流程
数据库系统:Mongodb、HBase
数据迁移工具:Sqoop
日志收集框架:Flume、Logstash、Filebeat
查询分析框架:Hive、Spark SQL、Flink SQL、Pig、Phoenix
任务调度框架:Azkaban、Oozie
分布式协调服务:Zookeeper
集群部署和监控:Ambari、Cloudera Manager
集群资源管理器:Hadoop YARN
分布式计算框架:批处理框架(Hadoop MapReduce)、流处理框架(Kafka、Storm)、混合处理框架(Spark、Flink)
分布式文件存储系统:Hadoop HDFS
---------------------------------------------------------------------------------------------------------
数据收集:从各种来源(如传感器、日志文件、社交媒体、交易记录等)收集原始数据。数据可能是结构化、半结构化或非结构化的。
数据存储:使用分布式存储系统(如Hadoop HDFS、NoSQL数据库等)存储大量的数据。存储的选择取决于数据的类型、访问需求和规模。
数据清洗:清理数据中的噪声和错误,处理缺失值和重复数据,以提高数据质量。数据清洗是确保后续分析准确性的重要步骤。
数据预处理:对数据进行标准化、归一化、编码等处理,使其适合用于模型训练和分析。预处理过程还可能包括特征选择、特征提取和数据降维等操作。
数据集成:将来自不同数据源的数据整合在一起,形成一个统一的数据视图。这一步通常涉及处理数据异构性和冲突。
数据转换:将数据转换为适合特定分析任务的格式。这可能包括数据聚合、维度缩减、数据抽取等。
数据分析:使用统计方法、机器学习算法或其他分析工具对数据进行分析,以提取有价值的模式、趋势和洞察。
数据可视化:通过图表、图形等方式将分析结果展示出来,帮助用户理解和解读数据。
数据挖掘:通过高级算法(如分类、聚类、关联规则挖掘等)从大数据中发现有价值的信息和模式。
模型训练与评估:使用预处理后的数据训练机器学习模型,并评估模型的性能。这个过程可能包括模型的优化和调参。
数据应用与部署:将分析结果或模型应用于实际业务场景中,例如预测、自动化决策或个性化推荐。
数据管理与维护:持续管理数据的质量和安全性,确保数据存储、访问和处理的有效性。
02.常见信息2
a.MapReduce任务
Spring Boot 提供了 MapReduce 任务功能,可以让开发人员更轻松地编写和执行 Hadoop 任务。
MapReduce 任务可以让开发人员将大量数据分成多个部分,并在多个节点上进行处理。
---------------------------------------------------------------------------------------------------------
MapReduce 任务的核心类包括:
Job:Job 类是 MapReduce 任务的核心类,它可以让开发人员创建、删除、提交、取消等 MapReduce 任务。Job 类提供了许多用于与 MapReduce 进行交互的方法,如 configure、submit、cancel 等。
JobConf:JobConf 类是 MapReduce 任务的核心类,它可以让开发人员配置 MapReduce 任务的参数。JobConf 类提供了许多用于配置 MapReduce 任务参数的方法,如 setInputPath、setOutputPath、setMapper、setReducer 等。
FileSplit:FileSplit 类是 MapReduce 任务的核心类,它可以让开发人员将 Hadoop 文件分成多个部分,并在多个节点上进行处理。FileSplit 类提供了许多用于构建和解析 Hadoop 文件分区的方法,如 getPath、getStart、getLength 等。
LongWritable:LongWritable 类是 MapReduce 任务的核心类,它可以让开发人员表示 Hadoop 文件的长度。LongWritable 类提供了许多用于构建和解析 Hadoop 文件长度的方法,如 get、toString、hashCode 等。
Text:Text 类是 MapReduce 任务的核心类,它可以让开发人员表示 Hadoop 文件的内容。Text 类提供了许多用于构建和解析 Hadoop 文件内容的方法,如 get、toString、hashCode 等。
b.MapReduce核心算法
MapReduce 是一个分布式数据处理模型,它将数据分成多个部分,并在多个节点上进行处理。
MapReduce 提供了高度并行性和可扩展性,可以处理大量数据。
MapReduce 的核心算法原理包括:
数据分区:MapReduce 将数据分成多个部分,并在多个节点上进行处理。数据分区可以让 MapReduce 提供高度并行性和可扩展性。
数据处理:MapReduce 将数据的多个部分分别处理,并在多个节点上进行处理。数据处理可以让 MapReduce 提供高度并行性和可扩展性。
数据汇总:MapReduce 将数据的多个部分汇总,并在多个节点上进行处理。数据汇总可以让 MapReduce 提供高度并行性和可扩展性。
c.HDFS存储
Spring Boot 提供了 HDFS 存储功能,可以让开发人员更轻松地存储和访问 Hadoop 数据。
HDFS 存储可以让开发人员将数据存储在 Hadoop 集群中,并在多个节点上进行处理。
-----------------------------------------------------------------------------------------------------
HDFS 存储的核心类包括:
FileSystem:FileSystem 类是 HDFS 存储的核心类,它可以让开发人员创建、删除、列出 Hadoop 文件和目录等操作。FileSystem 类提供了许多用于与 HDFS 进行交互的方法,如 create、delete、list 等。
Path:Path 类是 HDFS 存储的核心类,它可以让开发人员表示 Hadoop 文件和目录的路径。Path 类提供了许多用于构建和解析 Hadoop 文件和目录路径的方法,如 getName、getParent、getFileName 等。
FSDataInputStream:FSDataInputStream 类是 HDFS 存储的核心类,它可以让开发人员读取 Hadoop 文件的内容。FSDataInputStream 类提供了许多用于读取 Hadoop 文件内容的方法,如 read、skip、available 等。
FSDataOutputStream:FSDataOutputStream 类是 HDFS 存储的核心类,它可以让开发人员写入 Hadoop 文件的内容。FSDataOutputStream 类提供了许多用于写入 Hadoop 文件内容的方法,如 write、flush、close 等。
d.HDFS核心算法
Hadoop 文件系统(HDFS)是一个分布式文件系统,它将数据分成多个块,并在多个节点上存储。
HDFS 提供了高度可扩展性和容错性,可以处理大量数据。
---------------------------------------------------------------------------------------------------------
HDFS 的核心算法原理包括:
数据分区:HDFS 将数据分成多个块,并在多个节点上存储。数据分区可以让 HDFS 提供高度可扩展性和容错性。
数据重复:HDFS 将数据的多个副本存储在多个节点上。数据重复可以让 HDFS 提供高度可用性和容错性。
数据访问:HDFS 提供了高速缓存和数据访问功能,可以让 HDFS 提供高速访问和高度可扩展性。
03.常见信息3
a.Hadoop、Hive、Spark区别
Hadoop: 一个分布式存储和处理框架,主要组件包括HDFS(分布式文件系统)和MapReduce(分布式计算框架)。适用于处理大量批处理任务。
Hive: 构建在Hadoop之上的数据仓库工具,提供类SQL语法(HiveQL)来查询和管理Hadoop中的大规模数据。适合做数据分析,但速度较慢,因为底层依赖于MapReduce。
Spark: 一个更快的分布式计算框架,与Hadoop相比,Spark在内存中处理数据,支持更复杂的计算(如机器学习、流处理)。适用于对数据进行实时分析和迭代计算。
---------------------------------------------------------------------------------------------------------
Hadoop 主要用于分布式存储和批处理
Hive 是一个基于Hadoop的数据仓库工具,使用SQL语法来查询大数据,适合批量数据分析。
Spark 则是一个更快的计算框架,支持实时分析和复杂计算,通常在内存中处理数据,比MapReduce更高效。
b.Hive与Hbase区别
a.使用方面
a.hive
构建在hadoop平台之上的数据仓库
数据是存放在hdfs上的
数据查询最终被转化为MapReduce执行
b.hbase
基于hdfs平台的nosql的数据源
数据是存放在hdfs上的
基于数据库本身的实时查询,而不是去运行MapReduce
b.特点
a.hive
方便熟悉SQL的人,可以快速上手
默认的计算引擎MapReduce,所以面临了查询时间比较长
底层的计算引擎可以更换为spark/Tez
hive中的表纯逻辑表,只是表的定义,本身是不存储的、不计算的,完全依赖于hdfs/MapReduce
b.hbase
本身不支持SQL的,需要集成Phoenix/hive才可以支持SQL
有自己的一级索引,rowkey,基于一级索引进行数据查询,所以查询速度是比较快的
底层基于scan进行数据扫描,而不是用MapReduce
hbase中的表都是物理表,有独立的物理数据结构,查询的时候可以把数据加载到内存,提升查询效率
c.局限性
a.hive
目前仅支持ORC文件格式的数据更新操作,前提是开启事务支持
hive的运行依赖hdfs进行数据的存储,默认依赖MapReduce进行数据计算
b.hbase
本身不支持SQL查询,需要通过Phoenix实现SQL查询
hbase运行是需要依赖zookeeper(提供协润服务,配置服务,维护元数据,命名空间的维护),依赖于hdfs存储数据的
d.应用场景
a.hive
主要用于构建基于hadoop平台的数据仓库,离线处理海量数据
hive是提供完整的SQL实现,用于历史数据的分析、挖据
b.hbase
适用于大数据的实时查询,还有海量数据的存储
hbase当做一个近实时数据库,支持线上业务的实时查询
做实时数仓的,把维表数据存在hbase
做标签的,把标签数据存在hbase里,方便查询
c.Hadoop 2.x与Hadoop 3.x之间比较
a.License
相同点: 两个版本均采用 Apache 2.0 许可证,都是开源的。
b.支持的最低Java版本
Hadoop 2.x: 最低支持 Java 7。
Hadoop 3.x: 最低支持 Java 8,提供更好的性能和新特性支持。
c.容错机制
Hadoop 2.x: 通过复制数据块(3X 副本)来实现容错,但会浪费大量存储空间。
Hadoop 3.x: 引入了 Erasure Coding 技术,大幅减少存储开销,同时实现容错。
d.数据平衡
Hadoop 2.x: 使用 HDFS 平衡器进行数据平衡。
Hadoop 3.x: 除 HDFS 平衡器外,还支持 Intra-data 节点平衡器,通过 HDFS 磁盘平衡器 CLI 调用进行更加精细的数据平衡。
e.存储Scheme
Hadoop 2.x: 使用 3X 副本 Scheme。
Hadoop 3.x: 支持擦除编码,优化了存储效率。
f.存储开销
Hadoop 2.x: HDFS 有 200% 的存储开销,即每 1TB 数据需要 3TB 的存储空间。
Hadoop 3.x: 通过擦除编码,存储开销降低到 50%,显著节省存储资源。
g.存储开销示例
Hadoop 2.x: 6 个数据块需要 18 个块的存储空间(3X 副本)。
Hadoop 3.x: 6 个数据块只需要 9 个块的存储空间(其中 6 块为数据块,3 块用于奇偶校验)。
h.YARN 时间线服务
Hadoop 2.x: 使用旧版时间线服务,存在可伸缩性问题。
Hadoop 3.x: 改进了时间线服务(v2),提高了可扩展性和可靠性。
i.默认端口范围
Hadoop 2.x: 部分默认端口在 Linux 的临时端口范围内,可能导致启动时无法绑定。
Hadoop 3.x: 已将这些端口移出临时端口范围,减少冲突。
j.工具支持
相同点: 两个版本均支持 Hive、Pig、Tez、Hama、Giraph 等 Hadoop 工具。
k.兼容的文件系统
Hadoop 2.x: 支持 HDFS、FTP 文件系统、Amazon S3、WASB。
Hadoop 3.x: 进一步支持 Microsoft Azure Data Lake 文件系统。
l.Datanode 资源使用
相同点: 两个版本中,Datanode 资源均可用于 MapReduce 和其他应用程序。
m.MR API 兼容性
相同点: Hadoop 2.x 和 3.x 均与 Hadoop 1.x 的 MR API 兼容。
n.支持 Microsoft Windows
相同点: 两个版本均支持在 Windows 平台上部署。
o.插槽/容器
相同点: Hadoop 2.x 和 3.x 均使用容器概念来执行通用任务。
p.单点故障 (SPOF)
相同点: 两个版本都具有自动恢复的功能,当 Namenode 失败时可以自动恢复。
q.HDFS 联盟
相同点: 在 Hadoop 2.x 和 3.x 中,HDFS 均支持多个 NameNode 管理多个 Namespace。
r.可扩展性
Hadoop 2.x: 集群可扩展到 10,000 个节点。
Hadoop 3.x: 提供了更好的可扩展性,可支持超过 10,000 个节点。
s.数据访问速度
相同点: 两个版本都通过数据节点缓存实现快速数据访问。
t.HDFS 快照
相同点: 两个版本均支持 HDFS 快照功能,为用户提供数据恢复和保护。
u.平台支持
相同点: 两个版本都可以作为各种数据分析平台,支持事件处理、流媒体和实时操作。
v.集群资源管理
相同点: 两个版本均使用 YARN 进行集群资源管理。
w.Hadoop 3.x 的改进总结
Common 改进:Shell 脚本重写、过时 API 删除
HDFS 改进:支持擦除编码、支持多个 Namenode、数据均衡改进、多个服务端口变更
YARN 改进:引入 YARN 时间线服务 v2、支持机会性容器和分布式调度
MapReduce 改进:MapReduce 任务级别的本地优化、Daemon 和任务堆管理重构
其他新特性:共享客户端 JAR
04.常见信息4
a.数据仓库
数据仓库,Data Warehouse,可简写为DW或DWH。
数据仓库是面向主题的、集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,
数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
---------------------------------------------------------------------------------------------------------
面向主题 :主题是指使用数据仓库进行决策时所关心的重点方面,每个主题都对应一个相应的分析领域,一个主题通常与多个信息系统相关。
例如:在银行数据中心平台中,用户可以定义为一个主题,用户相关的数据可以来自信贷系统、银行资金业务系统、风险评估系统等,以用户为主题就是将以上各个系统的数据通过用户切入点,将各种信息关联起来。
---------------------------------------------------------------------------------------------------------
数据集成 :数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息,这个过程中会有ETL操作,以保证数据的一致性、完整性、有效性、精确性。
例如某公司中有人力资源系统、生产系统、财务系统、仓储系统等,现需要将各个系统的数据统一采集到数据仓库中进行分析。在人力系统中,张三的性别为“男”,可能在财务系统中张三的性别为“M”,在人力资源系统中张三的职称为“生产部员工”,在生产系统中张三的职称为“技术经理”,那么当我们将数据抽取到数据仓库中时,需要经过数据清洗将数据进行统一、精确、一致性存储。
---------------------------------------------------------------------------------------------------------
相对稳定: 数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,基本没有修改和删除操作,通常只需要定期的加载、刷新。
例如:某用户在一天中多次登录某系统,关系型数据库中只是记录当前用户最终在系统上的状态是“在线”还是“离线”,只需要记录一条数据进行状态更新即可。但是在数据仓库中,当用户多次登录系统时,会产生多条记录,不会存在更新状态操作,每次用户登录系统和下线系统都会在数据仓库中记录一条信息,这样方便后期分析用户行为。
---------------------------------------------------------------------------------------------------------
反映历史变化: 数据仓库中的数据通常包含历史信息,系统地记录企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
例如:电商网站中,用户从浏览各个商品,到将商品加入购物车,直到付款完成,最终的结果在关系型数据库中只需要记录用户的订单信息。往往用户在网站中的浏览商品的信息行为更具有价值,数据仓库中就可以全程记录某个用户登录系统之后浏览商品的浏览行为,加入购物车的行为,及付款行为。以上这些数据都会被记录在数据仓库中,这样就为企业分析用户行为数据提供了数据基础。
b.数据库与数据仓库区别
数据库: 传统关系型数据库的主要应用是OLTP(On-Line Transaction Processing),主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。
数据仓库 : 数仓系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。
---------------------------------------------------------------------------------------------------------
功能 数据库 数据仓库
数据范围 当前状态数据 存储历史、完整、反应历史变化数据
数据变化 支持频繁的增删改查操作 可增加、查询,无更新、删除操作
应用场景 面向业务交易流程 面向分析、支持侧重决策分析
处理数据量 频繁、小批次、高并发、低延迟 非频繁、大批量、高吞吐、有延迟
设计理论 遵循数据库三范式、避免冗余 违范式、适当冗余
建模方式 ER实体关系建模(范式建模) 范式建模+维度建模
c.实时数仓
当前基于Hive的离线数据仓库已经非常成熟,随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,
业界最近几年就一直聚焦并探索于实时数仓建设。根据数仓架构演变过程,在Lambda架构中含有离线处理与实时处理两条链路,
---------------------------------------------------------------------------------------------------------
Kappa架构可以称为真正的实时数仓,目前在业界最常用实现就是Flink + Kafka,
然而基于Kafka+Flink的实时数仓方案也有几个非常明显的缺陷,所以在目前很多企业中实时数仓构建中经常使用混合架构,
没有实现所有业务都采用Kappa架构中实时处理实现。
---------------------------------------------------------------------------------------------------------
Kappa架构缺陷如下:
Kafka无法支持海量数据存储。对于海量数据量的业务线来说,Kafka一般只能存储非常短时间的数据,比如最近一周,甚至最近一天。
Kafka无法支持高效的OLAP查询,大多数业务都希望能在DWD\DWS层支持即席查询的,但是Kafka无法非常友好地支持这样的需求。
无法复用目前已经非常成熟的基于离线数仓的数据血缘、数据质量管理体系。需要重新实现一套数据血缘、数据质量管理体系。
Kafka不支持update/upsert,目前Kafka仅支持append。实际场景中在DWS轻度汇聚层很多时候是需要更新的,
DWD明细层到DWS轻度汇聚层一般会根据时间粒度以及维度进行一定的聚合,用于减少数据量,提升查询性能。
假如原始数据是秒级数据,聚合窗口是1分钟,那就有可能产生某些延迟的数据经过时间窗口聚合之后需要更新之前数据的需求。
这部分更新需求无法使用Kafka实现。
---------------------------------------------------------------------------------------------------------
所以实时数仓发展到现在的架构,一定程度上解决了数据报表时效性问题,但是这样的架构依然存在不少问题,
随着技术的发展,相信基于Kafka+Flink的实时数仓架构也会进一步往前发展,那么到底往哪些方向发展,
我们可以结合大公司中技术选型可以推测实时数仓的发展大致会走向“批流一体”。
---------------------------------------------------------------------------------------------------------
这条架构中无论是流处理还是批处理,数据存储都统一到数据湖Iceberg上,这一套结构将存储统一后,解决了Kappa架构很多痛点,解决方面如下:
可以解决Kafka存储数据量少的问题。目前所有数据湖基本思路都是基于HDFS之上实现的一个文件管理系统,所以数据体量可以很大。
DW层数据依然可以支持OLAP查询。同样数据湖基于HDFS之上实现,只需要当前的OLAP查询引擎做一些适配就可以进行OLAP查询。
批流存储都基于Iceberg/HDFS存储之后,就完全可以复用一套相同的数据血缘、数据质量管理体系。
实时数据的更新。
d.混合架构
传统离线大数据架构已经不能满足一些公司中实时业务需求,因为随着互联网及物联网发展,
越来越多的公司多多少少涉及一些流式业务处理场景。由Lambda离线数仓+实时数仓架构到Kappa实时数仓架构,
都涉及到实时数仓开发,那么现实业务开发中到底使用Lambda架构还是Kappa架构?
---------------------------------------------------------------------------------------------------------
对比项 传统离线大数据架构 Lambda架构 Kappa架构
实时性 离线(无法处理实时业务) 离线+实时 实时(批流一体)
计算资源 只有批处理 批和流同时运行,资源消耗大 只有流处理,资源开销小
重新计算时吞吐量 批处理全量处理,吞吐量大 批处理全量处理,吞吐量大 流式全量处理,吞吐较批处理全量要低一些
开发、测试难度 批处理一套代码,开发、测试、上线难度小 批处理和流处理相同逻辑两条代码,开发、测试、上线难度大 只需实现一套代码,开发、测试、上线难度相对较小
运维成本 维护一套引擎,运维成本小 维护两套引擎,运维成本大 维护一套引擎,运维成本小
---------------------------------------------------------------------------------------------------------
通过以上对比来看,三者对比结果如下:
从架构上来看 ,三套架构有比较明显区别,真正的实时数仓以Kappa架构为主,而离线数仓以传统离线大数据架构为主,Lambda架构可以认为是两者的中间态。目前在业界中所说的实时数仓大多是Lambda架构,这是由需求决定的。
从建设方法上来看 ,实时数仓和离线数仓基本还是沿用传统的数仓主题建模理论,产出事实宽表。另外实时数仓中实时流数据的join有隐藏时间语义,在建设中需注意。
从数据保障上来看 ,实时数仓因为要保证实时性,所以对数据量的变化较为敏感,在大促等场景下需要提前做好压测和主备保障工作,这是与离线数仓较为明显的一个区别。
2.2 示例
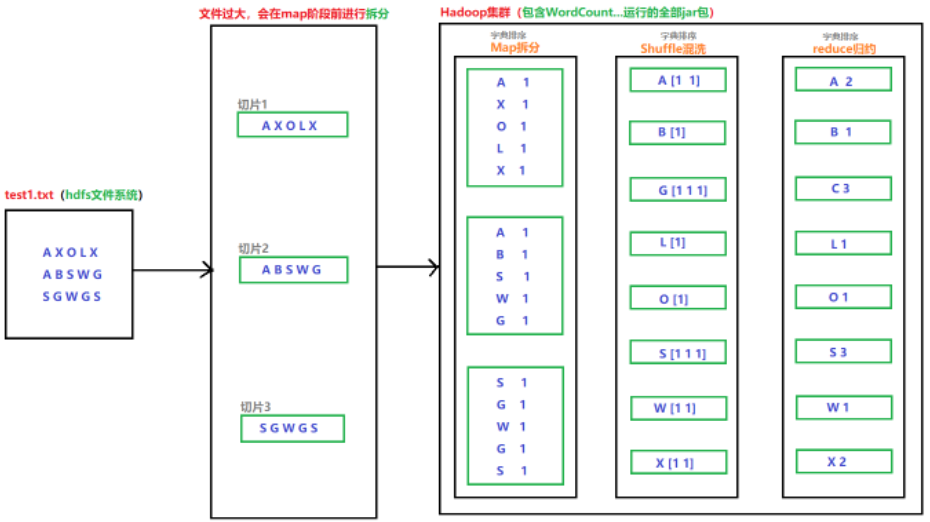
01.官方示例:map(拆)+reduce(合),位于/usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
a.新建hdfs目录
/myinput/ -> 放 test1.txt
hello world
hello hadoop
/myinput/ -> 放 test1.txt
hello china
-----------------------------------------------------------------------------------------------------
/myoutput -> 不要创建该目录,org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/myoutput already exists
b.用WordCount.java程序执行test1.txt、test2.txt文件
[root@master ~]# /usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /workspace/mapreduce1/input/demo00/ /workspace/mapreduce1/output/demo00/
24/08/25 05:32:05 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.185.150:8032
24/08/25 05:32:05 INFO mapreduce.JobSubmissionFiles: Permissions on staging directory /tmp/hadoop-yarn/staging/root/.staging are incorrect: rwxrwxrwx. Fixing permissions to correct value rwx------
24/08/25 05:32:06 INFO input.FileInputFormat: Total input paths to process : 2
24/08/25 05:32:06 INFO mapreduce.JobSubmitter: number of splits:2
24/08/25 05:32:06 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1724534865671_0001
24/08/25 05:32:07 INFO impl.YarnClientImpl: Submitted application application_1724534865671_0001
24/08/25 05:32:07 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1724534865671_0001/
24/08/25 05:32:07 INFO mapreduce.Job: Running job: job_1724534865671_0001
24/08/25 05:32:17 INFO mapreduce.Job: Job job_1724534865671_0001 running in uber mode : false
24/08/25 05:32:17 INFO mapreduce.Job: map 0% reduce 0%
24/08/25 05:32:28 INFO mapreduce.Job: map 50% reduce 0%
24/08/25 05:32:29 INFO mapreduce.Job: map 100% reduce 0%
24/08/25 05:32:35 INFO mapreduce.Job: map 100% reduce 100%
24/08/25 05:32:36 INFO mapreduce.Job: Job job_1724534865671_0001 completed successfully
24/08/25 05:32:36 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=67
FILE: Number of bytes written=368857
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=238
HDFS: Number of bytes written=33
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=18778
Total time spent by all reduces in occupied slots (ms)=3756
Total time spent by all map tasks (ms)=18778
Total time spent by all reduce tasks (ms)=3756
Total vcore-milliseconds taken by all map tasks=18778
Total vcore-milliseconds taken by all reduce tasks=3756
Total megabyte-milliseconds taken by all map tasks=19228672
Total megabyte-milliseconds taken by all reduce tasks=3846144
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=61
Map output materialized bytes=73
Input split bytes=202
Combine input records=6
Combine output records=5
Reduce input groups=4
Reduce shuffle bytes=73
Reduce input records=5
Reduce output records=4
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=433
CPU time spent (ms)=2560
Physical memory (bytes) snapshot=519319552
Virtual memory (bytes) snapshot=6234574848
Total committed heap usage (bytes)=301146112
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=36
File Output Format Counters
Bytes Written=33
c.查看执行后的结果
[root@master ~]# /usr/local/hadoop/hadoop-2.7.7/bin/hadoop fs -text /workspace/mapreduce1/output/demo00/part-r-00000
china 1
hadoop 1
hello 3
world 1
02.jar包问题
a.仿照系统自带的WordCount.java进行编写
WCMapper、WCReducer、WCDriver
b.终端打包
mvn packagew
c.jar包问题
只写WordCount.java,,并不需要真实的引入jar,然后直接扔到yarn集群中即可。
本次在本地编写wordcount时,引入jar只是在编写有用(不要报错,方便代码提示)
d.新建hdfs目录
/myinput/ -> 放 test1.txt
hello world
hello hadoop
/myinput/ -> 放 test1.txt
hello china
-----------------------------------------------------------------------------------------------------
/myoutput -> 不要创建该目录,org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/myoutput already exists
e.hadoop-mapreduce-examples-2.7.7.jar
hadoop jar [jar文件] [main启动类] [输入文件] [输出文件]
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/hadoop-mapreduce-examples-2.7.7.jar wordcount /workspace/mapreduce1/input/demo00/ /workspace/mapreduce1/output/demo00/
f.查看
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop fs -text /workspace/mapreduce1/output/demo00/part-r-00000
g.附:SpringBoot的jar包为何不能为hadoop所用
SpringBoot打的jar包,java -jar vilgob-0.0.1-SNAPSHOT.jar
-----------------------------------------------------------------------------------------------------
本质问题为Spring Boot 打成的 jar 和普通的 jar 的区别,Spring Boot 项目最终打包成的 jar 是可执行 jar ,
这种 jar 可以直接通过 java -jar xxx.jar 命令来运行,这种 jar 不可以作为普通的 jar 被其他项目依赖,
即使依赖了也无法使用其中的类。Spring Boot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。
-----------------------------------------------------------------------------------------------------
普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,
在 \BOOT-INF\classes 目录下才是我们的代码,因此无法被直接引用。
如果非要引用,可以在 pom.xml 文件中增加配置,将 Spring Boot 项目打包成两个 jar ,一个可执行,一个可引用。
2.3 环境
00.常见报错
a.报错1
出现hdfs.DFSClient: DataStreamer Exception的问题:
原因:在进行namenode格式化时多次造成那么spaceID不一致。
1.删除core.site.xml中临时文件指定的目录
2.重新进行格式化 hadoop name -formate
3.启动集群 start-all.sh
4.创造目录 hadoop fs -mkdir /user hadoop fs -mkdir /user/root
5.上传文件 hdfs dfs -put movie.csv /user/root/
b.报错2
出现 Call From master to localhost:9000 failed on connection exception…的错误:
原因没有打开权限:修改 /hadoop/etc/hadoop/hdfs.site.xml
解决:找到dfs.permissions属性修改为false(默认为true)
-----------------------------------------------------------------------------------------------------
org.apache.hadoop.security.AccessControlException --权限问题(关闭hdfs验证)
/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml --追加内容
dfs.name.dir: NameNode 的元数据存储位置(本地文件系统)
dfs.data.dir: DataNode 的数据块存储位置(本地文件系统)
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
c.报错3
问题:org.apache.hadoop.security.AccessControlException: Permission denied: user
原因:在执行Hadoop的创建目录、写数据等情况,可能会出现该异常,而在读文件的时候却不会报错,
这主要是由于系统的用户名不同导致的,由于我们进行实际开发的时候都是用Windows操作系统,
而编译后的JAVA程序是部署在Linux上的。而Windows的用户名一般都是自定义的或者是administrator,
Linux的用户名是root,对于Hadoop的部署,也有可能是hadoop用户名。
-----------------------------------------------------------------------------------------------------
由于,Hadoop的权限验证是依靠Linux系统的,而用户名不一致,会报错,这个错误很经典,异常名是:
org.apache.hadoop.security.AccessControlException
-----------------------------------------------------------------------------------------------------
对应的修改方法,是配置hdfs-site.xml文件,查看hdfs-default.xml可以看到这一句:
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
将这里面的value改为false,写到hdfs-site.xml中即可
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
d.报错4
报错:chmod: changing permissions of '/workspace': Cannot set permission for /workspace. Name node is in safe mode.
解决:hdfs dfsadmin -safemode leave
-----------------------------------------------------------------------------------------------------
对应的修改方法,是配置hdfs-site.xml文件
<property>
<name>dfs.safemode.threshold.pct</name>
<value>1.0</value>
<description>The percentage of blocks that should satisfy the minimum replication requirement.</description>
</property>
<property>
<name>dfs.safemode.min.datanodes</name>
<value>1</value>
<description>The minimum number of datanodes that must be available before leaving safemode.</description>
</property>
-----------------------------------------------------------------------------------------------------
如果 HDFS 频繁进入安全模式,可能是因为集群性能问题或者数据节点不可用等原因。
优化数据节点性能,确保网络连接稳定,检查并修复可能存在的副本失效问题等,也有助于减少安全模式的触发。
e.报错5
报错:hive无法远程连接
-----------------------------------------------------------------------------------------------------
对应的修改方法,是配置core-site.xml文件
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
3 hive
3.1 概念
01.概念
Hive 是一个架构在 Hadoop 之上的数据仓库基础工具,它可以处理结构化和半结构化数据,
它使得查询和分析存储在 Hadoop 上的数据变得非常方便。
---------------------------------------------------------------------------------------------------------
在没有 Hive 之前,处理数据必须开发复杂的 MapReduce 作业,但现在有了 Hive,你只要开发简单的 SQL 查询就可以达到
MapReduce 作业同样的查询功能。Hive 主要针对的是熟悉 SQL 的用户。Hive 使用的查询语言称为 HiveQL(HQL),
它跟 SQL 很像。HiveQL 自动把类 SQL 语句转换成 MapReduce 作业。Hive 对 Hadoop 的复杂性简单化了,
而且使用 Hive 并不需要你学习 Java 语言。
-----------------------------------------------------------------------------------------------------
Hive 一般在终端执行,并且把 SQL 语句转换成一系列能在 Hadoop 集群执行作业。
Apache Hive 可以让存储在 HDFS 的数据以表的方式呈现。
02.为什么使用Hive
直接使用 MapReduce 所面临的问题:
人员学习成本太高
项目周期要求太短
MapReduce 实现复杂查询逻辑开发难度太大
---------------------------------------------------------------------------------------------------------
什么要使用 Hive:
更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
03.优点和缺点
优点:
Hive 以简单的方式提供数据摘要,数据查询和数据分析能力。
Hive 支持外部表,这使得它可以处理未存储在 HDFS 的数据。
Apache Hive 非常适合 Hadoop 的底层接口需求。
支持数据分区
Hive 有一个基于规则的优化器,负责优化逻辑计划。
可扩展性以及可伸缩性
使用 HiveQL 不需要深入掌握编程语言,只有掌握基本的 SQL 知识就行,使用门槛较低。
处理结构化数据。
使用 Hive 执行即时查询做数据分析。
---------------------------------------------------------------------------------------------------------
缺点:
Hive 不支持实时查询和行级更新。
高延迟。
不适用于在线事务处理。
---------------------------------------------------------------------------------------------------------
优点:
1)Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员处理大数据的难度
2)使用JDBC 接口,开发人员更易开发应用;
3)以MR 作为计算引擎、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力;
4)统一的元数据管理(Derby、MySql等),并可与Pig 、spark等共享;
---------------------------------------------------------------------------------------------------------
缺点:
1)Hive 的HQL 表达的能力有限,比如不支持UPDATE、非等值连接、DELETE、INSERT单条等;insert单条代表的是 创建一个文件。
2)由于Hive自动生成MapReduce 作业, HQL 调优困难;
3)粒度较粗,可控性差,是因为数据是读的时候进行类型的转换,mysql关系型数据是在写入的时候就检查了数据的类型。
4)hive生成MapReduce作业,高延迟,不适合实时查询。
04.为什么使用 Apache Hive
Apache Hive 避免开发人员给临时需求开发复杂的 Hadoop MapReduce 作业。因为 hive 提供了数据的摘要、分析和查询。
Hive 具有比较好的扩展性和稳定性。有、由于 Hive 跟 SQL 语法上比较类似, 这对于 SQL 开发人员在学习和开发 Hive
时成本非常低,比较容易上手。Apache Hive 最重要的特性就是不会 Java,依然可以用好 Hive。
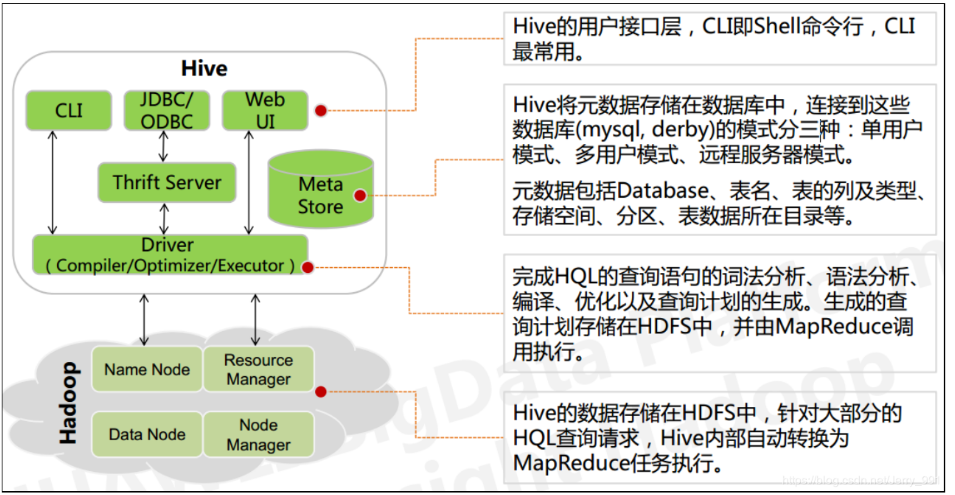
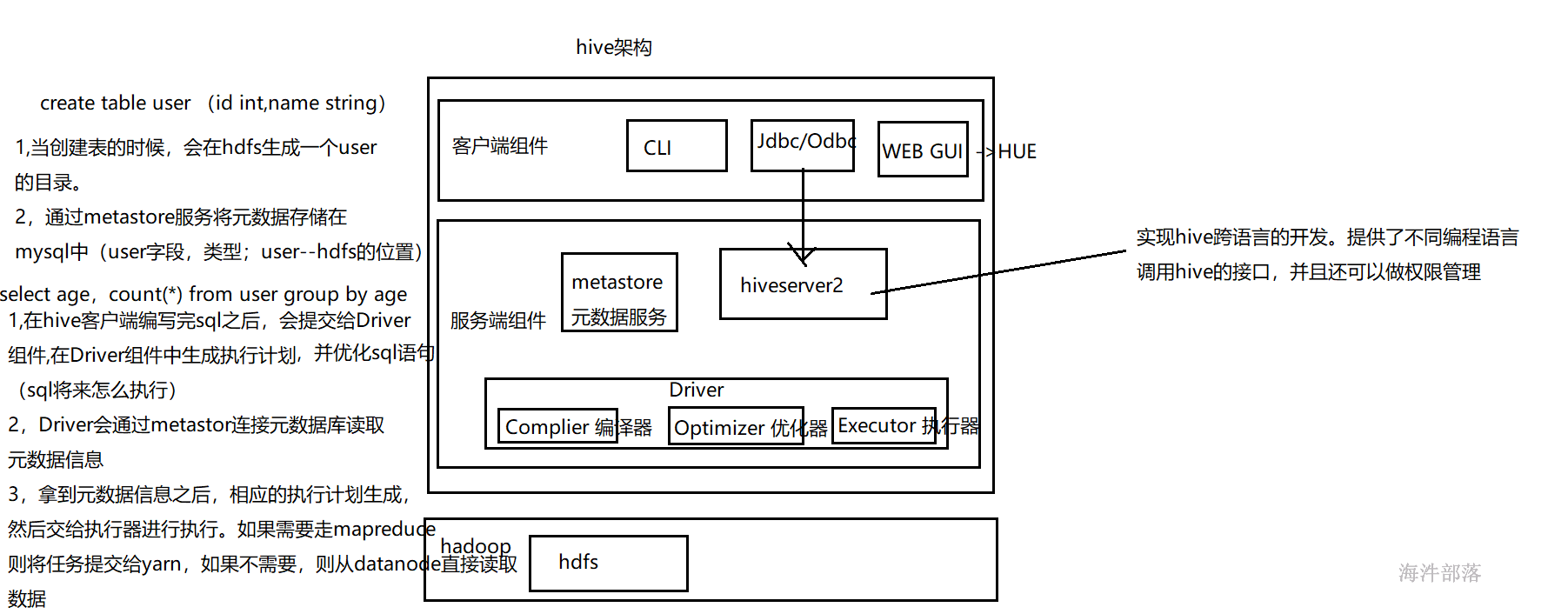
05.服务端组件
Driver 组件:该组件包括 Complier、Optimizer 和 Executor,它的作用是将 HiveQL 语句进行解析、编译优化,生成执行计划,然后调用底层的 MapReduce 计算框架。
Metastore 组件:元数据服务组件,这个组件存储 Hive 的元数据,hive 的元数据存储在关系数据库里,hive 支持的关系数据库有 derby、mysql。元数据对于 hive 十分重要,因此 hive 支持把 metastore 服务独立出来,安装到远程的服务器集群里,从而解耦 hive 服务和 metastore 服务,保证 hive 运行的健壮性。
Thrift 服务:thrift 是 facebook 开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive 集成了该服务,能让不同的编程语言调用 hive 的接口。
06.客户端组件
CLI:command line interface,命令行接口。
Thrift 客户端:上面的架构图里没有写上 Thrift 客户端,但是 hive 架构的许多客户端接口是建立在 thrift客户端之上,包括 JDBC 和 ODBC 接口。
WEB GUI:hive 客户端提供了一种通过网页的方式访问 hive 所提供的服务。这个接口对应 hive 的 hwi 组件(hive web interface),使用前要启动 hwi 服务。
07.Hive Shell
shell 是我们和 Hive 交互的主要方式,我们可以在 Hive shell 执行 HiveQL 语句以及其他命令。Hive Shell 非常像 MySQL shell,它是 Hive 的命令行接口。HiveQL 跟 SQL 一样也是不区分大小写的。我们可以以两种方式执行 Hive Shell:非交互式模式和交互式模式:
非交互式模式 Hive:Hive Shell 可以以非交互式模式执行。只要使用 -f 选项并指定包含 HQL 语句的文件的路径。如:hive -f my-script.sql
交互式模式 Hive:所谓交互式模式,就是在 Hive Shell 直接执行命令,Hive 会在 shell 返回执行结果。只要在 Linux Shell 输入 hive 即可进去交互式模式 hive shell。
08.工具:HUE
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
支持基于Impala的应用进行交互式查询
支持Spark编辑器和仪表板(Dashboard)
支持Pig编辑器,并能够提交脚本任务
支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
支持Job设计器,能够创建MapReduce/Streaming/Java Job
支持Sqoop 2编辑器和仪表板(Dashboard)
支持ZooKeeper浏览器和编辑器
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
09.与关系数据库的区别
1)hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2)hive使用mapreduce做运算,与传统数据库相比运算数据规模要大得多;
3)关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据统计分析的,实时性很差;实时性差导致hive的应用场景和关系数据库有很大的区别;
4)Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比Hive差很多。
---------------------------------------------------------------------------------------------------------
Hive 关系型数据库
查询语言 HQL SQL
数据存储 HDFS Raw Device or Local FS
执行 MapReduce spark 数据库引擎
数据存储校验 存储不校验 存储校验
可扩展性 强 有限
执行延迟 高 低
处理数据规模 大 小
3.2 组件
00.HQL的执行流程
语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
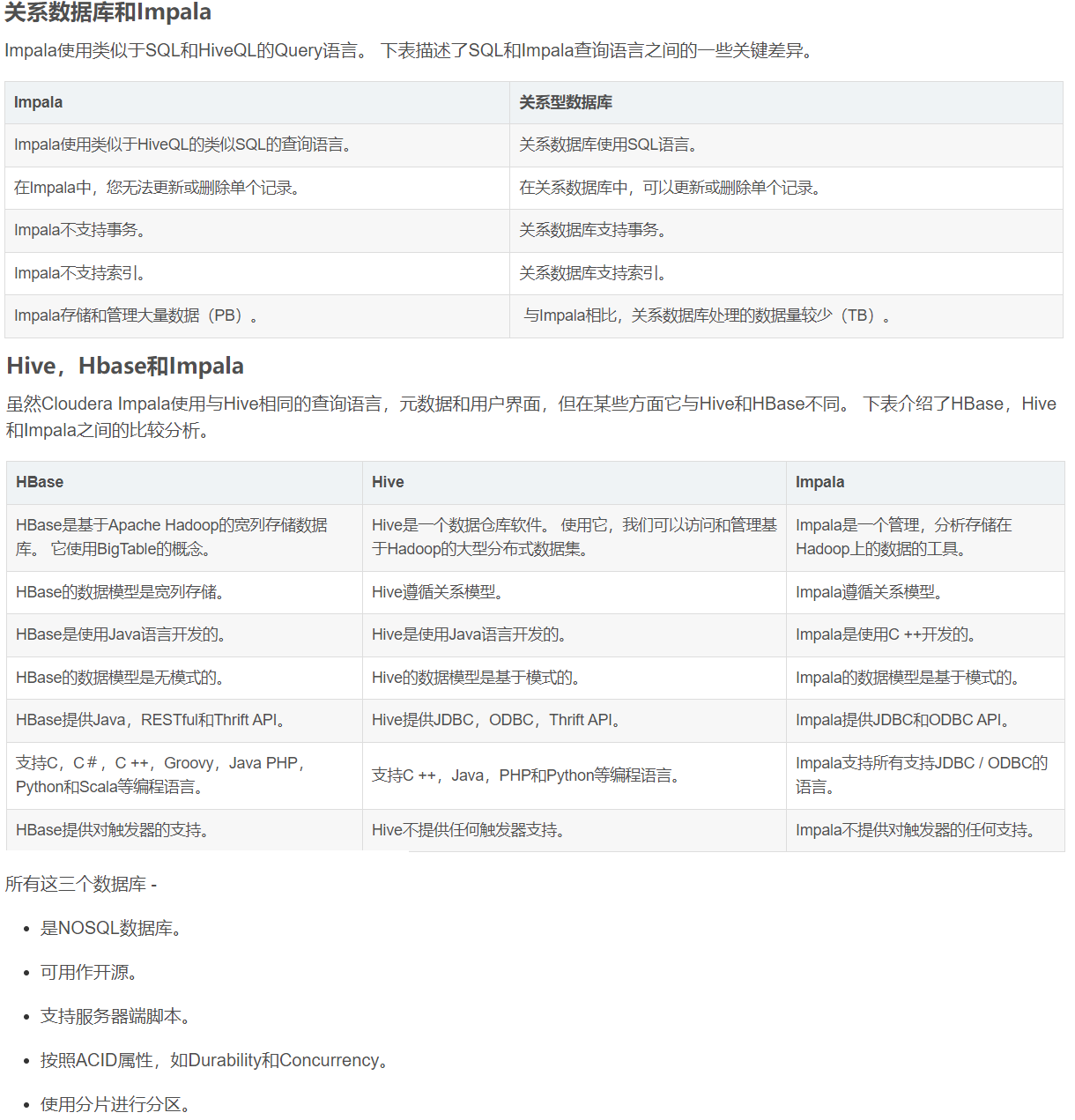
01.Metastore
metastore 是 Hive 元数据的集中存放地。metastore 元数据存储主要体现在两个方面:服务和后台数据的存储。
元数据包含用 Hive 创建的 database、table 等的元信息。元数据存储在关系型数据库中。如 Derby、MySQL 等。
---------------------------------------------------------------------------------------------------------
客户端连接 metastore 服务,metastore 再去连接 MySQL 数据库来存取元数据。有了 metastore 服务,
就可以有多个客户端同时连接,而且这些客户端不需要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。
---------------------------------------------------------------------------------------------------------
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。
所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,
也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
---------------------------------------------------------------------------------------------------------
Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/sparksql
中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto/impala/sparksql
中创建一张表,在 Hive 中也可以直接使用。
02.数据模型
a.介绍
Hive 是一个基于 Hadoop 的开源数据仓库系统,主要用于对存储在 Hadoop 上的数据进行查询和分析。
它可以处理结构化和半结构化数据。而 Hive 中的数据可以分成以下几类:
表
分区
桶
b.表
a.介绍
Hive 表跟关系数据库里面的表类似。逻辑上,数据是存储在 Hive 表里面的,而表的元数据描述了数据的布局。
我们可以对表执行过滤,关联,合并等操作。在 Hadoop 里面,物理数据一般是存储在 HDFS 的,
而元数据是存储在关系型数据库的。Hive 有下面两种表:
内部表
外部表
当我们在 Hive 创建表的时候,Hive 将以默认的方式管理表数据,也就是说,Hive 会默认把数据存储到
/user/hive/warehouse 目录里面。除了内部表,我们可以创建外部表,外部表需要指定数据的目录。
我们可以看到这两种不同类型的表在使用 LOAD 和 DROP 命令时的差异。
b.内部表
当我们把数据 load 到内部表的时候,Hive 会把数据存储在 /user/hive/warehouse 目录下。
-------------------------------------------------------------------------------------------------
CREATE TABLE managed_table (dummy STRING);
LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_table;
根据上面的代码,Hive 会把文件 data.txt 文件存储在 managed_table 表的 warehouse 目录下,
即 hdfs://user/hive/warehouse/managed_table 目录。
-------------------------------------------------------------------------------------------------
如果我们用 drop 命令把表删除:
DROP TABLE managed_table
这样将会把表以及表里面的数据和表的元数据都一起删除。
c.外部表
外部表与内部表的行为上有些差别。我们能够控制数据的创建和删除。删除外部表的时候,Hive 只会删除表的元数据,
不会删除表数据。数据路径是在创建表的时候指定的:
-------------------------------------------------------------------------------------------------
CREATE EXTERNAL TABLE external_table (dummy STRING)
LOCATION '/user/tom/external_table';
LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
-------------------------------------------------------------------------------------------------
利用 EXTERNAL 关键字创建外部表,Hive 不会去管理表数据,所以它不会把数据移到 /user/hive/warehouse 目录下。
甚至在执行创建语句的时候,它不会去检查建表语句中指定的外部数据路径是否存在。这个是比较有用的特性,
我们可以在表创建之后,再创建数据。
外部表还有一个比较重要的特性,上面有提到的,就是删除外部表的时候,Hive 只有删除表的元数据,而不会删除表数据。
d.区别
内部表又叫做管理表 (Managed/Internal Table),创建表时不做任何指定,默认创建的就是内部表。
想要创建外部表 (External Table),则需要使用 External 进行修饰。 内部表和外部表主要区别如下:
-------------------------------------------------------------------------------------------------
内部表
数据存储位置:内部表数据存储的位置由 hive.metastore.warehouse.dir 参数指定,默认情况下表的数据存储在 HDFS 的 /user/hive/warehouse/数据库名.db/表名/ 目录下
导入数据:在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下,数据的生命周期由 Hive 来进行管理
删除表:删除元数据(metadata)和文件
-------------------------------------------------------------------------------------------------
外部表
数据存储位置:外部表数据的存储位置创建表时由 Location 参数指定;
导入数据:外部表不会将数据移动到自己的数据仓库目录下,只是在元数据中存储了数据的位置
删除表:只删除元数据(metadata)
c.分区
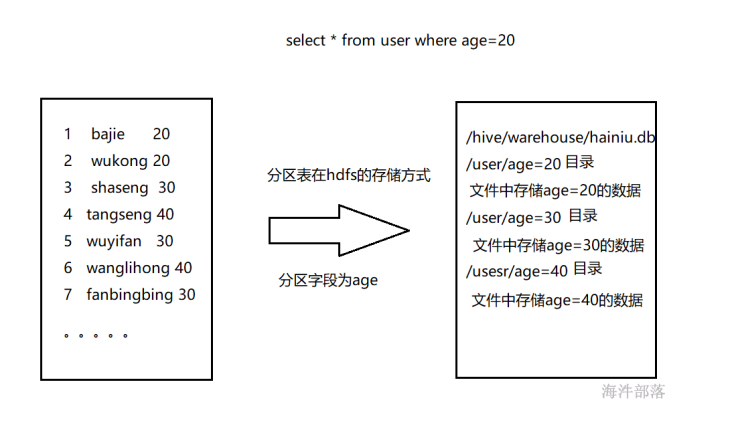
a.介绍
为了提高查询数据的效率,Hive 提供了表分区机制。分区表基于分区键把具有相同分区键的数据存储在一个目录下,
在查询某一个分区的数据的时候,只需要查询相对应目录下的数据,而不会执行全表扫描,
也就是说,Hive 在查询的时候会进行分区剪裁。每个表可以有一个或多个分区键。
-------------------------------------------------------------------------------------------------
Hive 表可以被分成多个分区。准确的说应该是,表里面的数据可以按某一个列或者几个列进行分区,比如按天分区,
不同日期的数据在不同的分区。查数据时只需查对应分区的数据,而不需要全表搜索。
b.下面通过一个例子来更好的理解分区概念
如上图所示,假如你有一个存储学生信息的表,表名为 student_details,列分别是 student_id,name,department,
year 等。现在,如果你想基于 department 列对数据进行分区。那么属于同一个 department 的学生将会被分在同一个
分区里面。在物理上,一个分区其实就是表目录下的一个子目录。
-------------------------------------------------------------------------------------------------
假如你在 student_details 表里面有三个 department 的数据,分别为 EEE,ECE 和 ME。那么这个表总共就会有三个
分区,也就是图中的绿色方块部分。对于每个 department ,您将拥有与该 department 相关的所有数据,这些数据位于
表目录下的单独子目录中。
-------------------------------------------------------------------------------------------------
假如所有 department = EEE 的学生数据被存储在 /user/hive/warehouse/student_details/department=EEE 目录下。
那么查询 department 为 EEE 的学生信息,只需要查询 EEE 目录下的数据即可,不需要全表扫描,这样查询的效率就比较高。
而在真实生产环境中,你需要处理的数据可能会有几百 TB,如果不分区,在你只需要表的其中一小部分数据的时候,
你不得不走全表扫描,这样的查询将会非常慢而且浪费资源,可能 95% 的数据跟你的查询语句并没有关系。
c.为什么分区很重要
随着互联网发展,数据已经越来越大,PB级别的数据量已经非常常见。因此从 HDFS 查询这么巨大的数据变得比较困难。
而 Hive 的出现降低了数据查询的负担。Apache Hive 把 SQL 代码转换的 MapReduce 作业,并提交到 Hadoop 集群执行。
当我们提交一个 SQL 查询的时候,Hive 会读取全部数据集。如果表的数据非常大,那么 MapReduce 作业的执行就比较低效。
因此,在表创建分区可以明显提升数据查询效率。
-------------------------------------------------------------------------------------------------
具有分区的表称为分区表,分区表的数据会被分成多个分区,每个分区对应一个分区列的值,每个分区在 HDFS 里面
其实就是表目录下的一个子目录。如果在查询的时候只需要特定分区的数据,那么 Hive 只会遍历该分区目录下的数据。
这样能够可以避免全表扫描减低 IO,提升查询性能。
d.创建分区表语法
CREATE TABLE table_name (column1 data_type, column2 data_type)
PARTITIONED BY (partition1 data_type, partition2 data_type,….);
e.Hive分区类型
a.静态分区
把输入数据文件单独插入分区表的叫静态分区。
通常在加载文件(大文件)到 Hive 表的时候,首先选择静态分区。
在加载数据时,静态分区比动态分区更节省时间。
你可以通过 alter table add partition 语句在表中添加一个分区,并将文件移动到表的分区中。
我们可以修改静态分区中的分区。
您可以从文件名、日期等获取分区列值,而无需读取整个大文件。
如果要在 Hive 使用静态分区,需要把 hive.mapred.mode 设置为 strict,set hive.mapred.mode=strict。
静态分区是在严格模式进行下。
你可以在 Hive 的内部表和外部表使用静态分区。
b.动态分区
对分区表的一次性插入称为动态分区。
通常动态分区表从非分区表加载数据。
在加载数据的时候,动态分区比静态分区会消耗更多时间。
如果需要存储到表的数据量比较大,那么适合用动态分区。
假如你要对多个列做分区,但又不知道有多少个列,那么适合使用动态分区。
动态分区不需要 where 子句使用 limit。
不能对动态分区执行修改。
可以对内部表和外部表使用动态分区。
使用动态分区之前,需要把模式修改为非严格模式。set hive.mapred.mode=nostrict。
c.分区的优点与缺点
优点
Hive 的分区可以水分分散执行压力。
数据查询性能比较好。
不需要在整个表列中搜索单个记录。
---------------------------------------------------------------------------------------------
缺点
可能会创建太多的小分区,也就是说可能会创建很多目录。
分区对于低容量数据是有效的,但有些查询比如对大的数据量进行分组需要消耗很长时间。
e.Hive 分区示例
a.介绍
让我们以例子的方式来理解 Hive 里面的数据分区。假如有一个表,表名为 Tab1,该表存储员工详细信息,
列包括 id,name,dept 和 yoj(year of joining)。假如我们需要查询所有 2012 年入职的员工,
那么 hive 会在全表搜索满足条件的数据。但如果我们对员工数据以yoj 进行分区并把数据对应的数据存储到
单独文件里面,那么将会减少查询时间。下面的例子演示了如何对数据做分区。
b.操作
存储员工数据的文件名是 file1:
tab1/clientdata/file1
id, name, dept, yoj
1, sunny, SC, 2009
2, animesh, HR, 2009
3, sumeer, SC, 2010
4, sarthak, TP, 2010
---------------------------------------------------------------------------------------------
现在我们把上面的数据使用 yoj 字段分成两个文件。
tab1/clientdata/2009/file2
1, sunny, SC, 2009
2, animesh, HR, 2009
tab1/clientdata/2010/file3
3, sumeer, SC, 2010
4, sarthak, TP, 2010
---------------------------------------------------------------------------------------------
现在如果我们从表查询数据,那么只有特定分区的数据会被搜索到。分区表创建语句如下:
CREATE TABLE table_tab1 (id INT, name STRING, dept STRING, yoj INT) PARTITIONED BY (year STRING);
LOAD DATA LOCAL INPATH tab1’/clientdata/2009/file2’OVERWRITE INTO TABLE studentTab PARTITION (year='2009');
LOAD DATA LOCAL INPATH tab1’/clientdata/2010/file3’OVERWRITE INTO TABLE studentTab PARTITION (year='2010');
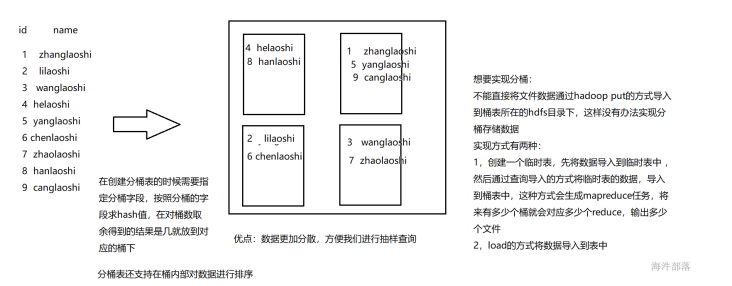
d.桶
a.介绍
Hive 可以对每一个表或者是分区,进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。
Hive 是针对表的某一列进行分桶。Hive 采用对表的列值进行哈希计算,然后除以桶的个数求余的方式决定该条记录
存放在哪个桶中。分桶的好处是可以获得更高的查询处理效率。使取样更高效。
b.为什么要分桶
Hive 分区可以把 hive 表的数据分成多个文件/目录。但有些事情,分区也可能无能为力。比如:
分区数不能太多,分区数量有限制
每个分区数据大小不一定相等
-------------------------------------------------------------------------------------------------
分区不可能适用于所有场景。比如,基于地理位置(比如:国家)对表进行分区时,某些较大的国家将会具有较大分区
,可能有四五个国家的数量占了所有数据的 70-80%。而小国家的数据创建的分区则比较小。那么这时,
给表做分区就不是个好主意。为了解决分区不平衡的问题,Hive 提出了分桶的概念。它是另一种针对表数据划分的技术。
c.特性
数据分桶原理是基于对分桶列做哈希计算,然后对哈希的结果和分桶数取模。分桶特性如下:
哈希函数取决于分桶列的类型。
具有相同分桶列的记录将始终存储在同一个桶中。
使用 clustered by 将表分成桶。
通常,在表目录中,每个桶只是一个文件,并且桶的编号是从 1 开始的。
可以先分区再分桶,也可以直接分桶。
此外,分桶表创建的数据文件大小几乎是一样的。
d.优点
与非分桶表相比,分桶表提供了高效采样。通过采样,我们可以尝试对一小部分数据进行查询,以便在原始数据集非常庞大时进行测试和调试。
由于数据文件的大小是几乎一样的,map 端的 join 在分桶表上执行的速度会比分区表快很多。在做 map 端 join 时,处理左侧表的 map 知道要匹配的右表的行在相关的桶中,因此只需要检索该桶即可。
分桶表查询速度快于非分桶表。
分桶的还提供了灵活性,可以使每个桶中的记录按一列或多列进行排序。 这使得 map 端 join 更加高效,因为每个桶之间的 join 变为更加高效的合并排序(merge-sort)。
e.缺点
分桶并不能确保数据加载的恰当性。数据加载到分桶的逻辑需要由我们自己处理。
f.分桶表创建命令
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)]
INTO num_buckets BUCKETS;
-------------------------------------------------------------------------------------------------
每个桶只是表目录或者分区目录下的一个文件,如果表不是分区表,那么桶文件会存储在表目录下,如果表是分区表,
那么桶文件会存储在分区目录下。所以你可以选择把分区分成 n 个桶,那么每个分区目录下就会有 n 个文件。
从上图可以看到,每个分区有 2 个桶。因此每个分区就会有 2 个文件,每个文件将会存储该分区下的数据。
g.分通表创建
我们可以利用 create table 语句里面的 clustered by 子句和 sorted by 子句来创建分桶表。
-------------------------------------------------------------------------------------------------
HiveQL 代码如下:
CREATE TABLE bucketed_user(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64),
state VARCHAR(64),
post STRING,
phone1 VARCHAR(64),
phone2 STRING,
email STRING,
web STRING
)
COMMENT 'A bucketed sorted user table'
PARTITIONED BY (country VARCHAR(64))
CLUSTERED BY (state) SORTED BY (city) INTO 32 BUCKETS
STORED AS SEQUENCEFILE;
-------------------------------------------------------------------------------------------------
从上面创建表代码可知,我们为每个分区创建了 32 个桶。需要注意的是分桶字段和排序字段需要出现在列定义中,而分区字段不能出现在列定义列表里面。
h.插入数据到分桶表
我们为分桶表或者分区表加载数据时,不能直接使用 load data 命令。
必须要用 insert overwrite table ... select ... from 语句从其他表把数据加载到分桶分区表。
所以我们需要在 Hive 创建一个临时表来先把数据加载进去,
然后再用 insert overwrite table ... select ... from 语句把数据插入到 分区分桶表。
-------------------------------------------------------------------------------------------------
假如我们已经创建了一个临时表,表名为 temp_user 。并且使用 load data 命令把数据先转载到临时表。
接下来就可以把数据插入到正式表了,HiveQL 如下:
-------------------------------------------------------------------------------------------------
set hive.enforce.bucketing = true;
INSERT OVERWRITE TABLE bucketed_user PARTITION (country)
SELECT firstname,
lastname,
address ,
city,
state,
post,
phone1,
phone2,
email,
web,
country
FROM temp_user;
i.一些重要的点:
在做分区的时候,hive.enforce.bucketing = true 和 hive.exec.dynamic.partition=true 发挥的作用有点像。
前者是自动分桶,后者是自动分区。所以在插入数据的时候,我们可以通过设置 hive.enforce.bucketing
这个属性等于 true 来启用自动分区。
-------------------------------------------------------------------------------------------------
自动分桶会自动把 reduce 任务数设置成等于分桶数量,而分桶数量是在 create table 的语句中设置的。
如上面创建语句中为 32 个分桶。另外还会根据 CLUSTERED BY 设置的字段分桶。
-------------------------------------------------------------------------------------------------
如果我们不在 Hive 会话中把 hive.enforce.bucketing 设置为 true,那么我们必须在上面的 INSERT ... SELECT
语句的前面,需要把 reduce 任务数手动设置为 32(set mapred.reduce.tasks = 32),也就是说要确保 reduce
任务数和分桶数是一致的。
j.完整的代码
我们把完整的代码保存在 bucketed_user_creation.hql 文件。假如示例中的数据保存在 user_table.txt 中。
-------------------------------------------------------------------------------------------------
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.enforce.bucketing = true;
DROP TABLE IF EXISTS bucketed_user;
CREATE TEMPORARY TABLE temp_user(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
country VARCHAR(64),
city VARCHAR(64),
state VARCHAR(64),
post STRING,
phone1 VARCHAR(64),
phone2 STRING,
email STRING,
web STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH '/home/user/user_table.txt' INTO TABLE temp_user;
CREATE TABLE bucketed_user(
firstname VARCHAR(64),
lastname VARCHAR(64),
address STRING,
city VARCHAR(64),
state VARCHAR(64),
post STRING,
phone1 VARCHAR(64),
phone2 STRING,
email STRING,
web STRING
)
COMMENT 'A bucketed sorted user table'
PARTITIONED BY (country VARCHAR(64))
CLUSTERED BY (state) SORTED BY (city) INTO 32 BUCKETS
STORED AS SEQUENCEFILE;
set hive.enforce.bucketing = true;
INSERT OVERWRITE TABLE bucketed_user PARTITION (country)
SELECT firstname ,
lastname ,
address,
city,
state,
post,
phone1,
phone2,
email,
web,
country
FROM temp_user;
e.分区与分桶
a.分区与分桶
Apache Hive 是用于查询和分析大数据集的开源数据仓库工具。Hive 里面把数据划分成三种数据模型,即表、分区、分桶。
表和关系型数据库的表概念类似,也是以行和列来呈现数据。不同的是 Hive 中的表可以分成内部表和外部表。
本节我们讨论 Hive 中的另外两个数据模型的 —— 分区和分桶。
-------------------------------------------------------------------------------------------------
分区
分区按表定义的分区字段,把具有相同字段值的数据存储到一个目录中。Hive 中的每个表可能有一个或多个分区键来
标识特定的分区。在查询数据分片的时候,使用分区可以使查询效率更高。
-------------------------------------------------------------------------------------------------
分桶
在 Hive 中,通过对表中的列运用哈希函数做哈希计算,根据计算出来的哈希值将表或分区细分为多个桶。
而且每个桶的大小几乎一样。以便提高查询效率。
b.分区与分桶创建命令
创建分区语句如下:
CREATE TABLE table_name (
column1 data_type,
column2 data_type
)
PARTITIONED BY (partition1 data_type, partition2 data_type,….);
-------------------------------------------------------------------------------------------------
创建分桶语句如下:
CREATE TABLE table_name (
column1 data_type,
column2 data_type
)
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)] INTO num_buckets BUCKETS;
c.分区与分桶优缺点
a.分区
优点:
Hive 的分区可以水分分散执行压力。
数据查询性能比较好。
不需要在整个表列中搜索单个记录。
---------------------------------------------------------------------------------------------
缺点:
可能会创建太多的小分区,也就是说可能会创建很多目录。
分区对于低容量数据是有效的,但有些查询比如对大的数据量进行分组需要消耗很长时间。
b.分桶
优点:
与非分桶表相比,分桶表提供了高效采样。通过采样,我们可以尝试对一小部分数据进行查询,以便在原始数据集非常庞大时进行测试和调试。
由于数据文件的大小是几乎一样的,map 端的 join 在分桶表上执行的速度会比分区表快很多。在做 map 端 join 时,处理左侧表的 map 知道要匹配的右表的行在相关的桶中,因此只需要检索该桶即可。
分桶表查询速度快于非分桶表。
分桶的还提供了灵活性,可以使每个桶中的记录按一列或多列进行排序。 这使得 map 端 join 更加高效,因为每个桶之间的 join 变为更加高效的合并排序(merge-sort)。
---------------------------------------------------------------------------------------------
缺点:
分桶并不能确保数据加载的恰当性。数据加载到分桶的逻辑需要由我们自己处理。
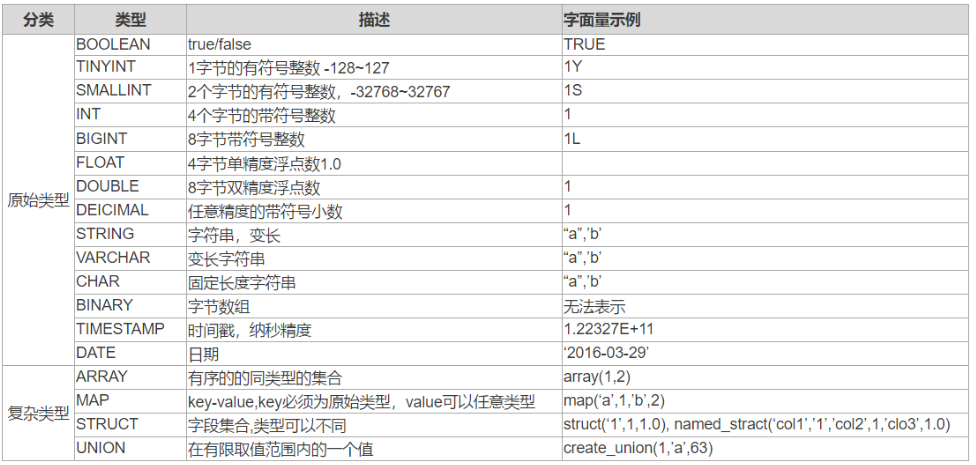
03.数据类型
a.基本类型
整数类型:包括TINYINT、SMALLINT、INT和BIGINT,分别对应Java中的byte、short、int和long。使用整数字面量时,默认是INT,可以通过后缀将其转换为其他类型。
小数类型:包括FLOAT、DOUBLE和DECIMAL。FLOAT和DOUBLE对应Java的float和double,而DECIMAL表示任意精度的小数,通常用于存储货币。
文本类型:包括STRING、VARCHAR和CHAR。STRING用于存储变长文本,VARCHAR类似于STRING但有长度限制,CHAR则是固定长度的文本类型。
布尔和二进制类型:BOOLEAN表示true或false,BINARY用于存储变长的二进制数据。
时间类型:包括TIMESTAMP和DATE,分别用于存储纳秒级的时间戳和日期。
b.类型转换
Hive 的类型层次中,可以根据需要进行隐式的类型转换,例如 TINYINT 与 INT 相加,则会将TINYINT 转化成 INT 然后 INT 做加法。
-----------------------------------------------------------------------------------------------------
隐式转换的规则大致可以归纳如下:
任意数值类型都可以转换成更宽的数据类型(不会导致精度丢失)或者文本类型。
所有的文本类型都可以隐式地转换成另一种文本类型。也可以被转换成 DOUBLE 或者 DECIMAL,转换失败时抛出异常。
BOOLEAN 不能做任何的类型转换。
时间戳和日期可以隐式地转换成文本类型。
-----------------------------------------------------------------------------------------------------
同时,可以使用 CAST 进行显式的类型转换,例如:
CAST('1' as INT)
如果转换失败,CAST 返回 NULL。
c.复杂类型:STRUCT
类似于 C、C# 语言,Hive 中定义的 struct 类型也可以使用点来访问。
从文件加载数据时,文件里的数据分隔符要和建表指定的一致。
-----------------------------------------------------------------------------------------------------
CREATE TABLE IF NOT EXISTS person_1 (id int,info struct<name:string,country:string>)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
STORED AS TEXTFILE;
-----------------------------------------------------------------------------------------------------
//创建一个文本文件test_struct.txt
1,'dd':'jp'
2,'ee':'cn'
3,'gg':'jp'
4,'ff':'cn'
5,'tt':'jp'
-----------------------------------------------------------------------------------------------------
//导入数据
LOAD DATA LOCAL INPATH '/data/test_struct.txt' OVERWRITE INTO TABLE person_1;
-----------------------------------------------------------------------------------------------------
//查询数据
hive> select * from person_1;
OK
1 {"name":"'dd'","country":"'jp'"}
2 {"name":"'ee'","country":"'cn'"}
3 {"name":"'gg'","country":"'jp'"}
4 {"name":"'ff'","country":"'cn'"}
5 {"name":"'tt'","country":"'jp'"}
Time taken: 0.046 seconds, Fetched: 5 row(s)
hive> select id,info.name,info.country from person_1 where info.name='dd';
OK
1 dd jp
Time taken: 1.166 seconds, Fetched: 1 row(s)
d.复杂类型:ARRAY
ARRAY 表示一组相同数据类型的集合,下标从零开始,可以用下标访问。
-----------------------------------------------------------------------------------------------------
CREATE TABLE IF NOT EXISTS array_1 (id int,name array<STRING>)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
STORED AS TEXTFILE;
-----------------------------------------------------------------------------------------------------
//导入数据
LOAD DATA LOCAL INPATH '/data/test_array.txt' OVERWRITE INTO TABLE array_1;
-----------------------------------------------------------------------------------------------------
//查询数据
hive> select * from array_1;
OK
1 ["dd","jp"]
2 ["ee","cn"]
3 ["gg","jp"]
4 ["ff","cn"]
5 ["tt","jp"]
Time taken: 0.041 seconds, Fetched: 5 row(s)
hive> select id,name[0],name[1] from array_1 where name[1]='cn';
OK
2 ee cn
4 ff cn
Time taken: 1.124 seconds, Fetched: 2 row(s)
e.复杂类型:MAP
MAP 是一组键值对的组合,可以通过 KEY 访问 VALUE,键值之间同样要在创建表时指定分隔符。
-----------------------------------------------------------------------------------------------------
CREATE TABLE IF NOT EXISTS map_1 (id int,name map<STRING,STRING>)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
MAP KEYS TERMINATED BY ':'
STORED AS TEXTFILE;
-----------------------------------------------------------------------------------------------------
//加载数据
LOAD DATA LOCAL INPATH '/data/test_map.txt' OVERWRITE INTO TABLE map_1;
-----------------------------------------------------------------------------------------------------
//查询数据
hive> select * from map_1;
OK
1 {"name":"dd","country":"jp"}
2 {"name":"ee","country":"cn"}
3 {"name":"gg","country":"jp"}
4 {"name":"ff","country":"cn"}
5 {"name":"tt","country":"jp"}
Time taken: 0.038 seconds, Fetched: 5 row(s)
select id,info['name'],info['country'] from map_1 where info['country']='cn';
OK
2 ee cn
4 ff cn
Time taken: 1.088 seconds, Fetched: 2 row(s)
f.复杂类型:UINON
Hive 除了支持 STRUCT、ARRAY、MAP 这些原生集合类型,还支持集合的组合,不支持集合里再组合多个集合。
简单示例 MAP 嵌套 ARRAY,手动设置集合格式的数据非常麻烦,建议采用 INSERT INTO SELECT 形式构造数据再插入UNION 表。
-----------------------------------------------------------------------------------------------------
//创建DUAL表,插入一条记录,用于生成数据
create table dual(d string);
insert into dual values('X');
-----------------------------------------------------------------------------------------------------
//创建UNION表
CREATE TABLE IF NOT EXISTS uniontype_1
(
id int,
info map<STRING,array<STRING>>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
STORED AS TEXTFILE;
-----------------------------------------------------------------------------------------------------
//插入数据
insert overwrite table uniontype_1
select 1 as id,map('english',array(99,21,33)) as info from dual
union all
select 2 as id,map('english',array(44,33,76)) as info from dual
union all
select 3 as id,map('english',array(76,88,66)) as info from dual;
-----------------------------------------------------------------------------------------------------
//查询数据
hive> select * from uniontype_1;
OK
3 {"german":[76,88,66]}
2 {"chinese":[44,33,76]}
1 {"english":[99,21,33]}
Time taken: 0.033 seconds, Fetched: 3 row(s)
hive> select * from uniontype_1 where info['english'][2]>30;
OK
1 {"english":[99,21,33]}
Time taken: 1.08 seconds, Fetched: 1 row(s)
04.JSON格式
a.JSON格式读取
a.使用 JSON SerDe 解析 JSON 数据
a.创建 Hive 表
首先,创建一个带有 JSON SerDe 的表。例如,假设你的 JSON 数据格式如下:
{"name": "Alice", "age": 30, "city": "New York"}
---------------------------------------------------------------------------------------------
可以创建 Hive 表如下:
CREATE EXTERNAL TABLE json_table (
name STRING,
age INT,
city STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION '/path/to/json/files';
b.加载 JSON 数据
把 JSON 文件放置在指定的 LOCATION 目录下,Hive 会自动识别和解析这些 JSON 文件
c.查询 JSON 数据
SELECT * FROM json_table;
b.使用 get_json_object() 函数
a.创建原始表
CREATE EXTERNAL TABLE raw_json_table (
json_string STRING
)
LOCATION '/path/to/json/files';
b.解析 JSON 字符串
SELECT
get_json_object(json_string, '$.name') AS name,
get_json_object(json_string, '$.age') AS age,
get_json_object(json_string, '$.city') AS city
FROM raw_json_table;
c.使用 lateral view 与 json_tuple()
a.创建 JSON 表
CREATE EXTERNAL TABLE raw_json_table (
json_string STRING
)
LOCATION '/path/to/json/files';
b.使用 lateral view 解析 JSON
SELECT name, age, city
FROM raw_json_table
LATERAL VIEW json_tuple(json_string, 'name', 'age', 'city') jt AS name, age, city;
d.总结
如果 JSON 数据结构较复杂,推荐使用 JsonSerDe。
如果只需要提取部分字段,可以使用 get_json_object() 函数。
对于简单结构的 JSON 数据,也可以使用 lateral view 和 json_tuple() 方法。
b.JSON格式解析
a.使用 lateral view 和 explode() 解析 JSON 数组
a.假设你的 JSON 数据格式如下
{
"name": "Alice",
"age": 30,
"friends": [
{"name": "Bob", "age": 25},
{"name": "Charlie", "age": 28}
]
}
b.创建包含 JSON 数据的原始表
CREATE EXTERNAL TABLE raw_json_table (
json_string STRING
)
LOCATION '/path/to/json/files';
c.解析 JSON 数组
使用 lateral view 和 explode() 函数,将 JSON 数组展开为多行,然后使用 get_json_object() 或 json_tuple() 提取数组中的字段:
---------------------------------------------------------------------------------------------
SELECT
main.name AS person_name,
main.age AS person_age,
friend_info.name AS friend_name,
friend_info.age AS friend_age
FROM (
SELECT
get_json_object(json_string, '$.name') AS name,
get_json_object(json_string, '$.age') AS age,
get_json_object(json_string, '$.friends') AS friends_json
FROM raw_json_table
) main
LATERAL VIEW explode(split(regexp_replace(main.friends_json, '\\{|\\}', ''), '\\},\\{')) exploded_friends AS friend_json
LATERAL VIEW json_tuple(concat('{', friend_json, '}'), 'name', 'age') friend_info AS name, age;
b.使用 lateral view 和 posexplode() 解析 JSON 数组
a.介绍
如果需要保留数组中元素的顺序,可以使用 posexplode()。该函数不仅能展开数组,还会生成数组索引。
b.假设 JSON 数据格式为:
{
"items": [
{"id": 1, "value": "A"},
{"id": 2, "value": "B"},
{"id": 3, "value": "C"}
]
}
c.创建表存储 JSON 字符串
CREATE EXTERNAL TABLE json_table (
json_data STRING
)
LOCATION '/path/to/json/files';
d.使用 posexplode() 和 json_tuple() 解析 JSON 数组
SELECT
index,
item.id AS item_id,
item.value AS item_value
FROM (
SELECT get_json_object(json_data, '$.items') AS items_json
FROM json_table
) t
LATERAL VIEW posexplode(split(regexp_replace(t.items_json, '\\{|\\}', ''), '\\},\\{')) exploded_items AS index, item_json
LATERAL VIEW json_tuple(concat('{', item_json, '}'), 'id', 'value') item AS id, value;
---------------------------------------------------------------------------------------------
get_json_object() 用于提取 JSON 中的数组部分。
explode() 或 posexplode() 将 JSON 数组字符串分解为多行。
使用 split() 和 regexp_replace() 处理 JSON 字符串,确保每个元素单独成行。
json_tuple() 提取每个 JSON 对象中的具体字段。
05.操作符
a.关系运算符
等值比较 (=): 比较两个表达式是否相等,结果为布尔值 TRUE 或 FALSE。
不等值比较 (<>): 比较两个表达式是否不相等,若不同则返回 TRUE,否则返回 FALSE。
小于比较 (<): 检查左侧表达式是否小于右侧表达式。
小于等于比较 (<=): 检查左侧表达式是否小于或等于右侧表达式。
大于比较 (>): 检查左侧表达式是否大于右侧表达式。
大于等于比较 (>=): 检查左侧表达式是否大于或等于右侧表达式。
空值判断 (IS NULL): 判断表达式是否为 NULL。
非空判断 (IS NOT NULL): 判断表达式是否不为 NULL。
字符串匹配 (LIKE): 用于字符串匹配,支持通配符 _ (任意单个字符) 和 % (任意多个字符)。
正则匹配 (RLIKE 和 REGEXP): 支持使用 Java 正则表达式进行字符串匹配。
b.数学运算符
加法 (+): 两数相加,结果为它们的和。
减法 (-): 两数相减,结果为它们的差。
乘法 (*): 两数相乘,结果为它们的积。
除法 (/): 两数相除,结果为 double 类型。
取余 (%): 计算除法的余数。
位操作: 包括按位与 (&)、按位或 (|)、按位异或 (^)、按位取反 (~) 等。
c.逻辑运算符
逻辑与 (AND): 当两个条件均为 TRUE 时,结果为 TRUE。
逻辑或 (OR): 任意一个条件为 TRUE,结果即为 TRUE。
逻辑非 (NOT): 对布尔表达式取反。
d.数值计算函数
取整函数 (round): 支持四舍五入取整。
向下取整 (floor): 返回不大于输入的最大整数。
向上取整 (ceil 或 ceiling): 返回不小于输入的最小整数。
随机数 (rand): 返回一个 0 到 1 之间的随机数。
指数与对数函数: 包括 exp, ln, log10, log2 和通用的 log 函数。
幂运算 (pow 或 power): 计算一个数的幂。
开平方 (sqrt): 返回一个数的平方根。
进制转换: 包括二进制 (bin), 十六进制 (hex), 反十六进制 (unhex), 进制转换 (conv) 等函数。
绝对值 (abs): 返回一个数的绝对值。
正弦 (sin), 反正弦 (asin), 余弦 (cos), 反余弦 (acos): 常见的三角函数。
e.日期函数
UNIX时间戳转日期 (from_unixtime): 将 UNIX 时间戳转换为日期格式。
获取当前 UNIX 时间戳 (unix_timestamp): 返回当前时间的 UNIX 时间戳。
日期转 UNIX 时间戳: 将日期字符串转换为 UNIX 时间戳。
日期提取: 包括 year, month, day 函数,用于提取日期中的年、月、日。
3.3 环境
01.环境变量
cat /etc/profile
---------------------------------------------------------------------------------------------------------
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export KAFKA_HOME=/usr/local/kafka/kafka-2.1.0
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export SPARK_HOME=/usr/local/spark/spark-2.4.0
export STORM_HOME=/usr/local/storm/apache-storm-1.2.2
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin:$SPARK_HOME/bin:$STORM_HOME/bin
02.hive-site.xml
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value><!-- 元数据存储在本地 -->
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive_metadata?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
-----------------------------------------------------------------------------------------------------
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>false</value>
<description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.</description>
</property>
<property>
</configuration>
03.运行1
a.CLI模式(Command Line Interface):
使用命令行启动Hive的最常见方式。通过输入hive命令可以进入Hive的交互式CLI环境,在该环境中可以执行HiveQL查询。
$ hive
$ exit;
b.Beeline模式:
Beeline是Hive提供的另一种命令行接口,通常用于远程连接HiveServer2。它比传统的CLI模式更轻量、稳定,并且支持多用户并发访问。
beeline -u "jdbc:hive2://<hostname>:<port>/default"
c.HiveServer2模式:
HiveServer2是Hive提供的一个多线程服务器进程,它允许客户端通过JDBC、ODBC等方式访问Hive。可以通过命令hive --service hiveserver2来启动HiveServer2。
hive --service hiveserver2
d.Metastore服务:
Metastore是Hive的元数据存储服务,它负责管理表、数据库等元数据。可以通过hive --service metastore来启动Metastore服务。
hive --service metastore
e.在YARN上运行Hive(运行MapReduce):
Hive作业可以提交到YARN上运行,通常是在分布式集群环境中使用。具体配置和启动方式可以通过Hive的配置文件(如hive-site.xml)来指定。
f.Web接口(如HUE):
一些Hadoop发行版(如Cloudera)提供了基于Web的接口(如HUE),通过这些接口用户可以直接在浏览器中启动和运行Hive查询。
g.说明
ive是hadoop的客户端,同时hive本身也有客户端
hive比较特殊,它既是自己的客户端,又是服务端
启动后窗口不能再操作,需打开一个新的shell窗口做别的操作
04.运行2
a.CLI模式
/usr/local/hive/hive-2.3.4/bin/hive --启动1
/usr/local/hive/hive-2.3.4/bin/hive --service cli --启动2(等同启动1)
只能Shell操作
b.HiveServer2模式
/usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 --启动
/usr/local/hive/hive-2.3.4/bin/beeline -u jdbc:hive2://localhost:10000 --连接10000
192.168.185.150:10000 hive hive --连接10002
c.Metastore服务
/usr/local/hive/hive-2.3.4/bin/hive --service metastore --启动
thrift://192.168.185.150:9083 --连接9083
d.(废)启动hiveWebInterface,通过网页访问hive
/usr/local/hive/hive-2.3.4/bin/hive --service hwi --启动
192.168.185.150:9999 --连接9999
e.(废)使用HCatalog访问hive
/usr/local/hive/hive-2.3.4/bin/hcatalog/bin/hcat --启动
/usr/local/hive/hive-2.3.4/bin/hcatalog/sbin/hcat_server.sh start --启动
/usr/local/hive/hive-2.3.4/bin/hcatalog/sbin/webhcat_server.sh start --启动
05.Metastore的三种配置方式
a.3种配置方式
由于元数据不断地修改、更新,所以 Hive 元数据不适合存储在 HDFS 中,一般存在 RDBMS 中,如 Mysql、Derby。
元数据的存储支持三种不同配置方式:
内嵌配置
本地配置
远程配置
b.内嵌配置
默认情况下,metastore 服务和 Hive 的服务运行在同一个 JVM 中,包含了一个内嵌的以本地磁盘作为存储的Derby
( Hive 自带的数据库)数据库实例。同时,这种配置也被称为内嵌配置。但是这种方式的不好之处就在于每次只有一
个内嵌的 Derby 数据库可以访问某个磁盘上的数据文件,也就是说一次只能为每个 metastore 打开一个 hive 会话。
如果尝试连接多个,会报错。这样效率很低。
c.本地配置
如果要支持多会话,或者多用户的话,需要使用一个独立的数据库(比如 mysql 比较常用),
这种配置方式称为本地 metastore 配置。虽然这种方式 Hvie 服务和 Metastore 服务仍然在一个 JVM 进程中,
但连接的却是另外一个进程中运行的数据库,在同一台机器上或者远程机器上。任何 JDBC 兼容的数据库都可以通过
javax.jdo.option.* 配置属性来供 metastore 使用。
-----------------------------------------------------------------------------------------------------
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>
d.远程配置
还有一种配置是远程 metastore 配置,这种配置情况下,一个或多个 metastore 服务器和 Hive 服务运行在不同的进程中。
这样一来,数据库层可以完全置于防火墙后,客户端则不需要数据库凭证(密码账号),从而提供了更好的可管理性和安全。
可以通过 hive.metastore.uris 设置为 metastore 服务器 URI(如果有多个服务器,可以用逗号分割),
把 hive 服务设为使用远程 metastore 服务器的URI的格式为:thrift://host:port。
-----------------------------------------------------------------------------------------------------
注意,仅连接远程的 mysql 并不能称之为“远程模式”,是否远程指的是 metastore 和 hive 服务是否在同一进程内
-----------------------------------------------------------------------------------------------------
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.214:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.1.188:9083</valu>
</property>
</configuration>
06.额外配置:hive操作hbase
a.背景1
一般在查询hbase的数据的时候我们可以直接使用hbase的命令行或者是api进行查询就行了,
但是在日常的计算过程中我们一般都不是为了查询,都是在查询的基础上进行二次计算,
所以使用hbase的命令是没有办法进行数据计算的,并且对于hbase的压力也会增加很多,
hbase的本身并没有提供任何的计算逻辑,所以我们要依赖于mapreducer进行计算,
这个代码上面我们已经实现过了,但是后续开发过程中很少有人会直接开发mr程序,
这个代码的复杂程度比较高,并且会非常大的拖慢我们的开发速度,
所以一般我们都会使用hive以外表的形式操作hbase中的数据,
进行多表的管理查询计算或者是进行数据的导入和导出
b.背景2
这两个文件 FcMeasureKafka2hdfs.java 和 FcMeasureKafka2hbase.java 的主要目的是从 Kafka 中接收数据,并将其分别写入 HDFS 和 HBase。这种设计通常是为了满足不同的数据存储和处理需求,具体原因如下:
数据存储需求:HDFS:适合存储大规模的、批量的数据,通常用于后续的分析和处理。HDFS 提供高吞吐量的数据访问,适合大数据处理场景。
HBase:适合实时读写操作,能够快速查询特定数据。HBase 是一个 NoSQL 数据库,适合需要快速随机访问的场景。
数据处理需求:通过将数据同时写入 HDFS 和 HBase,可以实现数据的多样化处理。例如,HDFS 中的数据可以用于离线分析,而 HBase 中的数据可以用于实时查询和监控。
系统架构设计:这种设计可以提高系统的灵活性和可扩展性。不同的应用可以根据需要选择从 HDFS 或 HBase 中读取数据,满足不同的业务需求。
数据冗余和备份:同时将数据写入两个存储系统可以作为一种冗余机制,确保数据的安全性和可用性。
总之,这种设计使得系统能够更好地适应不同的使用场景和需求,提供更高的灵活性和效率。
c.背景3
Hive中建表时,数据的存储位置主要取决于表的类型和存储格式,通常不会默认存储到HBase中
a.默认存储(HDFS)
在 Hive 中,最常见的数据存储方式是使用 HDFS(Hadoop Distributed File System)。
当你在 Hive 中创建一张表时,如果没有特别指定存储格式或存储位置,数据会存储在 HDFS 上的一个目录中。
Hive 的默认存储格式是 TextFile,但也支持其他格式如 ORC、Parquet、Avro 等。
b.HBase
Hive 可以与 HBase 集成,将表的数据存储在 HBase 中,但这需要在建表时显式指定。
例如,你可以使用类似 STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' 的语句
来告诉 Hive 使用 HBase 作为存储后端。这种方式适用于需要快速随机访问的数据场景。
c.其他外部存储:
Hive 还支持通过外部表的方式读取和写入其他数据源,比如 Amazon S3、关系型数据库(如 MySQL、PostgreSQL)、
NoSQL 数据库等。你需要通过 Hive 的存储处理器(Storage Handlers)或连接器来实现与这些外部数据源的集成。
d./usr/local/hive/hive-3.1.3/conf/hive-site.xml
<property>
<name>hive.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
e./usr/local/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
-----------------------------------------------------------------------------------------------------
scp /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml root@192.168.185.151:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml
scp /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml root@192.168.185.152:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml
07.额外配置:hive开启事务支持行级insert、update、delete、insert overwrite、mergee into
a.启用ACID特性
/usr/local/hive/hive-3.1.3/conf/hive-site.xml
-----------------------------------------------------------------------------------------------------
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
b.添加Hive元数据(使用mysql存储)
use hive_metadata;
INSERT INTO NEXT_LOCK_ID VALUES(1);
INSERT INTO NEXT_COMPACTION_QUEUE_ID VALUES(1);
INSERT INTO NEXT_TXN_ID VALUES(1);
COMMIT;
quit;
-----------------------------------------------------------------------------------------------------
说明:初始时这三个表没有数据,如果不添加数据,会报以下错误:
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager FAILED: Error in acquiring locks: Error communicating with the metastore
c.创建事务表:创建支持事务的表时,需要使用TBLPROPERTIES设置为事务表
CREATE TABLE student (
id INT,
name STRING,
age INT
)
STORED AS ORC
TBLPROPERTIES ('transactional'='true');
4 hbase
4.1 概念
01.简介
HBase 是一个开源的、分布式的、面向列的数据库,基于 Google 的 Bigtable 论文实现。
它提供了高可靠性、高性能、列式存储、分布式的扩展性和实时查询能力,适用于处理大数据集。
---------------------------------------------------------------------------------------------------------
HBase是建立在Hadoop文件系统之上的面向列的分布式数据库。这是一个开源项目,可横向扩展。
HBase是一种类似于Google BigTable的数据模型,旨在提供对大量结构化数据的快速随机访问。它利用了Hadoop文件系统(HDFS)提供的容错能力。
它是Hadoop生态系统的一部分,可提供对Hadoop File System中数据的随机实时读写访问。
可以直接或通过HBase将数据存储在HDFS中。数据使用者使用HBase随机读取/访问HDFS中的数据。HBase位于Hadoop File System的顶部,并提供读写访问权限。
02.应用场景
日志和事件数据存储:HBase 可以存储和检索大规模的日志和事件数据,适用于实时分析和监控系统。
实时数据分析:HBase 支持快速的随机读写操作,适用于需要实时数据分析的应用。
大数据平台:作为 Hadoop 生态系统的一部分,HBase 可以与其他大数据工具(如 Hadoop、Spark、Hive 等)无缝集成。
用户数据存储:HBase 可以用于存储海量的用户数据,适用于社交网络、电商平台等应用。
03.解决问题
a.大规模数据存储
水平扩展:HBase 可以通过增加 RegionServer 来水平扩展,支持存储海量数据。
高效存储:通过列式存储和数据压缩,HBase 可以高效地存储大规模数据。
b.快速随机读写访问
低延迟读写:HBase 支持毫秒级的随机读写访问,适用于对响应时间要求较高的应用场景。
实时写入:数据写入首先存储在内存中的 MemStore,随后异步写入 HFile,这使得写入操作非常高效。
c.数据可靠性
数据可靠性:通过 WAL 记录写操作日志,确保数据在写入过程中不丢失。
高可用性:通过 Zookeeper 协调来实现集群的高可用性和分布式一致性。
d.数据版本管理
数据版本:HBase 支持为每个单元格存储多个版本的数据,通过时间戳来标识版本。这使得数据的历史版本管理变得非常简单。
e.灵活的列式数据模型
面向列的存储模型:HBase 的列式存储模型使得数据模型设计非常灵活,可以根据需求动态增加列。
04.局限性
Hadoop只能执行批处理,并且只能按顺序访问数据。这意味着即使是最简单的工作,也必须搜索整个数据集。
处理后的庞大数据集会产生另一个庞大的数据集,这些数据集也应按顺序进行处理。
此时,需要一种新的解决方案来在单个时间单位内访问任何数据点(随机访问)。
05.随机访问数据库
HBase,Cassandra,couchDB,Dynamo和MongoDB等应用程序是一些存储大量数据并以随机方式访问数据的数据库。
06.存储机制
HBase是一个面向列的数据库,其中的表按行排序。表模式仅定义列族,它们是键值对。
一个表具有多个列族,每个列族可以具有任意数量的列。随后的列值连续存储在磁盘上。
该表的每个单元格值都有一个时间戳。
---------------------------------------------------------------------------------------------------------
在HBase中:
表是行的集合。
行是列族的集合。
列族是列的集合。
列是键值对的集合。
07.列导向和行导向
面向列的数据库是将数据表存储为数据列的一部分而不是数据行的数据库。很快,他们将拥有列族。
---------------------------------------------------------------------------------------------------------
面向行的数据库 列式数据库
它适用于在线事务处理(OLTP) 它适用于在线分析处理(OLAP)
此类数据库设计用于少量的行和列 面向列的数据库是为大型表设计的
08.功能
HBase是线性可伸缩的
它具有自动故障支持
它提供一致的读取和写入
它与Hadoop集成,既作为源也作为目标
它具有简单的客户端Java API
它提供跨集群的数据复制
09.应用
它在需要编写繁重的应用程序时使用
每当我们需要提供对可用数据的快速随机访问时,都会使用HBase
Facebook,Twitter,Yahoo和Adobe等公司在内部使用HBase
10.在哪里使用HBase
Apache HBase用于对大数据进行随机,实时的读写访问。
它在商用硬件集群的顶部托管着很大的表。
Apache HBase是根据Google的Bigtable建模的非关系数据库。Bigtable在Google File System上起作用,Apache HBase同样在Hadoop和HDFS之上工作。
11.附:HBase和HDFS
HDFS HBase
HDFS是适用于存储大文件的分布式文件系统 HBase是建立在HDFS之上的数据库
HDFS不支持快速的单个记录查找 HBase为大型表提供快速查找
它提供高延迟的批处理;没有批处理的概念 它提供了数十亿条记录对单行的低延迟访问(随机访问)
它仅提供数据的顺序访问 HBase在内部使用哈希表并提供随机访问,并且将数据存储在索引的HDFS文件中,以加快查找速度
12.附:HBase和RDBMS
HBase 关系数据库管理系统(RDBMS)
HBase是无架构的,它没有固定列架构的概念;仅定义列族 RDBMS由其架构控制,该架构描述表的整个结构
它是为宽表而设计的,HBase是水平可伸缩的 它很薄,专为小表而建。难以扩展
HBase中没有事务 RDBMS是事务性的
它具有非规范化的数据 它将具有标准化的数据
对于半结构化数据和结构化数据都非常有用 这对结构化数据很有用
4.2 组件
00.说明
在HBase中,表被分成区域,并由区域服务器提供服务。区域按列族垂直划分为“Stores”。Stores以文件形式保存在HDFS中
HBase具有三个主要组件:客户端库,主服务器和区域服务器。可以根据需要添加或删除区域服务器
01.主服务器(master)
将区域分配给区域服务器,并利用Apache ZooKeeper的帮助完成此任务。
处理跨区域服务器的区域负载平衡。它卸载繁忙的服务器,并将区域转移到占用较少的服务器。
通过调度负载均衡来维护集群的状态。
负责架构更改和其他元数据操作,例如创建表和列系列。
02.区域服务器(regions)
区域不过是分散在区域服务器中并分散在各个区域服务器中的表。它有以下几个作用:
与客户端通信并处理与数据相关的操作。
处理其下所有区域的读写请求。
通过遵循区域大小阈值来确定区域的大小。
---------------------------------------------------------------------------------------------------------
Store包含Memstore和HFiles。Memstore就像一个缓存。最初输入到HBase的所有内容都存储在此处。
以后,数据将作为块传输并保存在Hfiles中,并且刷新了存储器。
03.Zookeeper
Zookeeper 是一个开源项目,提供诸如维护配置信息,命名,提供分布式同步等服务。
Zookeeper具有代表不同区域服务器的临时节点。主服务器使用这些节点发现可用的服务器。
除了可用性,这些节点还用于跟踪服务器故障或网络分区。
客户端通过zookeeper与区域服务器通信。
在模拟和独立模式,HBase由zookeeper来管理。
4.3 环境
01.安装
a.节点
主备HMaster: 为了保证HBase的高可用性,HBase通常会配置多个HMaster(一个主HMaster和多个备HMaster)。如果主HMaster发生故障,备HMaster会自动接管。
RegionServer的分布式架构: HRegionServer通常是分布式部署的,多个RegionServer同时运行,以实现数据的高可用性和负载均衡。
b.启动
/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh --启动
http://192.168.185.150:16010
http://192.168.185.151:16010
http://192.168.185.152:16010
c.查看
# jps --查看节点信息
# 正确结果:主节点上显示:HMaster / 子节点上显示:HRegionServer
02.thrift连接
a.问题1
登录HBase master机器,执行以下命令启动thrift2:hbase-daemon.sh start thrift2。
thrift默认的监听端口是9090,可以通过参数“-p”指定其它端口。默认使用的Server是TThreadPoolServer。默认使用的Protocol是TBinaryProtocol。
注意客户端使用的Protocol和Transport和服务端的要保持一致,否则客户端在调用时,可能遇到“EAGAIN (timed out)”等错误。
b.问题2
thrift默认的监听端口是9090
c.问题3
在ZooKeeper集群中,以下是需要放行的端口:
ZooKeeper客户端连接ZooKeeper服务器的端口,默认为2181(TCP)
ZooKeeper服务器之间的通信端口,默认为2888(TCP),用于服务器之间的互相通信
用于Leader选举的端口,默认为3888(TCP)
d.问题4
HBase集群内的不同组件之间需要进行通信,因此需要放行一些端口,具体如下:
HMaster和HRegionServer之间的通信:默认使用60000端口。
HBase客户端和HBase集群之间的通信:默认使用2181端口的ZooKeeper端口。
HBase的Web界面:默认使用16010端口。
HBase的Thrift服务:默认使用9090端口。
e.问题5
如果你启用了HBase的Kerberos安全认证,还需要放行以下端口:
88端口:Kerberos认证服务端口。
749端口:Kerberos管理服务端口。
464端口:Kerberos密码改变服务端口。
03.常见问题
a.hue
连接hbase HTTPConnectionPool(host='192.168.185.150', port=9090)
Api Error: HTTPConnectionPool(host='192.168.185.150', port=9090): Max retries exceeded with url: /
(Caused by NewConnectionError(': Failed to establish a new connection: [Errno 111] Connection refused',))
b.HBase Assistant
Thrift.TApplicationException: Invalid method name: 'getThriftServerType'
at Hbase.Thrift2.THBaseService.Client.recv_getThriftServerType(CancellationToken cancellationToken)
at Hbase.Thrift2.THBaseService.Client.getThriftServerType(CancellationToken cancellationToken)
at HBaseClient.ThriftClient.GetThriftServerType()
at HBaseAssistant.ViewModels.ConnectionViewModel.OpenConnection()
c.phoenix
Could not load/instantiate class org.apache.phoenix.query.DefaultGuidePostsCacheFactory
5 附:2.x系列
01.快速开始
a.开启权限,追加内容到rc.local
chmod 777 /tmp
chmod +x /etc/rc.d/rc.local
hdfs dfs -chmod 777 /tmp
hadoop fs -chmod -R 777 /tmp/hadoop-yarn
hadoop fs -chmod -R 777 /workspace
-----------------------------------------------------------------------------------------------------
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
unset HADOOP_CLIENT_OPTS
-----------------------------------------------------------------------------------------------------
start-hadoop-cluster
start-hive-metastore
start-hive-server
start-zookeeper-cluster && status-zookeeper-cluster
start-hbase-cluster
--------------------------------------------------
start-kafka-cluster
start-spark
start-flink
start-flume
start-kafka-ui
start-hue
start-oozie
-----------------------------------------------------------------------------------------------------
stop-hadoop-cluster
stop-hive-cluster
stop-zookeeper-cluster
stop-hbase-cluster
--------------------------------------------------
stop-kafka-cluster
stop-spark
stop-flink
stop-flume
stop-kafka-ui
stop-hue
stop-oozie
-----------------------------------------------------------------------------------------------------
status-bigdata-all
status-zookeeper-cluster
-----------------------------------------------------------------------------------------------------
sqlline.py master:2181
sqlline.py master,slave1,slave2:2181
b.master
start-dfs && start-yarn && start-jobhistory && hdfs dfsadmin -safemode leave
start-hadoop-cluster
-----------------------------------------------------
start-hive-metastore
start-hive-server
-----------------------------------------------------
start-zookeeper
start-zookeeper-cluster
-----------------------------------------------------
start-hbase-basic && start-hbase-thrift && start-hbase-rest
start-hbase-cluster
-----------------------------------------------------
start-kafka
start-kafka-cluster
-----------------------------------------------------
start-spark
start-flink
start-flume
-----------------------------------------------------
start-kafka-ui
start-hue
start-oozie
-----------------------------------------------------------------------------------------------------
stop-dfs && stop-yarn && stop-jobhistory
stop-hadoop-cluster
-----------------------------------------------------
stop-hive-cluster
-----------------------------------------------------
stop-zookeeper
stop-zookeeper-cluster
-----------------------------------------------------
stop-hbase-basic && stop-hbase-thrift && stop-hbase-rest
stop-hbase
stop-hbase-cluster
-----------------------------------------------------
stop-kafka
stop-kafka-cluster
-----------------------------------------------------
stop-spark
stop-flink
stop-flume
-----------------------------------------------------
stop-kafka-ui
stop-hue
stop-oozie
c.slave
start-zookeeper
start-hbase && start-hbase-thrift && start-hbase-rest
start-kafka
-----------------------------------------------------------------------------------------------------
stop-zookeeper
stop-hbase && stop-hbase-thrift && stop-hbase-rest
stop-kafka
d.master
Hadoop(master启动后,slave会自动启动) /usr/local/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
Hadoop(master启动后,slave会自动启动) /usr/local/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
Hadoop(master启动后,slave会自动启动) /usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver
Hive1(仅有master节点存在) nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore &
Hive2(仅有master节点存在) nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 &
ZooKeeper(master、slave1、slave2依次启动) /usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start
Hbase-basic(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh
Hbase-thrift1(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start thrift --infoport 9095 -p 9090
Hbase-thrift2(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start thrift2 --infoport 9095 -p 9090
Hbase-rest(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start rest
-----------------------------------------------------------------------------------------------------
Kafka(master、slave1、slave2依次启动) /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
Spark(master启动后,slave会自动启动) /usr/local/spark/spark-2.4.0/sbin/start-all.sh
Flink(master启动后,slave会自动启动) /usr/local/flink/flink-1.18.1/bin/start-cluster.sh
Flume(仅有master节点存在) sh /usr/local/flume/flume-1.8.0/bin/flume.sh start
-----------------------------------------------------------------------------------------------------
kafka-ui(仅有master节点存在) cd /usr/local/kafka-console-ui && sh bin/start.sh
Hue(仅有master节点存在) nohup /usr/local/hue/build/env/bin/supervisor >> /usr/local/hue/logs/hue.log 2>&1 &
Oozie(仅有master节点存在) /usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh start
e.slave1、slave2
ZooKeeper(master、slave1、slave2依次启动) /usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start
Hbase(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh
Hbase-thrift(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start thrift
Hbase-rest(master、slave1、slave2依次启动) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start rest
-----------------------------------------------------------------------------------------------------
Kafka(master、slave1、slave2依次启动) /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
f.停止
Hadoop(master停止后,slave会自动停止) /usr/local/hadoop/hadoop-2.7.7/sbin/stop-dfs.sh
Hadoop(master停止后,slave会自动停止) /usr/local/hadoop/hadoop-2.7.7/sbin/stop-yarn.sh
Hadoop(master停止后,slave会自动停止) /usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh stop historyserver
Hive(仅有master节点存在) jps | grep RunJar | awk '{print $1}' | xargs -r kill -9
ZooKeeper(master、slave1、slave2依次停止) /usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh stop
Hbase-basic(master、slave1、slave2依次停止) /usr/local/hbase/hbase-2.1.1/bin/stop-hbase.sh
Hbase-thrift1(master、slave1、slave2依次停止) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop thrift --infoport 9095 -p 9090
Hbase-thrift2(master、slave1、slave2依次停止) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop thrift2 --infoport 9095 -p 9090
Hbase-rest(master、slave1、slave2依次停止) /usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop rest
-----------------------------------------------------------------------------------------------------
Kafka(master、slave1、slave2依次停止) /usr/local/kafka/kafka-2.1.0/bin/kafka-server-stop.sh
Spark(master启动后,slave会自动停止) /usr/local/spark/spark-2.4.0/sbin/stop-all.sh
Flink(master启动后,slave会自动停止) /usr/local/flink/flink-1.18.1/bin/stop-cluster.sh
Flume(仅有master节点存在) sh /usr/local/flume/flume-1.8.0/bin/flume.sh stop
-----------------------------------------------------------------------------------------------------
kafka-ui(仅有master节点存在) cd /usr/local/kafka-console-ui && sh bin/shutdown.sh
Hue(仅有master节点存在) ps -ef | grep hue | grep -v grep | awk '{print $2}' | xargs kill -9
Oozie(仅有master节点存在) /usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh stop
g.配置别名
环境变量 /etc/profile source /etc/profile
自定义命令 ~/.bashrc source ~/.bashrc
自定义shell
拷贝软链接到bin
-----------------------------------------------------------------------------------------------------
vi ~/.bashrc --追加内容
-----------------------------------------------------------------------------------------------------
alias start-dfs='/usr/local/hadoop/hadoop-2.7.7/sbin/start-dfs.sh'
alias start-yarn='/usr/local/hadoop/hadoop-2.7.7/sbin/start-yarn.sh'
alias start-jobhistory='/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver'
alias start-hadoop-cluster='start-dfs && start-yarn && hdfs dfsadmin -safemode leave'
alias start-hive-metastore="nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 &"
alias start-hive-server="nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1 &"
alias start-zookeeper='/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start'
alias start-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.4.10/bin/zookeeper-cluster.sh start'
alias start-hbase-basic='/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh'
alias start-hbase-thrift1="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start thrift --infoport 9095 -p 9090"
alias start-hbase-thrift2="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start thrift2 --infoport 9095 -p 9090"
alias start-hbase-rest="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh start rest"
alias start-hbase-cluster='start-hbase-basic && start-hbase-thrift1 && start-hbase-rest'
alias start-kafka='/usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties'
alias start-kafka-cluster='/usr/local/kafka/kafka-2.1.0/bin//kafka-cluster.sh start'
alias start-spark='/usr/local/spark/spark-2.4.0/sbin/start-all.sh'
alias start-flink='/usr/local/flink/flink-1.18.1/bin/start-cluster.sh'
alias start-flume='sh /usr/local/flume/flume-1.8.0/bin/flume.sh start'
alias start-kafka-ui="cd /usr/local/kafka-console-ui && sh bin/start.sh"
alias start-hue="nohup /usr/local/hue/build/env/bin/supervisor >> /usr/local/hue/logs/hue.log 2>&1 &"
alias start-oozie="/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh start"
alias stop-dfs='/usr/local/hadoop/hadoop-2.7.7/sbin/stop-dfs.sh'
alias stop-yarn='/usr/local/hadoop/hadoop-2.7.7/sbin/stop-yarn.sh'
alias stop-jobhistory='/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh stop historyserver'
alias stop-hadoop-cluster='stop-dfs && stop-yarn && stop-jobhistory'
alias stop-hive-cluster="jps | grep RunJar | awk '{print $1}' | xargs -r kill -9"
alias stop-zookeeper='/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh stop'
alias stop-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.4.10/bin/zookeeper-cluster.sh stop'
alias stop-hbase-basic='/usr/local/hbase/hbase-2.1.1/bin/stop-hbase.sh'
alias stop-hbase-thrift1="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop thrift --infoport 9095 -p 9090"
alias stop-hbase-thrift2="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop thrift2 --infoport 9095 -p 9090"
alias stop-hbase-rest="/usr/local/hbase/hbase-2.1.1/bin/hbase-daemons.sh stop rest"
alias stop-hbase-cluster='stop-hbase-basic && stop-hbase-thrift1 && stop-hbase-rest'
alias stop-kafka='/usr/local/kafka/kafka-2.1.0/bin/kafka-server-stop.sh'
alias stop-kafka-cluster='/usr/local/kafka/kafka-2.1.0/bin//kafka-cluster.sh stop'
alias stop-spark='/usr/local/spark/spark-2.4.0/sbin/stop-all.sh'
alias stop-flink='/usr/local/flink/flink-1.18.1/bin/stop-cluster.sh'
alias stop-flume='sh /usr/local/flume/flume-1.8.0/bin/flume.sh stop'
alias stop-kafka-ui="cd /usr/local/kafka-console-ui && sh bin/shutdown.sh"
alias stop-hue="ps -ef | grep hue | grep -v grep | awk '{print $2}' | xargs kill -9"
alias stop-oozie="/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh stop"
alias status-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.4.10/bin/zookeeper-cluster.sh status'
alias start-bigdata1="/usr/local/troyekk/start-bigdata1.sh"
alias start-bigdata2="/usr/local/troyekk/start-bigdata2.sh"
alias start-bigdata-all="/usr/local/troyekk/start-bigdata-all.sh"
alias stop-bigdata1="/usr/local/troyekk/stop-bigdata1.sh"
alias stop-bigdata2="/usr/local/troyekk/stop-bigdata2.sh"
alias stop-bigdata-all="/usr/local/troyekk/stop-bigdata-all.sh"
alias status-bigdata-all="/usr/local/troyekk/status-bigdata-all.sh"
-----------------------------------------------------------------------------------------------------
source ~/.bashrc
scp /root/.bashrc root@192.168.185.151:/root/.bashrc && ssh root@192.168.185.151 "source ~/.bashrc"
scp /root/.bashrc root@192.168.185.152:/root/.bashrc && ssh root@192.168.185.152 "source ~/.bashrc"
h.启动情况
[root@master ~]# jps
1424 NameNode --Hadoop
1279 DataNode --Hadoop
1385 NodeManager --Hadoop
1774 ResourceManager --Hadoop
1477 SecondaryNameNode --Hadoop
---------------------------------------------------------------------------
2113 QuorumPeerMain --ZooKeeper
---------------------------------------------------------------------------
2148 Kafka --Kafka
---------------------------------------------------------------------------
2502 Application --Flume
---------------------------------------------------------------------------
2503 RunJar --Hive(正常情况会出现两个RunJar)
---------------------------------------------------------------------------
主节点上显示:HMaster / 子节点上显示:HRegionServer --Hbase
主节点上显示:ThriftServer --Hbase thrift
主节点上显示:RESTServer --Hbase rest
---------------------------------------------------------------------------
正确结果:显示:Master、Worker --Spark
---------------------------------------------------------------------------
正确结果:显示:TaskManagerRunner --Flink
-----------------------------------------------------------------------------------------------------
正确结果:显示:Bootstrap --Oozie
正确结果:显示:SqlLine --Phoenix
-------------------------------------------------------------------------------------------------
[root@master ~]# ps aux | grep kafka
root 2819 0.0 0.0 112660 972 pts/1 R+ 17:55 0:00 grep --color=auto kafka
[root@master ~]# jps kill 1424 --停止NameNode
i.访问
hive(1.master启动hadoop,然后slave1启动hadoop)
hbase(启动Hbase之前,zookeeper和hadoop需要提前启动起来)
kafka(启动Hbase之前,zookeeper三台都需要提前启动起来)
storm(启动Storm之前,zookeeper三台都需要提前启动起来)
-------------------------------------------------------------------------------------------------
http://192.168.185.150:50070 --hdfs
http://192.168.185.150:8088 --yarn -> Tools -> Localogs
http://192.168.185.150:19888 --jobhistory -> Tools -> Localogs
http://192.168.185.150:16010 --hbase
http://192.168.185.150:8085 --hbase(restserver)
http://192.168.185.150:8086 --spark(集群的整体信息和状态)
http://192.168.185.150:8087 --spark(应用程序的详细信息)
http://192.168.185.150:8089 --flink
http://192.168.185.150:8000/hue --hue(root、123456)
http://192.168.185.150:7766 --kafka
02.环境配置
a.网络
a.win10
IP地址 192.168.185.1
子网掩码 255.255.255.0
默认网关 192.168.185.2
b.vmware
子网IP 192.168.185.0
子网掩码 255.255.255.0
网关IP 192.168.185.2
范围IP 192.168.185.128 ~ 192.168.185.254
c.host
C:\Windows\System32\drivers\etc\hosts
192.168.185.150 master
192.168.185.151 slave1
192.168.185.152 slave2
192.168.185.153 slave3
d.测试
ping 192.168.185.150
ping 192.168.185.151
ping 192.168.185.152
ping 192.168.185.153
ssh root@192.168.185.150 --免密钥访问
e.登录
root
123456
建议每个节点别低于1G内存,默认分配2G
b.Hadoop(hdfs+mapreduce)
/usr/local/hadoop/hadoop-2.7.7/sbin/start-dfs.sh --启动hdfs
/usr/local/hadoop/hadoop-2.7.7/sbin/start-yarn.sh --启动mapreduce
/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver --启动jobhistory
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/sbin/yarn-daemon.sh start resourcemanager --单独启动yarn
/usr/local/hadoop/hadoop-2.7.7/sbin/hadoop-daemon.sh start datanode --单独启动datanode
/usr/local/hadoop/hadoop-2.7.7/sbin/hadoop-daemon.sh start namenode --单独启动namenode
-----------------------------------------------------------------------------------------------------
http://192.168.185.150:50070/dfshealth.html --界面(hdfs)
http://192.168.185.150:8088/cluster --界面(yarn)
http://192.168.185.150:19888 --界面(jobhistory)
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
1968 ResourceManager
1591 NameNode
2522 Jps
1787 SecondaryNameNode
-----------------------------------------------------------------------------------------------------
jps | grep NodeManager
jps | grep SecondaryNameNode
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/bin/hdfs dfsadmin -report --hdfs状态
/usr/local/hadoop/hadoop-2.7.7/bin/yarn application -list --yarn状态(列出所有正在运行的应用程序)
/usr/local/hadoop/hadoop-2.7.7/bin/yarn node -list --yarn状态(列出所有YARN节点)
-----------------------------------------------------------------------------------------------------
org.apache.hadoop.security.AccessControlException --权限问题(关闭hdfs验证)
/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml --追加内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml --追加内容
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
c.Hive
mysql --进入mysql
create database if not exists hive_metadata;
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
flush privileges;
use hive_metadata;
exit
schematool -dbType mysql -initSchema --初始化
-----------------------------------------------------------------------------------------------------
mysql -u root
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY ''; --允许root用户远程连接
FLUSH PRIVILEGES;
-----------------------------------------------------------------------------------------------------
/usr/local/hive/hive-2.3.4/bin/hive --进入hive
-----------------------------------------------------------------------------------------------------
jdbc:hive2://192.168.185.150:10000
192.168.185.150
10000
hive
hive
-----------------------------------------------------------------------------------------------------
/usr/local/hive/hive-2.3.4/conf/hive-site.xml --修改内容
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
d.ZooKeeper
cd
/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start --启动zookeeper
-----------------------------------------------------------------------------------------------------
bin/zkCli.sh
ls /
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
2555 QuorumPeerMain
-----------------------------------------------------------------------------------------------------
192.168.185.150
2181
e.Kafka
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties &
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties > /usr/local/kafka/kafka-2.1.0/logs/kafka.log 2>&1 &
-----------------------------------------------------------------------------------------------------
kafka-server-start.sh kafka启动程序
kafka-server-stop.sh kafka停止程序
kafka-topics.sh 创建topic程序
kafka-console-producer.sh 命令行模拟生产者生产消息数据程序
kafka-console-consumer.sh 命令行模拟消费者消费消息数据程序
-----------------------------------------------------------------------------------------------------
# ps aux | grep kafka --查看进程
root 2966 0.0 0.0 112660 972 pts/0 R+ 16:43 0:00 grep --color=auto kafka
f.Flume
nohup /usr/local/flume/flume-1.8.0/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/flume-1.8.0/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console &
-----------------------------------------------------------------------------------------------------
# ps aux | grep flume --查看进程
root 3368 0.0 0.0 112660 972 pts/0 R+ 16:50 0:00 grep --color=auto flume
g.Hbase
/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh --启动
netstat -lnpt | grep 8080
http://192.168.185.150:16010
http://192.168.185.151:16010
http://192.168.185.152:16010
-----------------------------------------------------------------------------------------------------
主备HMaster: 为了保证HBase的高可用性,HBase通常会配置多个HMaster(一个主HMaster和多个备HMaster)。如果主HMaster发生故障,备HMaster会自动接管。
RegionServer的分布式架构: HRegionServer通常是分布式部署的,多个RegionServer同时运行,以实现数据的高可用性和负载均衡。
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:主节点上显示:HMaster / 子节点上显示:HRegionServer
-----------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
报错:
[root@master sqoop]# hbase version
Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
解决:
vi /usr/local/hbase/hbase-2.1.1/bin/hbase 修改如下内容
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/usr/local/hbase/hbase-2.1.1/lib/*
h.Spark
/usr/local/spark/spark-2.4.0/sbin/start-all.sh --启动
-----------------------------------------------------------------------------------------------------
vi /usr/local/spark/spark-2.4.0/conf/spark-env.sh --追加内容
export SPARK_MASTER_WEBUI_PORT=8086
export SPARK_WORKER_WEBUI_PORT=8087
-----------------------------------------------------------------------------------------------------
http://192.168.185.150:8086 --spark(集群的整体信息和状态)
http://192.168.185.150:8087 --spark(应用程序的详细信息)
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:Master、Worker
i.Storm(先启动Zookeeper,三台都启动)
master(启动Nimbus和UI) /usr/local/storm/apache-storm-1.2.2/bin/storm nimbus >/usr/local/storm/apache-storm-1.2.2/logs/nimbus.out 2>&1 &
master(启动Nimbus和UI) /usr/local/storm/apache-storm-1.2.2/bin/storm ui >/usr/local/storm/apache-storm-1.2.2/logs/ui.out 2>&1 &
-----------------------------------------------------------------------------------------------------
slave1(启动Supervisor) /usr/local/storm/apache-storm-1.2.2/bin/storm supervisor >/usr/local/storm/apache-storm-1.2.2/logs/supervisor.out 2>&1 &
slave2(启动Supervisor) /usr/local/storm/apache-storm-1.2.2/bin/storm supervisor >/usr/local/storm/apache-storm-1.2.2/logs/supervisor.out 2>&1 &
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:Nimbus、Supervisor
j.Flink
a.解压
cd /usr/local/flink
tar -xzf flink-1.18.1-bin-scala_2.12.tgz
b.配置集群
a.进入conf目录,修改flink-conf.yaml
cd /usr/flink/flink-1.18.0/conf/
vi flink-conf.yaml
# 部署Spark或Azkaban等应用,启动flink时发现默认端口8081被占用,于是得去更改默认端口
rest.port: 8089
# JobManager 节点地址
jobmanager.rpc.address: 192.168.185.150
jobmanager.bind-host: 0.0.0.0
rest.address: 192.168.185.150
rest.bind-address: 0.0.0.0
# Taskmanager节点地址,需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: 192.168.185.150
b.进入conf目录,修改workers
vi workers
192.168.185.150
192.168.185.151
192.168.185.152
c.进入conf目录,修改masters
vi masters
192.168.58.130:8081
d.将以上配置向集群其他节点同步,仅需要修改flink-conf.yaml中的taskmanager.host地址即可,修改为当前节点的IP地址
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.151:/usr/local/flink
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.152:/usr/local/flink
c.启动、停止、访问
/usr/local/flink/flink-1.18.1/bin/start-cluster.sh
/usr/local/flink/flink-1.18.1/bin/stop-cluster.sh
http://192.168.185.150:8089
-------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:TaskManagerRunner
03.基础环境
a.jdk
/usr/local/java/jdk1.8.0_191/
-----------------------------------------------------------------------------------------------------
cat /etc/profile
java -version
b.mysql
a.配置文件
主配置文件:/etc/my.cnf
包含配置片段的目录:/etc/my.cnf.d/
b.MySQL 数据库文件
默认数据目录:/var/lib/mysql/
MySQL 数据库和表的存储位置。
c.MySQL 日志文件
默认错误日志:/var/log/mysqld.log
其他日志(如慢查询日志)可以通过配置文件指定路径。
d.二进制文件
MySQL 服务启动脚本:/usr/lib/systemd/system/mysqld.service
可执行文件:/usr/bin/,如 mysql, mysqld, mysqladmin 等。
e.库文件
库文件路径:/usr/lib64/mysql/
f.其他重要文件
初始化脚本(如果有):/usr/bin/mysql_install_db
g.启动
[root@master ~]# mysql
[root@master ~]# mysql -u root
Server version: 5.6.42 MySQL Community Server (GPL)
mysql>
c.其他
MySQL
Redis
MongoDB
Maven
Kettle
Anaconda
Python(beautifulsoup4、pymysql、scrapy、kafka-python、numpy、pandas、matplotlib、seaborn)
04.常见端口
a.HDFS
a.NameNode
a.HTTP Web UI: 50070 或 9870(取决于 Hadoop 版本和配置)
用于访问 NameNode 的 Web 界面,以查看文件系统的状态和管理操作。
b.RPC 服务: 8020
用于 HDFS 客户端和 NameNode 之间的 RPC 通信。
b.DataNode
a.Data Transfer: 50010
用于数据块的传输。
b.HTTP Web UI: 50075
用于访问 DataNode 的 Web 界面,以查看 DataNode 的状态。
c.IPC: 50020
用于 DataNode 与 NameNode 之间的内部通信。
b.YARN
a.ResourceManager
a.HTTP Web UI: 8088
用于访问 ResourceManager 的 Web 界面,以查看集群的状态和正在运行的应用。
b.RPC 服务: 8032
用于 YARN 客户端和 ResourceManager 之间的 RPC 通信。
b.NodeManager
a.HTTP Web UI: 8042
用于访问 NodeManager 的 Web 界面,以查看 NodeManager 的状态。
b.RPC 服务: 8040
用于 NodeManager 与 ResourceManager 之间的 RPC 通信。
c.MapReduce(MapReduce 是 YARN 的一个应用框架,它使用 YARN 的端口来进行管理和通信)
a.JobTracker (MapReduce v1)
a.HTTP Web UI: 50030
用于访问 JobTracker 的 Web 界面(仅适用于 Hadoop 1.x 版本)。
b.RPC 服务: 54311
用于 MapReduce 客户端和 JobTracker 之间的 RPC 通信(仅适用于 Hadoop 1.x 版本)。
b.ApplicationMaster (MapReduce v2)
由 YARN 管理,通常没有固定的端口,端口由 YARN 分配。
HTTP Web UI: 19888
用于访问历史服务器的 Web 界面,以查看历史应用程序的运行状态(对于 MapReduce v2)。
d.其他相关端口
a.Hadoop WebHDFS
WebHDFS: 50070(NameNode 的端口)
允许通过 HTTP 访问 HDFS 文件系统。
b.Zookeeper
Zookeeper 默认端口: 2181
用于 Hadoop 集群中的协调服务(如 HBase、Hadoop HA)
05.远程调试
a.Centos7
a.【永久,废弃】hadoop-env.sh添加监听服务
export HADOOP_CLIENT_OPTS="-Xmx512m -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
b.【临时,推荐】
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
c.服务器端执行MapReduce任务,打印5005端口
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop jar /workspace/vilgob-1.0-SNAPSHOT.jar com.ruoyi.mapreduce1.Demo00 /workspace/mapreduce1/input/demo00/ /workspace/mapreduce1/output/demo00/
Listening for transport dt_socket at address: 5005
b.Windows
a.注意
注:远程代码和本地代码一定要一致,否则打断点会打偏或者压根无法打断点,
b.远程JVM调试
主持人:192.168.185.150
端口:5005
c.附:临时环境变量
具体来说,export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
这条命令会将新的调试选项(用于远程调试Java程序的JVM参数)添加到HADOOP_CLIENT_OPTS环境变量中。这个环境变量只在当前的终端会话(或脚本执行过程中)有效。
-----------------------------------------------------------------------------------------------------
解释:
export HADOOP_CLIENT_OPTS="...":这会将HADOOP_CLIENT_OPTS环境变量设置为指定的值,并在当前的shell会话中导出,使其对子进程可见。
"$HADOOP_CLIENT_OPTS":引用当前已存在的HADOOP_CLIENT_OPTS值,确保新值是对现有变量的追加而不是覆盖。
-agentlib:jdwp=...:这是JVM的参数,用于配置远程调试。
-----------------------------------------------------------------------------------------------------
临时性:
这种设置只会在当前终端会话或者脚本的生命周期内生效。
一旦关闭终端或者新开一个终端,HADOOP_CLIENT_OPTS将恢复为原来的状态。
-----------------------------------------------------------------------------------------------------
如果需要永久生效:
可以将这行命令添加到用户的shell配置文件中,如~/.bashrc或~/.bash_profile(对于Bash),然后运行source ~/.bashrc来使其生效。
d.附:临时环境变量,还原
方法 1:移除特定的设置
如果您只想移除刚才添加的-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005部分,可以重新设置HADOOP_CLIENT_OPTS,移除这部分内容。
例如,您可以手动重新设置HADOOP_CLIENT_OPTS,如下所示:
export HADOOP_CLIENT_OPTS=$(echo "$HADOOP_CLIENT_OPTS" | sed 's/-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005//')
这条命令使用sed命令从HADOOP_CLIENT_OPTS中删除了指定的调试参数。
-----------------------------------------------------------------------------------------------------
方法 2:重置 HADOOP_CLIENT_OPTS
如果您想完全清除HADOOP_CLIENT_OPTS环境变量的值,可以使用以下命令:
unset HADOOP_CLIENT_OPTS
这样将彻底删除HADOOP_CLIENT_OPTS环境变量,之后如果需要使用它,必须重新设置。
-----------------------------------------------------------------------------------------------------
方法 3:还原到之前的值
如果您有之前的值,可以直接将HADOOP_CLIENT_OPTS设置回原始值:
export HADOOP_CLIENT_OPTS="<之前的值>"
-----------------------------------------------------------------------------------------------------
方法 4:关闭终端
如果您关闭当前的终端会话,所有临时设置的环境变量(包括HADOOP_CLIENT_OPTS)都会被清除。重新打开一个新的终端后,HADOOP_CLIENT_OPTS将恢复为原来的默认状态。
c.附:不同的JDK版本需要设置不同的配置
a.要让远程服务器运行的代码支持远程调试,则服务端启动的时候必须加上特定的 JVM 参数,这些参数是:
不同的JDK版本需要设置不同的配置:
JDK 9 or later
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005
JDK 5-8
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
JDK 1.4.x
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005
JDK 1.3.x or earlier
-Xnoagent -Djava.compiler=NONE -Xdebug
-Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005
b.说明
这里的9999则是服务端开放的端口,后期客户端IDEA需要连接当前端口进行远程交互和调试。
但是我们需要注意的是,这个9999端口在服务端一定要放开防火墙或者安全组;
具体端口看项目需求;运行服务端jar包程序则如下(JDK 5-8版本):
java -jar -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 ./SwaggerDemo-0.0.1-SNAPSHOT.jar > app.log &
99.脚本,说明
a.使用 & 同时运行
如果您希望这两条命令并行执行,可以将它们放在后台运行。以下是两种方法:
方法 1: 分别放到后台
您可以分别在命令后面加上 & 来让它们并行运行:
nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 &
nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1 &
这会在后台同时启动两个服务。
-----------------------------------------------------------------------------------------------------
方法 2: 使用 & 将命令合并为一个背景任务
将两个命令放在同一行并用 & 将它们同时运行:
nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 & nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1 &
b.使用 ; 顺序运行
如果您希望按顺序运行命令,而不管前一个命令是否成功,可以用 ; 连接:
nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 ; nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1
这会依次执行两个命令,第二个命令在第一个命令执行完后开始执行。
c.使用 && 条件执行
如果您希望第二个命令仅在第一个命令成功执行后才执行,可以使用 &&:
nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 && nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1
这种方式会在 metastore 服务启动成功后才启动 hiveserver2 服务。
99.脚本,flume.sh
#!/bin/bash
#echo "begin start flume..."
#flume的安装根目录(根据自己情况,修改为自己的安装目录)
path=/usr/local/flume/flume-1.8.0/
echo "flume home is :$path"
#flume的进程名称,固定值(不用修改)
JAR="flume"
#flume的配置文件名称(根据自己的情况,修改为自己的flume配置文件名称)
Flumeconf="flume-conf.properties"
#定义的soure名称
agentname="agent1"
function start(){
echo "begin start flume process ...."
#查找flume运行的进程数
num=`ps -ef|grep java|grep $JAR|wc -l`
#判断是否有flume进程运行,如果有则运行执行nohup命令
if [ "$num" = "0" ] ;then
nohup $path/bin/flume-ng agent --conf conf -f $path/conf/$Flumeconf --name $agentname -Dflume.root.logger=INFO,console > /usr/local/flume/flume-1.8.0/logs/flume.log 2>&1 &
echo "start success...."
echo "日志路径: $path/logs/flume.log"
else
echo "进程已经存在,启动失败,请检查....."
exit 0
fi
}
function stop(){
echo "begin stop flume process.."
num=`ps -ef|grep java|grep $JAR|wc -l`
#echo "$num...."
if [ "$num" != "0" ];then
#正常停止flume
ps -ef|grep java|grep $JAR|awk '{print $2;}'|xargs kill
echo "进程已经关闭..."
else
echo "服务未启动,无须停止..."
fi
}
function restart(){
#echo "begin stop flume process .."
#执行stop函数
stop
#判断程序是否彻底停止
num='ps -ef|grep java|grep $JAR|wc -l'
#stop完成之后,查找flume的进程数,判断进程数是否为0,如果不为0,则休眠5秒,再次查看,直到进程数为0
while [ $num -gt 0 ];do
sleep 5
num='ps -ef|grep java|grep $JAR|wc -l'
done
echo "flume process stoped,and starting..."
#执行start
start
echo "started...."
}
#case 命令获取输入的参数,如果参数为start,执行start函数,如果参数为stop执行stop函数,如果参数为restart,执行restart函数
case "$1" in
"start")
start
;;
"stop")
stop
;;
"restart")
restart
;;
*)
;;
esac
99.脚本,zookeeper-cluster.sh
#!/bin/bash
case $1 in
"start")
echo " --------Start 192.168.185.150 Zookeeper-------"
zkServer.sh start
for i in 192.168.185.151 192.168.185.152
do
echo " --------Start $i Zookeeper-------"
ssh $i "source /etc/profile; zkServer.sh start"
done
;;
"stop")
echo " --------Stop 192.168.185.150 Zookeeper-------"
zkServer.sh stop
for i in 192.168.185.151 192.168.185.152
do
echo " --------Stop $i Zookeeper-------"
ssh $i "source /etc/profile; zkServer.sh stop"
done
;;
"status")
echo " --------192.168.185.150 Zookeeper Status-------"
zkServer.sh status
for i in 192.168.185.151 192.168.185.152
do
echo " --------$i Zookeeper status-------"
ssh $i "source /etc/profile; zkServer.sh status"
done
;;
*)
echo "Usage: $0 {start|stop|status}"
;;
esac
---------------------------------------------------------------------------------------------------------
sed -i 's/\r$//' zookeeper-cluster.sh --将 Windows 换行符已修正为 Unix 格式
file zookeeper-cluster.sh
chmod +x zookeeper-cluster.sh
./zookeeper-cluster.sh start
99.脚本,kafka-cluster.sh
cd /usr/local/kafka/kafka-2.1.0/bin/
touch kafka-cluster.sh
---------------------------------------------------------------------------------------------------------
#!/bin/bash
case $1 in
"start")
echo " --------Start 192.168.185.150 Kafka Broker-------"
export JMX_PORT=9988 && /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
for i in 192.168.185.151 192.168.185.152
do
echo " --------Start $i Kafka Broker-------"
# 用于KafkaManager监控
ssh $i "source /etc/profile; export JMX_PORT=9988 && /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties"
done
;;
"stop")
echo " --------Stop 192.168.185.150 Kafka-------"
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-stop.sh
for i in 192.168.185.151 192.168.185.152
do
echo " --------Stop $i Kafka-------"
ssh $i "source /etc/profile; /usr/local/kafka/kafka-2.1.0/bin/kafka-server-stop.sh"
done
;;
*)
echo "Usage: $0 {start|stop}"
;;
esac
---------------------------------------------------------------------------------------------------------
sed -i 's/\r$//' kafka-cluster.sh --将 Windows 换行符已修正为 Unix 格式
file kafka-cluster.sh
chmod +x kafka-cluster.sh
./kafka-cluster.sh start
99.脚本,hbase-cluster.sh
cd /usr/local/hbase/hbase-2.1.1/bin/
touch hbase-cluster.sh
---------------------------------------------------------------------------------------------------------
#!/bin/bash
case $1 in
"start")
echo " --------Start 192.168.185.150 hbase-------"
/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start thrift && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start rest
for i in 192.168.185.151 192.168.185.152
do
echo " --------Start $i hbase-------"
# 用于hbaseManager监控
ssh $i "source /etc/profile; /usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start thrift && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start rest"
done
;;
"stop")
echo " --------Stop 192.168.185.150 hbase-------"
/usr/local/hbase/hbase-2.1.1/bin/stop-hbase.sh && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop thrift && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop rest
for i in 192.168.185.151 192.168.185.152
do
echo " --------Stop $i hbase-------"
ssh $i "source /etc/profile; /usr/local/hbase/hbase-2.1.1/bin/stop-hbase.sh && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop thrift && /usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop rest"
done
;;
*)
echo "Usage: $0 {start|stop}"
;;
esac
---------------------------------------------------------------------------------------------------------
sed -i 's/\r$//' hbase-cluster.sh --将 Windows 换行符已修正为 Unix 格式
file hbase-cluster.sh
chmod +x hbase-cluster.sh
./hbase-cluster.sh start
99.脚本,start-bigdata.sh
cd /usr/local/troyekk/
touch start-bigdata.sh
---------------------------------------------------------------------------------------------------------
#!/bin/bash
# 定义启动服务的函数
start-dfs() {
/usr/local/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
/usr/local/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver
hdfs dfsadmin -safemode leave
}
start-hive-cluster() {
nohup /usr/local/hive/hive-2.3.4/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 &
nohup /usr/local/hive/hive-2.3.4/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1 &
}
start-zookeeper() {
/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start
}
start-zookeeper-cluster() {
/usr/local/zookeeper/zookeeper-3.4.10/bin/zookeeper-cluster.sh start
}
start-hbase() {
/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh
/usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start thrift
/usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh start rest
}
start-hbase-cluster() {
/usr/local/hbase/hbase-2.1.1/bin/hbase-cluster.sh start
}
start-kafka() {
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
}
start-kafka-cluster() {
/usr/local/kafka/kafka-2.1.0/bin/kafka-cluster.sh start
}
start-spark() {
/usr/local/spark/spark-2.4.0/sbin/start-all.sh
}
start-flink() {
/usr/local/flink/flink-1.18.1/bin/start-cluster.sh
}
start-flume() {
sh /usr/local/flume/flume-1.8.0/bin/flume.sh start
}
start-kafka-ui() {
cd /usr/local/kafka-console-ui && sh bin/start.sh
}
start-hue() {
nohup /usr/local/hue/build/env/bin/supervisor >> /usr/local/hue/logs/hue.log 2>&1 &
}
# 执行启动服务的函数
echo "Starting Hadoop cluster..."
start-dfs
sleep 3
echo "Starting Hive cluster..."
start-hive-cluster
sleep 3
echo "Starting Zookeeper cluster..."
start-zookeeper
start-zookeeper-cluster
sleep 3
echo "Starting HBase cluster..."
start-hbase
start-hbase-cluster
sleep 3
echo "Starting Kafka cluster..."
start-kafka
start-kafka-cluster
sleep 3
echo "Starting Spark..."
start-spark
sleep 3
echo "Starting Flink..."
start-flink
sleep 3
echo "Starting Flume..."
start-flume
sleep 3
echo "Starting Kafka UI..."
start-kafka-ui
sleep 3
echo "Starting Hue..."
start-hue
sleep 3
echo "All services started successfully!"
---------------------------------------------------------------------------------------------------------
sed -i 's/\r$//' start-bigdata.sh --将 Windows 换行符已修正为 Unix 格式
file start-bigdata.sh
chmod +x start-bigdata.sh
./start-bigdata.sh
99.脚本,stop-bigdata.sh
cd /usr/local/troyekk/
touch stop-bigdata.sh
---------------------------------------------------------------------------------------------------------
#!/bin/bash
# 定义停止服务的函数
stop-dfs() {
/usr/local/hadoop/hadoop-2.7.7/sbin/stop-dfs.sh
/usr/local/hadoop/hadoop-2.7.7/sbin/stop-yarn.sh
/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh stop historyserver
}
stop-hive-cluster() {
jps | grep RunJar | awk '{print $1}' | xargs -r kill -9
}
stop-zookeeper() {
/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh stop
}
stop-zookeeper-cluster() {
/usr/local/zookeeper/zookeeper-3.4.10/bin/zookeeper-cluster.sh stop
}
stop-hbase() {
/usr/local/hbase/hbase-2.1.1/bin/stop-hbase.sh
/usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop thrift
/usr/local/hbase/hbase-2.1.1/bin/hbase-daemon.sh stop rest
}
stop-hbase-cluster() {
/usr/local/hbase/hbase-2.1.1/bin/hbase-cluster.sh stop
}
stop-kafka() {
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-stop.sh
}
stop-kafka-cluster() {
/usr/local/kafka/kafka-2.1.0/bin/kafka-cluster.sh stop
}
stop-spark() {
/usr/local/spark/spark-2.4.0/sbin/stop-all.sh
}
stop-flink() {
/usr/local/flink/flink-1.18.1/bin/stop-cluster.sh
}
stop-flume() {
sh /usr/local/flume/flume-1.8.0/bin/flume.sh stop
}
stop-kafka-ui() {
cd /usr/local/kafka-console-ui && sh bin/shutdown.sh
}
stop-hue() {
ps -ef | grep hue | grep -v grep | awk '{print $2}' | xargs kill -9
}
# 执行停止服务的函数
echo "Stopping Kafka cluster..."
stop-kafka-cluster
sleep 3
echo "Stopping Hadoop cluster..."
stop-dfs
sleep 3
echo "Stopping Hive cluster..."
stop-hive-cluster
sleep 3
echo "Stopping Zookeeper cluster..."
stop-zookeeper
stop-zookeeper-cluster
sleep 3
echo "Stopping HBase cluster..."
stop-hbase
stop-hbase-cluster
sleep 3
echo "Stopping Spark..."
stop-spark
sleep 3
echo "Stopping Flink..."
stop-flink
sleep 3
echo "Stopping Flume..."
stop-flume
sleep 3
echo "Stopping Kafka UI..."
stop-kafka-ui
sleep 3
echo "Stopping Hue..."
stop-hue
sleep 3
echo "All services stopped successfully!"
---------------------------------------------------------------------------------------------------------
sed -i 's/\r$//' stop-bigdata.sh --将 Windows 换行符已修正为 Unix 格式
file stop-bigdata.sh
chmod +x stop-bigdata.sh
./stop-bigdata.sh
5.1 jdk-1.8.0_191
01.jdk
a.安装
rpm -ivh jdk-8u231-linux-x64.rpm
b.卸载系统自带的jdk
yum list installed | grep java --列举匹配已安装的java的软件包
yum -y remove java-1.7.0-openjdk* --卸载安装的jdk
yum -y remove java-1.8.0-openjdk*
yum -y remove jdk1.8.x86_64
02.jdk
a.环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191/
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
b.刷新环境变量
source /etc/profile
c.验证java
java -version
5.2 node-16.13.2
01.node1
a.安装
cd /usr/local
wget https://nodejs.org/dist/v16.13.2/node-v16.13.2-linux-x64.tar.xz
tar -xf node-v16.13.2-linux-x64.tar.xz
mv node-v16.13.2-linux-x64 /usr/local/node
b.建立软链接
ln -s /usr/local/node/bin/node /usr/bin/node
ln -s /usr/local/node/bin/npm /usr/bin/npm
c.查看版本
node -v
npm -v
d.配置1
npm config set prefix "/usr/local/node/node-global/" --全局cache位置
npm config set cache "/usr/local/node/node-cache/" --全局global位置
npm config ls --查看是否修改成功
e.配置2
npm config set registry https://registry.npmjs.org/ --设置国外镜像
npm config set registry https://registry.npmmirror.com --设置国内镜像
npm config get registry --查看镜像
f.测试
npm install -g hexo
/usr/local/node/node-global/bin/hexo
02.node2
a.环境变量
vi /etc/profile
export NODE_HOME=/usr/local/node/
export PATH=$PATH:$NODE_HOME/bin:$NODE_HOME/node-global/bin
b.刷新环境变量
source /etc/profile
c.验证node-global
hexo
5.3 maven-3.8.8
01.maven1
a.安装
cd /usr/local
wget https://downloads.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz
tar -zxvf apache-maven-3.8.8-bin.tar.gz
mv apache-maven-3.8.8 /usr/local/maven
b.查看版本
/usr/local/maven/bin/mvn -v
c.配置
vi /usr/local/maven/conf/settings.xml
-----------------------------------------------------------------------------------------------------
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.2.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.2.0 https://maven.apache.org/xsd/settings-1.2.0.xsd">
<pluginGroups></pluginGroups>
<proxies></proxies>
<servers></servers>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
<profiles>
<profile>
<id>jdk-1.8</id>
<activation>
<jdk>1.8</jdk>
</activation>
<properties>
<java.version>1.8</java.version>
<maven.test.skip>true</maven.test.skip>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
</profile>
</profiles>
</settings>
02.maven2
a.环境变量
vi /etc/profile
export MAVEN_HOME=/usr/local/maven/
export PATH=$PATH:$MAVEN_HOME/bin
b.刷新环境变量
source /etc/profile
c.验证node-global
mvn -v
5.4 python-2.7.2
01.Python检查版本
a.查看系统自带的Python、pip
whereis pip
whereis python
b.安装
apt-get install python-minimal
apt-get install curl
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.py --安装pip3
python2 get-pip.py --安装pip2
apt-get install python3-testresources --防止pip3出错
apt-get install python-testresources --防止pip2出错
pip3 install --upgrade pip --升级pip3
pip2 install --upgrade pip --升级pip2
apt-get install -y python-pip --安装pip2
apt-get install -y python3-pip --安装pip3
pip install --upgrade pip --更新pip版本
c.测试
pip3 --version --pip 20.2.4(Python 3.6.17)
pip2 --version --pip 20.2.4(Python 2.7.17)
python --version --Python 2.7.17
02.Python默认版本
a.用户级修改
echo "alias python='/usr/bin/python3.6'" >> ~/.bashrc && source ~/.bashrc
b.系统级修改
a.修改软链接
rm /usr/bin/python && ln -s /usr/bin/python3.6 /usr/bin/python
rm /usr/bin/python3 && ln -s /usr/local/Python3.6.2/bin/python3 /usr/bin/python3
b.管理器
ls /usr/bin/python* && ls | grep python && dpkg -l python*
update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
update-alternatives --install /usr/bin/python python /usr/bin/python3.7 2
update-alternatives --install /usr/bin/python python /usr/local/Python3.6.2/bin/python 3
03.pip报错
a.修改pip默认版本,导致pip报错
a.报错
ImportError: No module named 'pip'
b.文件
vi /usr/bin/pip 或 vi /usr/bin/pip3
c.解决
#!/usr/bin/python 修改为 #!/usr/bin/python2.7 或 /usr/bin/python3.6
b.升级pip更新为10.0.0,库里面的函数有所变动,导致pip报错
a.报错
ImportError: cannot import name 'main'
b.文件
vi /usr/bin/pip 或 vi /usr/bin/pip3
c.解决
from pip import main 修改为 from pip._internal import main
c.修改python默认版本,导致yum报错
a.报错
ImportError: No module named 'pip'
b.文件
vi /usr/bin/yum 或 vi /usr/libexec/urlgrabber-ext-down
c.解决
#!/usr/bin/python 修改为 #!/usr/bin/python2.7 或 /usr/bin/python3.6
04.Python3.6.2
a.依赖、卸载旧版本
apt-get -y install gcc g++ make cmake
apt-get -y install build-essential tk-dev
apt-get -y install libncurses5-dev libncursesw5-dev libreadline6-dev
apt-get -y install libdb5.3-dev libgdbm-dev libsqlite3-dev libssl-dev libc6-dev
apt-get -y install libbz2-dev libexpat1-dev liblzma-dev zlib1g-dev libffi-dev
apt-get -y purge --auto-remove python3.7
b.安装
cd /root/ && wget --no-check-certificate https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tar.xz && tar -xvJf Python-3.6.2.tar.xz && rm -rf Python-3.6.2.tar.xz
c.进入Modules目录修改配置文件Setup.dist,添加编译ssl模块
vi /root/Python-3.6.2/Modules/Setup.dist
SSL=/usr/local/ssl --打开这四行注释
_ssl _ssl.c \ --打开这四行注释
-DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \ --打开这四行注释
-L$(SSL)/lib -lssl -lcrypto --打开这四行注释
d.编译
cd /root/Python-3.6.2/ && ./configure --prefix=/usr/local/python-3.6.2/ --enable-shared --with-openssl=/usr/local/openssl-1.1.1g && make -j 4 && make install && rm -rf /root/Python-3.6.2/
e.无法加载libpython3.6m.so.1.0库文件
cp /usr/local/python-3.6.2/lib/libpython3.6m.so.1.0 /usr/lib/
cp /usr/local/python-3.6.2/lib/libpython3.6m.so.1.0 /usr/lib32/
cp /usr/local/python-3.6.2/lib/libpython3.6m.so.1.0 /usr/lib64/
f.修改软链接
rm /usr/bin/python && rm /usr/bin/python2* && rm /usr/bin/python3* && rm /usr/bin/pip*
# ln -s /usr/local/python-3.6.2/bin/python3 /usr/bin/python
# ln -s /usr/local/python-3.6.2/bin/python3-config /usr/bin/python-config
ln -s /usr/local/python-3.6.2/bin/python3 /usr/bin/python3
ln -s /usr/local/python-3.6.2/bin/python3-config /usr/bin/python3-config
ln -s /usr/local/python-3.6.2/bin/python3 /usr/bin/python3.6
ln -s /usr/local/python-3.6.2/bin/python3-config /usr/bin/python3.6-config
ln -s /usr/local/python-3.6.2/bin/pip3 /usr/bin/pip
ln -s /usr/local/python-3.6.2/bin/pip3 /usr/bin/pip3
python --version && python3 --version && python3.6 --version && pip --version && pip3 --version
g.用update-alternatives来为整个系统更改Python版本
a.设置优先级
ls /usr/bin/python* && ls | grep python && dpkg -l python*
update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
update-alternatives --install /usr/bin/python python /usr/bin/python3.7 2
update-alternatives --install /usr/bin/python python /usr/local/python-3.6.2/bin/python3.6 3
update-alternatives --remove /usr/bin/python python /usr/local/python-3.6.2/bin/python3.6 3
b.列出可用的Python替代版本
update-alternatives --list python
c.选择可用的Python替代版本
update-alternatives --config python
05.Vim8支持Python3
a.依赖、卸载旧版本
apt-get -y install gcc g++ make cmake
apt-get -y install build-essential tk-dev
apt-get -y install libncurses5-dev libncursesw5-dev libreadline6-dev
apt-get -y install libdb5.3-dev libgdbm-dev libsqlite3-dev libssl-dev libc6-dev
apt-get -y install libbz2-dev libexpat1-dev liblzma-dev zlib1g-dev libffi-dev
apt-get -y install libcairo2-dev libx11-dev libxpm-dev libxt-dev python3-dev ruby-dev libperl-dev
apt-get -y remove vim vim-runtime vim-tiny vim-common vim-scripts vim-doc
b.安装
cd /root/ && wget https://github.com/vim/vim/archive/refs/tags/v8.2.3156.tar.gz && tar -xvzf v8.2.3156.tar.gz && rm -rf v8.2.3156.tar.gz && python-config --configdir && python3-config --configdir
c.编译
cd /root/vim-8.2.3156/
./configure --with-features=huge \
--enable-multibyte \
--enable-rubyinterp=yes \
--enable-python3interp=yes \
--with-python3-config-dir=/usr/lib/python3.7/config-3.7m-x86_64-linux-gnu/ \
--enable-perlinterp=yes \
--prefix=/usr/local/vim8
make -j 4 && make install && rm -rf /root/vim-8.2.3156/
d.用户别名
echo "alias vi='/usr/local/vim8/bin/vim'" >> ~/.bashrc && source ~/.bashrc && vi --version
echo "alias vim='/usr/local/vim8/bin/vim'" >> ~/.bashrc && source ~/.bashrc && vim --version
e.常见报错
报错1:export PYTHON_CONFIGURE_OPTS="--enable-shared"
解决1:Python编译,configure --prefix=/usr/local/python-3.6.2/ --enable-shared,python共享动态链接
报错2:requires Vim compiled with Python (3.6.0+) support
解决2:VIM编译,configure --enable-python3interp=yes --with-python3-config-dir,参数只能python2/3
报错3:restart with ':YcmRestartServer', you need to compile YCM before using it
解决3:YCM编译,cd ../k-vim/bundle/YouCompleteMe && python install.py,python软链接对应为python3.6+
5.5 kafka-2.1.0
01.kafka
a.命令
kafka-server-start.sh kafka启动程序
kafka-server-stop.sh kafka停止程序
kafka-topics.sh 创建topic程序
kafka-console-producer.sh 命令行模拟生产者生产消息数据程序
kafka-console-consumer.sh 命令行模拟消费者消费消息数据程序
b.配置
a.server.properties
a.master
broker.id=0
listeners=PLAINTEXT://192.168.185.150:9092
log.dirs=/usr/local/kafka/kafka-2.1.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
b.slave1
broker.id=1
listeners=PLAINTEXT://192.168.185.151:9092
log.dirs=/usr/local/kafka/kafka-2.1.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
c.slave2
broker.id=2
listeners=PLAINTEXT://192.168.185.152:9092
log.dirs=/usr/local/kafka/kafka-2.1.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
b.连接Kafka集群
通常使用任意一个 Kafka Broker 的 IP 地址都可以。Kafka 集群会将生产者和消费者的请求路由到适当的 Broker。
任意一个 Broker 的 IP 地址: 你可以使用集群中任意一个 Broker 的 IP 地址来连接 Kafka 集群。Kafka 会处理请求并将其转发到其他 Brokers(如果需要)。
例如,你可以使用以下 IP 地址连接集群:
192.168.185.150:9092
192.168.185.151:9092
192.168.185.152:9092
-------------------------------------------------------------------------------------------------
为什么可以使用任意一个 Broker IP 地址?
负载均衡和故障转移: Kafka 集群的元数据会在客户端和集群之间同步。如果你连接到集群中的一个 Broker,客户端会从这个 Broker 获取集群的元数据,包括其他 Brokers 的信息,从而进行负载均衡和故障转移。
集群的元数据: Kafka 的客户端在连接到集群中的任意 Broker 后,会获取集群的完整元数据,包括所有 Brokers 的地址、分区信息等。这样,客户端能够与集群中的其他 Brokers 通信,而不仅仅是你初始连接的那个 Broker。
c.运行
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties &
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties > /usr/local/kafka/kafka-2.1.0/logs/kafka.log 2>&1 &
-----------------------------------------------------------------------------------------------------
# ps aux | grep kafka --查看进程
root 2966 0.0 0.0 112660 972 pts/0 R+ 16:43 0:00 grep --color=auto kafka
02.kafka-console-ui
a.安装
kafka-console-ui-1.0.10.zip
unzip kafka-console-ui-1.0.10.zip
b.使用
cd /usr/local/kafka-console-ui && sh bin/start.sh
cd /usr/local/kafka-console-ui && sh bin/shutdown.sh
http://192.168.185.150:7766
---------------------------------------------------------------------------------------------------------
运维 -> 集群切换 -> 新增集群 -> cluster、192.168.185.150:9092
5.6 hue-4.10.0
01.前提
安装node(镜像)、maven(镜像)、python2的pip(镜像)、openssl(export PIP_NO_VERIFY_SSL=1,禁止SSL验证)
02.Hue安装
a.更新yum源
a.备份异常的Base源文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
b.下载并安装Base源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
c.测试
ping www.google.com
ping mirrors.tuna.tsinghua.edu.cn
d.示例
yum install net-tools -y
b.依赖
yum -y install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel
c.下载解压并移动,编译
cd /usr/local
wget https://github.com/cloudera/hue/archive/release-4.10.0.tar.gz
tar -zxvf hue-release-4.10.0.tar.gz
d.编译
a.报错1
rm -rf /usr/local/hue
b.报错2
wget https://bootstrap.pypa.io/pip/2.7/get-pip.py
sudo python get-pip.py
which pip
pip --version
-------------------------------------------------------------------------------------------------
pip install setuptools_scm
pip show setuptools_scm
python -m pip show setuptools_scm
c.报错3
sudo yum install openssl openssl-devel
ls -l /usr/lib64 | grep 'libssl\|libcrypto'
d.报错4
export PIP_NO_VERIFY_SSL=1 --环境变量来临时禁用SSL验证
-------------------------------------------------------------------------------------------------
pip install cryptography
python -m pip show cryptography
e.报错5
cd ~
mkdir .pip
cd .pip
touch pip.conf
vi pip.conf
-------------------------------------------------------------------------------------------------
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
-------------------------------------------------------------------------------------------------
pip3 install pymysql
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
f.编译
cd /usr/local/hue-release-4.10.0
rm -rf /usr/local/hue
make clean
PREFIX=/usr/local make install
e.配置Hadoop
a.hdfs-site.xml
<!-- HUE -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
b.core-site.xml
<!-- HUE -->
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.groups</name>
<value>*</value>
</property>
c.httpfs-site.xml
<!-- HUE -->
<property>
<name>httpfs.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>httpfs.proxyuser.hue.groups</name>
<value>*</value>
</property>
d.同步配置到slave1、slave2
scp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml root@192.168.185.151:/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml
scp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml root@192.168.185.152:/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml
-------------------------------------------------------------------------------------------------
scp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/httpfs-site.xml root@192.168.185.151:/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/httpfs-site.xml
scp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/httpfs-site.xml root@192.168.185.152:/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/httpfs-site.xml
f.配置hbase
a.hbase-site.xml
vi /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
-------------------------------------------------------------------------------------------------
<property>
<name>hbase.regionserver.thrift.http</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>true</value>
</property>
b.同步配置到slave1、slave2
scp /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml root@192.168.185.151:/usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
scp /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml root@192.168.185.152:/usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
g.配置
a.配置1
a.打开
cd /usr/local/hue/desktop/conf/
cp pseudo-distributed.ini.tmpl pseudo-distributed.ini
vi pseudo-distributed.ini
b.配置hadoop
# [desktop]
http_host=0.0.0.0
http_port=8000
is_hue_4=true # 可能没有,就新增
time_zone=Asia/Shanghai
dev=true
server_user=hue
server_group=hue
default_user=hue
# 211行左右。禁用solr,规避报错
app_blacklist=search
# Hue默认使用SQLite数据库记录相关元数据,替换为mysql
[librdbms]
[[databases]]
[[[mysql]]]
nice_name="My SQL DB"
name=hue
engine=mysql
host=localhost
port=3306
user=hue
password=123456
options={}
# 1003行左右,Hadoop配置文件的路径
hadoop_conf_dir=$HADOOP_HOME/etc/hadoop
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://192.168.185.150:9000
webhdfs_url=http://192.168.185.150:50070/webhdfs/v1
c.配置yarn
[[yarn_clusters]]
[[[default]]]
resourcemanager_host=192.168.185.150
resourcemanager_port=8032
resourcemanager_api_url=http://192.168.185.150:8088
proxy_api_url=http://192.168.185.150:8088
history_server_api_url=http://192.168.185.150:19888
d.配置hbase
[hbase]
hbase_clusters=(Cluster|192.168.185.150:9090)
hbase_conf_dir=/usr/local/hbase/hbase-2.1.1/conf
e.配置hive
[beeswax]
hive_server_host=192.168.185.150
hive_server_port=10000
hive_conf_dir=$HIVE_HOME/conf
server_conn_timeout=120
thrift_version=7
f.配置oozie
[oozie]
#存储样本数据的本地路径
local_data_dir=/xxx
#存储采样数据的本地路径
sample_data_dir=/xxx
#存储oozie工作流的HDFS路径
remote_data_dir=/xxx
#一次调用中最大返回的oozie工作流数量
oozie_jobs_count=50
g.配置imapla
[impala]
#连接的impalad的服务器地址,如果使用了HAProxy配置了多个impalad,这里应填写HAProxy的地址
server_host=xxx
#连接的impalad的端口,如果使用了HAProxy配置了多个impalad,这里应填写HAProxy的JDBC服务的端口
server_port=xxx
b.创建用户
$ useradd hue
$ passwd hue
$ 123456789
c.添加hue用户并赋权
sudo adduser hue
sudo chmod -R 777 /usr/local/hue
sudo chown -R hue:hue /usr/local/hue --将hue源码的用户所有者/组改为hue
d.创建hue数据库,并初始化数据
$ mysql
$ create database hue;
$ select host,user from mysql.user;
$ create user 'hue'@'%' identified by '123456';
$ CREATE USER 'hue'@'localhost' IDENTIFIED BY '123456';
$ GRANT ALL PRIVILEGES ON *.* TO 'hue'@'%' IDENTIFIED BY '123456';
$ GRANT ALL PRIVILEGES ON *.* TO 'hue'@'localhost' IDENTIFIED BY '123456';
$ flush privileges;
-------------------------------------------------------------------------------------------------
$ mysql -u hue -p
$ 123456
e.向hue数据库中写表
/usr/local/hue/build/env/bin/hue syncdb
/usr/local/hue/build/env/bin/hue migrate
f.必须添加hue用户,不然无法启动
groupadd hue
useradd -g hue hue
g.启动
a.启动
/usr/local/hue/build/env/bin/supervisor
nohup /usr/local/hue/build/env/bin/supervisor >> /usr/local/hue/logs/hue.log 2>&1 &
chmod -R 777 /usr/local/hue/logs/hue.log
b.停止
ps -ef | grep hue | grep -v grep | awk '{print $2}' | xargs kill -9
kill -9 port
c.访问
http://master:8000/hue
root
123456
99.常见问题
a.报错1
a.问题
[root@master hue-release-4.10.0]# PREFIX=/usr/local make install
"PYTHON_VER is python2.7."
"Python 2 module install of desktop/ext-py"
"SYS_PYTHON is /usr/bin/python2.7."
"ENV_PYTHON is /usr/local/hue-release-4.10.0/build/env/bin/python2.7."
ERROR: /usr/local/hue not empty. Cowardly refusing to continue.
make: *** [install-check] Error 1
-------------------------------------------------------------------------------------------------
这个错误表明 make install 命令在执行时发现 /usr/local/hue 目录非空,因此拒绝继续安装。
安装过程可能会覆盖或冲突已有文件,所以系统出于安全考虑停止了安装。
b.解决
rm -rf /usr/local/hue
b.报错2
a.问题
[root@master hue-release-4.10.0]# which python
/usr/bin/python
[root@master hue-release-4.10.0]# python --version
Python 2.7.5
-------------------------------------------------------------------------------------------------
[root@master hue-release-4.10.0]# python -m pip show setuptools_scm
/usr/bin/python: No module named pip
-------------------------------------------------------------------------------------------------
[root@master hue-release-4.10.0]# which pip
/usr/bin/which: no pip in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/java/jdk1.8.0_191/bin:/usr/local/scala/scala-2.11.8/bin:/usr/local/hadoop/hadoop-2.7.7/bin:/usr/local/hadoop/hadoop-2.7.7/sbin:/usr/local/hive/hive-2.3.4/bin:/usr/local/zookeeper/zookeeper-3.4.10/bin:/usr/local/kafka/kafka-2.1.0/bin:/usr/local/hbase/hbase-2.1.1/bin:/usr/local/flume/flume-1.8.0/bin:/usr/local/spark/spark-2.4.0/bin:/usr/local/storm/apache-storm-1.2.2/bin:/usr/local/node//bin:/usr/local/node//node-global/bin:/usr/local/maven//bin:/root/bin)
-------------------------------------------------------------------------------------------------
经检测,centos7本系统默认安装的python2.7.5,没有pip命令
b.解决(手动安装 pip)
wget https://bootstrap.pypa.io/pip/2.7/get-pip.py
sudo python get-pip.py
which pip
pip --version
-------------------------------------------------------------------------------------------------
pip install setuptools_scm
pip show setuptools_scm
python -m pip show setuptools_scm
c.报错3
a.问题
/usr/bin/ld: cannot find -lssl
/usr/bin/ld: cannot find -lcrypto
collect2: error: ld returned 1 exit status
error: command 'gcc' failed with exit status 1
make[2]: *** [/usr/local/hue-release-4.10.0/desktop/core/build/python-ldap-2.3.13/egg.stamp] Error 1
make[2]: Leaving directory /usr/local/hue-release-4.10.0/desktop/core'
make[1]: *** [.recursive-install-bdist/core] Error 2
make[1]: Leaving directory /usr/local/hue-release-4.10.0/desktop'
make: *** [install-desktop] Error 2
-------------------------------------------------------------------------------------------------
经检测,centos7本系统默认安装的gcc,没有lssl、lcrypto库
b.解决(安装lssl、lcrypto)
sudo yum install openssl openssl-devel
ls -l /usr/lib64 | grep 'libssl\|libcrypto'
d.报错4
a.问题
# We have two virt-env: /usr/local/hue-release-4.10.0/build/env/bin/python2.7 /usr/local/hue-release-4.10.0/build/env/bin/pip aka /build/hue for build and /usr/local/hue/build/env for destination.
Collecting cryptography==3.3.2
Could not fetch URL https://pypi.python.org/simple/cryptography/: There was a problem confirming the ssl certificate: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:618) - skipping
Could not find a version that satisfies the requirement cryptography==3.3.2 (from versions: )
No matching distribution found for cryptography==3.3.2
-------------------------------------------------------------------------------------------------
经检测,PyPI(Python Package Index)下载 cryptography 包时,由于 SSL 证书验证失败,pip 无法建立安全连接,导致无法获取所需的包版本
b.解决
export PIP_NO_VERIFY_SSL=1 --环境变量来临时禁用SSL验证
-------------------------------------------------------------------------------------------------
pip install cryptography
python -m pip show cryptography
e.报错5
a.问题
Collecting future==0.18.2
Could not fetch URL https://pypi.python.org/simple/future/: There was a proble m confirming the ssl certificate: [SSL: CERTIFICATE_VERIFY_FAILED] certificate v erify failed (_ssl.c:618) - skipping
Could not find a version that satisfies the requirement future==0.18.2 (from v ersions: )
No matching distribution found for future==0.18.2
make: *** [install-env] Error 1
-------------------------------------------------------------------------------------------------
经检测,由于频繁通过pip安装包,镜像源为国外,导致编译中断
b.解决
cd ~
mkdir .pip
cd .pip
touch pip.conf
vi pip.conf
-------------------------------------------------------------------------------------------------
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
-------------------------------------------------------------------------------------------------
pip3 install pymysql
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
f.报错6
a.问题
root@master conf]# /usr/local/hue/build/env/bin/hue syncdb
[27/Aug/2024 18:26:04 +0000] settings DEBUG DESKTOP_DB_TEST_NAME SET: /usr/local/hue/desktop/desktop-test.db
[27/Aug/2024 18:26:04 +0000] settings DEBUG DESKTOP_DB_TEST_USER SET: hue_test
/usr/local/hue/build/env/lib/python2.7/site-packages/requests_kerberos-0.12.0-py2.7.egg/requests_kerberos/kerberos_.py:11: CryptographyDeprecationWarning: Python 2 is no longer supported by the Python core team. Support for it is now deprecated in cryptography, and will be removed in the next release.
from cryptography import x509
[27/Aug/2024 18:26:05 +0000] sslcompat DEBUG ipaddress module is available
[27/Aug/2024 18:26:05 +0000] sslcompat WARNING backports.ssl_match_hostname is unavailable
[27/Aug/2024 18:26:05 +0000] sslcompat DEBUG ssl.match_hostname is available
[27/Aug/2024 18:26:05 +0000] decorators INFO AXES: BEGIN LOG
[27/Aug/2024 18:26:05 +0000] decorators INFO AXES: Using django-axes 4.5.4
[27/Aug/2024 18:26:05 +0000] decorators INFO AXES: blocking by IP only.
[27/Aug/2024 18:26:05 +0000] __init__ INFO Couldn't import snappy. Support for snappy compression disabled.
System check identified some issues:
WARNINGS:
jobbrowser.DagDetails.dag_info: (fields.W342) Setting unique=True on a ForeignKey has the same effect as using a OneToOneField.
HINT: ForeignKey(unique=True) is usually better served by a OneToOneField.
jobbrowser.QueryDetails.hive_query: (fields.W342) Setting unique=True on a ForeignKey has the same effect as using a OneToOneField.
HINT: ForeignKey(unique=True) is usually better served by a OneToOneField.
-------------------------------------------------------------------------------------------------
经检测,这是一个警告,表示你正在使用的 cryptography 库不再支持 Python 2,Python 2 的支持在未来的版本中将被移除。
b.解决
升级到 Python 3:考虑将 Hue 升级到支持 Python 3 的版本,并迁移到 Python 3。这是最好的长期解决方案,因为 Python 2 已于 2020 年 1 月停止支持。
继续使用 Python 2:如果你必须使用 Python 2,确保所有库都是 Python 2 的兼容版本,但这不是推荐的做法,因为 Python 2 已经过时,且缺乏安全更新。
g.报错7
a.问题
Thrift version configured by property thrift_version might be too high. Request failed with
"Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null,
username:hue, configuration:{hive.server2.proxy.user=root})" (code OPEN_SESSION): None
-------------------------------------------------------------------------------------------------
经检测,"Required field 'client_protocol' is unset!":这表明请求中的 client_protocol 字段未设置,导致服务端无法处理请求。
"Thrift version configured by property thrift_version might be too high":这意味着配置的 Thrift 版本可能与服务端不兼容。
b.解决1
使用 pip 或 yum 查看已安装的 Thrift 版本
pip show thrift
yum list installed | grep thrift
-------------------------------------------------------------------------------------------------
pip install thrift
pip show thrift
c.解决2
vi /usr/local/hue/desktop/conf/pseudo-distributed.ini
-------------------------------------------------------------------------------------------------
thrift_version=7
5.7 oozie-4.0.0
00.前提
jdk8+, hadoop, maven, Ext JS 2.2, Pig 0.16.0
01.安装pig
a.下载
cd /usr/local/
wget https://downloads.apache.org/pig/pig-0.16.0/pig-0.16.0.tar.gz
tar -xzvf pig-0.16.0.tar.gz
mkdir -p /usr/local/pig-0.16.0/logs
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export PIG_HOME=/usr/local/pig-0.16.0
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$PIG_HOME/bin:$PIG_HOME/conf
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置
a.pig(废)
vi /usr/local/pig-0.16.0/conf/pig.properties
fs.default.name=hdfs://192.168.185.150:9000
mapred.job.tracker=192.168.185.150:9001
b.hadoop(废)
vi /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:9001</value>
</property>
d.验证
pig -version
-----------------------------------------------------------------------------------------------------
/usr/local/pig-0.16.0/bin/pig -x local --Local模式
/usr/local/pig-0.16.0/bin/pig -x mapreduce --MapReduce模式
/usr/local/pig-0.16.0/bin/pig -x local count_pig.pig --启动脚本
02.安装oozie(源码,需复杂编译)
a.编译
cd /usr/local/
wget https://downloads.apache.org/oozie/5.2.1/oozie-5.2.1.tar.gz
tar -xzvf oozie-5.2.1.tar.gz
b.编译
cd /usr/local/oozie-5.2.1/bin
mkdistro.sh -DskipTests -Puber --distro/target目录编译出Oozie-5.1.0-distro.tar.gz
/usr/local/oozie-5.2.1/target/oozie-5.2.1-distro.tar.gz --编译后的包
c.更改名称,因为编译前的包名为oozie-5.2.1
mv /usr/local/oozie-5.2.1 /usr/local/oozie-5.2.1-compile
mv /usr/local/oozie-5.2.1-compile/target/oozie-5.2.1-distro.tar.gz /usr/local/ --移动到/usr/loacl
tar -xzvf oozie-5.2.1-distro.tar.gz
mv /usr/local/oozie-5.2.1-distro /usr/local/oozie-5.2.1
-----------------------------------------------------------------------------------------------------
cd /usr/local/oozie-5.2.1
tar -xzvf oozie-client-5.2.1.tar.gz
tar -xzvf oozie-examples.tar.gz
tar -xzvf oozie-sharelib-5.2.1.tar.gz
d.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export OOZIE_HOME=/usr/local/oozie-5.2.1
export OOZIE_CONFIG=/usr/local/oozie-5.2.1/conf
export OOZIE_URL=http://192.168.185.150:11000/oozie
export PATH=$PATH:$OOZIE_HOME/bin
-----------------------------------------------------------------------------------------------------
source /etc/profile
e.配置
a.Ext JS 2.2
mkdir -p /usr/local/oozie-5.2.1/libext
cd /usr/local/oozie-5.2.1/libext
wget https://downloads.sourceforge.net/project/extjs/Ext%202.2/ext-2.2.zip
unzip ext-2.2.zip -d /usr/local/oozie-5.2.1/libext/
b.mysql-connector-java-5.1.49.tar.gz
cd /usr/local/oozie-5.2.1/libext
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.49.tar.gz
tar -xzvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar /usr/local/oozie-5.2.1/libext/
c.oozie-site.xml
<property>
<name>oozie.service.ProxyUserService.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>oozie.service.ProxyUserService.proxyuser.hue.groups</name>
<value>*</value>
</property>
d.mysql
mysql -u root -p
select host,user from mysql.user;
CREATE DATABASE oozie;
CREATE USER 'oozie'@'localhost' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON oozie.* TO 'oozie'@'%';
FLUSH PRIVILEGES;
-------------------------------------------------------------------------------------------------
mysql> select host,user from mysql.user;
+-----------+-------+
| host | user |
+-----------+-------+
| % | hive |
| % | hue |
| % | oozie |
| % | root |
| 127.0.0.1 | root |
| ::1 | root |
| localhost | |
| localhost | hive |
| localhost | hue |
| localhost | oozie |
| localhost | root |
| master | |
| master | hive |
| master | root |
+-----------+-------+
14 rows in set (0.00 sec)
-------------------------------------------------------------------------------------------------
注意要删除msyql中两个空的用户,否则会一直报用户无权限
-- 查看空用户
SELECT host, user FROM mysql.user WHERE user = '';
-- 删除空用户
DELETE FROM mysql.user WHERE user = '';
-- 刷新权限
FLUSH PRIVILEGES;
-- 查看用户、访问地址
select host,user from mysql.user;
-------------------------------------------------------------------------------------------------
/usr/local/oozie-5.2.1/bin/ooziedb.sh create -sqlfile oozie.sql -run --迁移表
f.构建Oozie
cd /usr/local/oozie-5.2.1
mvn clean package -DskipTests -P hadoop-2 -Dhadoop.version=2.7.7
g.部署Oozie
a.将 Oozie 部署到 Hadoop 集群,通常使用 Tomcat 作为 Web 服务器
mkdir -p /var/lib/oozie
cp distro/target/oozie-5.1.0-distro/oozie-5.1.0/oozie.war /var/lib/oozie/
b.使用 Oozie 提供的脚本来准备部署环境
/opt/oozie-5.1.0/bin/oozie-setup.sh prepare-war -d /opt/oozie-5.1.0/libext/
h.验证
a.启动
/usr/local/oozie-5.2.1/bin/oozied.sh start --守护进程
/usr/local/oozie-5.2.1/bin/oozied.sh stop --守护进程
/usr/local/oozie-5.2.1/bin/oozied.sh run --前台运行
/usr/local/oozie-5.2.1/bin/oozie admin -oozie http://localhost:11000/oozie -status --状态
b.访问
http://192.168.185.150:11000/oozie/
03.安装oozie(源码,已经编译好的安装包)
a.配置驱动包
百度网盘:oozie-4.0.0-cdh5.3.6.zip
cd /usr/local/
unzip oozie-4.0.0-cdh5.3.6.zip
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export OOZIE_HOME=/usr/local/oozie-4.0.0-cdh5.3.6
export OOZIE_CONFIG=/usr/local/oozie-4.0.0-cdh5.3.6/conf
export OOZIE_URL=http://192.168.185.150:11000/oozie
export PATH=$PATH:$OOZIE_HOME/bin
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置libext
a.将hadooplibs包放到根目录
cd /usr/local/oozie-4.0.0-cdh5.3.6/
tar -zxvf oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz
-------------------------------------------------------------------------------------------------
cd /usr/local/oozie-4.0.0-cdh5.3.6/
mkdir /usr/localoozie-4.0.0-cdh5.3.6/libext
cp -r oozie-4.0.0-cdh5.3.6/hadooplibs/hadooplib-2.5.0-cdh5.3.6.oozie-4.0.0-cdh5.3.6/* libext/
cp -r oozie-4.0.0-cdh5.3.6/hadooplibs/hadooplib-2.5.0-mr1-cdh5.3.6.oozie-4.0.0-cdh5.3.6/* libext/
rm -rf /usr/local/oozie-4.0.0-cdh5.3.6/oozie-4.0.0-cdh5.3.6
b.将ext-2.2放到libext
cd /usr/local/oozie-4.0.0-cdh5.3.6/libext/
unzip ext-2.2.zip
c.将mysql.jar放到libext
cd /usr/local/oozie-4.0.0-cdh5.3.6/libext
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.49.tar.gz
tar -xzvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar /usr/local/oozie-4.0.0-cdh5.3.6/libext/
d.配置数据库
a.配置oozie-site.xml
<property>
<name>oozie.service.JPAService.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.url</name>
<value>jdbc:mysql://localhost:3306/oozie</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.username</name>
<value>oozie</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.password</name>
<value>123456</value>
</property>
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop</value>
</property>
b.创建数据库
chmod 777 /usr/local/oozie-4.0.0-cdh5.3.6/bin/ooziedb.sh
bin/ooziedb.sh create -sqlfile oozie.sql -run --创建好oozie.sql
bin/ooziedb.sh create -sqlfile oozie.sql -run DB Connection --创建好oozie.sql
e.启动准备
a.上传oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz 文件到 HDFS
不要使用 Hadoop 自带的上传put命令, 而是使用 Oozie 提供的专有上传命令
cd /usr/local/oozie-4.0.0-cdh5.3.6/
chmod 777 /usr/local/oozie-4.0.0-cdh5.3.6/bin/oozie-setup.sh
bin/oozie-setup.sh sharelib create -fs hdfs://192.168.185.150:9000 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz
hadoop fs -ls /user/root/share/lib/
b.创建war包
chmod 777 /usr/local/oozie-4.0.0-cdh5.3.6/bin
cd /usr/local/oozie-4.0.0-cdh5.3.6/
bin/oozie-setup.sh prepare-war
f.启动
a.权限
chmod 777 -R /usr/local/oozie-4.0.0-cdh5.3.6/bin/
chmod 777 -R /usr/local/oozie-4.0.0-cdh5.3.6/oozie-server/bin/
chmod 777 -R /usr/local/oozie-4.0.0-cdh5.3.6/oozie-server/conf/
b.启动
/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh start --守护进程
/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh stop --守护进程
/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozied.sh run --前台运行
/usr/local/oozie-4.0.0-cdh5.3.6/bin/oozie admin -oozie http://localhost:11000/oozie -status --状态
c.访问
http://192.168.185.150:11000/oozie/
5.8 sqoop-1.4.7
00.安装
a.下载
cd /usr/local/
wget https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -xzvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
cp /usr/local/oozie-4.0.0-cdh5.3.6/libext/mysql-connector-java-5.1.49.jar /usr/local/sqoop/lib/
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置
cd /usr/local/sqoop/conf/
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
-----------------------------------------------------------------------------------------------------
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-2.7.7
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export ZOOCFGDIR=/usr/local/zookeeper/zookeeper-3.4.10/conf
d.报错
问题:
[root@master sqoop]# sqoop version
Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
解决:
vi /usr/local/hbase/hbase-2.1.1/bin/hbase 修改如下内容
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/usr/local/hbase/hbase-2.1.1/lib/*
e.验证
sqoop version
f.报错
[root@master bin]# sqoop version
Warning: /usr/local/sqoop/sqoop-1.4.7/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.7/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Error: Could not find or load main class org.apache.sqoop.Sqoop
-----------------------------------------------------------------------------------------------------
WARN警告提示,可以不必理会
5.9 impala-4.3.0
00.前提
a.前置安装
hadoop, hive
b.CDP:数据保护与管理
CDP(Cloud Data Protection)是一种针对企业数据保护和管理的平台。它利用云端技术,提供了全面的数据备份、恢复和管理的解决方案。CDP的优点包括:
数据备份与恢复:CDP提供了快速、可靠的数据备份和恢复功能,确保企业数据的安全性和完整性。
数据管理:CDP具备强大的数据管理能力,可以轻松管理企业数据的存储、备份和恢复过程。
云端集成:CDP与各种云服务提供商集成,方便企业将数据备份到云端或从云端恢复数据。
c.CDH:Cloudera的Hadoop发行版
CDH(Cloudera’s Distribution, including Apache Hadoop)是由Cloudera公司发行的一种Hadoop发行版。它提供了一个全面的大数据解决方案,包括数据存储、处理和分析等功能。CDH的优点包括:
稳定性:CDH经过多年的开发和优化,具有很高的稳定性和可靠性,能够满足企业级应用的需求。
安全性:CDH提供了完善的数据安全保护机制,确保企业数据的安全性和隐私性。
社区支持:Cloudera作为Hadoop领域的领军企业,拥有庞大的用户社区和丰富的生态系统,为企业提供全方位的支持服务。
d.HDP:Hortonworks的数据平台
HDP(Hortonworks Data Platform)是一种基于Apache Hadoop的数据平台。它为企业提供了大数据存储、处理和分析的一体化解决方案。HDP的优点包括:
开放性:HDP基于Apache开源技术构建,确保了平台的开放性和兼容性,方便企业集成各种不同的数据源和工具。
性能优化:HDP针对企业级应用进行了性能优化,可以快速处理大量数据,满足实时分析的需求。
生态系统:Hortonworks与众多合作伙伴共同构建了一个庞大的生态系统,为企业提供丰富的应用和工具支持。
e.总结
CDP专注于数据保护与管理,为企业提供可靠的数据备份和恢复解决方案;
CDH作为Cloudera的发行版,具有稳定性和安全性等方面的优势;
而HDP则注重开放性、性能优化和生态系统建设。
01.介绍
a.概述
Impala直接对存储在HDFS、HBase或Amazon Simple Storage Service (S3)中的Apache Hadoop数据提供快速的交互式SQL查询。除了使用相同的统一存储平台外,Impala还使用了
与Apache Hive相同的元数据、SQL语法(Hive SQL)、ODBC驱动程序和用户界面(色调中的Impala查询UI)。
这为实时或面向批处理的查询提供了一个熟悉的、统一的平台。
Impala是大数据查询工具的补充。Impala不会替代构建在MapReduce上的批处理框架,比如Hive。Hive和其他构建在MapReduce上的框架最适合长时间运行的批处理作业,比如那些涉及提取、转换和加载(ETL)类型作业的批处理。
b.优点
1.数据科学家和分析师已经熟悉的SQL接口。
2.能够在Apache Hadoop中查询大量数据(“大数据”)。
3.在集群环境中使用分布式查询,方便扩展和利用具有成本效益的商品硬件。
4.能够在不同的组件之间共享数据文件,而不需要复制或导出/导入步骤;例如,用Pig来写,用Hive来转换,用Impala来查询。Impala可以读写Hive表,支持使用Impala对hiveproduced数据进行分析的简单数据交换。
5.单一系统的大数据处理和分析,因此客户可以避免昂贵的建模和ETL只是为了分析。
c.缺点
1.基于内存计算,对内存依赖性较大
2.改用C++编写,意味着维护难度增大
3.基于hive,与hive共存亡,紧耦合
4.稳定性不如hive,但不存在数据丢失的情况
d.impala和Hive的关系
impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,
意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。
所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务。
e.Impala解决方案由以下组件组成:
客户端 —— 包括Hue、ODBC客户端、JDBC客户端和Impala Shell在内的实体都可以与Impala进行交互。这些接口通常用于发出查询或完成管理任务,比如连接到Impala。
Hive Metastore —— 存储信息的数据可用的Impala。例如,metastore让Impala知道哪些数据库是可用的,以及这些数据库的结构是什么。当您通过Impala SQL语句创建、删除和更改模式对象、将数据加载到表中等等时,相关的元数据更改将通过Impala 1.2中引入的专用目录服务自动广播到所有Impala节点。
Impala —— 这个进程在数据节点上运行,协调和执行查询。Impala的每个实例都可以接收、计划和协调来自Impala客户端的查询。查询分布在Impala节点中,这些节点充当工作人员,执行并行查询片段。
HBase和HDFS —— 用于查询数据的存储。
f.使用Impala执行的查询处理如下
1.用户应用程序通过ODBC或JDBC向Impala发送SQL查询,后者提供了标准化的查询接口。用户应用程序可以连接到集群中的任何impalad。这个impalad将成为查询的协调器。
2.Impala解析查询并分析它,以确定需要由集群中的impalad实例执行哪些任务。计划执行以获得最佳效率。本地impalad实例可以访问HDFS和HBase等服务来提供数据。
3.每个impalad将数据返回给协调impalad,协调impalad将这些结果发送给客户机。
02.安装impala(tar.gz二进制包)(废)
a.下载
cd /usr/local/
wget https://archive.apache.org/dist/impala/3.4.0/apache-impala-3.4.0.tar.gz
tar -xzvf apache-impala-3.4.0.tar.gz
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/
export IMPALA_HOME=/usr/local/apache-impala-3.4.0
export PATH=$PATH:$IMPALA_HOME/bin:$IMPALA_HOME/bin:HADOOP_CONF_DIR
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.方式1:删除fe/src/test/resources目录下的文件,并将集群的配置文件到此目录
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/slaves /usr/local/apache-impala-3.4.0/fe/src/test/resources/slaves
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh /usr/local/apache-impala-3.4.0/fe/src/test/resources/hadoop-env.sh
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-env.sh /usr/local/apache-impala-3.4.0/fe/src/test/resources/yarn-env.sh
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml /usr/local/apache-impala-3.4.0/fe/src/test/resources/core-site.xml
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml /usr/local/apache-impala-3.4.0/fe/src/test/resources/hdfs-site.xml
cp /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml /usr/local/apache-impala-3.4.0/fe/src/test/resources/yarn-site.xml
-----------------------------------------------------------------------------------------------------
scp -r /usr/local/apache-impala-3.4.0 root@192.168.185.151:/usr/local/apache-impala-3.4.0
scp -r /usr/local/apache-impala-3.4.0 root@192.168.185.152:/usr/local/apache-impala-3.4.0
d.方式2:conf
conf/impala-conf.sh
IMPALA_HOME=<Impala软件包解压缩后的目录>
IMPALA_LOG_DIR=<Impala日志文件存放目录>
IMPALA_STATE_STORE_HOST=<Impala StateStore的主机名或IP地址>
IMPALA_STATE_STORE_PORT=<Impala StateStore的端口号>
IMPALA_SERVER_HOST=<Impala Daemon的主机名或IP地址>
IMPALA_SERVER_PORT=<Impala Daemon的端口号>
-----------------------------------------------------------------------------------------------------
conf/impala-shell.sh
IMPALA_HOME=<Impala软件包解压缩后的目录>
IMPALA_SERVER=<Impala Daemon的主机名或IP地址>
IMPALA_PORT=<Impala Daemon的端口号>
---------------------------------------------------------------------------------------
conf/hdfs-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://<Hive Metastore的主机名或IP地址>:9083</value>
</property>
e.方式3:编译
yum install -y gcc-c++ cmake make zlib-devel bzip2-devel openssl-devel libxml2-devel boost-devel snappy-devel lz4-devel python3
-----------------------------------------------------------------------------------------------------
# Impala 需要 CMake 3.2.3 或更高版本,而你当前的版本是 2.8.12.2
sudo yum remove cmake
# 下载 CMake 最新版本的源码
wget https://github.com/Kitware/CMake/releases/download/v3.25.0/cmake-3.25.0.tar.gz
# 解压下载的文件
tar -xzvf cmake-3.25.0.tar.gz
cd cmake-3.25.0
# 编译和安装 CMake
./bootstrap
make
sudo make install
# 验证
cmake --version
-----------------------------------------------------------------------------------------------------
cd /usr/local/apache-impala-3.4.0
mkdir build
cd /usr/local/apache-impala-3.4.0/build
cmake ..
make
-----------------------------------------------------------------------------------------------------
./bin/catalogd --启动 Catalog 服务
./bin/statestored --启动 State Store 服务
./bin/impalad --启动 Impala Daemon
f.验证
/usr/local/apache-impala-3.4.0/bin/start-daemon.sh -statestored
03.安装impala(挂载磁盘,自定义yum源)
a.准备
a.说明
由于impala没有提供tar包进行安装,只提供了rpm包。因此在安装impala的时候,需要使用rpm包来进行安装。
rpm包只有cloudera公司提供了,所以去cloudera公司网站进行下载rpm包即可。
-------------------------------------------------------------------------------------------------
但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,
也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。这里就选择制作本地的yum源来进行安装。
b.下载到所有的rpm包
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
c.虚拟机新增磁盘
略
b.配置本地yum源
a.上传安装包解压
cd /cloudera_data
tar -zxvf cdh5.14.0-centos6.tar.gz
b.配置本地yum源信息
a.安装Apache Server服务器
yum -y install httpd
service httpd start
chkconfig httpd on
b.在每个节点上下载nc服务
yum -y install nc
c.配置本地yum源的文件
cd /etc/yum.repos.d
[localimp]
name=localimp
baseurl=http://node-3/cdh5.14.0/
gpgcheck=0
enabled=1
d.创建apache httpd的读取链接
ln -s /cloudera_data/cdh/5.14.0 /var/www/html/cdh5.14.0
e.确保linux的Selinux关闭
临时关闭:
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
---------------------------------------------------------------------------------------------
永久关闭:
[root@localhost ~]# vim /etc/sysconfig/selinux
SELINUX=enforcing 改为 SELINUX=disabled
重启服务reboot
f.通过浏览器访问本地yum源,如果出现下述页面则成功
http://192.168.100.100/cdh5.14.0/
g.将本地yum源配置文件localimp.repo发放到所有需要安装impala的节点。
cd /etc/yum.repos.d/
scp localimp.repo node-2:$PWD
scp localimp.repo node-3:$PWD
c.安装Impala
a.主节点安装
yum install -y impala impala-server impala-state-store impala-catalog impala-shell
b.从节点安装
yum install -y impala-server
d.修改Hadoop、Hive配置
a.修改hive配置
vi /export/servers/hive/conf/hive-site.xml
-------------------------------------------------------------------------------------------------
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node-1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 绑定运行hiveServer2的主机host,默认localhost -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node-1</value>
</property>
<!-- 指定hive metastore服务请求的uri地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node-1:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
</configuration>
-------------------------------------------------------------------------------------------------
scp
b.修改hadoop配置
所有节点创建下述文件夹
mkdir -p /var/run/hdfs-sockets
-------------------------------------------------------------------------------------------------
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim etc/hadoop/hdfs-site.xml
-------------------------------------------------------------------------------------------------
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
-------------------------------------------------------------------------------------------------
vim etc/hadoop/hdfs-site.xml
vim localimp.repo
-------------------------------------------------------------------------------------------------
cd /export/servers/hadoop-2.7.5/etc/hadoop
scp -r hdfs-site.xml node-2:$PWD
scp -r hdfs-site.xml node-3:$PWD
-------------------------------------------------------------------------------------------------
chown -R hadoop:hadoop /var/run/hdfs-sockets/
c.重启hadoop、hive
start-hadoop
start-hive
d.复制hadoop、hive配置文件
cp -r /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /export/servers/hive/conf/hive-site.xml /etc/impala/conf/hive-site.xml
e.修改impala配置
a.修改impala默认配置
vim /etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=node-3
IMPALA_STATE_STORE_HOST=node-3
b.添加mysql驱动
通过配置/etc/default/impala中可以发现已经指定了mysql驱动的位置名字
ln -s /export/servers/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
c.修改bigtop配置
vi /etc/default/bigtop-utils
export JAVA_HOME=/export/servers/jdk1.8.0_65
f.运行
a.主节点
service impala-state-store start
service impala-catalog start
service impala-server start
b.从节点
service impala-server start
c.进程
ps -ef | grep impala
d.页面
http://192.168.185.150:25000/ --impalad管理界面
http://192.168.185.150:25010/ --statestored管理界面
5.10 phoenix-5.1.3
00.前提
hadoop, habse
01.介绍
a.概述
Phoenix是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据
它相当于一个Java中间件,提供jdbc连接,操作hbase数据表。Phoenix是一个HBase的开源SQL引擎。
你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
Phoenix的团队用了一句话概括Phoenix:“We put the SQL back in NoSQL” 意思是:我们把SQL又放回NoSQL去了!
这边说的NoSQL专指HBase,意思是可以用SQL语句来查询Hbase,你可能会说:“Hive和Impala也可以啊!”。
但是Hive和Impala还可以查询文本文件,Phoenix的特点就是,它只能查Hbase,别的类型都不支持!
但是也因为这种专一的态度,让Phoenix在Hbase上查询的性能超过了Hive和Impala!
b.概念2
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。
在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,
HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,
即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。
同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
c.概念3
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,
通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,
可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase
不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
d.概念4
Apache Phoenix是构建在HBase之上的关系型数据库层,作为内嵌的客户端JDBC驱动用以对HBase中的数据进行低延迟访问。
Apache Phoenix会将用户编写的sql查询编译为一系列的scan操作,最终产生通用的JDBC结果集返回给客户端。
数据表的元数据存储在HBase的表中被会标记版本号,所以进行查询的时候会自动选择正确的schema。
直接使用HBase的API,结合协处理器(coprocessor)和自定义的过滤器的话,小范围的查询在毫秒级响应,
千万数据的话响应速度为秒级。
02.安装phoenix(tar.gz二进制包)
a.下载
cd /usr/local/
wget https://dlcdn.apache.org/phoenix/phoenix-5.1.3/phoenix-hbase-2.1-5.1.3-bin.tar.gz
tar -xzvf phoenix-hbase-2.1-5.1.3-bin.tar.gz
mv phoenix-hbase-2.1-5.1.3-bin phoenix
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export PHOENIX_HOME=/usr/local/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$PHOENIX_HOME/bin:$HADOOP_OPTS
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置
a.把客户端和服务端的Jar包给每一个Hbase的lib目录下面
cd /usr/local/phoenix/
scp -r phoenix-server-hbase-2.1-5.1.3.jar root@192.168.185.150:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-server-hbase-2.1-5.1.3.jar root@192.168.185.151:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-server-hbase-2.1-5.1.3.jar root@192.168.185.152:/usr/local/hbase/hbase-2.1.1/lib
-------------------------------------------------------------------------------------------------
废弃
scp -r phoenix-pherf-5.1.3.jar root@192.168.185.150:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-pherf-5.1.3.jar root@192.168.185.151:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-pherf-5.1.3.jar root@192.168.185.152:/usr/local/hbase/hbase-2.1.1/lib
-------------------------------------------------------------------------------------------------
废弃
scp -r phoenix-client-hbase-2.1-5.1.3.jar root@192.168.185.150:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-client-hbase-2.1-5.1.3.jar root@192.168.185.151:/usr/local/hbase/hbase-2.1.1/lib
scp -r phoenix-client-hbase-2.1-5.1.3.jar root@192.168.185.152:/usr/local/hbase/hbase-2.1.1/lib
-------------------------------------------------------------------------------------------------
废弃
rm -i /usr/local/hbase/hbase-2.1.1/lib/phoenix-client-hbase-2.1-5.1.3.jar
rm -i /usr/local/hbase/hbase-2.1.1/lib/phoenix-server-hbase-2.1-5.1.3.jar
-------------------------------------------------------------------------------------------------
废弃
cp -r phoenix-client-embedded-hbase-2.1-5.1.3.jar /usr/local/hbase/hbase-2.1.1/lib \
&& cp -r phoenix-client-hbase-2.1-5.1.3.jar /usr/local/hbase/hbase-2.1.1/lib \
&& cp -r phoenix-pherf-5.1.3.jar /usr/local/hbase/hbase-2.1.1/lib \
&& cp -r phoenix-server-hbase-2.1-5.1.3.jar /usr/local/hbase/hbase-2.1.1/lib
b.备份,并将hbase进行替换
cp -r /usr/local/phoenix/bin/hbase-site.xml /usr/local/phoenix/bin/hbase-site-bak.xml
cp -r /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml /usr/local/phoenix/bin/hbase-site.xml
c.将Hadoop的HDFS配置放入Phoenix
cp -r /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml /usr/local/phoenix/bin/core-site.xml
cp -r /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml /usr/local/phoenix/bin/hdfs-site.xml
-------------------------------------------------------------------------------------------------
mkdir /usr/local/phoenix/conf(废弃)
cp -r /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml /usr/local/phoenix/conf/core-site.xml
cp -r /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml /usr/local/phoenix/conf/hdfs-site.xml
d.将/usr/local/phoenix分发到slave1、slave2(无需搭建集群)(废弃)
scp -r /usr/local/phoenix root@192.168.185.151:/usr/local/phoenix
scp -r /usr/local/phoenix root@192.168.185.152:/usr/local/phoenix
e.将/usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml同步(废弃)
scp -r /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml root@192.168.185.151:/usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
scp -r /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml root@192.168.185.152:/usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
d.DataGrip连接Phoenix
a.日志
vi /usr/local/phoenix/bin/log4j.properties
psql.root.logger=DEBUG,console,DRFA
log4j.threshold=DEBUG
b.DataGrip中jar包
phoenix-client-hbase-2.1-5.1.3.jar
phoenix-client-hbase-2.4-5.1.3.jar
c.连接
jdbc:phoenix:master:2181
jdbc:phoenix:slave1:2181
jdbc:phoenix:slave2:2181
-------------------------------------------------------------------------------------------------
jdbc:phoenix:master
jdbc:phoenix:master:2181
jdbc:phoenix:master:2181:/hbase
jdbc:phoenix:master,slave1,slave2:2181:/hbase
-------------------------------------------------------------------------------------------------
jdbc:phoenix:192.168.185.150
jdbc:phoenix:192.168.185.150:2181
jdbc:phoenix:192.168.185.150:2181:/hbase
d.报错
Could not load/instantiate class org.apache.phoenix.query.DefaultGuidePostsCacheFactory.
-------------------------------------------------------------------------------------------------
服务端:
vi /usr/local/phoenix/bin/hbase-site.xml
vi /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
-------------------------------------------------------------------------------------------------
客户端:
phoenix -> 高级
phoenix.schema.isNamespaceMappingEnabled true
phoenix.schema.mapSystemTablesToNamespace true
e.验证
start-hadoop-cluster
start-zookeeper-cluster
start-hbase-cluster
-----------------------------------------------------------------------------------------------------
chmod 777 /usr/local/phoenix/bin/psql.py
chmod 777 /usr/local/phoenix/bin/sqlline.py
-----------------------------------------------------------------------------------------------------
/usr/local/phoenix/bin/sqlline.py master:2181
/usr/local/phoenix/bin/sqlline.py slave1:2181
/usr/local/phoenix/bin/sqlline.py slave2:2181
/usr/local/phoenix/bin/sqlline.py master,slave1,slave2:2181
-----------------------------------------------------------------------------------------------------
select 0
!tables
!quit
99.开启二级索引
a.报错
0: jdbc:phoenix:master:2181> CREATE INDEX "idx_name" ON "stu" ("name");
Error: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in the hbase-sites.xml of every region server. tableName=idx_name (state=42Y88,code=1029)
java.sql.SQLException: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in the hbase-sites.xml of every region server. tableName=idx_name
at org.apache.phoenix.exception.SQLExceptionCode$Factory$1.newException(SQLExceptionCode.java:607)
at org.apache.phoenix.exception.SQLExceptionInfo.buildException(SQLExceptionInfo.java:217)
at org.apache.phoenix.schema.MetaDataClient.createIndex(MetaDataClient.java:1557)
at org.apache.phoenix.compile.CreateIndexCompiler$1.execute(CreateIndexCompiler.java:85)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:443)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:425)
at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:424)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:412)
at org.apache.phoenix.jdbc.PhoenixStatement.execute(PhoenixStatement.java:2009)
at sqlline.Commands.executeSingleQuery(Commands.java:1054)
at sqlline.Commands.execute(Commands.java:1003)
at sqlline.Commands.sql(Commands.java:967)
at sqlline.SqlLine.dispatch(SqlLine.java:734)
at sqlline.SqlLine.begin(SqlLine.java:541)
at sqlline.SqlLine.start(SqlLine.java:267)
at sqlline.SqlLine.main(SqlLine.java:206)
b.hbase-1.3.1
a.Hregionserver节点的hbase-site.xml
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
</property>
b.Hbase中Hmaster节点的hbase-site.xml中
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>
c.hbase-2.4.17
a.Hregionserver节点的hbase-site.xml
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
b.Hbase中Hmaster节点的hbase-site.xml中
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
d.同步
a.hbase
cd /usr/local/hbase/hbase-2.4.17/conf
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml
b.phoenix
cd /usr/local/phoenix/phoenix-5.1.3/bin/
vi hbase-site.xml
99.常见问题
a.报错1
a.问题
[root@master phoenix]# /usr/local/phoenix/bin/sqlline.py master:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect -p driver org.apache.phoenix.jdbc.PhoenixDriver -p user "none" -p password "none" "jdbc:phoenix:master:2181"
Connecting to jdbc:phoenix:master:2181
24/08/30 18:05:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
b.解决
vi /etc/profile
-------------------------------------------------------------------------------------------------
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
-------------------------------------------------------------------------------------------------
source /etc/profile
c.测试
hdfs dfs -ls .
hadoop checknative -a
b.报错2
a.问题
bhbase6: Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/local/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
bhbase6: It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
bhbase2: Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/local/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
bhbase2: It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
bhbase5: Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/local/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
bhbase5: It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
-------------------------------------------------------------------------------------------------
出现这个问题基本都是在64位操作系统上,这主要是因为Hadoop官网上下载的本地库文件都是基于32位系统编译的,如果在64位系统上运行会出现这个问题错误。
b.解决(记得还原回去)
百度网盘:hadoop-2.7.7-native.zip
将native移动到/usr/local/hadoop/hadoop-2.7.7/lib/native/
chmod 777 -R /usr/local/hadoop/hadoop-2.7.7/lib/native/
-------------------------------------------------------------------------------------------------
vi /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
-------------------------------------------------------------------------------------------------
vi /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-env.sh
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
c.测试
hdfs dfs -ls .
hadoop checknative -a
c.报错3
a.问题
phoenix进不去sqlline.py,一直卡住(不报错)
可能是hbase meta信息不一致导致
b.解决
zkCli.sh
ls /
deleteall /hbase
6 附:3.x系列
01.快速开始
a.开启权限,追加内容到rc.local
chmod 777 /tmp
chmod +x /etc/rc.d/rc.local
hdfs dfs -chmod 777 /tmp
hadoop fs -chmod -R 777 /tmp/hadoop-yarn
hadoop fs -chmod -R 777 /workspace
-----------------------------------------------------------------------------------------------------
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
unset HADOOP_CLIENT_OPTS
-----------------------------------------------------------------------------------------------------
start-hadoop-cluster
start-hive-metastore
start-hive-server
start-zookeeper-cluster && status-zookeeper-cluster
start-hbase-cluster
--------------------------------------------------
start-kafka-cluster
start-spark
start-flink
start-flume
start-kafka-ui
start-hue
start-oozie
-----------------------------------------------------------------------------------------------------
stop-hadoop-cluster
stop-hive-cluster
stop-zookeeper-cluster
stop-hbase-cluster
--------------------------------------------------
stop-kafka-cluster
stop-spark
stop-flink
stop-flume
stop-kafka-ui
stop-hue
stop-oozie
-----------------------------------------------------------------------------------------------------
status-bigdata-all
status-zookeeper-cluster
-----------------------------------------------------------------------------------------------------
sqlline.py master:2181
sqlline.py master,slave1,slave2:2181
-----------------------------------------------------------------------------------------------------
netstat -lnpt | grep 9870
ps -ef | grep hue
-----------------------------------------------------------------------------------------------------
rm -rf /usr/local/hue
rm -rf /usr/local/hue/atp.txt
c.命令别名
vi ~/.bashrc
-----------------------------------------------------------------------------------------------------
alias start-dfs='/usr/local/hadoop/hadoop-3.3.6/sbin/start-dfs.sh'
alias start-yarn='/usr/local/hadoop/hadoop-3.3.6/sbin/start-yarn.sh'
alias start-jobhistory='/usr/local/hadoop/hadoop-3.3.6/sbin/mr-jobhistory-daemon.sh start historyserver'
alias start-hadoop-cluster='start-dfs && start-yarn && hdfs dfsadmin -safemode leave'
alias start-hive-metastore="nohup /usr/local/hive/hive-3.1.3/bin/hive --service metastore > /usr/local/hive/logs/metastore.log 2>&1 &"
alias start-hive-server="nohup /usr/local/hive/hive-3.1.3/bin/hive --service hiveserver2 > /usr/local/hive/logs/hiveserver2.log 2>&1 &"
alias start-zookeeper='/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh start'
alias start-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.7.1/bin/zookeeper-cluster.sh start'
alias start-hbase-basic='/usr/local/hbase/hbase-2.4.17/bin/start-hbase.sh'
alias start-hbase-thrift1="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start thrift --infoport 9095 -p 9090"
alias start-hbase-thrift2="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start thrift2 --infoport 9095 -p 9090"
alias start-hbase-rest="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start rest"
alias start-hbase-cluster='start-hbase-basic && start-hbase-thrift2 && start-hbase-rest'
alias start-kafka='/usr/local/kafka/kafka-3.4.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-3.4.0/config/server.properties'
alias start-kafka-cluster='/usr/local/kafka/kafka-3.4.0/bin//kafka-cluster.sh start'
alias start-spark='/usr/local/spark/spark-3.3.2/sbin/start-all.sh'
alias start-flink='/usr/local/flink/flink-1.18.1/bin/start-cluster.sh'
alias start-flume='sh /usr/local/flume/flume-1.11.0/bin/flume.sh start'
alias start-kafka-ui="cd /usr/local/kafka-console-ui && sh bin/start.sh"
alias start-hue="nohup /usr/local/hue/hue-4.10.0/build/env/bin/supervisor >> /usr/local/hue/hue-4.10.0/logs/hue.log 2>&1 &"
alias start-oozie="/usr/local/oozie/oozie-5.2.1/bin/oozied.sh start"
alias stop-dfs='/usr/local/hadoop/hadoop-3.3.6/sbin/stop-dfs.sh'
alias stop-yarn='/usr/local/hadoop/hadoop-3.3.6/sbin/stop-yarn.sh'
alias stop-jobhistory='/usr/local/hadoop/hadoop-3.3.6/sbin/mr-jobhistory-daemon.sh stop historyserver'
alias stop-hadoop-cluster='stop-dfs && stop-yarn && stop-jobhistory'
alias stop-hive-cluster="jps | grep RunJar | awk '{print $1}' | xargs -r kill -9"
alias stop-zookeeper='/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh stop'
alias stop-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.7.1/bin/zookeeper-cluster.sh stop'
alias stop-hbase-basic='/usr/local/hbase/hbase-2.4.17/bin/stop-hbase.sh'
alias stop-hbase-thrift1="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop thrift --infoport 9095 -p 9090"
alias stop-hbase-thrift2="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop thrift2 --infoport 9095 -p 9090"
alias stop-hbase-rest="/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop rest"
alias stop-hbase-cluster='stop-hbase-basic && stop-hbase-thrift2 && stop-hbase-rest'
alias stop-kafka='/usr/local/kafka/kafka-3.4.0/bin/kafka-server-stop.sh'
alias stop-kafka-cluster='/usr/local/kafka/kafka-3.4.0/bin//kafka-cluster.sh stop'
alias stop-spark='/usr/local/spark/spark-3.3.2/sbin/stop-all.sh'
alias stop-flink='/usr/local/flink/flink-1.18.1/bin/stop-cluster.sh'
alias stop-flume='sh /usr/local/flume/flume-1.11.0/bin/flume.sh stop'
alias stop-kafka-ui="cd /usr/local/kafka-console-ui && sh bin/shutdown.sh"
alias stop-hue="ps -ef | grep hue | grep -v grep | awk '{print $2}' | xargs kill -9"
alias stop-oozie="/usr/local/oozie/oozie-5.2.1/bin/oozied.sh stop"
alias status-zookeeper-cluster='/usr/local/zookeeper/zookeeper-3.7.1/bin/zookeeper-cluster.sh status'
alias start-bigdata1="/usr/local/troyekk/start-bigdata1.sh"
alias start-bigdata2="/usr/local/troyekk/start-bigdata2.sh"
alias start-bigdata-all="/usr/local/troyekk/start-bigdata-all.sh"
alias stop-bigdata1="/usr/local/troyekk/stop-bigdata1.sh"
alias stop-bigdata2="/usr/local/troyekk/stop-bigdata2.sh"
alias stop-bigdata-all="/usr/local/troyekk/stop-bigdata-all.sh"
alias status-bigdata-all="/usr/local/troyekk/status-bigdata-all.sh"
-----------------------------------------------------------------------------------------------------
source ~/.bashrc
scp /root/.bashrc root@192.168.185.151:/root/.bashrc && ssh root@192.168.185.151 "source ~/.bashrc"
scp /root/.bashrc root@192.168.185.152:/root/.bashrc && ssh root@192.168.185.152 "source ~/.bashrc"
c.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.12.0
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.6
export HIVE_HOME=/usr/local/hive/hive-3.1.3
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.7.1
export KAFKA_HOME=/usr/local/kafka/kafka-3.4.0
export HBASE_HOME=/usr/local/hbase/hbase-2.4.17
export FLUME_HOME=/usr/local/flume/flume-1.11.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export SPARK_HOME=/usr/local/spark/spark-3.3.2
export STORM_HOME=/usr/local/storm/apache-storm-2.4.0
export NODE_HOME=/usr/local/node
export MAVEN_HOME=/usr/local/maven
export PIG_HOME=/usr/local/pig/pig-0.17.0
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
export OOZIE_HOME=/usr/local/oozie/oozie-5.2.1
export OOZIE_CONFIG=/usr/local/oozie/oozie-5.2.1/conf
export OOZIE_URL=http://192.168.185.150:11000/oozie
export SQOOP_HOME=/usr/local/sqoop
export PHOENIX_HOME=/usr/local/phoenix/phoenix-5.2.0
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin:$SPARK_HOME/bin:$STORM_HOME/bin:$NODE_HOME/bin:$NODE_HOME/node-global/bin:$MAVEN_HOME/bin:$PIG_HOME/bin:$PIG_HOME/conf:$OOZIE_HOME/bin:$SQOOP_HOME/bin:$PHOENIX_HOME/bin:$HADOOP_OPTS
-----------------------------------------------------------------------------------------------------
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.12.0
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.6
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.7.1
export KAFKA_HOME=/usr/local/kafka/kafka-3.4.0
export SPARK_HOME=/usr/local/spark/spark-3.3.2
export HBASE_HOME=/usr/local/hbase/hbase-2.4.17
export STORM_HOME=/usr/local/storm/apache-storm-2.4.0
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HBASE_HOME/bin:$STORM_HOME/bin
-----------------------------------------------------------------------------------------------------
source /etc/profile
d.启动情况
[root@master ~]# jps
1424 NameNode --Hadoop
1279 DataNode --Hadoop
1385 NodeManager --Hadoop
1774 ResourceManager --Hadoop
1477 SecondaryNameNode --Hadoop
---------------------------------------------------------------------------
2113 QuorumPeerMain --ZooKeeper
---------------------------------------------------------------------------
2148 Kafka --Kafka
---------------------------------------------------------------------------
2502 Application --Flume
---------------------------------------------------------------------------
2503 RunJar --Hive(正常情况会出现两个RunJar)
---------------------------------------------------------------------------
主节点上显示:HMaster / 子节点上显示:HRegionServer --Hbase
主节点上显示:ThriftServer --Hbase thrift
主节点上显示:RESTServer --Hbase rest
---------------------------------------------------------------------------
正确结果:显示:Master、Worker --Spark
---------------------------------------------------------------------------
正确结果:显示:TaskManagerRunner --Flink
-----------------------------------------------------------------------------------------------------
正确结果:显示:Bootstrap --Oozie
正确结果:显示:SqlLine --Phoenix
-------------------------------------------------------------------------------------------------
[root@master ~]# ps aux | grep kafka
root 2819 0.0 0.0 112660 972 pts/1 R+ 17:55 0:00 grep --color=auto kafka
[root@master ~]# jps kill 1424 --停止NameNode
02.环境配置
a.网络
a.win10
IP地址 192.168.185.1
子网掩码 255.255.255.0
默认网关 192.168.185.2
b.vmware
子网IP 192.168.185.0
子网掩码 255.255.255.0
网关IP 192.168.185.2
范围IP 192.168.185.128 ~ 192.168.185.254
c.host
C:\Windows\System32\drivers\etc\hosts
192.168.185.150 master
192.168.185.151 slave1
192.168.185.152 slave2
192.168.185.153 slave3
d.测试
ping 192.168.185.150
ping 192.168.185.151
ping 192.168.185.152
ping 192.168.185.153
ssh root@192.168.185.150 --免密钥访问
e.登录
root
123456
建议每个节点别低于1G内存,默认分配2G
b.Hadoop(hdfs+mapreduce)
/usr/local/hadoop/hadoop-2.7.7/sbin/start-dfs.sh --启动hdfs
/usr/local/hadoop/hadoop-2.7.7/sbin/start-yarn.sh --启动mapreduce
/usr/local/hadoop/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver --启动jobhistory
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/sbin/yarn-daemon.sh start resourcemanager --单独启动yarn
/usr/local/hadoop/hadoop-2.7.7/sbin/hadoop-daemon.sh start datanode --单独启动datanode
/usr/local/hadoop/hadoop-2.7.7/sbin/hadoop-daemon.sh start namenode --单独启动namenode
-----------------------------------------------------------------------------------------------------
http://192.168.185.150:50070/dfshealth.html --界面(hdfs)
http://192.168.185.150:8088/cluster --界面(yarn)
http://192.168.185.150:19888 --界面(jobhistory)
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
1968 ResourceManager
1591 NameNode
2522 Jps
1787 SecondaryNameNode
-----------------------------------------------------------------------------------------------------
jps | grep NodeManager
jps | grep SecondaryNameNode
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/bin/hdfs dfsadmin -report --hdfs状态
/usr/local/hadoop/hadoop-2.7.7/bin/yarn application -list --yarn状态(列出所有正在运行的应用程序)
/usr/local/hadoop/hadoop-2.7.7/bin/yarn node -list --yarn状态(列出所有YARN节点)
-----------------------------------------------------------------------------------------------------
org.apache.hadoop.security.AccessControlException --权限问题(关闭hdfs验证)
/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml --追加内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
-----------------------------------------------------------------------------------------------------
/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml --追加内容
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
c.Hive
mysql --进入mysql
create database if not exists hive_metadata;
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
flush privileges;
use hive_metadata;
exit
schematool -dbType mysql -initSchema --初始化
-----------------------------------------------------------------------------------------------------
mysql -u root
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY ''; --允许root用户远程连接
FLUSH PRIVILEGES;
-----------------------------------------------------------------------------------------------------
/usr/local/hive/hive-2.3.4/bin/hive --进入hive
-----------------------------------------------------------------------------------------------------
jdbc:hive2://192.168.185.150:10000
192.168.185.150
10000
hive
hive
-----------------------------------------------------------------------------------------------------
/usr/local/hive/hive-2.3.4/conf/hive-site.xml --修改内容
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
d.ZooKeeper
cd
/usr/local/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start --启动zookeeper
-----------------------------------------------------------------------------------------------------
bin/zkCli.sh
ls /
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
2555 QuorumPeerMain
-----------------------------------------------------------------------------------------------------
192.168.185.150
2181
e.Kafka
/usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-2.1.0/config/server.properties
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties &
nohup /usr/local/kafka/kafka-2.1.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties > /usr/local/kafka/kafka-2.1.0/logs/kafka.log 2>&1 &
-----------------------------------------------------------------------------------------------------
kafka-server-start.sh kafka启动程序
kafka-server-stop.sh kafka停止程序
kafka-topics.sh 创建topic程序
kafka-console-producer.sh 命令行模拟生产者生产消息数据程序
kafka-console-consumer.sh 命令行模拟消费者消费消息数据程序
-----------------------------------------------------------------------------------------------------
# ps aux | grep kafka --查看进程
root 2966 0.0 0.0 112660 972 pts/0 R+ 16:43 0:00 grep --color=auto kafka
f.Flume
nohup /usr/local/flume/flume-1.8.0/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/flume-1.8.0/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console &
-----------------------------------------------------------------------------------------------------
# ps aux | grep flume --查看进程
root 3368 0.0 0.0 112660 972 pts/0 R+ 16:50 0:00 grep --color=auto flume
g.Hbase
/usr/local/hbase/hbase-2.1.1/bin/start-hbase.sh --启动
netstat -lnpt | grep 8080
http://192.168.185.150:16010
http://192.168.185.151:16010
http://192.168.185.152:16010
-----------------------------------------------------------------------------------------------------
主备HMaster: 为了保证HBase的高可用性,HBase通常会配置多个HMaster(一个主HMaster和多个备HMaster)。如果主HMaster发生故障,备HMaster会自动接管。
RegionServer的分布式架构: HRegionServer通常是分布式部署的,多个RegionServer同时运行,以实现数据的高可用性和负载均衡。
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:主节点上显示:HMaster / 子节点上显示:HRegionServer
-----------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
报错:
[root@master sqoop]# hbase version
Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
解决:
vi /usr/local/hbase/hbase-2.1.1/bin/hbase 修改如下内容
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/usr/local/hbase/hbase-2.1.1/lib/*
h.Spark
/usr/local/spark/spark-2.4.0/sbin/start-all.sh --启动
-----------------------------------------------------------------------------------------------------
vi /usr/local/spark/spark-2.4.0/conf/spark-env.sh --追加内容
export SPARK_MASTER_WEBUI_PORT=8086
export SPARK_WORKER_WEBUI_PORT=8087
-----------------------------------------------------------------------------------------------------
http://192.168.185.150:8086 --spark(集群的整体信息和状态)
http://192.168.185.150:8087 --spark(应用程序的详细信息)
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:Master、Worker
i.Storm(先启动Zookeeper,三台都启动)
master(启动Nimbus和UI) /usr/local/storm/apache-storm-1.2.2/bin/storm nimbus >/usr/local/storm/apache-storm-1.2.2/logs/nimbus.out 2>&1 &
master(启动Nimbus和UI) /usr/local/storm/apache-storm-1.2.2/bin/storm ui >/usr/local/storm/apache-storm-1.2.2/logs/ui.out 2>&1 &
-----------------------------------------------------------------------------------------------------
slave1(启动Supervisor) /usr/local/storm/apache-storm-1.2.2/bin/storm supervisor >/usr/local/storm/apache-storm-1.2.2/logs/supervisor.out 2>&1 &
slave2(启动Supervisor) /usr/local/storm/apache-storm-1.2.2/bin/storm supervisor >/usr/local/storm/apache-storm-1.2.2/logs/supervisor.out 2>&1 &
-----------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:Nimbus、Supervisor
j.Flink
a.解压
cd /usr/local/flink
tar -xzf flink-1.18.1-bin-scala_2.12.tgz
b.配置集群
a.进入conf目录,修改flink-conf.yaml
cd /usr/flink/flink-1.18.0/conf/
vi flink-conf.yaml
# 部署Spark或Azkaban等应用,启动flink时发现默认端口8081被占用,于是得去更改默认端口
rest.port: 8089
# JobManager 节点地址
jobmanager.rpc.address: 192.168.185.150
jobmanager.bind-host: 0.0.0.0
rest.address: 192.168.185.150
rest.bind-address: 0.0.0.0
# Taskmanager节点地址,需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: 192.168.185.150
b.进入conf目录,修改workers
vi workers
192.168.185.150
192.168.185.151
192.168.185.152
c.进入conf目录,修改masters
vi masters
192.168.58.130:8081
d.将以上配置向集群其他节点同步,仅需要修改flink-conf.yaml中的taskmanager.host地址即可,修改为当前节点的IP地址
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.151:/usr/local/flink
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.152:/usr/local/flink
c.启动、停止、访问
/usr/local/flink/flink-1.18.1/bin/start-cluster.sh
/usr/local/flink/flink-1.18.1/bin/stop-cluster.sh
http://192.168.185.150:8089
-------------------------------------------------------------------------------------------------
# jps --查看节点信息
# 正确结果:显示:TaskManagerRunner
99.卸载2.x
a.master
rm -rf /usr/local/hadoop/hadoop-2.7.7
rm -rf /usr/local/hive/hive-2.3.4
rm -rf /usr/local/zookeeper/zookeeper-3.4.10
rm -rf /usr/local/kafka/kafka-2.1.0
rm -rf /usr/local/flume/flume-1.8.0
rm -rf /usr/local/hbase/hbase-2.1.1
rm -rf /usr/local/spark/spark-2.4.0
rm -rf /usr/local/storm/apache-storm-1.2.2
rm -rf /usr/local/flink/flink-1.18.1
rm -rf /usr/local/hue
rm -rf /usr/local/oozie-4.0.0-cdh5.3.6
rm -rf /usr/local/sqoop
rm -rf /usr/local/phoenix
rm -rf /usr/local/pig-0.16.0
rm -rf /usr/local/scala/scala-2.11.8
b.slave
rm -rf /usr/local/hadoop/hadoop-2.7.7
rm -rf /usr/local/zookeeper/zookeeper-3.4.10
rm -rf /usr/local/kafka/kafka-2.1.0
rm -rf /usr/local/hbase/hbase-2.1.1
rm -rf /usr/local/spark/spark-2.4.0
rm -rf /usr/local/storm/apache-storm-1.2.2
rm -rf /usr/local/flink/flink-1.18.1
rm -rf /usr/local/scala/scala-2.11.8
c.解压
tar -xzf flink-1.18.1-bin-scala_2.12.tgz
d.拷贝
scp -r /usr/local/hadoop/hadoop-3.3.6 root@192.168.185.151:/usr/local/hadoop/hadoop-3.3.6
scp -r /usr/local/zookeeper/zookeeper-3.7.1 root@192.168.185.151:/usr/local/zookeeper/zookeeper-3.7.1
scp -r /usr/local/kafka/kafka-3.4.0 root@192.168.185.151:/usr/local/kafka/kafka-3.4.0
scp -r /usr/local/hbase/hbase-2.4.17 root@192.168.185.151:/usr/local/hbase/hbase-2.4.17
scp -r /usr/local/spark/spark-3.3.2 root@192.168.185.151:/usr/local/spark/spark-3.3.2
scp -r /usr/local/storm/apache-storm-2.4.0 root@192.168.185.151:/usr/local/storm/apache-storm-2.4.0
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.151:/usr/local/flink/flink-1.18.1
scp -r /usr/local/scala/scala-2.12.0 root@192.168.185.151:/usr/local/scala/scala-2.12.0
-----------------------------------------------------------------------------------------------------
scp -r /usr/local/hadoop/hadoop-3.3.6 root@192.168.185.152:/usr/local/hadoop/hadoop-3.3.6
scp -r /usr/local/zookeeper/zookeeper-3.7.1 root@192.168.185.152:/usr/local/zookeeper/zookeeper-3.7.1
scp -r /usr/local/kafka/kafka-3.4.0 root@192.168.185.152:/usr/local/kafka/kafka-3.4.0
scp -r /usr/local/hbase/hbase-2.4.17 root@192.168.185.152:/usr/local/hbase/hbase-2.4.17
scp -r /usr/local/spark/spark-3.3.2 root@192.168.185.152:/usr/local/spark/spark-3.3.2
scp -r /usr/local/storm/apache-storm-2.4.0 root@192.168.185.152:/usr/local/storm/apache-storm-2.4.0
scp -r /usr/local/flink/flink-1.18.1 root@192.168.185.152:/usr/local/flink/flink-1.18.1
scp -r /usr/local/scala/scala-2.12.0 root@192.168.185.152:/usr/local/scala/scala-2.12.0
6.1 hadoop-3.3.6
00.使用
a.拷贝
scp -r /usr/local/hadoop/hadoop-3.3.6/etc/hadoop root@192.168.185.151:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop
scp -r /usr/local/hadoop/hadoop-3.3.6/etc/hadoop root@192.168.185.152:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop
-----------------------------------------------------------------------------------------------------
scp /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml root@192.168.185.151:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml
scp /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml root@192.168.185.152:/usr/local/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml
b.初始化NameNode,即master
hdfs namenode -format
c.启动
start-dfs.sh
start-yarn.sh
hdfs dfsadmin -safemode leave
d.关闭
stop-dfs.sh
stop-yarn.sh
e.状态
master slave1 slave2
HDFS NameNode,DataNode NodeManager NodeManager
YARN NodeManager,ResourceManager SecondaryNameNode
f.访问
hdfs1 http://192.168.185.150:9870/dfshealth.html
hdfs2 http://192.168.185.152:9870/status.html
yarn http://192.168.185.150:8088/cluster
g.测试
/usr/local/hadoop/hadoop-3.3.6/bin/hadoop jar /workspace/hadoop-mapreduce-examples-3.3.6.jar wordcount /workspace/mapreduce1/input/demo00/ /workspace/mapreduce1/output/demo00/
/usr/local/hadoop/hadoop-3.3.6/bin/hadoop jar /usr/local/hadoop/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /workspace/mapreduce1/input/demo00/ /workspace/mapreduce1/output/demo00/
01.core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/data</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
02.hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
03.mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
04.yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
05.workers
master
slave1
slave2
06.hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
6.2 hive-3.1.3
00.安装
a.创建数据库
mysql --进入mysql
create database if not exists hive_metadata;
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
flush privileges;
use hive_metadata;
exit
b.迁移数据
schematool -dbType mysql -initSchema --初始化
c.权限
mysql -u root
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY ''; --允许root用户远程连接
FLUSH PRIVILEGES;
d.启动
/usr/local/hive/hive-2.3.4/bin/hive --进入hive
-----------------------------------------------------------------------------------------------------
jdbc:hive2://192.168.185.150:10000
192.168.185.150
10000
hive
hive
01.hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive_metadata?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive/hive-3.1.3/tmp/hadoop</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/hive/hive-3.1.3/tmp/hadoop/operation_logs</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive/hive-3.1.3/tmp/hadoop</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive/hive-3.1.3/tmp/${hive.session.id}_resources</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
02.hive-env.sh
HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6
export HIVE_CONF_DIR=/usr/local/hive/hive-3.1.3/conf
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HIVE_HOME=/usr/local/hive/hive-3.1.3
03.放jar包
/usr/local/hive/hive-3.1.3/lib/
mysql-connector-java.jar
6.3 zookeeper-3.7.1
00.使用
a.拷贝
scp /usr/local/zookeeper/zookeeper-3.7.1/conf/zoo.cfg root@192.168.185.151:/usr/local/zookeeper/zookeeper-3.7.1/conf/zoo.cfg
scp /usr/local/zookeeper/zookeeper-3.7.1/conf/zoo.cfg root@192.168.185.152:/usr/local/zookeeper/zookeeper-3.7.1/conf/zoo.cfg
b.启动
/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh start
/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh start-foreground
/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh stop
/usr/local/zookeeper/zookeeper-3.7.1/bin/zkServer.sh status
c.端口
netstat -tuln | grep 12181
01.zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/usr/local/zookeeper/zookeeper-3.7.1/data
dataLogDir=/usr/local/zookeeper/zookeeper-3.7.1/logs
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
02.myid
1
2
3
6.4 hbase-2.4.17
00.使用
a.拷贝
rm -rf /usr/local/hbase/hbase-2.4.17/conf
scp -r /usr/local/hbase/hbase-2.4.17/conf root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/conf
scp -r /usr/local/hbase/hbase-2.4.17/conf root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/conf
-----------------------------------------------------------------------------------------------------
scp /usr/local/hbase/hbase-2.4.17/conf/regionservers root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/conf/regionservers
scp /usr/local/hbase/hbase-2.4.17/conf/regionservers root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/conf/regionservers
-----------------------------------------------------------------------------------------------------
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml
-----------------------------------------------------------------------------------------------------
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-env.sh root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/conf/hbase-env.sh
scp /usr/local/hbase/hbase-2.4.17/conf/hbase-env.sh root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/conf/hbase-env.sh
b.启动
/usr/local/hbase/hbase-2.4.17/bin/start-hbase.sh
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start thrift --infoport 9095 -p 9090
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start thrift2 --infoport 9095 -p 9090
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh start rest
-----------------------------------------------------------------------------------------------------
/usr/local/hbase/hbase-2.4.17/bin/stop-hbase.sh
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop thrift --infoport 9095 -p 9090
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop thrift2 --infoport 9095 -p 9090
/usr/local/hbase/hbase-2.4.17/bin/hbase-daemons.sh stop rest
c.端口
netstat -tuln | grep 12181
netstat -tuln | grep 9090
01.regionservers
master
slave1
slave2
02.hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/zookeeper-3.7.1/data</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase/data/tmp</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.regionserver.thrift.http</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>
03.hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC"
6.5 phoenix-5.1.3
00.安装phoenix(tar.gz二进制包)
a.下载
cd /usr/local/phoenix
wget https://dlcdn.apache.org/phoenix/phoenix-5.1.3/phoenix-hbase-2.1-5.1.3-bin.tar.gz
tar -xzvf phoenix-hbase-2.4-5.1.3-bin.tar.gz
mv phoenix-hbase-2.4-5.1.3-bin phoenix-5.1.3
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export PHOENIX_HOME=/usr/local/phoenix/phoenix-5.2.0
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$PHOENIX_HOME/bin:$HADOOP_OPTS
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置
a.把客户端和服务端的Jar包给每一个Hbase的lib目录下面
cd /usr/local/phoenix/phoenix-5.1.3
scp -r phoenix-server-hbase-2.4-5.1.3.jar root@192.168.185.150:/usr/local/hbase/hbase-2.4.17/lib
scp -r phoenix-server-hbase-2.4-5.1.3.jar root@192.168.185.151:/usr/local/hbase/hbase-2.4.17/lib
scp -r phoenix-server-hbase-2.4-5.1.3.jar root@192.168.185.152:/usr/local/hbase/hbase-2.4.17/lib
-------------------------------------------------------------------------------------------------
rm -rf /usr/local/hbase/hbase-2.4.17/lib/phoenix-server-hbase-2.4-5.1.3.jar
b.备份,并将hbase进行替换
cp -r /usr/local/phoenix/phoenix-5.1.3/bin/hbase-site.xml /usr/local/phoenix/phoenix-5.1.3/bin/hbase-site-bak.xml
cp -r /usr/local/hbase/hbase-2.4.17/conf/hbase-site.xml /usr/local/phoenix/phoenix-5.1.3/bin/hbase-site.xml
c.将Hadoop的HDFS配置放入Phoenix
cp -r /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/core-site.xml /usr/local/phoenix/phoenix-5.1.3/bin/core-site.xml
cp -r /usr/local/hadoop/hadoop-3.3.6/etc/hadoop/hdfs-site.xml /usr/local/phoenix/phoenix-5.1.3/bin/hdfs-site.xml
d.DataGrip连接Phoenix
a.日志
vi /usr/local/phoenix/bin/log4j.properties
psql.root.logger=DEBUG,console,DRFA
log4j.threshold=DEBUG
b.DataGrip中jar包
phoenix-client-hbase-2.1-5.1.3.jar
phoenix-client-hbase-2.4-5.1.3.jar
c.连接
jdbc:phoenix:master:2181
jdbc:phoenix:slave1:2181
jdbc:phoenix:slave2:2181
-------------------------------------------------------------------------------------------------
jdbc:phoenix:master
jdbc:phoenix:master:2181
jdbc:phoenix:master:2181:/hbase
jdbc:phoenix:master,slave1,slave2:2181:/hbase
-------------------------------------------------------------------------------------------------
jdbc:phoenix:192.168.185.150
jdbc:phoenix:192.168.185.150:2181
jdbc:phoenix:192.168.185.150:2181:/hbase
d.报错
Could not load/instantiate class org.apache.phoenix.query.DefaultGuidePostsCacheFactory.
-------------------------------------------------------------------------------------------------
服务端:
vi /usr/local/phoenix/bin/hbase-site.xml
vi /usr/local/hbase/hbase-2.1.1/conf/hbase-site.xml
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
-------------------------------------------------------------------------------------------------
客户端:
phoenix -> 高级
phoenix.schema.isNamespaceMappingEnabled true
phoenix.schema.mapSystemTablesToNamespace true
e.验证
start-hadoop-cluster
start-zookeeper-cluster && status-zookeeper-cluster
start-hbase-cluster
-----------------------------------------------------------------------------------------------------
chmod 777 /usr/local/phoenix/phoenix-5.1.3/bin/psql.py
chmod 777 /usr/local/phoenix/phoenix-5.1.3/bin/sqlline.py
-----------------------------------------------------------------------------------------------------
/usr/local/phoenix/phoenix-5.1.3/bin/sqlline.py master:2181
/usr/local/phoenix/phoenix-5.1.3/bin/sqlline.py slave1:2181
/usr/local/phoenix/phoenix-5.1.3/bin/sqlline.py slave2:2181
/usr/local/phoenix/phoenix-5.1.3/bin/sqlline.py master,slave1,slave2:2181
-----------------------------------------------------------------------------------------------------
select 0
!tables
!quit
6.6 kafka-3.4.0
01.kafka
a.命令
kafka-server-start.sh kafka启动程序
kafka-server-stop.sh kafka停止程序
kafka-topics.sh 创建topic程序
kafka-console-producer.sh 命令行模拟生产者生产消息数据程序
kafka-console-consumer.sh 命令行模拟消费者消费消息数据程序
b.配置
a.server.properties
a.master
broker.id=0
listeners=PLAINTEXT://192.168.185.150:9092
log.dirs=/usr/local/kafka/kafka-3.4.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
b.slave1
broker.id=1
listeners=PLAINTEXT://192.168.185.151:9092
log.dirs=/usr/local/kafka/kafka-3.4.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
c.slave2
broker.id=2
listeners=PLAINTEXT://192.168.185.152:9092
log.dirs=/usr/local/kafka/kafka-3.4.0/logs/kafka-logs
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181
zookeeper.connection.timeout.ms=600000
b.连接Kafka集群
通常使用任意一个 Kafka Broker 的 IP 地址都可以。Kafka 集群会将生产者和消费者的请求路由到适当的 Broker。
任意一个 Broker 的 IP 地址: 你可以使用集群中任意一个 Broker 的 IP 地址来连接 Kafka 集群。Kafka 会处理请求并将其转发到其他 Brokers(如果需要)。
例如,你可以使用以下 IP 地址连接集群:
192.168.185.150:9092
192.168.185.151:9092
192.168.185.152:9092
-------------------------------------------------------------------------------------------------
为什么可以使用任意一个 Broker IP 地址?
负载均衡和故障转移: Kafka 集群的元数据会在客户端和集群之间同步。如果你连接到集群中的一个 Broker,客户端会从这个 Broker 获取集群的元数据,包括其他 Brokers 的信息,从而进行负载均衡和故障转移。
集群的元数据: Kafka 的客户端在连接到集群中的任意 Broker 后,会获取集群的完整元数据,包括所有 Brokers 的地址、分区信息等。这样,客户端能够与集群中的其他 Brokers 通信,而不仅仅是你初始连接的那个 Broker。
c.运行
/usr/local/kafka/kafka-3.4.0/bin/kafka-server-start.sh -daemon /usr/local/kafka/kafka-3.4.0/config/server.properties
nohup /usr/local/kafka/kafka-3.4.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-3.4.0/config/server.properties &
nohup /usr/local/kafka/kafka-3.4.0/bin/kafka-server-start.sh /usr/local/kafka/kafka-3.4.0/config/server.properties > /usr/local/kafka/kafka-3.4.0/logs/kafka.log 2>&1 &
-----------------------------------------------------------------------------------------------------
# ps aux | grep kafka --查看进程
root 2966 0.0 0.0 112660 972 pts/0 R+ 16:43 0:00 grep --color=auto kafka
02.kafka-console-ui
a.安装
kafka-console-ui-1.0.10.zip
unzip kafka-console-ui-1.0.10.zip
b.使用
cd /usr/local/kafka-console-ui && sh bin/start.sh
cd /usr/local/kafka-console-ui && sh bin/shutdown.sh
http://192.168.185.150:7766
---------------------------------------------------------------------------------------------------------
运维 -> 集群切换 -> 新增集群 -> cluster、192.168.185.150:9092
6.7 sqoop-1.4.7
00.安装
a.下载
cd /usr/local/
wget https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -xzvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
cp /usr/local/hive/hive-3.1.3/lib/mysql-connector-java.jar /usr/local/sqoop/sqoop-1.4.7/lib/
b.环境变量
vi /etc/profile
-----------------------------------------------------------------------------------------------------
export SQOOP_HOME=/usr/local/sqoop/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/bin
-----------------------------------------------------------------------------------------------------
source /etc/profile
c.配置
cd /usr/local/sqoop/sqoop-1.4.7/conf/
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
-----------------------------------------------------------------------------------------------------
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-3.3.6
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.6
export HBASE_HOME=/usr/local/hbase/hbase-2.4.17
export HIVE_HOME=/usr/local/hive/hive-3.1.3
export HIVE_CONF_DIR=/usr/local/hive/hive-3.1.3/conf
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.7.1
export ZOOCFGDIR=/usr/local/zookeeper/zookeeper-3.7.1/conf
d.报错
问题:
[root@master sqoop]# sqoop version
Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
解决:
vi /usr/local/hbase/hbase-2.4.17/bin/hbase 修改如下内容
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/usr/local/hbase/hbase-2.4.17/lib/*
e.验证
sqoop version
f.报错
[root@master bin]# sqoop version
Warning: /usr/local/sqoop/sqoop-1.4.7/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/sqoop-1.4.7/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Error: Could not find or load main class org.apache.sqoop.Sqoop
-----------------------------------------------------------------------------------------------------
WARN警告提示,可以不必理会