1 ElasticSearch介绍
1.1 定义
00.总结
a.服务
手动 elasticsearch6 net start es6 && net start esh6 && net start ki6 && net start log6
手动 elasticsearch6 net stop es6 && net stop esh6 && net stop ki6 && net stop log6
-----------------------------------------------------------------------------------------------------
手动 elasticsearch7 net start es7 && net start esh7 && net start ki7 && net start log7
手动 elasticsearch7 net stop es7 && net stop esh7 && net stop ki7 && net stop log7
-----------------------------------------------------------------------------------------------------
手动 ElasticHD net start ehd7
手动 ElasticHD net stop ehd7
b.对比说明
a.数据库(关系型数据库) 对应 索引(Elasticsearch):
在关系型数据库中,数据库是存储表的集合,而在 Elasticsearch 中,索引是存储文档的集合。
b.表 对应 类型(type):
在早期的 Elasticsearch 版本中,一个索引可以包含多个类型(类似于关系型数据库中的表),
但自 Elasticsearch 6.x 版本起,一个索引只能有一个类型。可以理解为每个索引只有一个数据模型。
c.表结构 对应 映射(mapping):
在关系型数据库中,表结构定义了表的列和数据类型。
在 Elasticsearch 中,映射(mapping)定义了文档中字段的结构和类型。
d.行,一条数据 对应 文档(document):
在关系型数据库中,一行表示表中的一条数据,而在 Elasticsearch 中,
一个文档是存储在索引中的基本单位,它包含了字段和字段值。
e.列,字段的值 对应 字段(field):
在关系型数据库中,列表示数据的字段,每行都有列的值。
在 Elasticsearch 中,字段是文档的组成部分,记录了文档的具体信息。
c.ElasticSearch Vs 关系型数据库
关系型数据库 ElasticSearch
数据库 索引(index)
表 类型(type) 废弃
表结构 映射(mapping)
行,一条数据 文档(document)
列,字段的值 字段(filed)
-----------------------------------------------------------------------------------------------------
SQL DSL(Domain Specific Language)
Select * from xxx GET http://
update xxx set xx=xxx PUT http://
Delete xxx DELETE http://
索引 全文索引
-----------------------------------------------------------------------------------------------------
在ES中索引是有不同上下文含义的,它既可以是名词也可以是动词。
索引为名词是就是上文中提到的它是document的集合,索引为动词的时候表示将document数据保存到ES中,也就是数据写入。
在ES中,为了屏蔽语言的交互差异,ES直接对外的交互都是通过Rest API进行的。
00.介绍
a.ElasticSearch Vs 关系型数据库
a.对比
关系型数据库 ElasticSearch
数据库 索引(index) 倒排索引:词条、词条所在文档id、位置、...
表 类型(type) 废弃
表结构 映射(mapping)
行,一条数据 文档(document)
列,字段的值 字段(filed)
-------------------------------------------------------------------------------------------------
SQL DSL(Domain Specific Language)
Select * from xxx GET http://
update xxx set xx=xxx PUT http://
Delete xxx DELETE http://
索引 全文索引
b.说明
在ES中索引是有不同上下文含义的,它既可以是名词也可以是动词。
索引为名词是就是上文中提到的它是document的集合,索引为动词的时候表示将document数据保存到ES中,也就是数据写入。
在ES中,为了屏蔽语言的交互差异,ES直接对外的交互都是通过Rest API进行的。
b.分词器
a.ik_smart:为最少切分
描述:该分词器为智能分词器,适合快速分词,适用于搜索时对速度要求较高的场景。
特点:
使用较少的词典,分词效果较为简单。
能够对常见的词进行合理的分词,但可能会忽略一些细节。
b.ik_max_word:为最细粒度划分
描述:该分词器为最大词长分词器,适合对分词精度要求较高的场景。
特点:
会生成尽可能多的词条,提供更细粒度的分词结果。
能够捕捉到更多的短语和组合,但相对速度较慢。
c.默认standard
它基于 Unicode 文本分割标准,适用于多种语言。
-----------------------------------------------------------------------------------------------------
具体特点包括:
处理多语言:standard 分词器可以处理多种语言的文本,自动识别并处理词边界。
过滤:它会去除一些常见的标点符号和停用词(如“the”、“is”等)。
小写转换:分词器会将所有输入的文本转换为小写,从而进行大小写不敏感的搜索。
-----------------------------------------------------------------------------------------------------
使用示例
如果你在创建索引时不指定分析器,standard 分词器将被自动应用。以下是创建索引的示例:
PUT /my_index
{
"settings": {
"analysis": {
// 此处未指定分析器,将使用默认的 standard 分词器
}
}
}
01.定义1
a.ElasticSearch
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
ElasticSearch 是一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。
ElasticSearch 基于 Java 编写,通过进一步封装 Lucene,将搜索的复杂性屏蔽起来,开发者只需要一套简单的 RESTful API 就可以操作全文检索。
ElasticSearch 在分布式环境下表现优异,这也是它比较受欢迎的原因之一。它支持 PB 级别的结构化或非结构化海量数据处理
b.Lucene
Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。
在实际开发中,Lucene 几乎适用于任何需要全文检索的场景,所以 Lucene 先后发展出好多语言版本,例如 C++、C#、Python 等。
早在 2005 年,Lucene 就升级为 Apache 顶级开源项目。它的作者是 Doug Cutting,有的人可能没听过这这个人,不过你肯定听过他的另一个大名鼎鼎的作品 Hadoop。
不过需要注意的是,Lucene 只是一个工具包,并非一个完整的搜索引擎,开发者可以基于 Lucene 来开发完整的搜索引擎。比较著名的有 Solr、ElasticSearch,不过在分布式和大数据环境下,ElasticSearch 更胜一筹。
-----------------------------------------------------------------------------------------------------
Lucene的优势:
易扩展
高性能(基于倒排索引)
-----------------------------------------------------------------------------------------------------
Lucene的缺点:
只限于Java语言开发
学习曲线陡峭
不支持水平扩展
-----------------------------------------------------------------------------------------------------
相比与lucene,elasticsearch具备下列优势:
支持分布式,可水平扩展
提供Restful接口,可被任何语言调用
c.ElasticSearch三大功能
数据搜集
数据分析
数据存储
d.ElasticSearch主要特点
分布式文件存储
实时分析的分布式搜索引擎
高可拓展性
可插拔的插件支持
分布式索引、搜索
索引自动分片、负载均衡
自动发现机器、组建集群
支持Restful 风格接口
02.定义2
a.概念
a.elasticsearch
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
b.elastic stack(ELK)
以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
c.Lucene
Apache的开源搜索引擎类库,提供了搜索引擎的核心API
b.ELK技术栈
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域:
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
03.核心概念
a.集群(Cluster)
在一个分布式系统里面,可以通过多个elasticsearch运行实例组成一个集群,
这个集群里面有一个节点叫做主节点(master),elasticsearch是去中心化的,
所以这里的主节点是动态选举出来的,不存在单点故障。
-----------------------------------------------------------------------------------------------------
在同一个子网内,只需要在每个节点上设置相同的集群名,
elasticsearch就会自动的把这些集群名相同的节点组成一个集群。
节点和节点之间通讯以及节点之间的数据分配和平衡全部由elasticsearch自动管理,
在外部看来elasticsearch就是一个整体。
-----------------------------------------------------------------------------------------------------
一个或者多个安装了 es 节点的服务器组织在一起,就是集群,这些节点共同持有数据,共同提供搜索服务。
一个集群有一个名字,这个名字是集群的唯一标识,该名字成为 cluster name,默认的集群名称是 elasticsearch,具有相同名称的节点才会组成一个集群。
-----------------------------------------------------------------------------------------------------
可以在 config/elasticsearch.yml 文件中配置集群名称:
cluster.name: javaboy-es
-----------------------------------------------------------------------------------------------------
在集群中,节点的状态有三种:绿色、黄色、红色:
绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。
黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。
红色:表示集群无法正常工作。
b.节点(Node)
集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能。
一个节点想要加入一个集群,只需要配置一下集群名称即可。
默认情况下,如果我们启动了多个节点,多个节点还能够互相发现彼此,那么它们会自动组成一个集群,这是 es 默认提供的,
但是这种方式并不可靠,有可能会发生脑裂现象。所以在实际使用中,建议一定手动配置一下集群信息。
-----------------------------------------------------------------------------------------------------
每一个运行实例称为一个节点,每一个运行实例既可以在同一机器上,也可以在不同的机器上。
所谓运行实例,就是一个服务器进程,在测试环境中可以在一台服务器上运行多个服务器进程,在生产环境中建议每台服务器运行一个服务器进程。
c.索引(Index)
索引可以从两方面来理解:索引可以从两方面来理解:
名词:具有相似特征文档的集合
动词:索引数据以及对数据进行索引操作
-----------------------------------------------------------------------------------------------------
Elasticsearch里的索引概念是名词而不是动词,在elasticsearch里它支持多个索引。
优点类似于关系数据库里面每一个服务器可以支持多个数据库是一个道理,
在每一索引下面又可以支持多种类型,这又类似于关系数据库里面的一个数据库可以有多张表一样。
但是本质上和关系数据库还是有很大的区别,我们这里暂时可以这么理解。
-----------------------------------------------------------------------------------------------------
在ES之前的版本中,是有type这个概念的,类比数据库中的表,那上文中所说的document就会放在type中。
但是在ES后面的版本中为了提高数据存储的效率逐渐取消了type,
因此index实际上在现在的ES中既有库的概念也有表的概念。
简单理解就是index就是文档的容器,它是一类文档的集合,
但是这里需要注意的是index是逻辑空间的分类,实际数据是存在物理空间的分片上的。
-----------------------------------------------------------------------------------------------------
另外需要说明的是,在ES中索引是有不同上下文含义的,它既可以是名词也可以是动词。
索引为名词是就是上文中提到的它是document的集合,索引为动词的时候表示将document数据保存到ES中,也就是数据写入。
在ES中,为了屏蔽语言的交互差异,ES直接对外的交互都是通过Rest API进行的。
d.类型(Type)
类型是索引上的逻辑分类或者分区。在 es6 之前,一个索引中可以有多个类型,
从 es7 开始,一个索引中,只能有一个类型。
在 es6.x 中,依然保持了兼容,依然支持单 index 多个 type 结构,但是已经不建议这么使用。
e.文档(Document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等等。文档都是 JSON 格式的。
-----------------------------------------------------------------------------------------------------
我们都说ES是面向document的,这句话什么意思呢?实际就是表示ES是基于document进行数据操作的,
操作主要包括数据搜索以及索引(这里的索引是数据写入的意思)。因此可以说document是ES的基础数据结构,
它会被序列化之后保存到ES中。那么这个document到底是个什么东东呢?相信大家都对Mysql还是比较熟悉的,
因此我们用Mysql中的数据库与表的概念与ES的index进行对比,可能并不是十分的恰当和吻合,
但是可以有助于大家对于这些概念的理解。另外type也在ES6.x版本之后逐渐取消了。
f.分片(Shards)
索引都是存储在节点上的,但是受限于节点的空间大小以及数据处理能力,单个节点的处理效果可能不理想,
此时我们可以对索引进行分片。当我们创建一个索引的时候,就需要指定分片的数量。
每个分片本身也是一个功能完善并且独立的索引。
默认情况下,一个索引会自动创建 1 个分片,并且为每一个分片创建一个副本。
-----------------------------------------------------------------------------------------------------
Elasticsearch 它会把一个索引分解为多个小的索引,每一个小的索引就叫做分片。
分片之后就可以把各个分片分配到不同的节点中去。
g.副本(Replicas)
副本也就是备份,是对主分片的一个备份。‘
-----------------------------------------------------------------------------------------------------
Elasticsearch的每一个分片都可以有0到多个副本,
而每一个副本也都是分片的完整拷贝,好处是可以用它来增加速度的同时也提高了系统的容错性。
一旦Elasticsearch的某个节点数据损坏或则服务不可用的时候,
那么这个时就可以用其他节点来代替坏掉的节点,以达到高考用的目的。
h.recovery概念
Elasticsearch 的recovery代表的是数据恢复或者叫做数据重新分布。
elasticsearch 当有节点加入或退出时时它会根据机器的负载对索引分片进行重新分配,当挂掉的节点再次重新启动的时候也会进行数据恢复。
i.river
Elasticsearch river 代表的是一个数据源,这也是其它存储方式(比如:数据库)同步数据到 elasticsearch 的一个方法。
它是以插件方式存在的一个 elasticsearch 服务,通过读取 river 中的数据并把它索引到 elasticsearch 当中去,官方的 river 有 couchDB、RabbitMQ、Twitter、Wikipedia。
j.gateway
gateway 代表 elasticsearch 索引的持久化存储方式,elasticsearch 默认是先把索引存放到内存中去,当内存满了的时候再持久化到硬盘里。
当这个 elasticsearch 集群关闭或者再次重新启动时就会从 gateway 中读取索引数据。
elasticsearch 支持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop 的 HDFS 和 amazon 的 s3 云存储服务。
k.discovery.zen
discovery.zen代表 elasticsearch 的自动节点发现机制,而且 elasticsearch还是一个基于 p2p 的系统。
首先它它会通过以广播的方式去寻找存在的节点,然后再通过多播协议来进行节点之间的通信,于此同时也支持点对点的交互操作。
l.Transport
Transport代表 elasticsearch 内部的节点或者集群与客户端之间的交互方式。
默认的内部是使用 tcp 协议来进行交互的,同时它支持 http 协议(json格式)、thrift、servlet、memcached、zeroMQ等多种的传输协议(通过插件方式集成)。
m.Settings
集群中对索引的定义信息,例如索引的分片数、副本数等等。
n.Mapping
Mapping 保存了定义索引字段的存储类型、分词方式、是否存储等信息。
o.Analyzer
字段分词方式的定义。

1.2 架构1
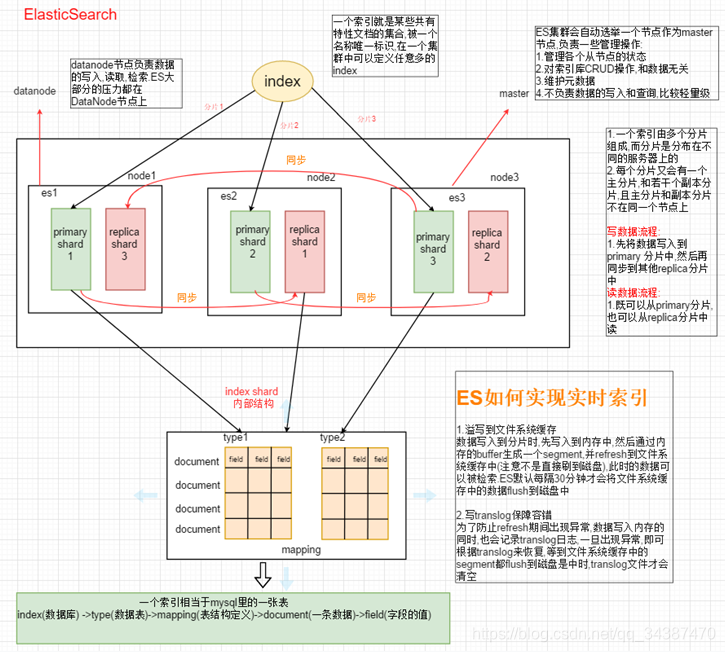
00.总结
a.流程
datanode节点负责数据的写入读取,检索ES大部分的压力都在DataNode节点上
一个索引就是某些共有特性文档的集合,被一个名称唯一标识在一个集群中可以定义任意多的index
b.ES集群会自动选举一个节点作为master节点负责一些管理操作
1.管理各个从节点的状态
2.对索引库CRUD提作和数据无关
3.维护元数据
4.不负责数据的写入和查询比较轻量级
-----------------------------------------------------------------------------------------------------
分片
1.一个索引由多个分片组成而分片是分布在不同的服务器上的
2.每个分片又会有一个主分片,和若干个副本分片且主分片和副本分片不在同一个节点上
-----------------------------------------------------------------------------------------------------
写数据流程:先将数据写入到primary分片中,然后再同步到其他replica分片中
读数据流程:既可以从primary分片,也可以从replica分片中
c.ES如何实现实时索引
1.溢写到文件系统缓存
数据写入到分片时,先写入到内存中,然后通过内存的buffer生成一个segment,
并refresh到文件系统缓存中(注意不是直接刷到磁盘)此时的数据可以被检索,
ES默认每隔30分钟才会将文件系统缓存中的数据flush到磁盘中
2.写translog保障容错
为了防止refresh期间出现异常,数据写入内存的同时,也会记录translog日志,一旦出现异常,
即可根据translog来恢复等到文件系统缓存中的segment都flush到磁盘是中时,translog文件才会清空
-------------------------------------------------------------------------------------------------------------
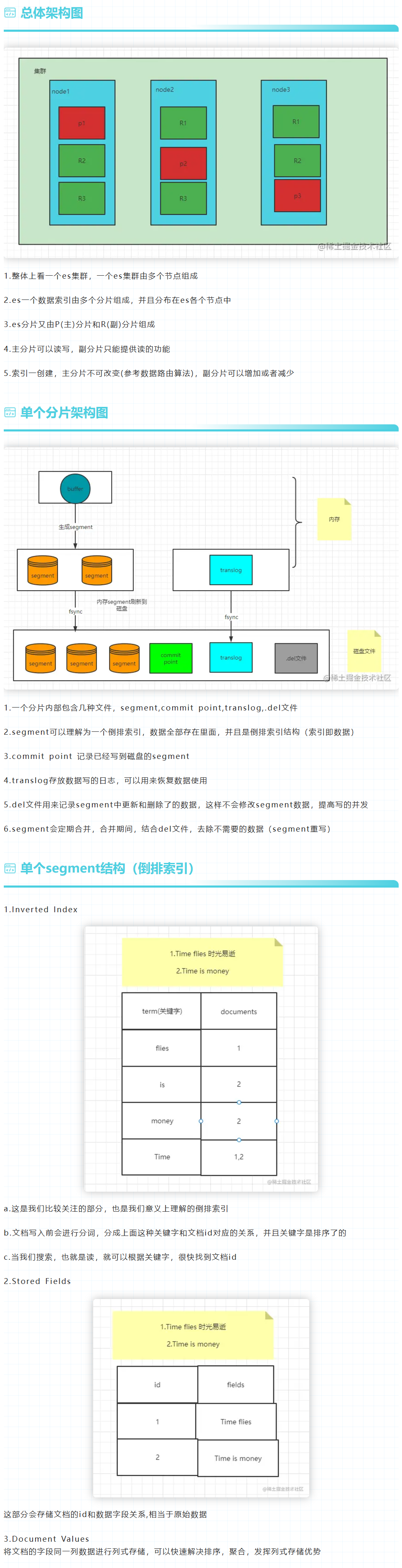
01.总体架构图
1.整体上看一个es集群,一个es集群由多个节点组成
2.es一个数据索引由多个分片组成,并且分布在es各个节点中
3.es分片又由P(主)分片和R(副)分片组成
4.主分片可以读写,副分片只能提供读的功能
5.索引一创建,主分片不可改变(参考数据路由算法),副分片可以增加或者减少
02.单个分片架构图
1.一个分片内部包含几种文件,segment,commit point,translog,.del文件
2.segment可以理解为一个倒排索引,数据全部存在里面,并且是倒排索引结构(索引即数据)
3.commit point 记录已经写到磁盘的segment
4.translog存放数据写的日志,可以用来恢复数据使用
5.del文件用来记录segment中更新和删除了的数据,这样不会修改segment数据,提高写的并发
6.segment会定期合并,合并期间,结合del文件,去除不需要的数据(segment重写)
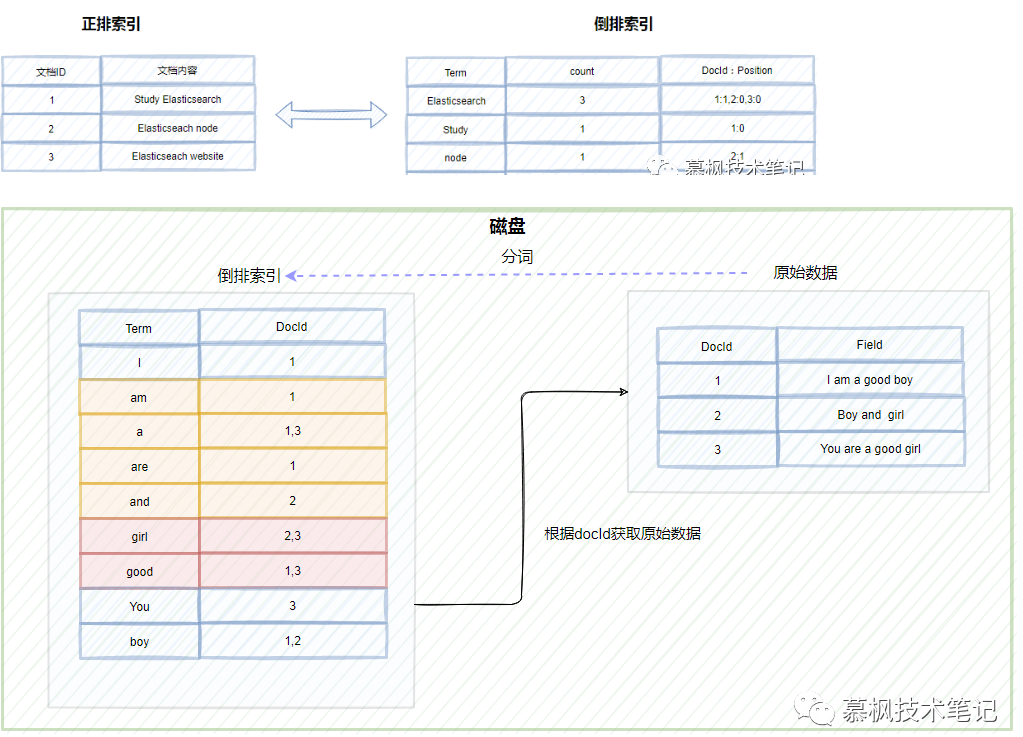
03.单个segment结构(倒排索引)
1.Inverted Index
a.这是我们比较关注的部分,也是我们意义上理解的倒排索引
b.文档写入前会进行分词,分成上面这种关键字和文档id对应的关系,并且关键字是排序了的
c.当我们搜索,也就是读,就可以根据关键字,很快找到文档id
2.Stored Fields
这部分会存储文档的id和数据字段关系,相当于原始数据
3.Document Values
将文档的字段同一列数据进行列式存储,可以快速解决排序,聚合,发挥列式存储优势
1.3 架构2
01.倒排索引
a.用B+树作为索引行不行呢?
全文索引就是需要支持对大文本进行索引的,从空间上来说 B+ 树不适合作为全文索引,
同时 B+ 树因为每次搜索都是从根节点开始往下搜索,所以会遵循最左匹配原则,
而我们使用全文搜索时,往往不会遵循最左匹配原则,所以可能会导致索引失效。这时候倒排索引就派上用场了。
b.倒排索引1
所谓正排索引就像书中的目录一样,根据页码查询内容,但是倒排索引确实相反的,它是通过对内容的分词,
建立内容到文档ID的关联关系。这样在进行全文检索的时候,根据词典的内容便可以精确以及模糊查询,
非常符合全文检索的要求。
c.倒排索引2
倒排索引的结构主要包括了两大部分一个是Term Dictionary(单词词典),另一个是Posting List(倒排列表)。
Term Dictionary(单词词典)记录了所用文档的单词以及单词和倒排列表的关系。
Posting List(倒排列表)则是记录了term在文档中的位置以及其他信息,
主要包括文档ID,词频(term在文档中出现的次数,用来计算相关性评分),位置以及偏移(实现搜索高亮)。
02.FST
a.介绍1
在进行全文检索的时候,通过倒排索引中term与docId的关联关系获取到原始数据。
但是这里有一个问题,ES底层依赖Lucene实现倒排索引的,因此在进行数据写入的时候,
Lucene会为原始数据中的每个term生成对应的倒排索引,因此造成的结果就是倒排索引的数据量就会很大。
而倒排索引对应的倒排表文件是存储在硬盘上的。如果每次查询都直接去磁盘中读取倒排索引数据,
在通过获取的docId再去查询原始数据的话,肯定会造成多次的磁盘IO,严重影响全文检索的效率。
因此我们需要一种方式可以快速定位到倒排索引中的term。
大家想想使用什么方式比较好呢?可以考虑HashMap, TRIE, Binary Search Tree或者Tenary Search Tree等数据结构,
实际上Lucene实际是使用了FST(Finite State Transducer)有限状态传感器来实现二级索引的设计,
它其实就是一种有限状态机。
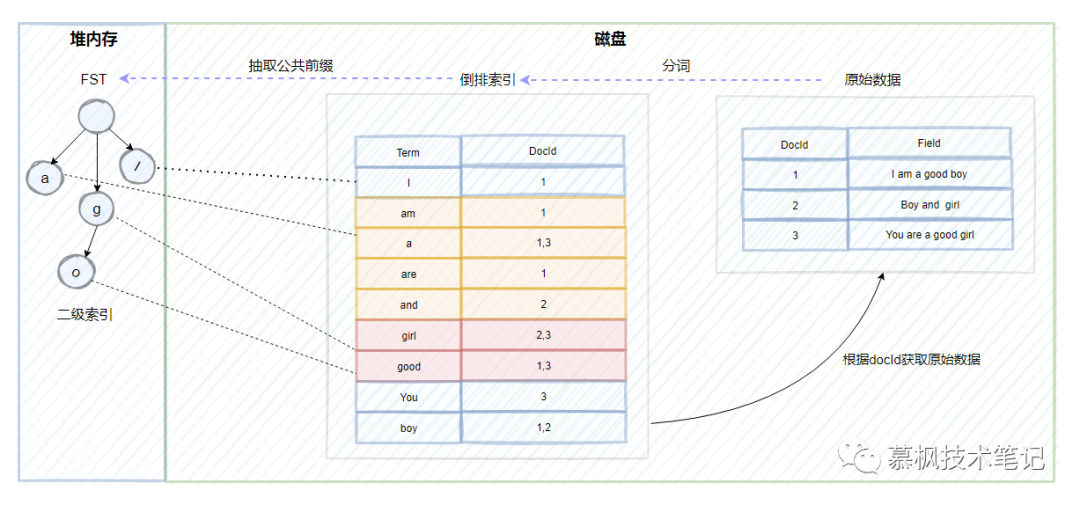
b.介绍2
我们先来看下 trie树的结构,在Lucene中是这样做的,将倒排索引中具有公共前缀的term组成一个block,
如下图所示的cool以及copy,它们拥有co的公共前缀,按照类似前缀树的逻辑来构成trie树,
对应节点中携带block的首地址。我们来分析下trie树相比hashmap有什么优点?hashmap实现的是精准查找,
但是trie树不仅可以实现精准查找,另外由于其公共前缀的特性还可以实现模糊查找。
那我们再看trie树有什么地方可以再进行优化的地方?
-----------------------------------------------------------------------------------------------------
如上如所示,term中的school以及cool的后面字符是一致的,
因此我们可以通过将原先的trie树中的后缀字符进行合并来进一步的压缩空间。优化后的trie树就是FST。
-----------------------------------------------------------------------------------------------------
因此通过建立FST这个二级索引,可以实现倒排索引的快速定位,不需要经过多次的磁盘IO,搜索效率大大提高了。
不过需要注意的是FST是存储在堆内存中的,而且是常驻内存,大概占用50%-70%的堆内存,
因此这里也是我们在生产中可以进行堆内存优化的地方。
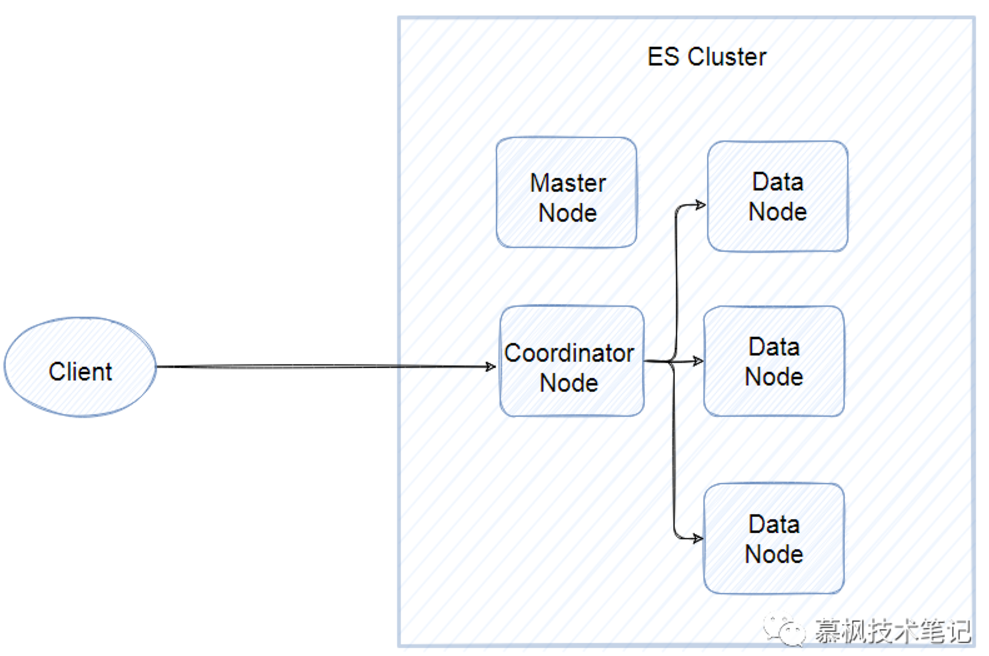
03.节点
所谓的节点实际就是ES的实例,我们通常在一台服务器部署一个ES实例,其实就是一个Java进程。
虽然都是ES实例,但是实际上的ES集群,不同节点承担着不同的能力角色,
有的是data node,主要负责保存分片的数据的,承担着数据横向扩展的重要作用,
有的是coordinating node负责将用户请求进行转发以及将查询的结果进行合并返回。
当然还有master节点,负责对整个集群状态进行管理和维护。
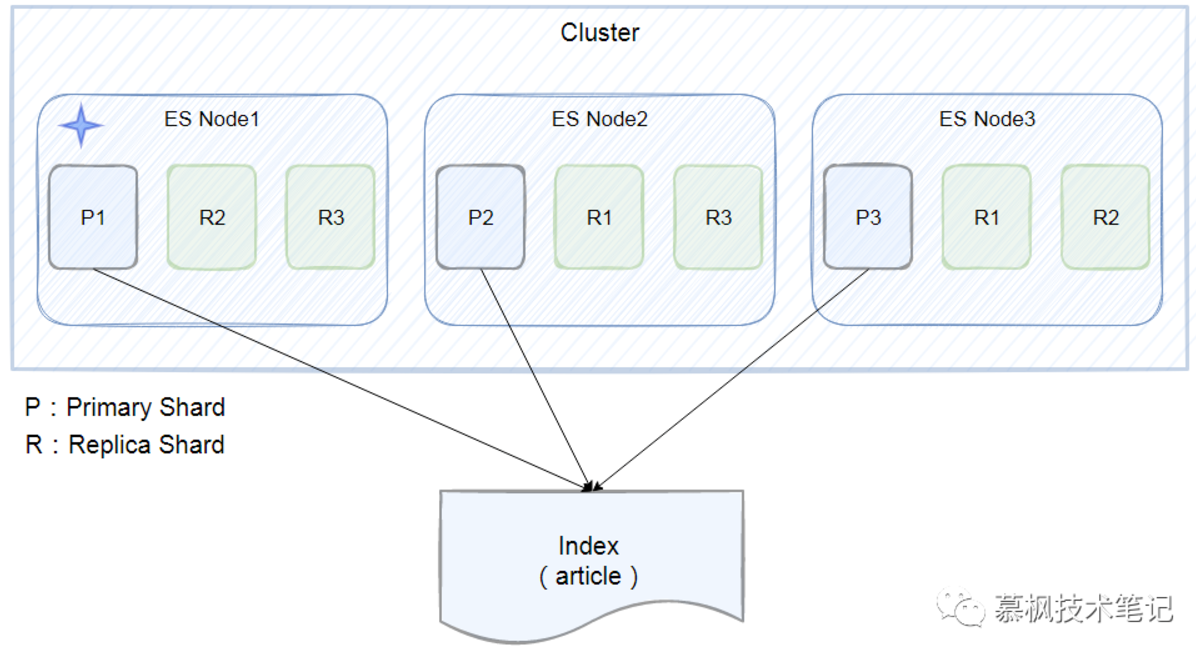
04.分片
单个ES节点的数据存储毕竟有限,没法实现海量数据的存储要求。那么怎么才能满足海量数据的存储要求呢?
一个核心思想就是拆分,比如总共10亿条数据,如果都放在一个节点中不仅查询以及数据写入的速度会很慢,
也存在单点问题。在传统关系型数据库中,采用分库分表的方式,用更多的数据库实例来承接大量的数据存储。
那么在ES中,也是采取类似的设计思想,既然一个ES的实例存在数据存储的上线,那么就用多个实例来进行存储。
在每个实例中存在的数据集合就是分片。如下图所示,index被切分成三个分片,三个分片分别存储在三个ES实例中
,同时为了提升数据的高可用性,每个主分片都有两个副本分片,这些副本分片是主分片的数据拷贝。
---------------------------------------------------------------------------------------------------------
这里需要注意的是,分片不是随意进行设定的,而是需要根据实际的生产环境提前进行数据存储的容量规划,
否则分片设置的过大或者过小都会影响ES集群的整体性能。如果分片设置的过小,那么单个分片的数据量可能会很大,
影响数据检索效率,也会影响数据的横向扩展。如果分片设置的过大就会影响搜索结果的数据相关性评分,影响数据检索的准确性。
倒排索引
FST
节点
分片
1.4 分词器
01.内置分词器
a.概念
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤:
词条化:分词器将输入的文本转为一个一个的词条流。
过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等。
b.内置分词器
| 分词器 | 作用
|----------------------|------------------------------
| Standard Analyzer | 标准分词器,适用于英语等。
| Simple Analyzer | 简单分词器,基于非字母字符进行分词,单词会被转为小写字母。
| Whitespace Analyzer | 空格分词器。按照空格进行切分。
| Stop Analyzer | 类似于简单分词器,但是增加了停用词的功能。
| Keyword Analyzer | 关键词分词器,输入文本等于输出文本。
| Pattern Analyzer | 利用正则表达式对文本进行切分,支持停用词。
| Language Analyzer | 针对特定语言的分词器。
| Fingerprint Analyzer | 指纹分析仪分词器,通过创建标记进行重复检测。
02.中文分词器
a.安装
首先打开分词器官网:https://github.com/medcl/elasticsearch-analysis-ik。
在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到最新的正式版,下载下来。我们这里的下载链接是 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip。
将下载文件解压。
在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
重启 es 服务。
b.自定义扩展词库
a.本地自定义
在 es/plugins/ik/config 目录下,新建 ext.dic 文件(文件名任意),在该文件中可以配置自定义的词库。
如果有多个词,换行写入新词即可。
然后在 es/plugins/ik/config/IKAnalyzer.cfg.xml 中配置扩展词典的位置:
-------------------------------------------------------------------------------------------------
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<entry key="remote_ext_dict">location</entry>
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
b.远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件,写入扩展词:
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:
配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展辞典。
c.测试
The plugin comprises analyzer:
a.创建索引
http://localhost:9200/test
b.测试分词
curl --location 'http://localhost:9200/test/_analyze' \
--header 'Content-Type: application/json' \
--data '{
"analyzer": "ik_max_word",
"text": "欢迎来到黑马"
}'
-------------------------------------------------------------------------------------------------
analyzer可选:
ik_smart
ik_max_word
03.官方文档
a.创建索引
curl -XPUT http://localhost:9200/index
b.创建映射
curl -XPOST http://localhost:9200/index/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}'
c.索引一些文档
curl -XPOST http://localhost:9200/index/_create/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
-----------------------------------------------------------------------------------------------------
curl -XPOST http://localhost:9200/index/_create/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
-----------------------------------------------------------------------------------------------------
curl -XPOST http://localhost:9200/index/_create/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
-----------------------------------------------------------------------------------------------------
curl -XPOST http://localhost:9200/index/_create/4 -H 'Content-Type:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
d.查询高亮
curl -XPOST http://localhost:9200/index/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
-----------------------------------------------------------------------------------------------------
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 2,
"hits": [
{
"_index": "index",
"_type": "fulltext",
"_id": "4",
"_score": 2,
"_source": {
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight": {
"content": [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首 "
]
}
},
{
"_index": "index",
"_type": "fulltext",
"_id": "3",
"_score": 2,
"_source": {
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight": {
"content": [
"均每天扣1艘<tag1>中国</tag1>渔船 "
]
}
}
]
}
}
1.5 工作原理
01.写数据过程
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node 。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
02.读数据过程
通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node 。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
03.搜索数据过程
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊
java好难学啊
j2ee特别牛
---------------------------------------------------------------------------------------------------------
你根据 java 关键词来搜索,将包含 java 的 document 给搜索出来。es 就会给你返回:java 真好玩儿啊,java 好难学啊。
---------------------------------------------------------------------------------------------------------
客户端发送请求到一个 coordinate node 。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
---------------------------------------------------------------------------------------------------------
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
04.写数据底层原理
先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据 refresh 到一个新的 segment file 中,但是此时数据不是直接进入 segment file 磁盘文件,而是先进入 os cache 。这个过程就是 refresh 。
每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file ,每秒钟会产生一个新的磁盘文件 segment file ,这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。
但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
操作系统里面,磁盘文件其实都有一个东西,叫做 os cache ,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入 os cache ,先进入操作系统级别的一个内存缓存中去。只要 buffer 中的数据被 refresh 操作刷入 os cache 中,这个数据就可以被搜索到了。
---------------------------------------------------------------------------------------------------------
为什么叫 es 是准实时的? NRT ,全称 near real-time 。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的 restful api 或者 java api ,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入 os cache 中,让数据立马就可以被搜索到。只要数据被输入 os cache 中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。
重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将 buffer 数据写入一个又一个新的 segment file 中去,每次 refresh 完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发 commit 操作。
commit 操作发生第一步,就是将 buffer 中现有数据 refresh 到 os cache 中去,清空 buffer。然后,将一个 commit point 写入磁盘文件,里面标识着这个 commit point 对应的所有 segment file ,同时强行将 os cache 中目前所有的数据都 fsync 到磁盘文件中去。最后清空 现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。
这个 commit 操作叫做 flush 。默认 30 分钟自动执行一次 flush ,但如果 translog 过大,也会触发 flush 。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去。
translog 日志文件的作用是什么?你执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件 translog 中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。
translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
实际上你在这里,如果面试官没有问你 es 丢数据的问题,你可以在这里给面试官炫一把,你说,其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
---------------------------------------------------------------------------------------------------------
总结一下,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
数据写入 segment file 之后,同时就建立好了倒排索引。
05.删除/更新数据底层原理
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
buffer 每 refresh 一次,就会产生一个 segment file ,所以默认情况下是 1 秒钟一个 segment file ,这样下来 segment file 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,这里会写一个 commit point ,标识所有新的 segment file ,然后打开 segment file 供搜索使用,同时删除旧的 segment file 。
06.底层 lucene
简单来说,lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码。我们用 Java 开发的时候,引入 lucene jar,然后基于 lucene 的 api 去开发就可以了。
通过 lucene,我们可以将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。
07.倒排索引
在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。
那么,倒排索引就是关键词到文档 ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。
举个栗子。
有以下文档:
DocId Doc
1 谷歌地图之父跳槽 Facebook
2 谷歌地图之父加盟 Facebook
3 谷歌地图创始人拉斯离开谷歌加盟 Facebook
4 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关
5 谷歌地图之父拉斯加盟社交网站 Facebook
---------------------------------------------------------------------------------------------------------
对文档进行分词之后,得到以下倒排索引。
WordId Word DocIds
1 谷歌 1, 2, 3, 4, 5
2 地图 1, 2, 3, 4, 5
3 之父 1, 2, 4, 5
4 跳槽 1, 4
5 Facebook 1, 2, 3, 4, 5
6 加盟 2, 3, 5
7 创始人 3
8 拉斯 3, 5
9 离开 3
10 与 4
.. .. ..
另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 Facebook ,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
---------------------------------------------------------------------------------------------------------
要注意倒排索引的两个重要细节:
倒排索引中的所有词项对应一个或多个文档;
倒排索引中的词项根据字典顺序升序排列
上面只是一个简单的栗子,并没有严格按照字典顺序升序排列。
1.6 倒排索引
00.对比
a.概念区别
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
b.正向索引
a.优点
可以给多个字段创建索引
根据索引字段搜索、排序速度非常快
b.缺点
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
c.倒排索引
a.优点
根据词条搜索、模糊搜索时,速度非常快
b.缺点
只能给词条创建索引,而不是字段
无法根据字段做排序
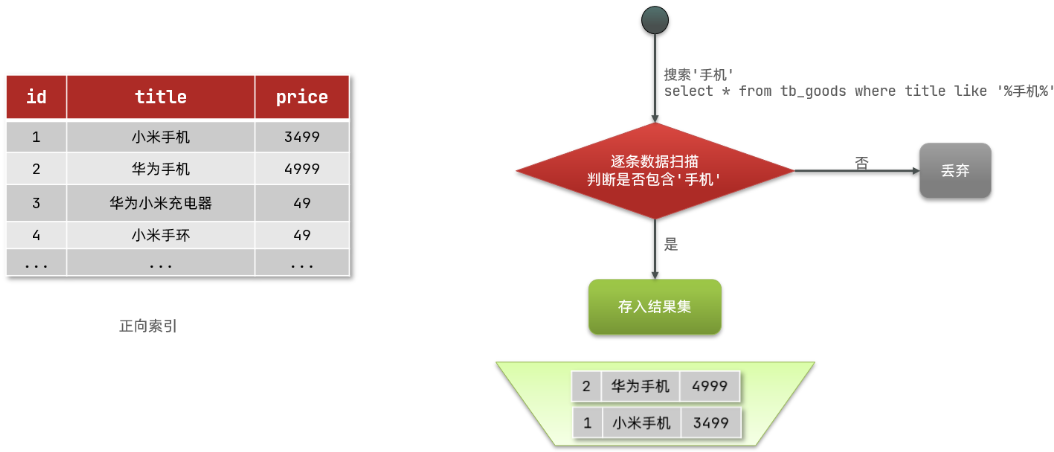
01.正向索引
a.介绍
设置了索引的话挺快的,但要是模糊查询则就很慢!
b.流程
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
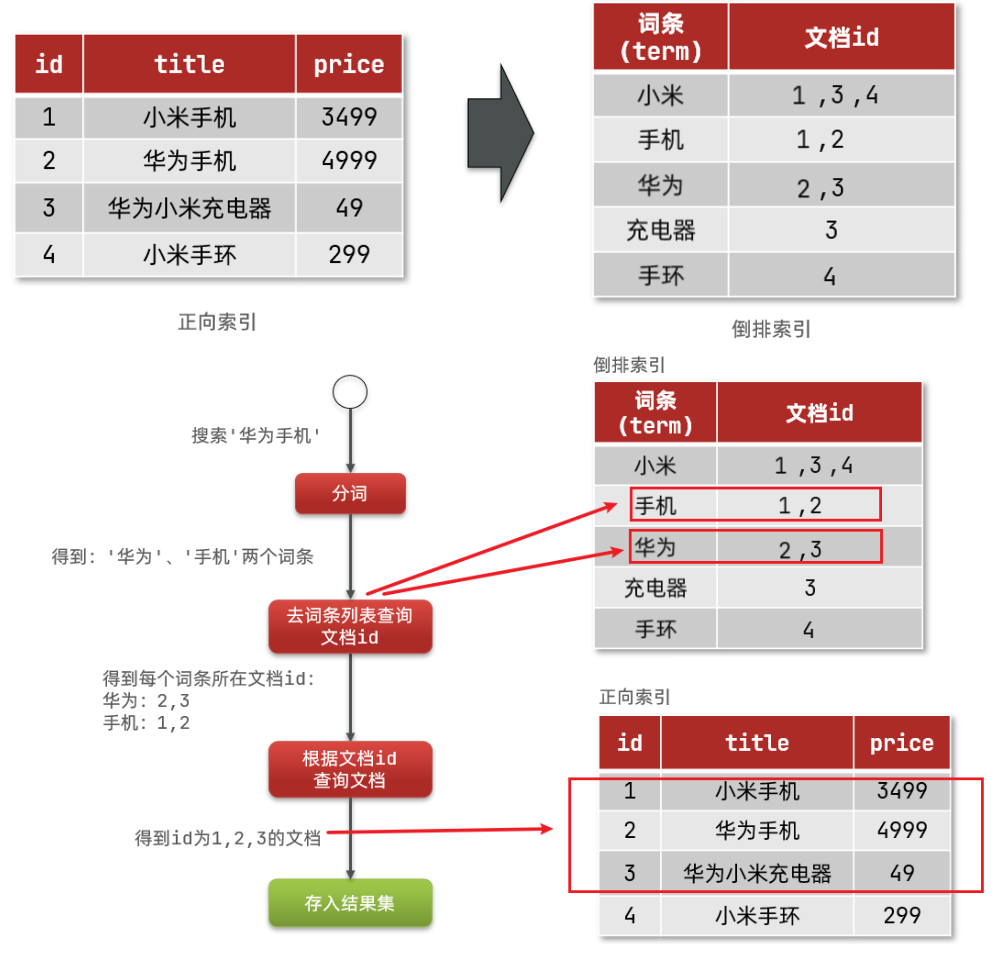
02.倒排索引
a.介绍
倒排索引中有两个非常重要的概念:
文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
b.创建倒排索引是对正向索引的一种特殊处理,流程如下:
将每一个文档的数据利用算法分词,得到一个个词条
创建表,每行数据包括词条、词条所在文档id、位置等信息
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
c.倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
d.总结
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
-----------------------------------------------------------------------------------------------------
一般来说,倒排索引分为两个部分:
单词词典(记录所有的文档词项,以及词项到倒排列表的关联关系)
倒排列表(记录单词与对应的关系,由一系列倒排索引项组成,
倒排索引项指:文档 id、
词频(TF)(词项在文档中出现的次数,评分时使用)、
位置(Position,词项在文档中分词的位置)、
偏移(记录词项开始和结束的位置)
)
正向索引
倒排索引
1.7 ES数据库
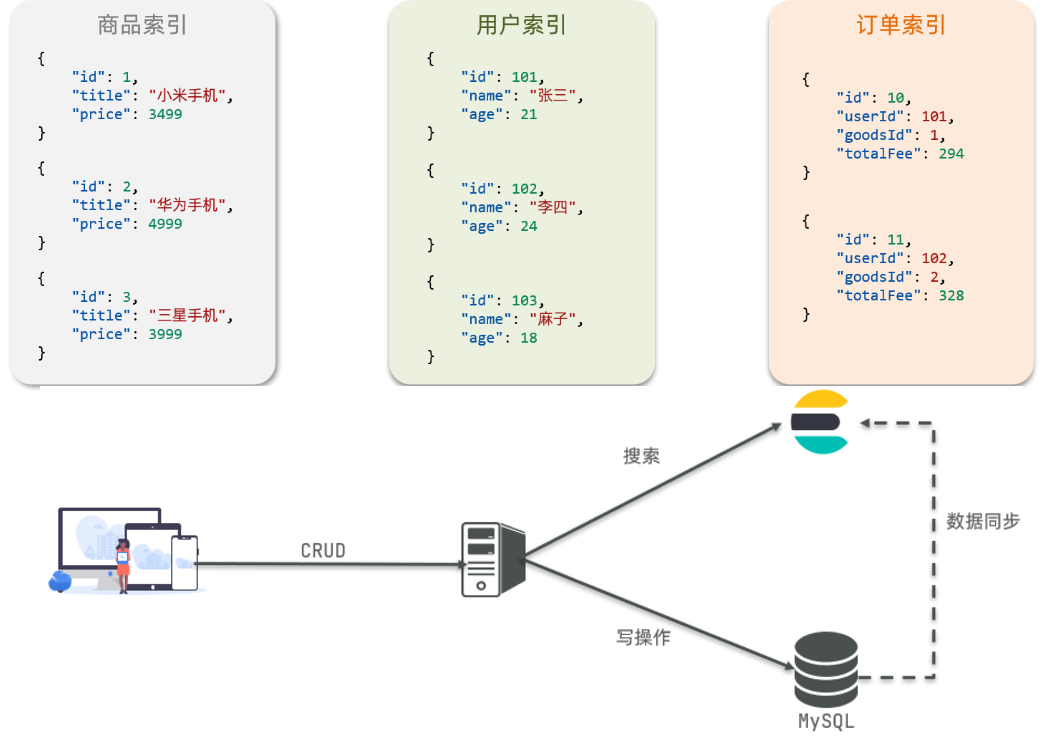
01.文档和字段
a.概念
一个文档就像数据库里的一条数据,字段就像数据库里的列
b.说明
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中,而Json文档中往往包含很多的字段(Field),类似于mysql数据库中的列。
02.索引和映射
a.概念
索引就像数据库里的表,映射就像数据库中定义的表结构
b.说明
索引(Index),就是相同类型的文档的集合【类似mysql中的表】
例如:
所有用户文档,就可以组织在一起,称为用户的索引;
所有商品的文档,可以组织在一起,称为商品的索引;
所有订单的文档,可以组织在一起,称为订单的索引;
-----------------------------------------------------------------------------------------------------
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。
因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
03.mysql与elasticsearch
a.概念
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
b.对比
| MySQL | Elasticsearch | 说明
|--------|---------------|----------------------------------------------------------
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table)
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column)
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD
c.在企业中,往往是两者结合使用:
对安全性要求较高的写操作,使用mysql实现
对查询性能要求较高的搜索需求,使用elasticsearch实现
两者再基于某种方式,实现数据的同步,保证一致性
文档和字段

索引和映射
1.8 锁和版本控制
01.介绍
a.概念
当我们使用 es 的 API 去进行文档更新时,它首先读取原文档出来,然后对原文档进行更新,
更新完成后再重新索引整个文档。不论你执行多少次更新,最终保存在 es 中的是最后一次更新的文档。
但是如果有两个线程同时去更新,就有可能出问题。
b.解决1:锁
a.悲观锁
很悲观,每一次去读取数据的时候,都认为别人可能会修改数据,所以屏蔽一切可能破坏数据完整性的操作。
关系型数据库中,悲观锁使用较多,例如行锁、表锁等等。
b.乐观锁
很乐观,每次读取数据时,都认为别人不会修改数据,因此也不锁定数据,只有在提交数据时,才会检查数据完整性。
这种方式可以省去锁的开销,进而提高吞吐量。
c.总结
在 es 中,实际上使用的就是乐观锁。
c.解决2:版本控制
a.介绍
在 es6.7 之前,使用 version+version_type 来进行乐观并发控制。
根据前面的介绍,文档每被修改一个,version 就会自增一次,es 通过 version 字段来确保所有的操作都有序进行。
version 分为内部版本控制和外部版本控制。
b.内部版本
es 自己维护的就是内部版本,当创建一个文档时,es 会给文档的版本赋值为 1。
每当用户修改一次文档,版本号就回自增 1。
如果使用内部版本,es 要求 version 参数的值必须和 es 文档中 version 的值相当,才能操作成功。
c.外部版本
在添加文档时,就指定版本号:
PUT blog/_doc/1?version=200&version_type=external
{
"title":"2222"
}
-------------------------------------------------------------------------------------------------
以后更新的时候,版本要大于已有的版本号。
vertion_type=external 或者 vertion_type=external_gt 表示以后更新的时候,版本要大于已有的版本号。
vertion_type=external_gte 表示以后更新的时候,版本要大于等于已有的版本号。
d.解决3:最新方案(Es6.7 之后)
a.介绍
现在使用 if_seq_no 和 if_primary_term 两个参数来做并发控制。
seq_no 不属于某一个文档,它是属于整个索引的(version 则是属于某一个文档的,每个文档的 version 互不影响)。
现在更新文档时,使用 seq_no 来做并发。由于 seq_no 是属于整个 index 的,所以任何文档的修改或者新增,
seq_no 都会自增。
b.现在就可以通过 seq_no 和 primary_term 来做乐观并发控制
PUT blog/_doc/2?if_seq_no=5&if_primary_term=1
{
"title":"6666"
}
2 ElasticSearch组成
2.1 汇总
01.组成
a.索引:表
创建索引库和映射
查询索引库
索引打开/关闭
复制索引
索引别名
修改索引库-字段
删除索引库
-----------------------------------------------------------------------------------------------------
修改索引库-副本数
修改索引库-切片数
修改索引库-读写权限
其他权限
b.映射:表结构
mapping组成
23个映射参数
动态映射
动态模板
静态映射
c.文档:行,一条数据
INSERT
QUERY
UPDATE
DELETE
Bulk
-----------------------------------------------------------------------------------------------------
文档路由
文档路由-指定routing
d.字段:列,字段的值
字符串类型:string、text、keyword、数字类型、long、integer、short、byte、double、float、half_float、scaled_float
日期类型
布尔类型
二进制类型
范围类型:integer_range、float_range、long_range、double_range、date_range、ip_range
复合类型
地理类型
特殊类型
02._命令1
a.分类1
a._settings
用途:查询和修改索引的设置。
示例:GET /your_index/_settings
b._mapping
用途:查询和修改索引的字段映射。
示例:GET /your_index/_mapping
c._search
用途:执行查询以检索索引中的文档。
示例:GET /your_index/_search
d._bulk
用途:批量执行多个索引、删除或更新操作。
示例:POST /your_index/_bulk
e._delete_by_query
用途:根据查询条件批量删除文档。
示例:POST /your_index/_delete_by_query
f._refresh
用途:手动刷新索引,使所有操作可见。
示例:POST /your_index/_refresh
g._cat
用途:用于监控集群和索引的状态,以可读格式显示信息。
示例:GET /_cat/indices
h._alias
用途:管理索引的别名。
示例:POST /_aliases
i._reindex
用途:将数据从一个索引复制到另一个索引。
示例:POST /_reindex
j._analyze
用途:分析文本,返回分词结果。
示例:POST /your_index/_analyze
b.分类2
a._cluster
用途:与集群状态、健康等相关的操作。
示例:GET /_cluster/health
b._nodes
用途:查看节点的状态和配置信息。
示例:GET /_nodes
c._template
用途:管理索引模板。
示例:GET /_template
d._snapshot
用途:管理快照和备份。
示例:GET /_snapshot
2.2 索引:表
00.查询索引
a.方式1:多个index、多个type 查询
GET /your_index/_settings --要获取某个索引的所有设置信息
GET /your_index/_settings/number_of_shards --如果你只想查询特定的设置(例如分片数和复制数),可以在请求中获取相关信息
GET /_settings --要查看集群中所有索引的设置
GET /index1,index2/_settings --可以查询多个索引的设置
GET /your_index/_settings/analysis --如果索引中定义了分析器,想要查看分析器的详细设置
-----------------------------------------------------------------------------------------------------
GET /twitter/_search?q=user:shay --搜索 twitter 索引下面所有匹配条件的所有类型中文档
GET /twitter/tweet,user/_search?q=user:banon --一个索引下面指定多个 type 下匹配条件的文档
GET /twitter,elasticsearch/_search?q=tag:wow --搜索多个索引下匹配条件的文档
GET /_all/_search?q=tag:wow --搜索所有索引下匹配条件的文档
GET /_search?q=tag:wow --搜索所有索引及所有 type 下匹配条件的文档
-----------------------------------------------------------------------------------------------------
GET kibana_sample_data_ecommerce --查看索引相关信息
GET kibana_sample_data_ecommerce/_count --查看索引的文档总数
GET kibana_sample_data_ecommerce/_search --查看前10条文档,了解文档格式
GET /_cat/indices/kibana*?v&s=index --查看indices
GET /_cat/indices?v&health=green --查看状态为绿的索引
GET /_cat/indices?v&s=docs.count:desc --按照文档个数排序
GET /_cat/indices/kibana*?pri&v&h=health,index --查看具体的字段
GET /_cat/indices?v&h=i,tm&s=tm:desc --查看索引占用的内存
-----------------------------------------------------------------------------------------------------
集群 API
# 如果没有给出过滤器,默认是查询所有节点
GET /_nodes
# 查询所有节点
GET /_nodes/_all
# 查询本地节点
GET /_nodes/_local
# 查询主节点
GET /_nodes/_master
# 根据名称查询节点(支持通配符)
GET /_nodes/node_name_goes_here
GET /_nodes/node_name_goes_*
# 根据地址查询节点(支持通配符)
GET /_nodes/10.0.0.3,10.0.0.4
GET /_nodes/10.0.0.*
# 根据规则查询节点
GET /_nodes/_all,master:false
GET /_nodes/data:true,ingest:true
GET /_nodes/coordinating_only:true
GET /_nodes/master:true,voting_only:false
# 根据自定义属性查询节点(如:查询配置文件中含 node.attr.rack:2 属性的节点)
GET /_nodes/rack:2
GET /_nodes/ra*:2
GET /_nodes/ra*:2*
-----------------------------------------------------------------------------------------------------
集群健康 API
GET /_cluster/health
GET /_cluster/health?level=shards
GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights
GET /_cluster/health/kibana_sample_data_flights?level=shards
-----------------------------------------------------------------------------------------------------
集群状态 API 返回表示整个集群状态的元数据。
GET /_cluster/state
-----------------------------------------------------------------------------------------------------
集群状态 API 返回表示整个集群状态的元数据。
GET /_cluster/state
-----------------------------------------------------------------------------------------------------
节点 API
# 查看默认的字段
GET /_cat/nodes?v=true
# 查看指定的字段
GET /_cat/nodes?v=true&h=id,ip,port,v,m
-----------------------------------------------------------------------------------------------------
分片 API
# 查看默认的字段
GET /_cat/shards
# 根据名称查询分片(支持通配符)
GET /_cat/shards/my-index-*
# 查看指定的字段
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason
-----------------------------------------------------------------------------------------------------
监控 API
通过 GET 请求发送 cat,下面列出了所有可用的 API:
GET /_cat
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
b.方式2:URI 搜索
Elasticsearch 支持用 uri 搜索,可用 get 请求里面拼接相关的参数,并用 curl 相关的命令就可以进行测试。
-----------------------------------------------------------------------------------------------------
GET twitter/_search?q=user:kimchy
{
"timed_out": false,
"took": 62,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.3862944,
"hits": [
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 1.3862944,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
-----------------------------------------------------------------------------------------------------
URI 中允许的参数:
名称 描述
q 查询字符串,映射到 query_string 查询
df 在查询中未定义字段前缀时使用的默认字段
analyzer 查询字符串时指定的分词器
analyze_wildcard 是否允许通配符和前缀查询,默认设置为 false
batched_reduce_size 应在协调节点上一次减少的分片结果数。如果请求中潜在的分片数量很大,则应将此值用作保护机制,以减少每个搜索请求的内存开销
default_operator 默认使用的匹配运算符,可以是AND或者OR,默认是OR
lenient 如果设置为 true,将会忽略由于格式化引起的问题(如向数据字段提供文本),默认为 false
explain 对于每个 hit,包含了具体如何计算得分的解释
_source 请求文档内容的参数,默认 true;设置 false 的话,不返回_source 字段,可以使用**_source_include和_source_exclude**参数分别指定返回字段和不返回的字段
stored_fields 指定每个匹配返回的文档中的存储字段,多个用逗号分隔。不指定任何值将导致没有字段返回
sort 排序方式,可以是fieldName、fieldName:asc或者fieldName:desc的形式。fieldName 可以是文档中的实际字段,也可以是诸如_score 字段,其表示基于分数的排序。此外可以指定多个 sort 参数(顺序很重要)
track_scores 当排序时,若设置 true,返回每个命中文档的分数
track_total_hits 是否返回匹配条件命中的总文档数,默认为 true
timeout 设置搜索的超时时间,默认无超时时间
terminate_after 在达到查询终止条件之前,指定每个分片收集的最大文档数。如果设置,则在响应中多了一个 terminated_early 的布尔字段,以指示查询执行是否实际上已终止。默认为 no terminate_after
from 从第几条(索引以 0 开始)结果开始返回,默认为 0
size 返回命中的文档数,默认为 10
search_type 搜索的方式,可以是dfs_query_then_fetch或query_then_fetch。默认为query_then_fetch
allow_partial_search_results 是否可以返回部分结果。如设置为 false,表示如果请求产生部分结果,则设置为返回整体故障;默认为 true,表示允许请求在超时或部分失败的情况下获得部分结果
pretty 美化,GET /kibana_sample_data_ecommerce/_search?pretty=true
01.索引库的CRUD
a.CRUD简单描述
创建索引库:PUT /索引库名
查询索引库:GET /索引库名
删除索引库:DELETE /索引库名
修改索引库(添加字段):PUT /索引库名/_mapping
-----------------------------------------------------------------------------------------------------
索引名称不能有大写字母
索引名是唯一的,不能重复,重复创建会出错
-----------------------------------------------------------------------------------------------------
Kibana的Dev Tools,执行相关的DSL命令
b.创建索引库和映射
PUT /heima
{
"mappings": {
"properties": {
"column1":{
"type": "text",
"analyzer": "ik_smart"
},
"column2":{
"type": "keyword",
"index": "false"
},
"column3":{
"properties": {
"子字段1": {
"type": "keyword"
},
"子字段2": {
"type": "keyword"
}
}
}
}
}
}
c.查询索引库
GET /heima
GET /heima/_settings --heima
GET /heima,test/_settings --heima,test
GET /_all/_settings --全部
d.索引打开/关闭
同时关闭/打开多个索引,多个索引用 , 隔开,或者直接使用 _all 代表所有索引
POST /heima/_close --关闭索引
POST /heima/_open --打开索引
e.复制索引
索引复制,只会复制数据,不会复制索引配置。
POST _reindex
{
"source": {"index":"heima"},
"dest": {"index":"heima_new"}
}
f.索引别名
为索引创建别名,如果这个别名是唯一的,该别名可以代替索引名称。
POST /_aliases
{
"actions": [
{
"add": {
"index": "heima",
"alias": "heima_alias"
}
}
]
}
-----------------------------------------------------------------------------------------------------
将 add 改为 remove 就表示移除别名:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "heima",
"alias": "heima_alias"
}
}
]
}
-----------------------------------------------------------------------------------------------------
查看某一个索引的别名:
GET /heima/_alias
-----------------------------------------------------------------------------------------------------
查看某一个别名对应的索引(book_alias 表示一个别名):
GET /heima_alias/_alias
-----------------------------------------------------------------------------------------------------
可以查看集群上所有可用别名:
GET /_alias
g.修改索引库-字段
这里的修改是只能增加新的字段到mapping中
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。
因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
-----------------------------------------------------------------------------------------------------
PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
h.删除索引库
DELETE /heima
DELETE /index_one,index_two
DELETE /index_*
02.索引库的配置
a.修改索引库-副本数
PUT /heima/_settings
{
"number_of_replicas": 2
}
b.修改索引库-切片数
PUT /heima/_settings
{
"number_of_shards": 2
}
c.修改索引库-读写权限
PUT /heima/_settings
{
"blocks.write": true
}
d.其他权限
blocks.write
blocks.read
blocks.read_only
-------------------------------------------------------------------------------------------------------------
01.字段数据类型
a.普通类型
binary (opens new window):编码为 Base64 字符串的二进制值。
boolean (opens new window):布尔类型,值为 true 或 false。
Keywords (opens new window):keyword 族类型,包括 keyword、constant_keyword 和 wildcard。
Numbers (opens new window):数字类型,如 long 和 double
Dates:日期类型,包括 date (opens new window)和 date_nanos (opens new window)。
alias (opens new window):用于定义存在字段的别名。
b.对象类型
object (opens new window):JSON 对象
flattened (opens new window):整个 JSON 对象作为单个字段值。
nested (opens new window):保留其子字段之间关系的 JSON 对象。
join (opens new window):为同一索引中的文档定义父/子关系。
c.结构化数据类型
Range (opens new window):范围类型,例如:long_range、double_range、date_range 和 ip_range。
ip (opens new window):IPv4 和 IPv6 地址。
version (opens new window):版本号。支持 Semantic Versioning (opens new window)优先规则。
murmur3 (opens new window):计算并存储 hash 值。
d.聚合数据类型
aggregate_metric_double (opens new window):预先聚合的指标值
histogram (opens new window):直方图式的预聚合数值。
e.文本搜索类型
text fields (opens new window):text 族类型,包括 text 和 match_only_text。
annotated-text (opens new window):包含特殊标记的文本。用于识别命名实体。
completion (opens new window):用于自动补全。
search_as_you_type (opens new window):键入时完成的类似文本的类型。
token_count (opens new window):文本中标记的计数。
f.文档排名类型
dense_vector (opens new window):记录浮点数的密集向量。
rank_feature (opens new window):记录一个数字特征,为了在查询时提高命中率。
rank_features (opens new window):记录多个数字特征,为了在查询时提高命中率。
g.空间数据类型
geo_point (opens new window):地理经纬度
geo_shape (opens new window):复杂的形状,例如多边形
point (opens new window):任意笛卡尔点
shape (opens new window):任意笛卡尔几何形状
h.其他类型
percolator (opens new window):使用 Query DSL (opens new window)编写的索引查询
02.元数据字段
a.标识元数据字段
_index (opens new window):文档所属的索引。
_id (opens new window):文档的 ID。
b.文档 source 元数据字段
_source (opens new window):文档正文的原始 JSON。
_size (opens new window):_source 字段的大小(以字节为单位),由 mapper-size (opens new window)插件提供。
c.文档计数元数据字段
_doc_count (opens new window):当文档表示预聚合数据时,用于存储文档计数的自定义字段。
d.索引元数据字段
_field_names (opens new window):文档中的所有非空字段。
_ignored (opens new window):文档中所有的由于 ignore_malformed (opens new window)而在索引时被忽略的字段。
e.路由元数据字段
_routing (opens new window):将文档路由到特定分片的自定义路由值。
f.其他元数据字段
_meta (opens new window):应用程序特定的元数据。
_tier (opens new window):文档所属索引的当前数据层首选项。
03.映射参数
a.分类1
analyzer (opens new window):指定在索引或搜索文本字段时用于文本分析的分析器。
coerce (opens new window):如果开启,Elasticsearch 将尝试清理脏数据以适应字段的数据类型。
copy_to (opens new window):允许将多个字段的值复制到一个组字段中,然后可以将其作为单个字段进行查询。
doc_values (opens new window):默认情况下,所有字段都是被
dynamic (opens new window):是否开启动态映射。
b.分类2
eager_global_ordinals (opens new window):当在 global ordinals 的时候,refresh 以后下一次查询字典就需要重新构建,在追求查询的场景下很影响查询性能。可以使用 eager_global_ordinals,即在每次 refresh 以后即可更新字典,字典常驻内存,减少了查询的时候构建字典的耗时。
enabled (opens new window):只能应用于顶级 mapping 定义和 object 字段。设置为 false 后,Elasticsearch 解析时,会完全跳过该字段。
fielddata (opens new window):默认情况下, text 字段是可搜索的,但不可用于聚合、排序或脚本。如果为字段设置 fielddata=true,就会通过反转倒排索引将 fielddata 加载到内存中。请注意,这可能会占用大量内存。如果想对 text 字段进行聚合、排序或脚本操作,fielddata 是唯一方法。
fields (opens new window):有时候,同一个字段需要以不同目的进行索引,此时可以通过 fields 进行配置。
format (opens new window):用于格式化日期类型。
c.分类3
ignore_above (opens new window):字符串长度大于 ignore_above 所设,则不会被索引或存储。
ignore_malformed (opens new window):有时候,同一个字段,可能会存储不同的数据类型。默认情况下,Elasticsearch 解析字段数据类型失败时,会引发异常,并拒绝整个文档。 如果设置 ignore_malformed 为 true,则允许忽略异常。这种情况下,格式错误的字段不会被索引,但文档中的其他字段可以正常处理。
index_options (opens new window)用于控制将哪些信息添加到倒排索引以进行搜索和突出显示。只有 text 和 keyword 等基于术语(term)的字段类型支持此配置。
index_phrases (opens new window):如果启用,两个词的组合(shingles)将被索引到一个单独的字段中。这允许以更大的索引为代价,更有效地运行精确的短语查询(无 slop)。请注意,当停用词未被删除时,此方法效果最佳,因为包含停用词的短语将不使用辅助字段,并将回退到标准短语查询。接受真或假(默认)。
index_prefixes (opens new window):index_prefixes 参数启用 term 前缀索引以加快前缀搜索。
d.分类4
index (opens new window):index 选项控制字段值是否被索引。默认为 true。
meta (opens new window):附加到字段的元数据。此元数据对 Elasticsearch 是不透明的,它仅适用于多个应用共享相同索引的元数据信息,例如:单位。
normalizer (opens new window):keyword 字段的 normalizer 属性类似于 analyzer (opens new window),只是它保证分析链只产生单个标记。 normalizer 在索引 keyword 之前应用,以及在搜索时通过查询解析器(例如匹配查询)或通过术语级别查询(例如术语查询)搜索关键字字段时应用。
norms (opens new window):norms 存储在查询时使用的各种规范化因子,以便计算文档的相关性评分。
null_value (opens new window):null 值无法被索引和搜索。当一个字段被设为 null,则被视为没有值。null_value 允许将空值替换为指定值,以便对其进行索引和搜索。
e.分类5
position_increment_gap (opens new window):分析的文本字段会考虑术语位置,以便能够支持邻近或短语查询。当索引具有多个值的文本字段时,值之间会添加一个“假”间隙,以防止大多数短语查询在值之间匹配。此间隙的大小使用 position_increment_gap 配置,默认为 100。
properties (opens new window):类型映射、对象字段和嵌套字段包含的子字段,都称为属性。这些属性可以是任何数据类型,包括对象和嵌套。
search_analyzer (opens new window):通常,在索引时和搜索时应使用相同的分析器,以确保查询中的术语与倒排索引中的术语格式相同。但是,有时在搜索时使用不同的分析器可能是有意义的,例如使用 edge_ngram (opens new window)标记器实现自动补全或使用同义词搜索时。
similarity (opens new window):Elasticsearch 允许为每个字段配置文本评分算法或相似度。相似度设置提供了一种选择文本相似度算法的简单方法,而不是默认的 BM25,例如布尔值。只有 text 和 keyword 等基于文本的字段类型支持此配置。
store (opens new window):默认情况下,对字段值进行索引以使其可搜索,但不会存储它们。这意味着可以查询该字段,但无法检索原始字段值。通常这不重要,字段值已经是默认存储的 _source 字段的一部分。如果您只想检索单个字段或几个字段的值,而不是整个 _source,则可以通过 source filtering (opens new window)来实现。
term_vector (opens new window):term_vector 包含有关分析过程产生的术语的信息,包括:术语列表、每个 term 的位置(或顺序)、起始和结束字符偏移量,用于将 term 和原始字符串进行映射、有效负载(如果可用) - 用户定义的,与 term 位置相关的二进制数据
04.映射配置
index.mapping.total_fields.limit:索引中的最大字段数。字段和对象映射以及字段别名计入此限制。默认值为 1000。
index.mapping.depth.limit:字段的最大深度,以内部对象的数量来衡量。例如,如果所有字段都在根对象级别定义,则深度为 1。如果有一个对象映射,则深度为 2,以此类推。默认值为 20。
index.mapping.nested_fields.limit:索引中不同 nested 映射的最大数量。 nested 类型只应在特殊情况下使用,即需要相互独立地查询对象数组。为了防止设计不佳的映射,此设置限制了每个索引的唯一 nested 类型的数量。默认值为 50。
index.mapping.nested_objects.limit:单个文档中,所有 nested 类型中包含的最大嵌套 JSON 对象数。当文档包含太多 nested 对象时,此限制有助于防止出现内存溢出。默认值为 10000。
index.mapping.field_name_length.limit:设置字段名称的最大长度。默认为 Long.MAX_VALUE(无限制)。
2.3 映射:表结构
00.查询映射
a.查询整个索引的映射
GET /your_index/_mapping --要获取某个索引的所有映射信息
b.查询特定字段的映射
GET /your_index/_mapping/field/your_field_name --如果只想查询特定字段的映射信息,可以在请求中指定字段名
c.查询多个字段的映射
GET /your_index/_mapping/field/field1,field2 --可以一次性查询多个字段的映射
d.查询所有索引的映射
GET /_mapping --要查看集群中所有索引的映射
e.查询指定类型的映射(如果适用)
GET /your_index/_mapping/your_type_name --在使用类型的版本中,可以查询特定类型的映射(Elasticsearch 7.x 之后不再支持类型)
f.使用嵌套字段的映射查询
GET /your_index/_mapping/field/name.firstName --对于嵌套字段,你可以指定路径查询映射信息
00.Mapping映射
a.mapping组成
a.组成1:metadata元数据字段用于自定义如何处理文档关联的元数据。例如:
_index:用于定义document属于哪个index
_type:类型,已经移除的概念
_id:document的唯一id
_source:存放原始的document数据
_size:_source字段中存放的数据的大小
b.组成2:mapping中包含的field,包含字段的类型和参数。本文主要介绍的mapping参数就需要在field中去定义。例如:
type:设置字段对应的类型,常见的有text,keyword等
analyzer:指定一个用来文本分析的索引或者搜索text字段的分析器 应用于索引以及查询
c.常见的mapping属性
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址),keyword类型只能整体搜索,不支持搜索部分内容
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器
properties:该字段的子字段
b.23个映射参数
a.分类1
analyzer(分析器):定义字段使用的分析器,决定如何将文本拆分为词条。
normalizer(归一化器):主要用于 keyword 类型的字段,指定一个归一化器来处理统一大小写、去除空格等。
boost(提升):为字段指定权重,影响搜索结果中的相关性评分。
coerce(强制类型转换):如果设置为 true,Elasticsearch 会尝试将值强制转换为正确的类型(如将字符串转换为数字)。
copy_to(合并参数):将字段的值复制到另一个字段中,通常用于聚合搜索条件。
b.分类2
doc_values(文档值):用于排序、聚合和脚本的预先计算的值,通常 keyword 和 numeric 类型使用它。
dynamic(动态设置):定义是否允许动态添加字段(true/false/strict)。
enabled(开启字段):用于完全启用或禁用一个字段。如果 enabled: false,字段不会被索引。
fielddata(字段数据):用于在 text 类型字段上启用排序和聚合。
format(日期格式):为 date 类型字段指定日期格式(如 yyyy-MM-dd)。
c.分类3
ignore_above(忽略超越限制的字段):忽略超过指定长度的字符串,常用于 keyword 类型字段。
ignore_malformed(忽略格式不对的数据):忽略格式不正确的字段值,避免引发错误。
include_in_all(_all 查询包含字段):已废弃,早期用于控制字段是否包含在 _all 字段中进行全文搜索。
index_options(索引设置):定义索引时记录哪些信息,通常是 docs、freqs 或 positions。
index(索引):控制字段是否可被索引,如果设置为 false,该字段不能用于搜索。
d.分类4
fields(字段):允许为同一个字段定义多种表示形式,比如文本字段可以有 text 和 keyword 两种类型。
norms(标准信息):控制是否存储归一化信息(用于相关性评分),通常对 text 类型字段有用。
null_value(空值):为 null 值指定一个默认值,防止 null 值引起查询问题。
position_increment_gap(短语位置间隙):定义在多个值之间的短语查询时的间隔。
properties(属性):用于定义复杂对象(如 object 或 nested 类型)的子字段。
e.分类5
search_analyzer(搜索分析器):为字段指定搜索时使用的分析器(可以不同于索引时的分析器)。
similarity(相似度模型):控制字段的相似度计算方式,常见的有 BM25 和 classic 等模型。
store(存储):控制字段是否以源文档之外的方式单独存储,通常是 false。
term_vectors(词根信息):定义是否存储字段的词条向量及其位置信息、偏移信息等,通常用于高级搜索和分析。
c.示例
a.例如下面的json文档
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "真相只有一个!",
"email": "zy@itcast.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "柯",
"lastName": "南"
}
}
b.对应的每个字段映射(mapping)
age:类型为 integer;参与搜索,因此需要index为true;无需分词器
weight:类型为float;参与搜索,因此需要index为true;无需分词器
isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
name:类型为object,需要定义多个子属性
name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
d.es中动态映射类型推断方式如下
JSON中的数据 自动推断出来的数据类型
null 没有字段被添加
true/false boolean
浮点数字 float
数字 long
JSON对象 object
数组 数组中的第一个非空值来决定
string text/keyword/date/double/long都有可能
-------------------------------------------------------------------------------------------------------------
01.动态映射
a.介绍
顾名思义,就是自动创建出来的映射。es 根据存入的文档,自动分析出来文档中字段的类型以及存储方式,这种就是动态映射。
在创建好的索引信息中,可以看到,mappings 为空,这个 mappings 中保存的就是映射信息。
-----------------------------------------------------------------------------------------------------
现在我们向索引中添加一个文档,如下:
PUT blog/_doc/1
{
"title":"1111",
"date":"2020-11-11"
}
-----------------------------------------------------------------------------------------------------
文档添加成功后,就会自动生成 Mappings
可以看到,date 字段的类型为 date,title 的类型有两个,text 和 keyword。
,文档中如果新增了字段,mappings 中也会自动新增进来。
b.动态映射还有一个日期检测的问题
例如新建一个索引,然后添加一个含有日期的文档,如下:
PUT blog/_doc/1
{
"remark":"2020-11-11"
}
-----------------------------------------------------------------------------------------------------
添加成功后,remark 字段会被推断是一个日期类型。
-----------------------------------------------------------------------------------------------------
此时,remark 字段就无法存储其他类型了。
PUT blog/_doc/1
{
"remark":"javaboy"
}
-----------------------------------------------------------------------------------------------------
此时报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'javaboy'"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'javaboy'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [javaboy] with format [strict_date_optional_time||epoch_millis]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "Failed to parse with all enclosed parsers"
}
}
},
"status" : 400
}
-----------------------------------------------------------------------------------------------------
要解决这个问题,可以使用静态映射,即在索引定义时,将 remark 指定为 text 类型。也可以关闭日期检测。
PUT blog
{
"mappings": {
"date_detection": false
}
}
此时日期类型就回当成文本来处理。
c.es中动态映射类型推断方式如下
JSON中的数据 自动推断出来的数据类型
null 没有字段被添加
true/false boolean
浮点数字 float
数字 long
JSON对象 object
数组 数组中的第一个非空值来决定
string text/keyword/date/double/long都有可能
02.动态模板
a.介绍
在Elasticsearch中,动态模板(Dynamic Templates) 是一种用于自动处理字段映射的机制。
它允许你为新添加的字段动态定义其映射,而不需要在每次添加新字段时显式地定义其映射。
b.动态模板通常用于以下场景:
处理多种类型的文档,尤其是字段名称和类型不确定的情况。
根据字段名称或数据类型自动设置字段的映射属性。
c.示例 1:根据字段类型定义动态模板
在这个示例中,所有字符串类型的字段都将被映射为 text 类型,而所有数字类型的字段都将被映射为 float 类型。
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_text": {
"match_mapping_type": "string", // 匹配所有字符串类型
"mapping": {
"type": "text" // 将其映射为 text 类型
}
}
},
{
"numbers_as_float": {
"match_mapping_type": "long", // 匹配所有长整型
"mapping": {
"type": "float" // 将其映射为 float 类型
}
}
}
]
}
}
d.示例 2:根据字段名称定义动态模板
在这个示例中,所有以 date_ 开头的字段将被映射为 date 类型,所有以 user_ 开头的字段将被映射为 keyword 类型。
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
"dates": {
"match": "date_*", // 匹配以 date_ 开头的字段
"mapping": {
"type": "date" // 将其映射为 date 类型
}
}
},
{
"users": {
"match": "user_*", // 匹配以 user_ 开头的字段
"mapping": {
"type": "keyword" // 将其映射为 keyword 类型
}
}
}
]
}
}
e.示例 3:更复杂的动态模板
以下示例展示了一个更复杂的动态模板,可以根据字段名称和类型同时进行匹配。
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string", // 匹配所有字符串类型
"mapping": {
"type": "text",
"analyzer": "ik_max_word" // 使用 IK 分词器
}
}
},
{
"numbers": {
"match_mapping_type": "float", // 匹配所有浮点数类型
"mapping": {
"type": "float",
"null_value": 0.0 // 将 null 值转换为 0.0
}
}
}
]
}
}
03.静态映射
a.dynamic属性
有的时候,如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic 属性来配置。
dynamic 属性有三种取值:
true,默认即此。自动添加新字段。
false,忽略新字段。
strict,严格模式,发现新字段会抛出异常。
b.具体配置方式如下,创建索引时指定 mappings(这其实就是静态映射)
PUT blog
{
"mappings": {
"dynamic":"strict",
"properties": {
"title":{
"type": "text"
},
"age":{
"type":"long"
}
}
}
}
-----------------------------------------------------------------------------------------------------
然后向 blog 中索引中添加数据:
PUT blog/_doc/2
{
"title":"1111",
"date":"2020-11-11",
"age":99
}
-----------------------------------------------------------------------------------------------------
在添加的文档中,多出了一个 date 字段,而该字段没有预定义,所以这个添加操作就回报错
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
},
"status" : 400
}
-------------------------------------------------------------------------------------------------------------
01.analyzer(分析器):定义字段使用的分析器,决定如何将文本拆分为词条。
a.介绍
a.概念
指定分词器。elasticsearch是一款支持全文检索的分布式存储系统,对于text类型的字段,
首先会使用分词器进行分词,然后将分词后的词根一个一个存储在倒排索引中,后续查询主要是针对词根的搜索。
b.analyzer该参数可以在查询、字段、索引级别中指定,其优先级如下(越靠前越优先)
1.字段上定义的分词器
2.索引配置中定义的分词器
3.默认分词器(standard)
c.在查询上下文,分词器的查找优先为
1.full-text query中定义的分词器
2.定义类型映射时字段中search_analyzer定义的分词器
3.定义字段映射时analyzer定义的分词器
4.索引中default_search中定义的分词器
5.索引中默认定义的分词器
6.标准分词器(standard)
d.analyzer:指定字段在索引时如何分词。search_analyzer:指定字段在搜索时如何分词。
查询时候的分词器。
默认情况下,如果没有配置search_analyzer,则查询时,首先查看有没有search_analyzer,有的话,就用search_analyzer来进行分词,
如果没有,则看有没有analyzer,如果有,则用analyzer来进行分词,否则使用es默认的分词器。
-------------------------------------------------------------------------------------------------
search_analyzer 不是分词器本身,而是用于指定搜索时使用的分词器。
当你对一个字段进行搜索时,search_analyzer 控制输入的查询文本如何被分词,
而这个分词器可以与索引时使用的分词器(analyzer)不同
-------------------------------------------------------------------------------------------------
两者可以是相同的,也可以不同。
比如,通常你可能希望在索引时使用一个分词精度更高的分词器,而在搜索时使用一个简单的分词器以提高搜索性能。
-----------------------------------------------------------------------------------------------------
假设你有一个文本字段,你希望在索引时使用精细的 ik_max_word 分词器,而在搜索时使用较简单的 ik_smart 分词器,可以这样配置
PUT /my_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
在索引文档时,Elasticsearch 会使用 analyzer 定义的分词器将字段内容进行分词和存储。
在用户进行查询时,Elasticsearch 会使用 search_analyzer 定义的分词器来处理查询词。
b.假设不用分词器,我们先来看一下索引的结果
a.创建一个索引并添加一个文档
# 添加索引
PUT /blog
# 添加文档
PUT /blog/_doc/1
{
"title": "定义文本字段的分词器。默认对索引l和查询都是有效的。"
}
b.查看词条向量(_termvectors)
GET /blog/_termvectors/1
{
"fields": ["title"]
}
-------------------------------------------------------------------------------------------------
可以看到,默认情况下,中文就是一个字一个字的分,这种分词方式没有任何意义。
c.如果这样分词,查询就只能按照一个字一个字来查,像下面这样
GET /blog/_search
{
"query": {
"term": {
"title": "定"
}
}
}
-------------------------------------------------------------------------------------------------
无意义
c.配置合适分词器
a.设置ik_smart
PUT blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
b.存储文档
PUT /blog/_doc/1
{
"title": "定义文本字段的分词器。默认对索引l和查询都是有效的。"
}
c.查看词条向量(_termvectors)
GET /blog/_termvectors/1
{
"fields": ["title"]
}
-------------------------------------------------------------------------------------------------
"都是" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 20,
"end_offset" : 22
}
]
},
"默认" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 11,
"end_offset" : 13
}
]
d.查询_search
GET /blog/_search
{
"query": {
"term": {
"title": "定"
}
}
}
-------------------------------------------------------------------------------------------------
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "定义文本字段的分词器。默认对索引l和查询都是有效的。"
}
}
]
}
}
02.normalizer(归一化器):主要用于 keyword 类型的字段,指定一个归一化器来处理统一大小写、去除空格等。
a.介绍
normalizer参数用于解析前(索引或者查询)的标准化配置。
比如,在es中,对于一些我们不想切分的字符串,我们通常会将其设置为keyword,搜索时候也是使用整个词进行搜索。
如果在索引前 没有做好数据清洗,导致大小写不一致,例如javaboy和JAVABOY,
此时,我们就可以使用normalizer在索引之前以及查询之前进行文档的标准化。
-----------------------------------------------------------------------------------------------------
规划化,主要针对keyword类型,在索引该字段或查询字段之前,
可以先对原始数据进行一些简单的处理,然后再将处理后的结果当成一个词根存入倒排索引中
b.示例
PUT index
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": { // @1
"type": "custom",
"char_filter": [],
"filter": ["lowercase", "asciifolding"] // @2
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer" // @3
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
代码@1:首先在settings中的analysis属性中定义normalizer。
代码@2:设置标准化过滤器,示例中的处理器为小写、asciifolding。
代码@3:在定义映射时,如果字段类型为keyword,可以使用normali
zer引用定义好的normalizer。
03.boost(提升):为字段指定权重,影响搜索结果中的相关性评分。
a.介绍
权重值,可以提升在查询时的权重,对查询相关性有直接的影响,其默认值为1.0。其影响范围为词根查询(team que-ry),对前缀、范围查询、全文索引(match query)不生效。
注意:不建议在创建索引映射时使用boost属性,而是在查询时通过boost参数指定。其主要原因如下:
无法动态修改字段中定义的boost值,除非使用reindex命令重建索引。
相反,如果在查询时指定boost值,每一个查询都可以使用不同的boost值,灵活。
在索引中指定boost值,boost存储在记录中,从而会降低分数计算的质量。
-----------------------------------------------------------------------------------------------------
boost 参数可以设置字段的权重。
boost 有两种使用思路,一种就是在定义 mappings 的时候使用,在指定字段类型时使用;另一种就是在查询时使用。
实际开发中建议使用后者,前者有问题:如果不重新索引文档,权重无法修改。
b.mapping 中使用 boost(不推荐)
PUT blog
{
"mappings": {
"properties": {
"content":{
"type": "text",
"boost": 2
}
}
}
}
c.另一种方式就是在查询的时候,指定 boost
GET blog/_search
{
"query": {
"match": {
"content": {
"query": "你好",
"boost": 2
}
}
}
}
04.coerce(强制类型转换):如果设置为 true,Elasticsearch 会尝试将值强制转换为正确的类型(如将字符串转换为数字)。
a.介绍
是否进行类型“隐式转换”。es最终存储文档的格式是字符串。
coerce 用来清除脏数据,默认为 true。
b.示例1
例如一个数字,在 JSON 中,用户可能写错了:
{"age":"99"}
或者 :
{"age":"99.0"}
这些都不是正确的数字格式。
-----------------------------------------------------------------------------------------------------
通过 coerce 可以解决该问题。
默认情况下,以下操作没问题,就是 coerce 起作用:
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer"
}
}
}
}
POST blog/_doc
{
"age":"99.0"
}
-----------------------------------------------------------------------------------------------------
如果需要修改 coerce ,方式如下:
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"coerce": false
}
}
}
}
POST blog/_doc
{
"age":99
}
-----------------------------------------------------------------------------------------------------
当 coerce 修改为 false 之后,数字就只能是数字了,不可以是字符串,该字段传入字符串会报错。
c.示例2
例如存在如下字段类型:
"number_one": {
"type": "integer"
}
声明number_one字段的类型为数字类型,那是否允许接收“6”字符串形式的数据呢?
因为在JSON中,“6”是可以用来赋给int类型的字段。默认coerce为tru-e,表示允许这种赋值,
但如coerce设置为false,此时es只能接受不带双引号的数字,如果在coerce=false时,
将“6”赋值给number_one时会抛出类型不匹配异常。
-----------------------------------------------------------------------------------------------------
可以在创建索引时指定默认的coerce值,示例如下:
PUT my_index
{
"settings": {
"index.mapping.coerce": false
},
"mappings": {
// 省略字段映射定义
}
}
05.copy_to(合并参数):将字段的值复制到另一个字段中,通常用于聚合搜索条件。
a.介绍
这个属性,可以将多个字段的值,复制到同一个字段中。
copy_to参数允许您创建自定义的_all字段。换句话说,多个字段的值可以被复制到一个字段.
例如,将first_name和la-st_name字段复制到full_name
b.示例1
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"copy_to": "full_content"
},
"content":{
"type": "text",
"copy_to": "full_content"
},
"full_content":{
"type": "text"
}
}
}
}
PUT blog/_doc/1
{
"title":"你好江南一点雨",
"content":"当 coerce 修改为 false 之后,数字就只能是数字了,不可以是字符串,该字段传入字符串会报错。"
}
GET blog/_search
{
"query": {
"term": {
"full_content": "当"
}
}
}
c.示例2
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
表示字段full_name的值来自first_nam-e+last_name。
关于copy_to重点说明:
字段的复制是原始值,而不是分词后的词根。
复制字段不会包含在_souce字段中,但可以使用复制字段进行查询。
同一个字段可以复制到多个字段,写法如下:"copy_to": [ "field_1", "field_2" ]
06.doc_values(文档值):用于排序、聚合和脚本的预先计算的值,通常 keyword 和 numeric 类型使用它。
a.介绍
当需要对一个字段进行排序时,es需要提取匹配结果集中的排序字段值集合,然后进行排序。
倒排索引的数据结构对检索来说相当高效,但对排序就不那么擅长了。
-----------------------------------------------------------------------------------------------------
业界对排序、聚合非常高效的数据存储格式首推列式存储,在elasticsearch中,doc_values就是一种列式存储结构,
绝大多数数据类型doc_values默认为ture,即在索引时会将字段的值(或分词后的词根序列)加入到倒排索引中,
同时也会该字段的值加入doc_values中,所有该类型的索引下该字段的值用一列存储
-----------------------------------------------------------------------------------------------------
es 中的搜索主要是用到倒排索引,doc_values 参数是为了加快排序、聚合操作而生的。当建立倒排索引的时候,会额外增加列式存储映射。
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭 doc_values。
大部分的字段在索引时都会生成 doc_values,除了 text。text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成。
-----------------------------------------------------------------------------------------------------
doc_values felddata
索引时创建 使用时动态创建
磁盘 内存
不占用内存 不占用磁盘
索引速度稍微低一点 文档很多时,动态创建慢,占内存
-----------------------------------------------------------------------------------------------------
doc_values 默认开启,fielddata 默认关闭。
b.doc_values 演示:
PUT users
PUT users/_doc/1
{
"age":100
}
PUT users/_doc/2
{
"age":99
}
PUT users/_doc/3
{
"age":98
}
PUT users/_doc/4
{
"age":101
}
GET users/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"age":{
"order": "desc"
}
}
]
}
c.由于 doc_values 默认时开启的,所以可以直接使用该字段排序,如果想关闭 doc_values ,如下
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"doc_values": false
}
}
}
}
PUT users/_doc/1
{
"age":100
}
PUT users/_doc/2
{
"age":99
}
PUT users/_doc/3
{
"age":98
}
PUT users/_doc/4
{
"age":101
}
GET users/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"age":{
"order": "desc"
}
}
]
}
d.代码
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"status_code": {
"type": "keyword" // 默认情况下,“doc_values”:true
},
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
}
07.dynamic(动态设置):定义是否允许动态添加字段(true/false/strict)。
a.介绍
是否允许动态的隐式增加字段。在执行index api或更新文档API时,对于_sour-ce字段中包含一些原先未定义的字段采取的措施,根据dynamic的取值,会进行不同的操作:
true,默认值,表示新的字段会加入到类型映射中。
false,新的字段会被忽略,即不会存入_souce字段中,即不会存储新字段,也无法通过新字段进行查询。
strict,会显示抛出异常,需要新使用put mapping api先显示增加字段映射。
b.示例
可以通过put mapping api对dynamic值进行更新
PUT my_index/_doc/1
{
"username": "johnsmith",
"name": {
"first": "John",
"last": "Smith"
}
}
PUT my_index/_doc/2 // @1
{
"username": "marywhite",
"email": "mary@white.com",
"name": {
"first": "Mary",
"middle": "Alice",
"last": "White"
}
}
GET my_index/_mapping // @2
-----------------------------------------------------------------------------------------------------
代码@1在原有的映射下,增加了user-name,name.middle两个字段,
通过代码@2获取映射API可以得知,es已经为原本不存在的字段自动添加了类型映射定义。
c.示例
dynamic只对当前层级具有约束力
PUT my_index
{
"mappings": {
"_doc": {
"dynamic": false, // @1
"properties": {
"user": { // @2
"properties": {
"name": {
"type": "text"
},
"social_networks": { // @3
"dynamic": true,
"properties": {}
}
}
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
代码@1:_doc类型的顶层不能不支持动态隐式添加字段映射。
代码@2:但_doc的嵌套对象user对象,是支持动态隐式添加字段映射。
代码@3:同样对于嵌套对象social_n-etworks,也支持动态隐式添加字段映射。
08.enabled(开启字段):用于完全启用或禁用一个字段。如果 enabled: false,字段不会被索引。
a.介绍
enabled属性,用来对映射类型(_type)和object类型的字段来启用或禁用索引功能,
如果enabled属性设置为false,表示只存储,但不创建索引,意味者无法使用该字段的值进行查询。
-----------------------------------------------------------------------------------------------------
es 默认会索引所有的字段,但是有的字段可能只需要存储,不需要索引。此时可以通过 enabled 字段来控制
b.示例
PUT blog
{
"mappings": {
"properties": {
"title":{
"enabled": false
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
GET blog/_search
{
"query": {
"term": {
"title": "javaboy"
}
}
}
-----------------------------------------------------------------------------------------------------
设置了 enabled 为 false 之后,就可以再通过该字段进行搜索了。
c.示例
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"user_id": {
"type": "keyword"
},
"last_updated": {
"type": "date"
},
"session_data": {
"enabled": false
}
}
}
}
}
PUT my_index/_doc/session_1
{
"user_id": "kimchy",
"session_data": {
"arbitrary_object": {
"some_array": [ "foo", "bar", { "baz": 2 } ]
}
},
"last_updated": "2015-12-06T18:20:22"
}
-----------------------------------------------------------------------------------------------------
上述示例,es会存储session_data对象的数据,但无法通过查询API根据sessi-on_data中的属性进行查询。
同样,可以通过put mapping api更新enabled属性。
09.fielddata(字段数据):用于在 text 类型字段上启用排序和聚合。
a.介绍
为了解决排序与聚合,elasticsearch提供了doc_values属性来支持列式存储,但doc_values不支持text字段类型。因为text字段是需要先分析(分词),会影响doc_values列式存储的性能。
Elasticsearch为了支持文本字段高效排序与聚合,引入了一种新的数据结构(fielddata),使用内存进行存储。
默认是在第一次聚合查询、排序操作时构建,主要存储倒排索引中的词根与文档的映射关系,聚合、排序操作在内存中执行。因此fielddata需要消耗大量的JVM堆内存。一旦fielddata加载到内存后,它将永久存在。
通常情况下,加载fielddata是一个昂贵的操作,故默认情况下,文本类型的字段默认是不开启fielddata机制。在使用fielddata之前请慎重考虑其必要性。
通常text字段用来进行全文搜索,对于聚合、排序字段,建议使用doc_values机制。
为了节省内存的使用,es提供了另一项机制(fielddata_frequency_filter),允许只加载那些词根频率在指定范围(最大,小值)直接的词根与文档的映射关系,最大最小值可以指定为绝对值,例如数字,也可以基于百分比(百分比的计算是基于整个分段(segment),其频率分母不是分段(segment)中所有的文档,而是segment中该字段有值的文档)。
可以通过min_segment_size参数来指定分段中必须包含的最小文档数量来排除小段,也就是说可以控制fielddata_freq-uency_filter的作用范围是包含大于min_-segment_size的文档数量的段。
b.示例
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"tag": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
}
}
}
}
}
}
10.format(日期格式):为 date 类型字段指定日期格式(如 yyyy-MM-dd)。
a.介绍
在JSON文档中,日期表示为字符串。Elasticsearch使用一组预先配置的格式来识别和解析这些字符串,
并将其解析为long类型的数值(毫秒)。
-----------------------------------------------------------------------------------------------------
日期格式主要包括如下3种方式:
自定义格式
date mesh(已在DSL查询API中详解)
内置格式
b.自定义格式
首先可以使用java定义时间的格式,例如:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}
c.date mesh
某些API支持,已在DSL查询API中详细介绍过,这里不再重复。
d.内置格式
epoch_millis
时间戳,单位,毫秒。
-----------------------------------------------------------------------------------------------------
epoch_second
时间戳,单位,秒。
-----------------------------------------------------------------------------------------------------
date_optional_time
日期必填,时间可选,其支持的格式如下:
-----------------------------------------------------------------------------------------------------
basic_date
yyyyMMdd
-----------------------------------------------------------------------------------------------------
basic_date_time
yyyyMMdd'T'HHmmss.SSSZ
-----------------------------------------------------------------------------------------------------
basic_date_time_no_millis
yyyyMMdd'T'HHmmssZ
-----------------------------------------------------------------------------------------------------
basic_ordinal_date
4位数的年 + 3位(day of year),其格式字符串为yyyyDDD
-----------------------------------------------------------------------------------------------------
basic_ordinal_date_time
yyyyDDD'T'HHmmss.SSSZ
-----------------------------------------------------------------------------------------------------
basic_ordinal_date_time_no_millis
yyyyDDD'T'HHmmssZ
-----------------------------------------------------------------------------------------------------
basic_time
HHmmss.SSSZ
-----------------------------------------------------------------------------------------------------
basic_time_no_millis
HHmmssZ
-----------------------------------------------------------------------------------------------------
basic_t_time
'T'HHmmss.SSSZ
-----------------------------------------------------------------------------------------------------
basic_t_time_no_millis
'T'HHmmssZ
-----------------------------------------------------------------------------------------------------
basic_week_date
xxxx'W'wwe,4为年 ,然后用'W', 2位week of year(所在年里周序号)1位 day of week。
-----------------------------------------------------------------------------------------------------
basic_week_date_time
xxxx'W'wwe'T'HH:mm:ss.SSSZ.
-----------------------------------------------------------------------------------------------------
basic_week_date_time_no_millis
xxxx'W'wwe'T'HH:mm:ssZ.
-----------------------------------------------------------------------------------------------------
date
yyyy-MM-dd
-----------------------------------------------------------------------------------------------------
date_hour
yyyy-MM-dd'T'HH
-----------------------------------------------------------------------------------------------------
date_hour_minute
yyyy-MM-dd'T'HH:mm
-----------------------------------------------------------------------------------------------------
date_hour_minute_second
yyyy-MM-dd'T'HH:mm:ss
-----------------------------------------------------------------------------------------------------
date_hour_minute_second_fraction
yyyy-MM-dd'T'HH:mm:ss.SSS
-----------------------------------------------------------------------------------------------------
date_hour_minute_second_millis
yyyy-MM-dd'T'HH:mm:ss.SSS
-----------------------------------------------------------------------------------------------------
date_time
yyyy-MM-dd'T'HH:mm:ss.SSS
-----------------------------------------------------------------------------------------------------
date_time_no_millis
yyyy-MM-dd'T'HH:mm:ss
-----------------------------------------------------------------------------------------------------
hour
HH
-----------------------------------------------------------------------------------------------------
hour_minute
HH:mm
-----------------------------------------------------------------------------------------------------
hour_minute_second
HH:mm:ss
-----------------------------------------------------------------------------------------------------
hour_minute_second_fraction
HH:mm:ss.SSS
-----------------------------------------------------------------------------------------------------
hour_minute_second_millis
HH:mm:ss.SSS
-----------------------------------------------------------------------------------------------------
ordinal_date
yyyy-DDD,其中DDD为 day of year。
-----------------------------------------------------------------------------------------------------
ordinal_date_time
yyyy-DDD‘T’HH:mm:ss.SSSZZ,其中DDD为 day of year。
-----------------------------------------------------------------------------------------------------
ordinal_date_time_no_millis
yyyy-DDD‘T’HH:mm:ssZZ
-----------------------------------------------------------------------------------------------------
time
HH:mm:ss.SSSZZ
-----------------------------------------------------------------------------------------------------
time_no_millis
HH:mm:ssZZ
-----------------------------------------------------------------------------------------------------
t_time
'T'HH:mm:ss.SSSZZ
-----------------------------------------------------------------------------------------------------
t_time_no_millis
'T'HH:mm:ssZZ
-----------------------------------------------------------------------------------------------------
week_date
xxxx-'W'ww-e,4位年份,ww表示week of year,e表示day of week。
-----------------------------------------------------------------------------------------------------
week_date_time
xxxx-'W'ww-e'T'HH:mm:ss.SSSZZ
-----------------------------------------------------------------------------------------------------
week_date_time_no_millis
xxxx-'W'ww-e'T'HH:mm:ssZZ
-----------------------------------------------------------------------------------------------------
weekyear
xxxx
-----------------------------------------------------------------------------------------------------
weekyear_week
xxxx-'W'ww,其中ww为week of year。
-----------------------------------------------------------------------------------------------------
weekyear_week_day
xxxx-'W'ww-e,其中ww为week of year,e为day of week。
-----------------------------------------------------------------------------------------------------
year
yyyy
-----------------------------------------------------------------------------------------------------
year_month
yyyy-MM
-----------------------------------------------------------------------------------------------------
year_month_day
yyyy-MM-dd,温馨提示,日期格式时,es建议在上述格式之前加上strict_前缀。
11.ignore_above(忽略超越限制的字段):忽略超过指定长度的字符串,常用于 keyword 类型字段。
a.介绍
超过ignore_above设置的字符串不会被索引或存储。对于字符串数组,将分别对每个数组元素应用ignore_above,
超过ignore_above的字符串元素将不会被索引或存储。
目前测试的结果为:对于字符串字符长度超过ignore_above会存储,但不索引(也就是无法根据该值去查询)。
-----------------------------------------------------------------------------------------------------
igbore_above 用于指定分词和索引的字符串最大长度,超过最大长度的话,该字段将不会被索引,这个字段只适用于 keyword 类型。
b.代码
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "keyword",
"ignore_above": 10
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
PUT blog/_doc/2
{
"title":"javaboyjavaboyjavaboy"
}
GET blog/_search
{
"query": {
"term": {
"title": "javaboyjavaboyjavaboy"
}
}
}
c.代码
public static void create_mapping_ignore_above() { // 创建映射
RestHighLevelClient client = EsClient.getClient();
try {
CreateIndexRequest request = new CreateIndexRequest("mapping_test_ignore_above2");
XContentBuilder mapping = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("lies")
.field("type", "keyword") // 创建关键字段
.field("ignore_above", 10) // 设置长度不能超过10
.endObject()
.endObject()
.endObject();
// request.mapping("user", mapping_user);
request.mapping("_doc", mapping);
System.out.println(client.indices().create(request, RequestOptions.DEFAULT));
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
public static void index_mapping_ignore_above() { // 索引数据
RestHighLevelClient client = EsClient.getClient();
try {
IndexRequest request = new IndexRequest("mapping_test_ignore_above2", "_doc");
Map<String, Object> data = new HashMap<>();
data.put("lies", new String[] {"dingabcdwei","huangsw","wuyanfengamdule"});
request.source(data);
System.out.println(client.index(request, RequestOptions.DEFAULT));
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
public static void search_ignore_above() { // 查询数据
RestHighLevelClient client = EsClient.getClient();
try {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("mapping_test_ignore_above2");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(
// QueryBuilders.matchAllQuery() // @1
// QueryBuilders.termQuery("lies", "dingabcdwei") // @2
// QueryBuilders.termQuery("lies", "huangsw") // @3
);
searchRequest.source(sourceBuilder);
SearchResponse result = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
-----------------------------------------------------------------------------------------------------
代码@1:首先查询所有数据,其_sou-ce字段的值为:"_source":{"lies":["dingabcdwei","huangsw","wuyanfengamdule"]},表名不管字符串的值是否大于ignore_above指定的值,都会存储。
代码@2:用超过ignore_above长度的值尝试去搜索,发现无法匹配到记录,表明并未加入到倒排索引中。
代码@3:用未超过ignore_above长度的值尝试去搜索,发现能匹配到记录。
注意:在es中,ignore_above的长度是字符的长度,而es其底层实现lucene是使用字节进行计算的,故,如果要反馈到lucnce,请注意关系。
12.ignore_malformed(忽略格式不对的数据):忽略格式不正确的字段值,避免引发错误。
a.介绍
试图将错误的数据类型索引到字段中,默认情况下会抛出异常,并拒绝整个文档。
ignore_malformed参数,如果设置为真,允许错误被忽略。格式不正确的字段不建立索引,
但是文档中的其他字段正常处理。该参数也可以在创建索引时通过index.mapping.ignore_malformed
来配置索引级别的默认值,其优先级为字段级、索引级。
-----------------------------------------------------------------------------------------------------
ignore_malformed 可以忽略不规则的数据,该参数默认为 false。
b.代码
PUT users
{
"mappings": {
"properties": {
"birthday":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"age":{
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT users/_doc/1
{
"birthday":"2020-11-11",
"age":99
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11",
"age":"abc"
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11aaa",
"age":"abc"
}
13.include_in_all(_all 查询包含字段):已废弃,早期用于控制字段是否包含在 _all 字段中进行全文搜索。
a.介绍
这个是针对 _all 字段的,但是在 es7 中,该字段已经被废弃了。
14.index_options(索引设置):定义索引时记录哪些信息,通常是 docs、freqs 或 positions。
a.介绍
控制文档添加到反向索引的额外内容,其可选择值如下:
docs:文档编号添加到倒排索引。
freqs:文档编号与访问频率。
positions:文档编号、访问频率、词位置(顺序性),proximity 和phrase queries 需要用到该模式。
offsets:文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号),高亮显示,需要设置为该模式。
-----------------------------------------------------------------------------------------------------
默认情况下,被分析的字符串(analyz-ed string)字段使用positions,其他字段使用docs;
b.index_options 控制索引时哪些信息被存储到倒排索引中(用在 text 字段中),有四种取值:
index_options 备注
docs 只存储文档编号,默认即此
freqs 在docs基础上,存储词项频率
positions 在freqs基础上,存储词项偏移位置
offsets 在positions基础上,存储词项开始和结束的字符位置
15.index(索引):控制字段是否可被索引,如果设置为 false,该字段不能用于搜索。
a.介绍
定义字段是否索引。
true:代表索引,默认值。
false表示不索引(则无法通过该字段进行查询)。
-----------------------------------------------------------------------------------------------------
index 属性指定一个字段是否被索引,该属性为 true 表示字段被索引,false 表示字段不被索引
b.代码
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
PUT users/_doc/1
{
"age":99
}
GET users/_search
{
"query": {
"term": {
"age": 99
}
}
}
16.fields(字段):允许为同一个字段定义多种表示形式,比如文本字段可以有 text 和 keyword 两种类型。
a.介绍
fields允许对同一索引中同名的字段进行不同的设置
fields 参数可以让同一字段有多种不同的索引方式
b.代码
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"raw":{
"type":"keyword"
}
}
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
GET blog/_search
{
"query": {
"term": {
"title.raw": "javaboy"
}
}
}
c.代码
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "text", // @1
"fields": { // @2
"raw": {
"type": "keyword" // @3
}
}
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
@1:上述映射为city字段,定义类型为text,使用全文索引。
@2:为city定义多字段,city.raw,其类型用keyword。
主要就可以用user进行全文匹配,也可以用user.raw进行聚合、排序等操作。另外一种比较常用的场合是对该字段使用不同的分词器。
17.norms(标准信息):控制是否存储归一化信息(用于相关性评分),通常对 text 类型字段有用。
a.介绍
字段的评分规范,存储该规范信息,会提高查询时的评分计算效率。
虽然规范对计分很有用,但它也需要大量磁盘(通常是索引中每个字段的每个文档一个字节的顺序,甚至对于没有这个特定字段的文档也是如此)。
从这里也可以看出,norms适合为过滤或聚合的字段。
注意,可以通过put mapping api 将nor-ms=true更新为norms=false,但无法从false更新到true。
b.介绍
norms 对字段评分有用,text 默认开启 norms,如果不是特别需要,不要开启 norms。
18.null_value(空值):为 null 值指定一个默认值,防止 null 值引起查询问题。
a.介绍
在 es 中,值为 null 的字段不索引也不可以被搜索,null_value 可以让值为 null 的字段显式的可索引、可搜索
-----------------------------------------------------------------------------------------------------
将显示的null值替换为新定义的额值。
b.代码
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"status_code": {
"type": "keyword",
"null_value": "NULL" // @1
}
}
}
}
}
PUT my_index/_doc/1
{
"status_code": null // @2
}
PUT my_index/_doc/2
{
"status_code": [] // @3
}
GET my_index/_search
{
"query": {
"term": {
"status_code": "NULL" // @4
}
}
}
-----------------------------------------------------------------------------------------------------
代码@1:为status_code字段定义"NU-LL"为空值null;
代码@2:该处,存储在status_code为 null_value中定义的值,即"NULL"
代码@3:空数组不包含显式null,因此不会被null_value替换。
代码@4:该处查询,会查询出文档1。其查询结果如下:
c.代码
{
"took":4,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"skipped":0,
"failed":0
},
"hits":{
"total":1,
"max_score":0.2876821,
"hits":[
{
"_index":"mapping_test_null_value",
"_type":"_doc",
"_id":"RyjGEmcB-TTORxhqI2Zn",
"_score":0.2876821,
"_source":{
"status_code":null
}
}
]
}
}
-----------------------------------------------------------------------------------------------------
null_value具有如下两个特点:
null_value需要与字段的数据类型相同。例如,一个long类型的字段不能有字符串null_value。
null_value只会索引中的值(倒排索引),无法改变_souce字段的值。
d.代码
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "keyword",
"null_value": "javaboy_null"
}
}
}
}
PUT users/_doc/1
{
"name":null,
"age":99
}
GET users/_search
{
"query": {
"term": {
"name": "javaboy_null"
}
}
}
19.position_increment_gap(短语位置间隙):定义在多个值之间的短语查询时的间隔。
a.介绍
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,
当我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,
将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 来控制,默认是 100。
-----------------------------------------------------------------------------------------------------
针对多值字段,值与值之间的间隙
b.代码
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"names": {
"type": "text",
"position_increment_gap": 0 // @1
// "position_increment_gap": 10 // @2
}
}
}
}
}
PUT my_index/_doc/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
-----------------------------------------------------------------------------------------------------
names字段是个数组,也即ES中说的多值字段。
当position_increment_gap=0时,es的默认使用标准分词器,分成的词根为:
position 0 : john
position 1 : abraham
position 2 : lincoln
position 3 : smith
当position_increment_gap = 10时,es使用默认分词器,分成的词根为:
position 0 : john
position 1 : abraham
position 11 : lincoln 这是第二个词,等于上一个词的position + pos-ition_increment_gap。
position 12 : smith
c.代码
GET my_index/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
-----------------------------------------------------------------------------------------------------
针对position_increment_gap=0时,能匹配上文档,如果position_increment_gap=10,则无法匹配到文档,因为abraham
与lincoln的位置相差10,如果要能匹配到该文档,需要在查询时设置slop=10,该参数在前面的DSL查询部分已详细介绍过。
d.代码
PUT users
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "sanli"
}
}
}
}
-----------------------------------------------------------------------------------------------------
sanli 搜索不到,因为两个短语之间有一个假想的空隙,为 100。
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li",
"slop": 101
}
}
}
}
-----------------------------------------------------------------------------------------------------
可以通过 slop 指定空隙大小。
也可以在定义索引的时候,指定空隙:
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "text",
"position_increment_gap": 0
}
}
}
}
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}
20.properties(属性):用于定义复杂对象(如 object 或 nested 类型)的子字段。
a.介绍
为映射类型创建字段定义。
21.search_analyzer
a.介绍
通常,在索引时和搜索时应用相同的分析器,以确保查询中的术语与反向索引中的术语具有相同的格式,
如果想要在搜索时使用与存储时不同的分词器,则使用search_analyzer属性指定,
通常用于ES实现即时搜索(edge_ngram)。
b.代码
假设你有一个文本字段,你希望在索引时使用精细的 ik_max_word 分词器,而在搜索时使用较简单的 ik_smart 分词器,可以这样配置
PUT /my_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
在索引文档时,Elasticsearch 会使用 analyzer 定义的分词器将字段内容进行分词和存储。
在用户进行查询时,Elasticsearch 会使用 search_analyzer 定义的分词器来处理查询词。
22.similarity(相似度模型):控制字段的相似度计算方式,常见的有 BM25 和 classic 等模型。
a.similarity 指定文档的评分模型,默认有三种:
指定相似度算法,其可选值:
BM25 当前版本的默认值,使用BM25算法。
classic 使用TF/IDF算法,曾经是es,lucene的默认相似度算法。
boolean 一个简单的布尔相似度,当不需要全文排序时使用,并且分数应该只基于查询条件是否匹配。布尔相似度为术语提供了一个与它们的查询boost相等的分数。
23.store(存储):控制字段是否以源文档之外的方式单独存储,通常是 false。
a.介绍
默认情况下,字段会被索引,也可以搜索,但是不会存储,虽然不会被存储的,
但是 _source 中有一个字段的备份。如果想将字段存储下来,可以通过配置 store 来实现。
b.介绍
默认情况下,字段值被索引以使其可搜索,但它们不存储。这意味着可以查询字段,但无法检索原始字段值。通常这并不重要。字段值已经是_source字段的一部分,该字段默认存储。
如果您只想检索单个字段或几个字段的值,而不是整个_source,那么这可以通过字段过滤上下文(source filting context来实现,在某些情况下,存储字段是有意义的。
例如,如果您有一个包含标题、日期和非常大的内容字段的文档,您可能只想检索标题和日期,而不需要从大型_sou-rce字段中提取这些字段,es还提供了另外一种提取部分字段的方法stored_field-s。
stored_fields只支持字段的store定义为ture,该部分内容已经在Elasticsearch Doc api时,_souce过滤部分详细介绍过,这里不过多介绍。
24.term_vectors(词根信息):定义是否存储字段的词条向量及其位置信息、偏移信息等,通常用于高级搜索和分析。
a.term_vector包含分析过程产生的术语的信息,包括:
术语列表。
每一项的位置(或顺序)。
开始和结束字符偏移量。
b.term_vector可取值
no
不存储term_vector信息,默认值。
yes
只存储字段中的值。
with_positions
存储字段中的值与位置信息。
with_offsets
存储字段中的值、偏移量
with_positions_offsets
存储字段中的值、位置、偏移量信息。
2.4 文档:行,一条数据
01.INSERT
a.示例
{
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
_index 文档索引1
_type 文档的类型
_id 文档的id
_version 文档的版本(更新文档,版本会自动加1)
result 执行结果
shards 分片信息
seq_no和_primary_term 版本控制
b.说明
格式:PUT /索引名/类型名/文档id
以前的写法是:{index}/{type}/{id},例如:user/_doc/1
现在的写法是:{index}/_doc/{id},例如:user/_doc/1
由于在ES7中将type概念移除了,所以现在建议直接写成_doc,当然你硬要指定type类型也行,只是ES是给出一个警告:#! [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
c.操作
POST /heima/_doc/1
{
"info": "真相只有一个!",
"email": "zy@itcast.cn",
"name": {
"firstName":"柯",
"lastName":"南"
}
}
-----------------------------------------------------------------------------------------------------
POST /heima/_doc/2
{
"info": "真相!",
"email": "zy@itc.cn",
"name": {
"firstName":"关",
"lastName":"羽"
}
}
-----------------------------------------------------------------------------------------------------
POST /heima/_doc/3
{
"info": "真相!",
"email": "zy@itc.cn",
"name": {
"firstName":"刘",
"lastName":"备"
}
}
02.QUERY
a.单个查询
GET /{索引库名称}/_doc/{id}
GET /{索引库名称}/_search
-----------------------------------------------------------------------------------------------------
HEAD /heima/_doc/1 --是否存在
-----------------------------------------------------------------------------------------------------
GET /heima/_search --所有文档信息
GET /heima/_search?q=name:张三 --根据关键字查询文档信息
-----------------------------------------------------------------------------------------------------
GET /heima --查看全部
GET /heima/_doc/1 --查询一个
b.批量查询
GET /heima/_mget --查询批量
{
"ids" : ["1", "2"]
}
03.UPDATE
a.普通更新
a.全量修改:直接覆盖原来的文档
a.说明
全量修改是覆盖原来的文档,其本质是:根据指定的id删除文档、新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
b.示例
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
b.增量修改:修改文档中的部分字段
a.说明
增量修改是只修改指定id匹配的文档中的部分字段
b.示例
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn",
"tmp": "1111"
}
}
c.painless脚本
a.说明
在脚本中,lang表示脚本语言,painless是es内置的一种脚本语言。
source表示具体执行的脚本,ctx是一个上下文对象,通过ctx可以访问到_source、_title等。
b.示例
a.简单字段更新
ctx._source 代表文档的 _source 字段。
通过 ctx._source.age += params.increment,Painless脚本将 age 字段的值增加了 1
-----------------------------------------------------------------------------------------
POST /heima/_update/1
{
"script": {
"source": "ctx._source.age += params.increment",
"lang": "painless",
"params": {
"increment": 1
}
}
}
b.根据条件更新字段
脚本根据用户的 age 字段值判断是否更新 status 字段为 'senior' 或 'junior'。
-----------------------------------------------------------------------------------------
POST /heima/_update/1
{
"script": {
"source": """
if (ctx._source.age > 30) {
ctx._source.status = 'senior';
} else {
ctx._source.status = 'junior';
}
""",
"lang": "painless"
}
}
b.查询更新
a.原数据
GET /heima/_doc/1
-------------------------------------------------------------------------------------------------
{
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "黑马程序员高级Java讲师",
"email" : "ZhaoYun@itcast.cn",
"name" : {
"firstName" : "云",
"lastName" : "赵"
},
"tmp" : "1111"
}
}
b.查询更新,更新名为 "赵云" 的文档,将其 email 字段修改为 ZhaoYunUpdated@itcast.cn,并删除 tmp 字段
POST /heima/_update_by_query
{
"script": {
"source": """
ctx._source.email = 'ZhaoYunUpdated@itcast.cn';
ctx._source.remove('tmp');
""",
"lang": "painless"
},
"query": {
"bool": {
"must": [
{ "match": { "name.lastName": "赵" } },
{ "match": { "name.firstName": "云" } }
]
}
}
}
04.DELETE
a.普通删除
DELETE /{索引库名}/_doc/{id}
-----------------------------------------------------------------------------------------------------
DELETE /heima --删除索引
DELETE /heima/_doc/1 --根据id删除数据
b.查询删除
a.示例1:从 heima_v2 索引中删除所有 info 字段包含 "Java" 关键词的文档
POST /heima_v2/_delete_by_query
{
"query": {
"match": {
"info": "Java"
}
}
}
-------------------------------------------------------------------------------------------------
索引:请求的路径是 /heima_v2/_delete_by_query,表示在 heima_v2 索引中执行删除操作。
查询条件:使用 match 查询,查找 info 字段中包含 "Java" 的文档。如果某个文档的 info 字段中包含 "Java",那么该文档将被删除。
b.示例2:删除姓 "赵" 且 info 字段中包含 "高级" 的文档,可以结合 bool 查询来完成
POST /heima_v2/_delete_by_query
{
"query": {
"bool": {
"must": [
{ "match": { "name.lastName": "赵" } },
{ "match": { "info": "高级" } }
]
}
}
}
-------------------------------------------------------------------------------------------------
bool 查询:bool 查询允许组合多个查询条件。
must:表示文档必须同时满足多个条件。
match:查询 name.lastName 为 "赵" 且 info 包含 "高级" 的文档。
-------------------------------------------------------------------------------------------------
查询数据:GET /heima/_search
05.通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作
a.方式1
POST /heima_v2/_bulk
{ "index": { "_id": "1" } }
{ "name": { "firstName": "云", "lastName": "赵" }, "email": "ZhaoYun@itcast.cn", "info": "黑马程序员高级Java讲师" }
{ "index": { "_id": "2" } }
{ "name": { "firstName": "华", "lastName": "刘" }, "email": "LiuHua@itcast.cn", "info": "黑马程序员Java基础讲师" }
{ "delete": { "_id": "3" } }
{ "update": { "_id": "4" } }
{ "doc": { "info": "黑马程序员大数据与AI讲师" } }
-----------------------------------------------------------------------------------------------------
a.批量索引文档
index 操作插入或更新一个文档(如果ID已存在,则覆盖该文档)。
例子中,ID为 1 和 2 的文档会被索引或更新。
b.批量删除文档
delete 操作根据指定的文档ID删除文档。
例子中,ID为 3 的文档将被删除。
c.批量更新文档
update 操作更新文档中的部分字段。
例子中,ID为 4 的文档将更新 info 字段为 "黑马程序员大数据与AI讲师"。
b.方式2
{ "index" : { "_index" : "heima_v2", "_id" : "1" } }
{ "name" : { "firstName" : "云", "lastName" : "赵" }, "email" : "ZhaoYun@itcast.cn", "info" : "黑马程序员高级Java讲师" }
{ "index" : { "_index" : "heima_v2", "_id" : "2" } }
{ "name" : { "firstName" : "莉", "lastName" : "张" }, "email" : "LiZhang@itcast.cn", "info" : "高级前端讲师" }
{ "index" : { "_index" : "heima_v2", "_id" : "3" } }
{ "name" : { "firstName" : "杰", "lastName" : "王" }, "email" : "JieWang@itcast.cn", "info" : "Python 数据分析师" }
-----------------------------------------------------------------------------------------------------
curl -X POST "http://localhost:9200/heima_v2/_bulk" -H "Content-Type: application/json" --data-binary "@bulk_data.json"
c.批量读取
读多个索引
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_id" : "1"
},
{
"_index" : "test",
"_id" : "2"
}
]
}
-----------------------------------------------------------------------------------------------------
读一个索引
GET /test/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
]
}
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_id" : "1",
"_source" : false
},
{
"_index" : "test",
"_id" : "2",
"_source" : ["field3", "field4"]
},
{
"_index" : "test",
"_id" : "3",
"_source" : {
"include": ["user"],
"exclude": ["user.location"]
}
}
]
}
d.批量查询
POST kibana_sample_data_ecommerce/_msearch
{}
{"query" : {"match_all" : {}},"size":1}
{"index" : "kibana_sample_data_flights"}
{"query" : {"match_all" : {}},"size":2}
-------------------------------------------------------------------------------------------------------------
01.文档路由
a.新增一个文档
POST /heima/_doc/5
{
"info": "蜡笔!",
"email": "zy@itc.cn",
"name": {
"firstName":"蜡",
"lastName":"笔"
}
}
b.查看该文档被保存到哪个分片
GET _cat/shards/heima?v
-----------------------------------------------------------------------------------------------------
index shard prirep state docs store ip node
heima 0 p STARTED 3 10.7kb 127.0.0.1 DESKTOP-NTRUK8V
heima 0 r UNASSIGNED
从这个结果中,可以看出,文档被保存到分片 0 中
c.那么 es 中到底是按照什么样的规则去分配分片的?
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
-----------------------------------------------------------------------------------------------------
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,
然后将该数字和分片数取余,取余的结果就是分片的位置。
-----------------------------------------------------------------------------------------------------
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。
但是他有一个很大的劣势,就是查询时候无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。
另一方面,使用默认的路由模式,后期修改分片数量不方便。
02.文档路由-指定routing
a.新增一个文档
POST /heima/_doc/6?routing=javaboy
{
"info": "蜡笔!",
"email": "zy@itc.cn",
"name": {
"firstName":"蜡",
"lastName":"笔"
}
}
b.查询、删除、更新时也需要指定 routing
GET /heima/_doc/6?routing=javaboy
c.说明
自定义 routing 有可能会导致负载不均衡,这个还是要结合实际情况选择。
d.场景
对于用户数据,我们可以将 userid 作为 routing,
这样就能保证同一个用户的数据保存在同一个分片中,检索时,
同样使用 userid 作为 routing,这样就可以精准的从某一个分片中获取数据。
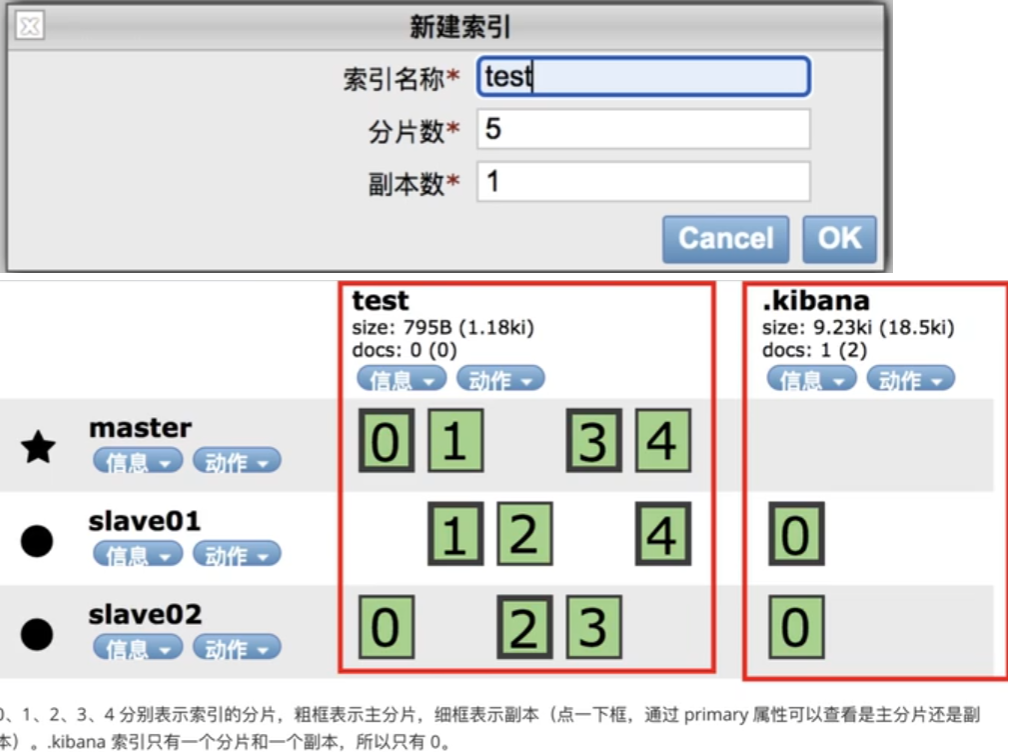
2.5 字段:列,字段的值
01.核心类型
a.字符串类型
a.string
这是一个已经过期的字符串类型。在 es5 之前,用这个来描述字符串,现在的话,它已经被 text 和 keyword 替代了。
从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代
b.text
如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述,那么可以使用 text。
用了 text 之后,字段内容会被分析,在生成倒排索引之前,字符串会被分词器分成一个个词项。
text 类型的字段不用于排序,很少用于聚合。这种字符串也被称为 analyzed 字段。
-------------------------------------------------------------------------------------------------
text 类型适用于需要被全文检索的字段,因为它会分词,例如新闻正文、邮件内容等比较长的文字,
text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,
text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
-------------------------------------------------------------------------------------------------
关于text类型的常用参数:
analyzer:指明该字段用于索引时和搜索时的分析字符串的分词器(使用search_analyzer可覆盖它)。 默认为索引分析器或标准分词器
fielddata:指明该字段是否可以使用内存中的fielddata进行排序,聚合或脚本编写?默认值为false,可取值true或false。(排序,分组需要指定为true)
fields:【多数类型】text类型字段会被分词搜索,不能用于排序,而当字段既要能通过分词搜索,又要能够排序,就要设置fields为keyword类型进行聚合排序。
index:【是否被索引】设置该字段是否可以用于搜索。默认为true,表示可以用于搜索。
search_analyzer:设置在搜索时,用于分析该字段的分析器,默认是【analyzer】参数的值。
search_quote_analyzer:设置在遇到短语搜索时,用于分析该字段的分析器,默认是【search_analyzer】参数的值。
index_options:【索引选项】用于控制在索引过程中哪些信息会被写入到倒排索引中
- docs:只索引文档号到倒排索引中,但是并不会存储
- freqs:文档号和关键词的出现频率会被索引,词频用于给文档进行评分,重复词的评分会高于单个次评分
- positions:文档号、词频和关键词 term 的相对位置会被索引,相对位置可用于编辑距离计算和短语查询(不分词那种)
- offsets:文档号、词频、关键词 term 的相对位置和该词的起始字符串偏移量
c.keyword
这种类型适用于结构化的字段,例如标签、email 地址、手机号码等等,这种类型的字段可以用作过滤、排序、聚合等。
这种字符串也称之为 not-analyzed 字段。
-------------------------------------------------------------------------------------------------
keyword 只能通过精确值搜索到,适合简短、结构化字符串,例如主机名、姓名、商品名称等,
可以用于过滤、排序、聚合检索,也可以用于精确查询。
-------------------------------------------------------------------------------------------------
关于keyword类型的常用参数:
eager_global_ordinals:指明该字段是否加载全局序数?默认为false,不加载。 对于经常用于术语聚合的字段,启用此功能是个好主意。
fields:指明能以不同的方式索引该字段相同的字符串值,例如用于搜索的一个字段和用于排序和聚合的多字段
ignore_above:不要索引长于此值的任何字符串。默认为2147483647,以便接受所有值
index:指明该字段是否可以被搜索,默认为true,表示可以被搜索
index_options:指定该字段应将哪些信息存储在索引中,以便用于评分。默认为docs,但也可以设置为freqs,这样可以在计算分数时考虑术语频率
norms:在进行查询评分时,是否需要考虑字段长度,默认为false,不考虑
ignore_above:默认值是256,该参数的意思是,当字段文本的长度大于指定值时,不会被索引,但是会存储。即当字段文本的长度大于指定值时,聚合、全文搜索都查不到这条数据。ignore_above 最大值是 32766 ,但是要根据场景来设置,比如说中文最大值 应该是设定在10922 。
b.数字类型
a.介绍
long
integer
short
byte
double
float
half_float
scaled_float
-------------------------------------------------------------------------------------------------
long带符号的64位整数,最小值-263,最大值263-1
integer带符号的32位整数,最小值-231,最大值231^-1
short带符号的16位整数,最小值-32768,最大值32767
byte带符号的8位整数,最小值-128,最小值127
double双精度64位IEEE 754 浮点数
float单精度32位IEEE 754 浮点数
half_float半精度16位IEEE 754 浮点数
scaled_float带有缩放因子的缩放类型浮点数,依靠一个long数字类型通过一个固定的(double类型)缩放因数进行缩放
b.说明
在满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
浮点数,优先考虑使用 scaled_float。
c.scaled_float举例
PUT product
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"price":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
c.日期类型
a.介绍
由于 JSON 中没有日期类型,所以 es 中的日期类型形式就比较多样:
2020-11-11 或者 2020-11-11 11:11:11
一个从 1970.1.1 零点到现在的一个秒数或者毫秒数。
es 内部将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 的长整型来存储。
b.自定义日期类型
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
}
}
}
}
-------------------------------------------------------------------------------------------------
这个能够解析出来的时间格式比较多。
PUT product/_doc/1
{
"date":"2020-11-11"
}
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z"
}
PUT product/_doc/3
{
"date":"1604672099958"
}
-------------------------------------------------------------------------------------------------
上面三个文档中的日期都可以被解析,内部存储的是毫秒计时的长整型数。
d.布尔类型(boolean)
JSON 中的 “true”、“false”、true、false 都可以。
e.二进制类型(binary)
二进制接受的是 base64 编码的字符串,默认不存储,也不可搜索。
f.范围类型
a.介绍
integer_range
float_range
long_range
double_range
date_range
ip_range
-------------------------------------------------------------------------------------------------
integer_range,带符号的32位整数区间,最小值-231,最大值231-1
long_range,带符号的64位整数区间,最小值-263,最小值263-1
float_range,单精度32位IEEE 754浮点数区间
double_range,双精度64位IEEE 754浮点数区间
date_range,日期值范围,表示为系统纪元以来经过的无符号64位整数毫秒
ip_range,支持IPv4或IPv6(或混合)地址ip值范围
b.定义的时候,指定范围类型即可
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
},
"price":{
"type":"float_range"
}
}
}
}
c.插入文档的时候,需要指定范围的界限
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
},
"price":{
"type":"float_range"
}
}
}
}
d.gt、gte、lt、lte
指定范围的时,可以使用 gt、gte、lt、lte
02.复合类型
a.数组类型
es 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值。
需要注意的是,数组中的元素必须是同一种类型。
添加数组是,数组中的第一个元素决定了整个数组的类型。
b.对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。
-----------------------------------------------------------------------------------------------------
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z",
"ext_info":{
"address":"China"
}
}
c.嵌套类型(nested)
nested 是 object 中的一个特例。
如果使用 object 类型,假如有如下一个文档:
{
"user":[
{
"first":"Zhang",
"last":"san"
},
{
"first":"Li",
"last":"si"
}
]
}
-----------------------------------------------------------------------------------------------------
由于 Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。
即上面的文档,最终存储形式如下:
{
"user.first":["Zhang","Li"],
"user.last":["san","si"]
}
扁平化之后,用户名之间的关系没了。这样会导致如果搜索 Zhang si 这个人,会搜索到。
-----------------------------------------------------------------------------------------------------
此时可以 nested 类型来解决问题,nested 对象类型可以保持数组中每个对象的独立性。
nested 类型将数组中的每一饿对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。
{
{
"user.first":"Zhang",
"user.last":"san"
},{
"user.first":"Li",
"user.last":"si"
}
}
-----------------------------------------------------------------------------------------------------
优点,文档存储在一起,读取性能高。
缺点,更新父或者子文档时需要更新更个文档。
03.地理类型
a.使用场景
查找某一个范围内的地理位置
通过地理位置或者相对中心点的距离来聚合文档
把距离整个到文档的评分中
通过距离对文档进行排序
b.geo_point
PUT people
{
"mappings": {
"properties": {
"location":{
"type": "geo_point"
}
}
}
}
-----------------------------------------------------------------------------------------------------
创建时指定字段类型,存储的时候,有四种方式:
PUT people/_doc/1
{
"location":{
"lat": 34.27,
"lon": 108.94
}
}
PUT people/_doc/2
{
"location":"34.27,108.94"
}
PUT people/_doc/3
{
"location":"uzbrgzfxuzup"
}
PUT people/_doc/4
{
"location":[108.94,34.27]
}
-----------------------------------------------------------------------------------------------------
注意,使用数组描述,先经度后纬度。
地址位置转 geo_hash:http://www.csxgame.top/#/
c.geo_shape
GeoJSON ElasticSearch 备注
Point point 一个由经纬度描述的点
LineString linestring 一个任意的线条,由两个以上的点组成
Polygon polygon 一个封闭多边形
MultiPoint multipoint 一组不连续的点
MultiLineString multilinestring 多条不关联的线
MultiPolygon multipolygon 多个多边形
GeometryCollection geometrycollection 几何对象的集合
circle 一个圆形
envelope 通过左上角和右下角两个点确定的矩形
-----------------------------------------------------------------------------------------------------
指定 geo_shape 类型:
PUT people
{
"mappings": {
"properties": {
"location":{
"type": "geo_shape"
}
}
}
}
-----------------------------------------------------------------------------------------------------
添加文档时需要指定具体的类型:
PUT people/_doc/1
{
"location":{
"type":"point",
"coordinates": [108.94,34.27]
}
}
-----------------------------------------------------------------------------------------------------
如果是 linestring,如下:
PUT people/_doc/2
{
"location":{
"type":"linestring",
"coordinates": [[108.94,34.27],[100,33]]
}
}
04.特殊类型
a.IP
存储 IP 地址,类型是 ip:
PUT blog
{
"mappings": {
"properties": {
"address":{
"type": "ip"
}
}
}
}
-----------------------------------------------------------------------------------------------------
添加文档:
PUT blog/_doc/1
{
"address":"192.168.91.1"
}
-----------------------------------------------------------------------------------------------------
搜索文档:
GET blog/_search
{
"query": {
"term": {
"address": "192.168.0.0/16"
}
}
}
b.token_count
用于统计字符串分词后的词项个数。
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"length":{
"type":"token_count",
"analyzer":"standard"
}
}
}
}
}
}
相当于新增了 title.length 字段用来统计分词后词项的个数。
-----------------------------------------------------------------------------------------------------
添加文档:
PUT blog/_doc/1
{
"title":"zhang san"
}
-----------------------------------------------------------------------------------------------------
可以通过 token_count 去查询:
GET blog/_search
{
"query": {
"term": {
"title.length": 2
}
}
}
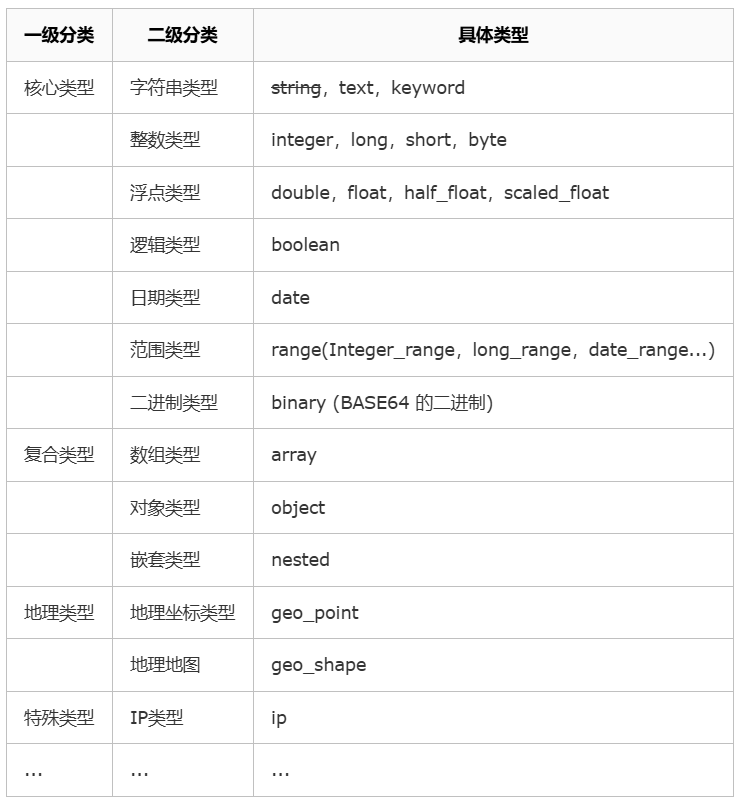
2.6 附:别名
01.查询别名
#获取指定索引的别名
GET /test2/_alias
#获取ES中所有索引的别名
GET /_alias
02.新增别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "test2",
"alias": "test2_alias_1.0"
}
}
]
}
03.删除别名
#方式一
POST /_aliases
{
"actions": [
{
"remove": {
"index": "test2",
"alias": "test2_alias_1.0"
}
}
]
}
---------------------------------------------------------------------------------------------------------
#方式二
DELETE /test2/_alias/test2_alias_1.0
04.重命名别名
POST /_aliases
{
"actions": [
{
"remove": {
"index": "test2",
"alias": "test2_alias_1.0"
}
},
{
"add": {
"index": "test2",
"alias": "test2_alias_1.0"
}
}
]
}
05.为多个索引指定一个别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "test2",
"alias": "test2_alias_2.0"
}
},{
"add": {
"index": "test1",
"alias": "test1_alias_2.0"
}
}
]
}
06.为同个索引指定多个别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "test2",
"alias": "test2_alias_2.1"
}
},{
"add": {
"index": "test2",
"alias": "test2_alias_2.2"
}
}
]
}
07.通过别名读索引
GET /test2_alias_2.1
08.通过别名写索引
POST /test2_alias_2.1.0/_doc/
{
"name": "Tom",
"age": "26"
}
2.7 附:重建索引
01.重建索引1
a.说明
在Elasticsearch中,可以通过修改映射(mapping)来指定字段使用某个特定的分词器,
比如 ik_smart 分词器。为了让 info 字段使用 ik_smart 分词,
首先需要对索引的映射进行调整,使 info 字段使用该分词器。
b.步骤
1.创建新索引并指定映射:因为Elasticsearch中现有字段的映射不能直接修改,你需要先创建一个新索引,并在映射中为 info 字段指定 ik_smart 分词器。
2.重新索引数据:使用 reindex API 将数据从旧索引迁移到新索引。
c.操作1:创建新索引并设置 info 字段的分词器
这里,info 字段被配置为 text 类型,并使用 ik_smart 分词器进行分词处理。
PUT /heima_v2
{
"mappings": {
"properties": {
"name": {
"properties": {
"firstName": { "type": "text" },
"lastName": { "type": "text" }
}
},
"email": { "type": "keyword" },
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
d.操作2:使用 reindex 将数据迁移到新索引
这会将原 heima 索引中的所有数据复制到新的 heima_v2 索引中,info 字段将按照新的映射使用 ik_smart 分词器。
POST /_reindex
{
"source": {
"index": "heima"
},
"dest": {
"index": "heima_v2"
}
}
e.操作3:删除旧索引(可选)
如果你确认数据迁移成功,并且不再需要旧的 heima 索引,你可以选择删除它:
DELETE /heima
f.操作4:重命名新索引为原来的名字(可选)
如果你需要保持索引名一致,可以将新索引重命名为 heima:
POST /heima_v2/_alias/heima
g.操作5:测试 info 字段的分词效果
可以通过 analyze API 测试 ik_smart 分词效果,验证 info 字段的内容是否按照预期被分词:
POST /heima_v2/_analyze
{
"text": "黑马程序员高级Java讲师",
"analyzer": "ik_smart"
}
h.操作6:批量插入数据
POST /heima_v2/_bulk
{ "index": { "_id": "1" }}
{ "name": { "firstName": "云", "lastName": "赵" }, "email": "ZhaoYun@itcast.cn", "info": "黑马程序员高级Java讲师" }
{ "index": { "_id": "2" }}
{ "name": { "firstName": "华", "lastName": "刘" }, "email": "LiuHua@itcast.cn", "info": "黑马程序员Java基础讲师" }
{ "index": { "_id": "3" }}
{ "name": { "firstName": "平", "lastName": "王" }, "email": "WangPing@itcast.cn", "info": "黑马程序员Python讲师" }
{ "index": { "_id": "4" }}
{ "name": { "firstName": "强", "lastName": "李" }, "email": "LiQiang@itcast.cn", "info": "黑马程序员大数据讲师" }
i.操作7:查询这些数据
GET /heima_v2/_search
02.重建索引2
a.介绍
随着业务需求的变更,索引的结构可能发生改变。ElasticSearch的索引一旦创建,只允许添加字段,不允许改变字段。
因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。那么此时,就需要重建一个新的索引,
并将原有索引的数据导入到新索引中。
b.目标
原索引库 :test_index_v1
新索引库 :test_index_v2
c.操作1
# 新建test_index_v1索引,索引名称必须全部小写
PUT test_index_v1
{
"mappings": {
"properties": {
"birthday":{
"type": "date"
}
}
}
}
# 查询索引
GET test_index_v1
# 添加数据
PUT test_index_v1/_doc/1
{
"birthday":"2020-11-11"
}
# 查询数据
GET test_index_v1/_search
# 随着业务的变更,换种数据类型进行添加数据,程序会直接报错
PUT test_index_v1/_doc/1
{
"birthday":"2020年11月11号"
}
# 业务变更,需要改变birthday数据类型为text
# 1:创建新的索引 test_index_v2
# 2:将test_index_v1 数据拷贝到 test_index_v2
b.操作2
# 创建新的索引
PUT test_index_v2
{
"mappings": {
"properties": {
"birthday":{
"type": "text"
}
}
}
}
-----------------------------------------------------------------------------------------------------
# 将test_index_v1 数据拷贝到 test_index_v2
POST _reindex
{
"source": {
"index": "test_index_v1"
},
"dest": {
"index": "test_index_v2"
}
}
-----------------------------------------------------------------------------------------------------
# 查询新索引库数据
GET test_index_v2/_search
-----------------------------------------------------------------------------------------------------
# 在新的索引库里面添加数据
PUT test_index_v2/_doc/2
{
"birthday":"2020年11月13号"
}
-----------------------------------------------------------------------------------------------------
# 删除旧索引
DELETE test_index_v1
2.8 附:Painless脚本
01.介绍
在Elasticsearch的Painless脚本语言中,modifier 中可以使用各种内置函数和方法来操作数据或执行特定的任务。
除了自定义和修改查询的 modifier 外,Painless 脚本还提供了许多内置函数和方法,用于操作字符串、日期、数学运算等。
02.Painless内置函数
a.数学函数
Math.abs(value):返回绝对值。
Math.ceil(value):向上取整。
Math.floor(value):向下取整。
Math.max(a, b):返回两个数中的最大值。
Math.min(a, b):返回两个数中的最小值。
Math.pow(base, exp):计算 base 的 exp 次幂。
Math.sqrt(value):计算平方根。
Math.log(value):返回自然对数。
Math.exp(value):返回 e 的 value 次幂。
b.日期和时间函数
new Date().getTime():返回当前时间的时间戳(毫秒)。
Instant.now():返回当前 UTC 时间。
ZonedDateTime.now():返回当前时区的日期时间。
Instant.ofEpochMilli(epochMillis):根据给定的时间戳返回 Instant。
c.字符串函数
String.length():返回字符串的长度。
String.substring(start, end):截取字符串子串。
String.indexOf(substring):返回子串在字符串中的位置。
String.replace(oldChar, newChar):替换字符串中的字符。
String.split(delimiter):根据指定的分隔符拆分字符串。
String.toUpperCase():将字符串转换为大写。
String.toLowerCase():将字符串转换为小写。
d.集合和数组函数
List.size():返回集合的大小。
List.get(index):获取集合中的元素。
Map.get(key):从Map中获取值。
Map.put(key, value):向Map中添加键值对。
Array.length:返回数组的长度。
e.布尔逻辑函数
Boolean.parseBoolean(string):将字符串转换为布尔值。
Boolean.TRUE / Boolean.FALSE:返回布尔常量值。
f.条件和控制
if-else:用于条件判断。
for / while:用于循环操作。
try-catch:用于异常捕获。
g.类型转换
(int)、(double)、(String):用于类型强制转换。
Integer.parseInt(string):将字符串转换为整数。
Double.parseDouble(string):将字符串转换为浮点数。
2.9 附:URI查询
00.介绍
a.说明
Elasticsearch URI Search 遵循 QueryString 查询语义,其形式如下:
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
{
"profile": true
}
b.参数
q 指定查询语句,使用 QueryString 语义
df 默认字段,不指定时
sort 排序:from 和 size 用于分页
profile 可以查看查询时如何被执行的
c.示例
Elasticsearch 支持用 uri 搜索,可用 get 请求里面拼接相关的参数,并用 curl 相关的命令就可以进行测试。
-----------------------------------------------------------------------------------------------------
GET twitter/_search?q=user:kimchy
{
"timed_out": false,
"took": 62,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.3862944,
"hits": [
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 1.3862944,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
-----------------------------------------------------------------------------------------------------
URI 中允许的参数:
名称 描述
q 查询字符串,映射到 query_string 查询
df 在查询中未定义字段前缀时使用的默认字段
analyzer 查询字符串时指定的分词器
analyze_wildcard 是否允许通配符和前缀查询,默认设置为 false
batched_reduce_size 应在协调节点上一次减少的分片结果数。如果请求中潜在的分片数量很大,则应将此值用作保护机制,以减少每个搜索请求的内存开销
default_operator 默认使用的匹配运算符,可以是AND或者OR,默认是OR
lenient 如果设置为 true,将会忽略由于格式化引起的问题(如向数据字段提供文本),默认为 false
explain 对于每个 hit,包含了具体如何计算得分的解释
_source 请求文档内容的参数,默认 true;设置 false 的话,不返回_source 字段,可以使用**_source_include和_source_exclude**参数分别指定返回字段和不返回的字段
stored_fields 指定每个匹配返回的文档中的存储字段,多个用逗号分隔。不指定任何值将导致没有字段返回
sort 排序方式,可以是fieldName、fieldName:asc或者fieldName:desc的形式。fieldName 可以是文档中的实际字段,也可以是诸如_score 字段,其表示基于分数的排序。此外可以指定多个 sort 参数(顺序很重要)
track_scores 当排序时,若设置 true,返回每个命中文档的分数
track_total_hits 是否返回匹配条件命中的总文档数,默认为 true
timeout 设置搜索的超时时间,默认无超时时间
terminate_after 在达到查询终止条件之前,指定每个分片收集的最大文档数。如果设置,则在响应中多了一个 terminated_early 的布尔字段,以指示查询执行是否实际上已终止。默认为 no terminate_after
from 从第几条(索引以 0 开始)结果开始返回,默认为 0
size 返回命中的文档数,默认为 10
search_type 搜索的方式,可以是dfs_query_then_fetch或query_then_fetch。默认为query_then_fetch
allow_partial_search_results 是否可以返回部分结果。如设置为 false,表示如果请求产生部分结果,则设置为返回整体故障;默认为 true,表示允许请求在超时或部分失败的情况下获得部分结果
pretty 美化,GET /kibana_sample_data_ecommerce/_search?pretty=true
01.Term 和 Phrase
Beautiful Mind 等效于 Beautiful OR Mind
"Beautiful Mind" 等效于 Beautiful AND Mind
---------------------------------------------------------------------------------------------------------
# Term 查询
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
# 使用引号,Phrase 查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
02.分组与引号
title:(Beautiful AND Mind)
title="Beautiful Mind"
03.AND、OR、NOT 或者 &&、||、!
注意:AND、OR、NOT 必须大写
---------------------------------------------------------------------------------------------------------
# 布尔操作符
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
04.范围查询
[] 表示闭区间
{} 表示开区间
---------------------------------------------------------------------------------------------------------
# 范围查询 ,区间写法
GET /movies/_search?q=title:beautiful AND year:{2010 TO 2018%7D
{
"profile":"true"
}
GET /movies/_search?q=title:beautiful AND year:[* TO 2018]
{
"profile":"true"
}
05.算数符号
# 2010 年以后的记录
GET /movies/_search?q=year:>2010
{
"profile":"true"
}
# 2010 年到 2018 年的记录
GET /movies/_search?q=year:(>2010 && <=2018)
{
"profile":"true"
}
# 2010 年到 2018 年的记录
GET /movies/_search?q=year:(+>2010 +<=2018)
{
"profile":"true"
}
06.通配符查询
? 代表 1 个字符
* 代表 0 或多个字符
---------------------------------------------------------------------------------------------------------
GET /movies/_search?q=title:mi?d
{
"profile":"true"
}
GET /movies/_search?q=title:b*
{
"profile":"true"
}
07.正则表达式
title:[bt]oy
08.模糊匹配与近似查询
# 相似度在 1 个字符以内
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}
# 相似度在 2 个字符以内
GET /movies/_search?q=title:"Lord Rings"~2
{
"profile":"true"
}
2.10 附:DSL查询
00.介绍
Elasticsearch 除了 URI Search 查询方式,还支持将查询语句通过 Http Request Body 发起查询。
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
{
"profile":"true",
"query": {
"match_all": {}
}
}
01.分页
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
{
"profile": "true",
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
02.排序
最好在数字型或日期型字段上排序
因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
{
"profile": "true",
"sort": [
{
"order_date": "desc"
}
],
"from": 1,
"size": 10,
"query": {
"match_all": {}
}
}
03._source 过滤
如果 _source 没有存储,那就只返回匹配的文档的元数据
_source 支持使用通配符,如:_source["name*", "desc*"]
示例:
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
{
"profile": "true",
"_source": [
"order_date",
"category.keyword"
],
"from": 1,
"size": 10,
"query": {
"match_all": {}
}
}
04.脚本字段
GET /kibana_sample_data_ecommerce/_search?ignore_unavailable=true
{
"profile": "true",
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source":"doc['order_date'].value+' hello'"
}
}
},
"from": 1,
"size": 10,
"query": {
"match_all": {}
}
}
05.使用查询表达式 - Match
POST movies/_search
{
"query": {
"match": {
"title": "last christmas"
}
}
}
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "last christmas",
"operator": "and"
}
}
}
}
06.短语搜索 - Match Phrase
POST movies/_search
{
"query": {
"match_phrase": {
"title":{
"query": "last christmas"
}
}
}
}
2.11 附:性能优化
01.硬件配置优化
升级硬件设备配置一直都是提高服务能力最快速有效的手段,
在系统层面能够影响应用性能的一般包括三个因素:CPU、内存和 IO,可以从这三方面进行 ES 的性能优化工作。
a.CPU 配置
一般说来,CPU 繁忙的原因有以下几个:
线程中有无限空循环、无阻塞、正则匹配或者单纯的计算;
发生了频繁的 GC;
多线程的上下文切换;
-----------------------------------------------------------------------------------------------------
大多数 Elasticsearch 部署往往对 CPU 要求不高。因此,相对其它资源,
具体配置多少个(CPU)不是那么关键。你应该选择具有多个内核的现代处理器,
常见的集群使用 2 到 8 个核的机器。如果你要在更快的 CPUs 和更多的核数之间选择,
选择更多的核数更好。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
b.内存配置
a.介绍
如果有一种资源是最先被耗尽的,它可能是内存。排序和聚合都很耗内存,
所以有足够的堆空间来应付它们是很重要的。即使堆空间是比较小的时候,
也能为操作系统文件缓存提供额外的内存。因为 Lucene 使用的许多数据结构是基于磁盘的格式,
Elasticsearch 利用操作系统缓存能产生很大效果。
-------------------------------------------------------------------------------------------------
64 GB 内存的机器是非常理想的,但是 32 GB 和 16 GB 机器也是很常见的。
少于 8 GB 会适得其反(你最终需要很多很多的小机器),大于 64 GB 的机器也会有问题。
-------------------------------------------------------------------------------------------------
由于 ES 构建基于 lucene,而 lucene 设计强大之处在于 lucene 能够很好的利用操作系统内存来缓存索引数据,
以提供快速的查询性能。lucene 的索引文件 segements 是存储在单文件中的,并且不可变,对于 OS 来说,
能够很友好地将索引文件保持在 cache 中,以便快速访问;
因此,我们很有必要将一半的物理内存留给 lucene;另一半的物理内存留给 ES(JVM heap)。
a.内存分配
当机器内存小于 64G 时,遵循通用的原则,50% 给 ES,50% 留给 lucene。
当机器内存大于 64G 时,遵循以下原则:
如果主要的使用场景是全文检索,那么建议给 ES Heap 分配 4~32G 的内存即可;其它内存留给操作系统,供 lucene 使用(segments cache),以提供更快的查询性能。
如果主要的使用场景是聚合或排序,并且大多数是 numerics,dates,geo_points 以及 not_analyzed 的字符类型,建议分配给 ES Heap 分配 4~32G 的内存即可,其它内存留给操作系统,供 lucene 使用,提供快速的基于文档的聚类、排序性能。
如果使用场景是聚合或排序,并且都是基于 analyzed 字符数据,这时需要更多的 heap size,建议机器上运行多 ES 实例,每个实例保持不超过 50% 的 ES heap 设置(但不超过 32 G,堆内存设置 32 G 以下时,JVM 使用对象指标压缩技巧节省空间),50% 以上留给 lucene。
b.禁止 swap
禁止 swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。可以通过在 elasticsearch.yml 中
bootstrap.memory_lock: true,以保持 JVM 锁定内存,保证 ES 的性能。
c.GC 设置
保持 GC 的现有设置,默认设置为:Concurrent-Mark and Sweep(CMS),
别换成 G1 GC,因为目前 G1 还有很多 BUG。
-------------------------------------------------------------------------------------------------
保持线程池的现有设置,目前 ES 的线程池较 1.X 有了较多优化设置,保持现状即可;
默认线程池大小等于 CPU 核心数。如果一定要改,按公式 ( ( CPU 核心数 * 3 ) / 2 ) + 1 设置;
不能超过 CPU 核心数的 2 倍;但是不建议修改默认配置,否则会对 CPU 造成硬伤。
c.磁盘
硬盘对所有的集群都很重要,对大量写入的集群更是加倍重要(例如那些存储日志数据的)。
硬盘是服务器上最慢的子系统,这意味着那些写入量很大的集群很容易让硬盘饱和,使得它成为集群的瓶颈。
-----------------------------------------------------------------------------------------------------
在经济压力能承受的范围下,尽量使用固态硬盘(SSD)。固态硬盘相比于任何旋转介质(机械硬盘,磁带等),
无论随机写还是顺序写,都会对 IO 有较大的提升。
-----------------------------------------------------------------------------------------------------
如果你正在使用 SSDs,确保你的系统 I/O 调度程序是配置正确的。当你向硬盘写数据,I/O 调度程序决定何时把数据实际发送到硬盘。大多数默认 *nix 发行版下的调度程序都叫做 cfq(完全公平队列)。
调度程序分配时间片到每个进程。并且优化这些到硬盘的众多队列的传递。但它是为旋转介质优化的:机械硬盘的固有特性意味着它写入数据到基于物理布局的硬盘会更高效。
这对 SSD 来说是低效的,尽管这里没有涉及到机械硬盘。但是,deadline 或者 noop 应该被使用。deadline 调度程序基于写入等待时间进行优化,noop 只是一个简单的 FIFO 队列。
这个简单的更改可以带来显著的影响。仅仅是使用正确的调度程序,我们看到了 500 倍的写入能力提升。
-----------------------------------------------------------------------------------------------------
如果你使用旋转介质(如机械硬盘),尝试获取尽可能快的硬盘(高性能服务器硬盘,15k RPM 驱动器)。
使用 RAID0 是提高硬盘速度的有效途径,对机械硬盘和 SSD 来说都是如此。没有必要使用镜像或其它 RAID 变体,因为 Elasticsearch 在自身层面通过副本,已经提供了备份的功能,所以不需要利用磁盘的备份功能,同时如果使用磁盘备份功能的话,对写入速度有较大的影响。
最后,避免使用网络附加存储(NAS)。人们常声称他们的 NAS 解决方案比本地驱动器更快更可靠。除却这些声称,我们从没看到 NAS 能配得上它的大肆宣传。NAS 常常很慢,显露出更大的延时和更宽的平均延时方差,而且它是单点故障的。
02.索引优化设置
a.介绍
索引优化主要是在 Elasticsearch 的插入层面优化,Elasticsearch 本身索引速度其实还是蛮快的,
具体数据,我们可以参考官方的 benchmark 数据。我们可以根据不同的需求,针对索引优化。
b.批量提交
当有大量数据提交的时候,建议采用批量提交(Bulk 操作);此外使用 bulk 请求时,每个请求不超过几十 M,因为太大会导致内存使用过大。
比如在做 ELK 过程中,Logstash indexer 提交数据到 Elasticsearch 中,batch size 就可以作为一个优化功能点。但是优化 size 大小需要根据文档大小和服务器性能而定。
像 Logstash 中提交文档大小超过 20MB,Logstash 会将一个批量请求切分为多个批量请求。
如果在提交过程中,遇到 EsRejectedExecutionException 异常的话,则说明集群的索引性能已经达到极限了。这种情况,要么提高服务器集群的资源,要么根据业务规则,减少数据收集速度,比如只收集 Warn、Error 级别以上的日志。
c.增加 Refresh 时间间隔
为了提高索引性能,Elasticsearch 在写入数据的时候,采用延迟写入的策略,即数据先写到内存中,当超过默认 1 秒(index.refresh_interval)会进行一次写入操作,就是将内存中 segment 数据刷新到磁盘中,此时我们才能将数据搜索出来,所以这就是为什么 Elasticsearch 提供的是近实时搜索功能,而不是实时搜索功能。
如果我们的系统对数据延迟要求不高的话,我们可以通过延长 refresh 时间间隔,可以有效地减少 segment 合并压力,提高索引速度。比如在做全链路跟踪的过程中,我们就将 index.refresh_interval 设置为 30s,减少 refresh 次数。再如,在进行全量索引时,可以将 refresh 次数临时关闭,即 index.refresh_interval 设置为-1,数据导入成功后再打开到正常模式,比如 30s。
在加载大量数据时候可以暂时不用 refresh 和 repliccas,index.refresh_interval 设置为-1,index.number_of_replicas 设置为 0。
d.修改 index_buffer_size 的设置
索引缓冲的设置可以控制多少内存分配给索引进程。这是一个全局配置,会应用于一个节点上所有不同的分片上。
indices.memory.index_buffer_size: 10%
indices.memory.min_index_buffer_size: 48mb
indices.memory.index_buffer_size 接受一个百分比或者一个表示字节大小的值。默认是 10%,意味着分配给节点的总内存的 10%用来做索引缓冲的大小。这个数值被分到不同的分片(shards)上。如果设置的是百分比,还可以设置 min_index_buffer_size (默认 48mb)和 max_index_buffer_size(默认没有上限)。
e.修改 translog 相关的设置
一是控制数据从内存到硬盘的操作频率,以减少硬盘 IO。可将 sync_interval 的时间设置大一些。默认为 5s。
index.translog.sync_interval: 5s
也可以控制 tranlog 数据块的大小,达到 threshold 大小时,才会 flush 到 lucene 索引文件。默认为 512m。
index.translog.flush_threshold_size: 512mb
f.注意 _id 字段的使用
_id 字段的使用,应尽可能避免自定义 _id,以避免针对 ID 的版本管理;建议使用 ES 的默认 ID 生成策略或使用数字类型 ID 做为主键。
g.注意 _all 字段及 _source 字段的使用
**_**all 字段及 _source 字段的使用,应该注意场景和需要,_all 字段包含了所有的索引字段,方便做全文检索,如果无此需求,可以禁用;_source 存储了原始的 document 内容,如果没有获取原始文档数据的需求,可通过设置 includes、excludes 属性来定义放入 _source 的字段。
h.合理的配置使用 index 属性
合理的配置使用 index 属性,analyzed 和 not_analyzed,根据业务需求来控制字段是否分词或不分词。只有 groupby 需求的字段,配置时就设置成 not_analyzed,以提高查询或聚类的效率。
i.减少副本数量
Elasticsearch 默认副本数量为 3 个,虽然这样会提高集群的可用性,增加搜索的并发数,但是同时也会影响写入索引的效率。
在索引过程中,需要把更新的文档发到副本节点上,等副本节点生效后在进行返回结束。使用 Elasticsearch 做业务搜索的时候,建议副本数目还是设置为 3 个,但是像内部 ELK 日志系统、分布式跟踪系统中,完全可以将副本数目设置为 1 个。
03.查询方面优化
a.路由优化
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来的。
shard = hash(routing) % number_of_primary_shards
routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID。
-----------------------------------------------------------------------------------------------------
#不带 routing 查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为 2 个步骤:
分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
聚合:协调节点搜集到每个分片上查询结果,再将查询的结果进行排序,之后给用户返回结果。
-----------------------------------------------------------------------------------------------------
#带 routing 查询
查询的时候,可以直接根据 routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。
向上面自定义的用户查询,如果 routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
b.Filter VS Query
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
Query:此文档与此查询子句的匹配程度如何?
Filter:此文档和查询子句匹配吗?
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时 Filter 结果可以缓存。
c.深度翻页
在使用 Elasticsearch 过程中,应尽量避免大翻页的出现。
正常翻页查询都是从 from 开始 size 条数据,这样就需要在每个分片中查询打分排名在前面的 from+size 条数据。协同节点收集每个分配的前 from+size 条数据。协同节点一共会受到 N*(from+size) 条数据,然后进行排序,再将其中 from 到 from+size 条数据返回出去。如果 from 或者 size 很大的话,导致参加排序的数量会同步扩大很多,最终会导致 CPU 资源消耗增大。
可以通过使用 Elasticsearch scroll 和 scroll-scan 高效滚动的方式来解决这样的问题。
也可以结合实际业务特点,文档 id 大小如果和文档创建时间是一致有序的,可以以文档 id 作为分页的偏移量,并将其作为分页查询的一个条件。
d.脚本(script)合理使用
我们知道脚本使用主要有 3 种形式,内联动态编译方式、_script 索引库中存储和文件脚本存储的形式;一般脚本的使用场景是粗排,尽量用第二种方式先将脚本存储在 _script 索引库中,起到提前编译,然后通过引用脚本 id,并结合 params 参数使用,即可以达到模型(逻辑)和数据进行了分离,同时又便于脚本模块的扩展与维护。具体 ES 脚本的深入内容请参考 Elasticsearch 脚本模块的详解 (opens new window)。
04.数据结构优化
a.尽量减少不需要的字段
如果 Elasticsearch 用于业务搜索服务,一些不需要用于搜索的字段最好不存到 ES 中,这样即节省空间,同时在相同的数据量下,也能提高搜索性能。
避免使用动态值作字段,动态递增的 mapping,会导致集群崩溃;同样,也需要控制字段的数量,业务中不使用的字段,就不要索引。控制索引的字段数量、mapping 深度、索引字段的类型,对于 ES 的性能优化是重中之重。
以下是 ES 关于字段数、mapping 深度的一些默认设置:
index.mapping.nested_objects.limit: 10000
index.mapping.total_fields.limit: 1000
index.mapping.depth.limit: 20
b.Nested Object vs Parent/Child
尽量避免使用 nested 或 parent/child 的字段,能不用就不用;nested query 慢,parent/child query 更慢,比 nested query 慢上百倍;因此能在 mapping 设计阶段搞定的(大宽表设计或采用比较 smart 的数据结构),就不要用父子关系的 mapping。
如果一定要使用 nested fields,保证 nested fields 字段不能过多,目前 ES 默认限制是 50。因为针对 1 个 document,每一个 nested field,都会生成一个独立的 document,这将使 doc 数量剧增,影响查询效率,尤其是 JOIN 的效率。
index.mapping.nested_fields.limit: 50
对比 Nested Object Parent/Child
优点 文档存储在一起,因此读取性高 父子文档可以独立更新,互不影响
缺点 更新父文档或子文档时需要更新整个文档 为了维护 join 关系,需要占用部分内存,读取性能较差
场景 子文档偶尔更新,查询频繁 子文档更新频繁
c.选择静态映射,非必需时,禁止动态映射
尽量避免使用动态映射,这样有可能会导致集群崩溃,此外,动态映射有可能会带来不可控制的数据类型,进而有可能导致在查询端出现相关异常,影响业务。
此外,Elasticsearch 作为搜索引擎时,主要承载 query 的匹配和排序的功能,那数据的存储类型基于这两种功能的用途分为两类,一是需要匹配的字段,用来建立倒排索引对 query 匹配用,另一类字段是用做粗排用到的特征字段,如 ctr、点击数、评论数等等。
05.集群架构设计
a.主节点、数据节点和协调节点分离
a.介绍
Elasticsearch 集群在架构拓朴时,采用主节点、数据节点和负载均衡节点分离的架构,在 5.x 版本以后,又可将数据节点再细分为“Hot-Warm”的架构模式。
Elasticsearch 的配置文件中有 2 个参数,node.master 和 node.data。这两个参数搭配使用时,能够帮助提供服务器性能。
b.主(master)节点
配置 node.master:true 和 node.data:false,该 node 服务器只作为一个主节点,但不存储任何索引数据。
我们推荐每个集群运行 3 个专用的 master 节点来提供最好的弹性。使用时,
你还需要将 discovery.zen.minimum_master_nodes setting 参数设置为 2,以免出现脑裂(split-brain)的情况。
用 3 个专用的 master 节点,专门负责处理集群的管理以及加强状态的整体稳定性。
因为这 3 个 master 节点不包含数据也不会实际参与搜索以及索引操作,在 JVM 上它们不用做相同的事,
例如繁重的索引或者耗时,资源耗费很大的搜索。因此不太可能会因为垃圾回收而导致停顿。
因此,master 节点的 CPU,内存以及磁盘配置可以比 data 节点少很多的。
c.数据(data)节点
配置 node.master:false 和 node.data:true,该 node 服务器只作为一个数据节点,只用于存储索引数据,使该 node 服务器功能单一,只用于数据存储和数据查询,降低其资源消耗率。
在 Elasticsearch 5.x 版本之后,data 节点又可再细分为“Hot-Warm”架构,即分为热节点(hot node)和暖节点(warm node)。
-------------------------------------------------------------------------------------------------
hot 节点:
hot 节点主要是索引节点(写节点),同时会保存近期的一些频繁被查询的索引。由于进行索引非常耗费 CPU 和 IO,即属于 IO 和 CPU 密集型操作,建议使用 SSD 的磁盘类型,保持良好的写性能;我们推荐部署最小化的 3 个 hot 节点来保证高可用性。根据近期需要收集以及查询的数据量,可以增加服务器数量来获得想要的性能。
将节点设置为 hot 类型需要 elasticsearch.yml 如下配置:
node.attr.box_type: hot
如果是针对指定的 index 操作,可以通过 settings 设置 index.routing.allocation.require.box_type: hot 将索引写入 hot 节点。
-------------------------------------------------------------------------------------------------
warm 节点:
这种类型的节点是为了处理大量的,而且不经常访问的只读索引而设计的。由于这些索引是只读的,warm 节点倾向于挂载大量磁盘(普通磁盘)来替代 SSD。内存、CPU 的配置跟 hot 节点保持一致即可;节点数量一般也是大于等于 3 个。
将节点设置为 warm 类型需要 elasticsearch.yml 如下配置:
node.attr.box_type: warm
同时,也可以在 elasticsearch.yml 中设置 index.codec:best_compression 保证 warm 节点的压缩配置
当索引不再被频繁查询时,可通过 index.routing.allocation.require.box_type:warm,将索引标记为 warm,从而保证索引不写入 hot 节点,以便将 SSD 磁盘资源用在刀刃上。一旦设置这个属性,ES 会自动将索引合并到 warm 节点。
d.协调(coordinating)节点
协调节点用于做分布式里的协调,将各分片或节点返回的数据整合后返回。该节点不会被选作主节点,也不会存储任何索引数据。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个 node 服务器上查询数据,并将请求分发到多个指定的 node 服务器,并对各个 node 服务器返回的结果进行一个汇总处理,最终返回给客户端。在 ES 集群中,所有的节点都有可能是协调节点,但是,可以通过设置 node.master、node.data、node.ingest 都为 false 来设置专门的协调节点。需要较好的 CPU 和较高的内存。
node.master:false 和 node.data:true,该 node 服务器只作为一个数据节点,只用于存储索引数据,使该 node 服务器功能单一,只用于数据存储和数据查询,降低其资源消耗率。
node.master:true 和 node.data:false,该 node 服务器只作为一个主节点,但不存储任何索引数据,该 node 服务器将使用自身空闲的资源,来协调各种创建索引请求或者查询请求,并将这些请求合理分发到相关的 node 服务器上。
node.master:false 和 node.data:false,该 node 服务器即不会被选作主节点,也不会存储任何索引数据。该服务器主要用于查询负载均衡。在查询的时候,通常会涉及到从多个 node 服务器上查询数据,并将请求分发到多个指定的 node 服务器,并对各个 node 服务器返回的结果进行一个汇总处理,最终返回给客户端。
b.关闭 data 节点服务器中的 http 功能
针对 Elasticsearch 集群中的所有数据节点,不用开启 http 服务。将其中的配置参数这样设置,http.enabled:false,同时也不要安装 head, bigdesk, marvel 等监控插件,这样保证 data 节点服务器只需处理创建/更新/删除/查询索引数据等操作。
http 功能可以在非数据节点服务器上开启,上述相关的监控插件也安装到这些服务器上,用于监控 Elasticsearch 集群状态等数据信息。这样做一来出于数据安全考虑,二来出于服务性能考虑。
c.一台服务器上最好只部署一个 node
一台物理服务器上可以启动多个 node 服务器节点(通过设置不同的启动 port),但一台服务器上的 CPU、内存、硬盘等资源毕竟有限,从服务器性能考虑,不建议一台服务器上启动多个 node 节点。
d.集群分片设置
ES 一旦创建好索引后,就无法调整分片的设置,而在 ES 中,一个分片实际上对应一个 lucene 索引,而 lucene 索引的读写会占用很多的系统资源,因此,分片数不能设置过大;所以,在创建索引时,合理配置分片数是非常重要的。一般来说,我们遵循一些原则:
控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32 G,参考上面的 JVM 内存设置原则),因此,如果索引的总容量在 500 G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。
考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以,一般都设置分片数不超过节点数的 3 倍。
3 ElasticSearch查询1
3.1 汇总
00.使用
a.全文查询:match
intervals:基于间隔查询,用于匹配特定词语或短语在指定位置间隔内出现的文档。
match:用于全文匹配,将查询字符串分词后,与字段的倒排索引进行匹配。
match_bool_prefix:类似于 match 查询,但支持前缀匹配,特别适用于补全查询。
match_phrase:用于匹配整个短语,要求短语中的词按顺序出现在文档中。
match_phrase_prefix:类似于 match_phrase 查询,但支持最后一个词的前缀匹配,适合处理未完整输入的短语。
multi_match:扩展的 match 查询,允许在多个字段上同时进行匹配。
combined_fields:将多个字段组合为一个字段进行匹配,以提高相关性计算。
common_terms:处理频繁出现的常用词,控制这些词的影响,以提升查询的效率和准确度。
query_string:允许使用查询字符串语法进行查询,支持布尔操作符、通配符等高级查询。
simple_query_string:类似于 query_string,但更简化,具有更严格的语法控制,适合用户直接输入。
b.词项查询:term
exists:用于检查某个字段是否存在于文档中。
fuzzy:执行模糊匹配查询,允许对词项进行少量的编辑操作(如插入、删除、替换或移动字符)以匹配近似的词。
ids:根据文档的 _id 字段进行查询,返回指定 ID 的文档。
prefix:用于前缀匹配,查询以指定前缀开头的词项。
range:用于范围查询,允许基于数字、日期或字符串字段指定上下限。
regexp:执行正则表达式查询,用于匹配符合正则表达式的词项。
term:精确匹配查询,用于查找字段中包含精确值的文档。
terms:类似于 term 查询,但允许指定多个精确值进行查询。
type:用于查询指定 _type 字段的文档(在 7.x 版本后逐渐被弃用)。
wildcard:通配符查询,允许使用 * 或 ? 通配符进行词项的模糊匹配。
c.复合查询:bool
bool:允许将多个查询条件组合在一起,通过 must、should、must_not 和 filter 条件控制查询逻辑。
boosting:用于执行加权查询,提升匹配特定条件的文档得分,同时降低其他条件下文档的得分。
constant_score:忽略查询的相关性评分,返回固定评分的结果,通常用于过滤查询。
dis_max:在多个查询之间选择得分最高的文档,适合组合多个子查询并返回最相关的结果。
function_score:允许通过定义评分函数来调整文档的相关性得分,用于复杂的得分计算。
indices:根据索引名称来执行不同的查询,当索引符合特定条件时,应用不同的查询逻辑(在新版本中逐渐被弃用)。
d.嵌套查询:nested
Elasticsearch 提供了以下两种形式的 join:
nested(嵌套查询):文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来。
has_child(有子查询):父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档
has_parent(有父查询):父子关系可以存在单个的索引的两个类型的文档之间。has_parent 则返回其父文档能满足特定查询的子文档
e.位置查询:geo
geo_distance:用于计算两个地理位置(经纬度坐标)之间的距离。此查询可以用于基于距离的过滤,帮助用户找到特定半径内的文档。
geoboundingbox:表示一个矩形区域,由西南和东北两个角的经纬度坐标定义。使用此查询可以快速找到位于该矩形范围内的文档。
geo_polygon:用于定义一个多边形区域,该区域由一系列经纬度坐标构成。此查询可以用于查找位于多边形内部的文档,适用于更复杂的地理区域。
geo_shape:支持多种形状(如点、线、面等)的地理查询。使用此查询可以匹配复杂的地理形状,适合于对地理数据有更高需求的应用场景。
f.特殊查询:script
more_like_this:用于查找与给定文档相似的文档。该查询会分析输入文档的内容,提取关键词,并找到与这些关键词匹配的其他文档,从而提供相似性搜索的功能。
script:允许用户使用脚本来自定义查询逻辑。通过脚本,用户可以在查询、过滤或评分阶段执行自定义操作,从而实现更复杂的查询条件和行为。
percolate:用于在一组查询中查找与给定文档匹配的查询。该查询类型适用于监控、通知和事件检测等场景,用户可以预先定义多个查询,然后通过该机制检查新文档是否与任何预定义查询相匹配。
01.搜索分为两个过程:
a.过程1
当向索引中保存文档时,默认情况下,es 会保存两份内容,一份是 _source 中的数据,
另一份则是通过分词、排序等一系列过程生成的倒排索引文件,倒排索引中保存了词项和文档之间的对应关系。
b.过程2
搜索时,当 es 接收到用户的搜索请求之后,就会去倒排索引中查询,通过的倒排索引中维护的倒排记录表找到
关键词对应的文档集合,然后对文档进行评分、排序、高亮等处理,处理完成后返回文档。
02.查询从机制分为两种
a.方式1
一种是根据用户输入的查询词,通过排序模型计算文档与查询词之间的相关度,并根据评分高低排序返回
b.方式2
另一种是过滤机制,只根据过滤条件对文档进行过滤,不计算评分,速度相对较快。
03.搜索的两种方式
a.方式1:查询字符串搜索
GET /user/_search?q=name:张三
b.方式2:DSL查询
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL)
它允许你构建更加复杂、强大的查询
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
-----------------------------------------------------------------------------------------------------
GET user/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
平时更多采用这种方式,因为可操作性更强,处理复杂请求时更得心应手。
3.2 全文查询:match
00.汇总
a.介绍
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
b.term和match的区别
match是经过analyer的,也就是说,文档首先被分析器给处理了。根据不同的分析器,分析的结果也稍显不同,然后再根据分词结果进行匹配。
term则不经过分词,它是直接去倒排索引中查找了精确的值了。
c.汇总1
match_all:查询全部。
match:返回所有匹配的分词。
match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配。其实默认是50.......
multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
d.汇总2
01.intervals:基于间隔查询,用于匹配特定词语或短语在指定位置间隔内出现的文档。
02.match:用于全文匹配,将查询字符串分词后,与字段的倒排索引进行匹配。
03.match_bool_prefix:类似于 match 查询,但支持前缀匹配,特别适用于补全查询。
04.match_phrase:用于匹配整个短语,要求短语中的词按顺序出现在文档中。
05.match_phrase_prefix:类似于 match_phrase 查询,但支持最后一个词的前缀匹配,适合处理未完整输入的短语。
06.multi_match:扩展的 match 查询,允许在多个字段上同时进行匹配。
07.combined_fields:将多个字段组合为一个字段进行匹配,以提高相关性计算。
08.common_terms:处理频繁出现的常用词,控制这些词的影响,以提升查询的效率和准确度。
09.query_string:允许使用查询字符串语法进行查询,支持布尔操作符、通配符等高级查询。
10.simple_query_string:类似于 query_string,但更简化,具有更严格的语法控制,适合用户直接输入。
-------------------------------------------------------------------------------------------------------------
00.准备数据
PUT /test1/_doc/1
{
"name":"Jack",
"age":18,
"sex":"男",
"address":"美国纽约州",
"remark":"美国是世界上军事实力最强大的国家"
}
PUT /test1/_doc/2
{
"name":"李四",
"age":29,
"sex":"男",
"address":"中国广东省广州市",
"remark":"中国是世界上人口最多的国家"
}
PUT /test1/_doc/3
{
"name":"阿三",
"age":30,
"sex":"男",
"address":"印度新德里",
"remark":"印度的食品干净又卫生"
}
PUT /test1/_doc/4
{
"name":"王五",
"age":30,
"sex":"男",
"address":"中国北京市三里屯",
"remark":"中国的首都是北京市"
}
01.match_all:查询全部。
GET /test1/_search
{
"query": {
"match_all": {}
}
}
---------------------------------------------------------------------------------------------------------
这个没啥好说的。
02.match:返回所有匹配的分词。
POST /test1/_search
{
"query": {
"match": {
"address": "中国"
}
}
}
---------------------------------------------------------------------------------------------------------
从结果我们可以看到,我查询的条件是中国,虽然如期的返回了中国的文档,
但是为什么含有美国的地址信息也被查询出来了,这并不是我们想要的,是怎么回事呢?
因为这是elasticsearch在内部对文档做分词的时候,对于中文来说,就是一个字一个字分的,例如:'I Love You',
此时会被分为三个词分别是:I、Love、You,而中文也是一样的,例如:‘我爱中国’,会被分词为:我、爱、中、国。
所以我们的查询条件也会被分为:中和国,所以中和国都符合条件,
当去查询文档的时候,此时美国中的 国 字也符合,所以匹配上了并且将结果返回了。
而我们认为中国是个短语,是一个有具体含义的词。
所以elasticsearch在处理中文分词方面比较弱势。后面会讲针对中文的分词插件。
但目前我们还有办法解决,那就是使用短语查询 用match_phrase来处理。
03.match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
GET /test1/_search
{
"query": {
"match_phrase": {
"address": {
"query": "中国"
}
}
}
}
---------------------------------------------------------------------------------------------------------
此时可以发现返回的结果中只包含了中国的文档数据。
04.match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配。其实默认是50.......
最左前缀查询,智能搜索--以什么开头
GET /test1/_search
{
"query": {
"match_phrase_prefix": {
"remark": "印度"
}
}
}
---------------------------------------------------------------------------------------------------------
查询地址以 印度 开头的文档信息
05.multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
multi_match是要在多个字段中查询同一个关键字 除此之外,
mulit_match甚至可以当做match_phrase和match_phrase_prefix使用,只需要指定type类型即可
---------------------------------------------------------------------------------------------------------
GET /test1/_search
{
"query": {
"multi_match": {
"query": "中国",
"fields": ["address","remark"]
}
}
}
---------------------------------------------------------------------------------------------------------
加上phrase属性,当设置属性 type:phrase 时 等同于 短语查询。
GET /test1/_search
{
"query": {
"multi_match": {
"query": "中国",
"fields": ["address","remark"],
"type": "phrase"
}
}
}
---------------------------------------------------------------------------------------------------------
加上phrase_prefix属性,当设置属性 type:phrase_prefix时 等同于 最左前缀查询。
GET /test1/_search
{
"query": {
"multi_match": {
"query": "中国",
"fields": ["address","remark"],
"type": "phrase_prefix"
}
}
}
-------------------------------------------------------------------------------------------------------------
01.intervals
intervals query (opens new window)根据匹配词的顺序和近似度返回文档。
intervals query 使用匹配规则,这些规则应用于指定字段中的 term。
示例:下面示例搜索 query 字段,搜索值是 my favorite food,没有任何间隙;然后是 my_text 字段搜索匹配 hot water、cold porridge 的 term。
当 my_text 中的值为 my favorite food is cold porridge 时,会匹配成功,但是 when it's cold my favorite food is porridge 则匹配失败
---------------------------------------------------------------------------------------------------------
POST _search
{
"query": {
"intervals" : {
"my_text" : {
"all_of" : {
"ordered" : true,
"intervals" : [
{
"match" : {
"query" : "my favorite food",
"max_gaps" : 0,
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "hot water" } },
{ "match" : { "query" : "cold porridge" } }
]
}
}
]
}
}
}
}
}
02.match
a.示例
match query (opens new window)用于搜索单个字段,首先会针对查询语句进行解析(经过 analyzer),
主要是对查询语句进行分词,分词后查询语句的任何一个词项被匹配,文档就会被搜到,
默认情况下相当于对分词后词项进行 or 匹配操作。
match query (opens new window)是执行全文搜索的标准查询,包括模糊匹配选项。
-----------------------------------------------------------------------------------------------------
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_full_name": {
"query": "George Hubbard"
}
}
}
}
-----------------------------------------------------------------------------------------------------
等同于 or 匹配操作,如下:
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_full_name": {
"query": "George Hubbard",
"operator": "or"
}
}
}
}
b.match query 简写
可以通过组合 <field> 和 query 参数来简化匹配查询语法。
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"match": {
"message": "this is a test"
}
}
}
c.match query 如何工作
匹配查询是布尔类型。这意味着会对提供的文本进行分析,分析过程从提供的文本构造一个布尔查询。
operator 参数可以设置为 or 或 and 来控制布尔子句(默认为 or)。
可以使用 minimum_should_match (opens new window)参数设置要匹配的可选 should 子句的最小数量。
-----------------------------------------------------------------------------------------------------
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_full_name": {
"query": "George Hubbard",
"operator": "and"
}
}
}
}
-----------------------------------------------------------------------------------------------------
可以设置 analyzer 来控制哪个分析器将对文本执行分析过程。它默认为字段显式映射定义或默认搜索分析器。
lenient 参数可以设置为 true 以忽略由数据类型不匹配导致的异常,例如尝试使用文本查询字符串查询数字字段。默认为 false。
d.match query 的模糊查询
fuzziness 允许基于被查询字段的类型进行模糊匹配。请参阅 Fuzziness (opens new window)的配置。
在这种情况下可以设置 prefix_length 和 max_expansions 来控制模糊匹配。如果设置了模糊选项,查询将使用 top_terms_blended_freqs_${max_expansions} 作为其重写方法,fuzzy_rewrite 参数允许控制查询将如何被重写。
默认情况下允许模糊倒转 (ab → ba),但可以通过将 fuzzy_transpositions 设置为 false 来禁用。
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"match": {
"message": {
"query": "this is a testt",
"fuzziness": "AUTO"
}
}
}
}
e.zero terms 查询
如果使用的分析器像 stop 过滤器一样删除查询中的所有标记,则默认行为是不匹配任何文档。
可以使用 zero_terms_query 选项来改变默认行为,它接受 none(默认)和 all (相当于 match_all 查询)。
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"match": {
"message": {
"query": "to be or not to be",
"operator": "and",
"zero_terms_query": "all"
}
}
}
}
03.match_bool_prefix
a.介绍
match_bool_prefix query (opens new window)分析其输入并根据这些词构造一个布尔查询。
除了最后一个术语之外的每个术语都用于术语查询。最后一个词用于 prefix query。
b.示例
GET /_search
{
"query": {
"match_bool_prefix" : {
"message" : "quick brown f"
}
}
}
-----------------------------------------------------------------------------------------------------
等价于
GET /_search
{
"query": {
"bool" : {
"should": [
{ "term": { "message": "quick" }},
{ "term": { "message": "brown" }},
{ "prefix": { "message": "f"}}
]
}
}
}
-----------------------------------------------------------------------------------------------------
match_bool_prefix query 和 match_phrase_prefix query 之间的一个重要区别是:match_phrase_prefix query 将其 term 匹配为短语,但 match_bool_prefix query 可以在任何位置匹配其 term。
上面的示例 match_bool_prefix query 查询可以匹配包含 quick brown fox 的字段,但它也可以快速匹配 brown fox。它还可以匹配包含 quick、brown 和以 f 开头的字段,出现在任何位置。
04.match_phrase
a.介绍
match_phrase query (opens new window)即短语匹配,首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
分词后所有词项都要出现在该字段中(相当于 and 操作)。
字段中的词项顺序要一致。
b.例如,有以下 3 个文档,使用 match_phrase 查询 "How are you",只有前两个文档会被匹配:
PUT demo/_create/1
{ "desc": "How are you" }
PUT demo/_create/2
{ "desc": "How are you, Jack?"}
PUT demo/_create/3
{ "desc": "are you"}
GET demo/_search
{
"query": {
"match_phrase": {
"desc": "How are you"
}
}
}
-----------------------------------------------------------------------------------------------------
说明:
一个被认定为和短语 How are you 匹配的文档,必须满足以下这些要求:
How、 are 和 you 需要全部出现在域中。
are 的位置应该比 How 的位置大 1 。
you 的位置应该比 How 的位置大 2 。
05.match_phrase_prefix
a.介绍
match_phrase_prefix query (opens new window)和 match_phrase query (opens new window)类似,
只不过 match_phrase_prefix query (opens new window)最后一个 term 会被作为前缀匹配。
b.示例
GET demo/_search
{
"query": {
"match_phrase_prefix": {
"desc": "are yo"
}
}
}
06.multi_match
a.代码
multi_match query (opens new window)是 match query 的升级,用于搜索多个字段。
GET kibana_sample_data_ecommerce/_search
{
"query": {
"multi_match": {
"query": 34.98,
"fields": [
"taxful_total_price",
"taxless_total_price"
]
}
}
}
b.代码
multi_match query 的搜索字段可以使用通配符指定,示例如下:
GET kibana_sample_data_ecommerce/_search
{
"query": {
"multi_match": {
"query": 34.98,
"fields": [
"taxful_*",
"taxless_total_price"
]
}
}
}
c.代码
同时,也可以用指数符指定搜索字段的权重。
示例:指定 taxful_total_price 字段的权重是 taxless_total_price 字段的 3 倍,命令如下:
GET kibana_sample_data_ecommerce/_search
{
"query": {
"multi_match": {
"query": 34.98,
"fields": [
"taxful_total_price^3",
"taxless_total_price"
]
}
}
}
07.combined_fields
a.介绍
combined_fields query (opens new window)支持搜索多个文本字段,就好像它们的内容已被索引到一个组合字段中一样。
该查询会生成以 term 为中心的输入字符串视图:首先它将查询字符串解析为独立的 term,然后在所有字段中查找每个
term。当匹配结果可能跨越多个文本字段时,此查询特别有用,例如文章的标题、摘要和正文:
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"combined_fields" : {
"query": "database systems",
"fields": [ "title", "abstract", "body"],
"operator": "and"
}
}
}
b.字段前缀权重
字段前缀权重根据组合字段模型进行计算。例如,如果 title 字段的权重为 2,
则匹配度打分时会将 title 中的每个 term 形成的组合字段,按出现两次进行打分。
08.common_terms
a.介绍
7.3.0 废弃
b.介绍
common_terms query (opens new window)是一种在不牺牲性能的情况下替代停用词提高搜索准确率和召回率的方案。
查询中的每个词项都有一定的代价,以搜索“The brown fox”为例,query 会被解析成三个词项“the”“brown”和“fox”,每个词项都会到索引中执行一次查询。很显然包含“the”的文档非常多,相比其他词项,“the”的重要性会低很多。传统的解决方案是把“the”当作停用词处理,去除停用词之后可以减少索引大小,同时在搜索时减少对停用词的收缩。
虽然停用词对文档评分影响不大,但是当停用词仍然有重要意义的时候,去除停用词就不是完美的解决方案了。如果去除停用词,就无法区分“happy”和“not happy”, “The”“To be or not to be”就不会在索引中存在,搜索的准确率和召回率就会降低。
common_terms query 提供了一种解决方案,它把 query 分词后的词项分成重要词项(低频词项)和不重要的词项(高频词,也就是之前的停用词)。在搜索的时候,首先搜索和重要词项匹配的文档,这些文档是词项出现较少并且词项对其评分影响较大的文档。然后执行第二次查询,搜索对评分影响较小的高频词项,但是不计算所有文档的评分,而是只计算第一次查询已经匹配的文档得分。如果一个查询中只包含高频词,那么会通过 and 连接符执行一个单独的查询,换言之,会搜索所有的词项。
词项是高频词还是低频词是通过 cutoff frequency 来设置阀值的,取值可以是绝对频率(频率大于 1)或者相对频率(0 ~ 1)。common_terms query 最有趣之处在于它能自适应特定领域的停用词,例如,在视频托管网站上,诸如“clip”或“video”之类的高频词项将自动表现为停用词,无须保留手动列表。
例如,文档频率高于 0.1% 的词项将会被当作高频词项,词频之间可以用 low_freq_operator、high_freq_operator 参数连接。设置低频词操作符为“and”使所有的低频词都是必须搜索的
c.示例
GET books/_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"low_freq_operator": "and"
}
}
}
}
-----------------------------------------------------------------------------------------------------
上述操作等价于:
GET books/_search
{
"query": {
"bool": {
"must": [
{ "term": { "body": "nelly" } },
{ "term": { "body": "elephant" } },
{ "term": { "body": "cartoon" } }
],
"should": [
{ "term": { "body": "the" } },
{ "term": { "body": "as" } },
{ "term": { "body": "a" } }
]
}
}
}
09.query_string
a.介绍
query_string query (opens new window)是与 Lucene 查询语句的语法结合非常紧密的一种查询,
允许在一个查询语句中使用多个特殊条件关键字(如:AND | OR | NOT)对多个字段进行查询,
建议熟悉 Lucene 查询语法的用户去使用。
-----------------------------------------------------------------------------------------------------
会对查询条件进行分词,然后将分词后的查询条件和词条进行等值匹配,
默认取并集(OR),可以指定单个字段也可多个查询字段
b.代码
用户可以使用 query_string query 来创建包含通配符、跨多个字段的搜索等复杂搜索。
虽然通用,但查询是严格的,如果查询字符串包含任何无效语法,则会返回错误。
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"query_string": {
"query": "(new york city) OR (big apple)",
"default_field": "content"
}
}
}
c.代码
POST /test2/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "张三 OR 七七"
}
},
"size": 100
}
d.代码
GET /test2/_search
{
"query": {
"query_string": {
"fields": ["name","address"],
"query": "张三 or 中国"
}
}
}
10.simple_query_string
a.介绍
simple_query_string query (opens new window)是一种适合直接暴露给用户,
并且具有非常完善的查询语法的查询语句,接受 Lucene 查询语法,解析过程中发生错误不会抛出异常。
-----------------------------------------------------------------------------------------------------
虽然语法比 query_string query (opens new window)更严格,
但 simple_query_string query (opens new window)不会返回无效语法的错误。
相反,它会忽略查询字符串的任何无效部分。
b.示例
GET /_search
{
"query": {
"simple_query_string" : {
"query": "\"fried eggs\" +(eggplant | potato) -frittata",
"fields": ["title^5", "body"],
"default_operator": "and"
}
}
}
c.simple_query_string 语义
+:等价于 AND 操作
|:等价于 OR 操作
-:相当于 NOT 操作
":包装一些标记以表示用于搜索的短语
*:词尾表示前缀查询
( and ):表示优先级
~N:词尾表示表示编辑距离(模糊性)
~N:在一个短语之后表示溢出量
注意:要使用上面的字符,请使用反斜杠 / 对其进行转义。
3.3 词项查询:term
00.总结
a.介绍
Term(词项)是表达语意的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理 Term。
全文查询在执行查询之前会分析查询字符串。
与全文查询不同,词项查询不会分词,而是将输入作为一个整体,在倒排索引中查找准确的词项。
并且使用相关度计算公式为每个包含该词项的文档进行相关度计算。一言以概之:词项查询是对词项进行精确匹配。
词项查询通常用于结构化数据,如数字、日期和枚举类型。
b.类型
exists:用于检查某个字段是否存在于文档中。
fuzzy:执行模糊匹配查询,允许对词项进行少量的编辑操作(如插入、删除、替换或移动字符)以匹配近似的词。
ids:根据文档的 _id 字段进行查询,返回指定 ID 的文档。
prefix:用于前缀匹配,查询以指定前缀开头的词项。
range:用于范围查询,允许基于数字、日期或字符串字段指定上下限。
regexp:执行正则表达式查询,用于匹配符合正则表达式的词项。
term:精确匹配查询,用于查找字段中包含精确值的文档。
terms:类似于 term 查询,但允许指定多个精确值进行查询。
type:用于查询指定 _type 字段的文档(在 7.x 版本后逐渐被弃用)。
wildcard:通配符查询,允许使用 * 或 ? 通配符进行词项的模糊匹配。
-------------------------------------------------------------------------------------------------------------
01.exists:用于检查某个字段是否存在于文档中。
a.介绍
exists query (opens new window)会返回字段中至少有一个非空值的文档。
-----------------------------------------------------------------------------------------------------
由于多种原因,文档字段可能不存在索引值:
- JSON 中的字段为 null 或 []
- 该字段在 mapping 中配置了 "index" : false
- 字段值的长度超过了 mapping 中的 ignore_above 设置
- 字段值格式错误,并且在 mapping 中定义了 ignore_malformed
b.示例:
GET kibana_sample_data_ecommerce/_search
{
"query": {
"exists": {
"field": "email"
}
}
}
-----------------------------------------------------------------------------------------------------
以下文档会匹配上面的查询:
{ "user" : "jane" } 有 user 字段,且不为空。
{ "user" : "" } 有 user 字段,值为空字符串。
{ "user" : "-" } 有 user 字段,值不为空。
{ "user" : [ "jane" ] } 有 user 字段,值不为空。
{ "user" : [ "jane", null ] } 有 user 字段,至少一个值不为空即可。
-----------------------------------------------------------------------------------------------------
下面的文档都不会被匹配:
{ "user" : null } 虽然有 user 字段,但是值为空。
{ "user" : [] } 虽然有 user 字段,但是值为空。
{ "user" : [null] } 虽然有 user 字段,但是值为空。
{ "foo" : "bar" } 没有 user 字段。
02.fuzzy:执行模糊匹配查询,允许对词项进行少量的编辑操作(如插入、删除、替换或移动字符)以匹配近似的词。
a.介绍
fuzzy query(模糊查询) (opens new window)返回包含与搜索词相似的词的文档。
ES 使用 Levenshtein edit distance(Levenshtein 编辑距离) (opens new window)测量相似度或模糊度。
-----------------------------------------------------------------------------------------------------
编辑距离是将一个术语转换为另一个术语所需的单个字符更改的数量。这些变化可能包括:
改变一个字符:(box -> fox)
删除一个字符:(black -> lack)
插入一个字符:(sic -> sick)
反转两个相邻字符:(act → cat)
b.为了找到相似的词条,fuzzy query 会在指定的编辑距离内创建搜索词条的所有可能变体或扩展集。然后返回完全匹配任意扩展的文档。
GET books/_search
{
"query": {
"fuzzy": {
"user.id": {
"value": "ki",
"fuzziness": "AUTO",
"max_expansions": 50,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}
-----------------------------------------------------------------------------------------------------
注意:如果配置了 search.allow_expensive_queries (opens new window),则 fuzzy query 不能执行。
03.ids:根据文档的 _id 字段进行查询,返回指定 ID 的文档。
a.介绍
ids query (opens new window)根据 ID 返回文档。 此查询使用存储在 _id 字段中的文档 ID。
b.使用
GET /_search
{
"query": {
"ids" : {
"values" : ["1", "4", "100"]
}
}
}
04.prefix:用于前缀匹配,查询以指定前缀开头的词项。
a.介绍
prefix query (opens new window)用于查询某个字段中包含指定前缀的文档。
比如查询 user.id 中含有以 ki 为前缀的关键词的文档,那么含有 kind、kid 等所有以 ki 开头关键词的文档都会被匹配。
b.使用
GET /_search
{
"query": {
"prefix": {
"user.id": {
"value": "ki"
}
}
}
}
05.range:用于范围查询,允许基于数字、日期或字符串字段指定上下限。
a.介绍
range query (opens new window)即范围查询,用于匹配在某一范围内的数值型、
日期类型或者字符串型字段的文档。比如搜索哪些书籍的价格在 50 到 100 之间、
哪些书籍的出版时间在 2015 年到 2019 年之间。使用 range 查询只能查询一个字段,不能作用在多个字段上。
b.range 查询支持的参数有以下几种:
gt:大于
gte:大于等于
lt:小于
lte:小于等于
format:如果字段是 Date 类型,可以设置日期格式化
time_zone:时区
relation:指示范围查询如何匹配范围字段的值。
INTERSECTS (Default):匹配与查询字段值范围相交的文档。
CONTAINS:匹配完全包含查询字段值的文档。
WITHIN:匹配具有完全在查询范围内的范围字段值的文档。
c.示例:数值范围查询
GET kibana_sample_data_ecommerce/_search
{
"query": {
"range": {
"taxful_total_price": {
"gt": 10,
"lte": 50
}
}
}
}
d.示例:日期范围查询
GET kibana_sample_data_ecommerce/_search
{
"query": {
"range": {
"order_date": {
"time_zone": "+00:00",
"gte": "2018-01-01T00:00:00",
"lte": "now"
}
}
}
}
06.regexp:执行正则表达式查询,用于匹配符合正则表达式的词项。
a.介绍
regexp query (opens new window)返回与正则表达式相匹配的 term 所属的文档。
正则表达式 (opens new window)是一种使用占位符字符匹配数据模式的方法,称为运算符。
b.示例
以下搜索返回 user.id 字段包含任何以 k 开头并以 y 结尾的文档。 .* 运算符匹配任何长度的任何字符,
包括无字符。匹配项可以包括 ky、kay 和 kimchy。
-----------------------------------------------------------------------------------------------------
GET /_search
{
"query": {
"regexp": {
"user.id": {
"value": "k.*y",
"flags": "ALL",
"case_insensitive": true,
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
注意:如果配置了search.allow_expensive_queries (opens new window),则 regexp query (opens new window)会被禁用。
07.term:精确匹配查询,用于查找字段中包含精确值的文档。
a.介绍
term query (opens new window)用来查找指定字段中包含给定单词的文档,term 查询不被解析,
只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精准匹配的需求。
b.示例
# 1. 创建一个索引
DELETE my-index-000001
PUT my-index-000001
{
"mappings": {
"properties": {
"full_text": { "type": "text" }
}
}
}
-----------------------------------------------------------------------------------------------------
# 2. 使用 "Quick Brown Foxes!" 关键字查 "full_text" 字段
PUT my-index-000001/_doc/1
{
"full_text": "Quick Brown Foxes!"
}
-----------------------------------------------------------------------------------------------------
# 3. 使用 term 查询
GET my-index-000001/_search?pretty
{
"query": {
"term": {
"full_text": "Quick Brown Foxes!"
}
}
}
# 因为 full_text 字段不再包含确切的 Term —— "Quick Brown Foxes!",所以 term query 搜索不到任何结果
-----------------------------------------------------------------------------------------------------
# 4. 使用 match 查询
GET my-index-000001/_search?pretty
{
"query": {
"match": {
"full_text": "Quick Brown Foxes!"
}
}
}
-----------------------------------------------------------------------------------------------------
DELETE my-index-000001
-----------------------------------------------------------------------------------------------------
⚠️ 注意:应避免 term 查询对 text 字段使用查询。
默认情况下,Elasticsearch 针对 text 字段的值进行解析分词,这会使查找 text 字段值的精确匹配变得困难。
要搜索 text 字段值,需改用 match 查询。
08.terms:类似于 term 查询,但允许指定多个精确值进行查询。
a.介绍
terms query (opens new window)与 term query (opens new window)相同,但可以搜索多个值。
b.terms query 查询参数:
index:索引名
id:文档 ID
path:要从中获取字段值的字段的名称,即搜索关键字
routing(选填):要从中获取 term 值的文档的自定义路由值。如果在索引文档时提供了自定义路由值,则此参数是必需的。
c.示例:
# 1. 创建一个索引
DELETE my-index-000001
PUT my-index-000001
{
"mappings": {
"properties": {
"color": { "type": "keyword" }
}
}
}
-----------------------------------------------------------------------------------------------------
# 2. 写入一个文档
PUT my-index-000001/_doc/1
{
"color": [
"blue",
"green"
]
}
-----------------------------------------------------------------------------------------------------
# 3. 写入另一个文档
PUT my-index-000001/_doc/2
{
"color": "blue"
}
-----------------------------------------------------------------------------------------------------
# 3. 使用 terms query
GET my-index-000001/_search?pretty
{
"query": {
"terms": {
"color": {
"index": "my-index-000001",
"id": "2",
"path": "color"
}
}
}
}
-----------------------------------------------------------------------------------------------------
DELETE my-index-000001
09.type:用于查询指定 _type 字段的文档(在 7.x 版本后逐渐被弃用)。
a.介绍
7.0.0 后废弃
-----------------------------------------------------------------------------------------------------
type query (opens new window)用于查询具有指定类型的文档。
b.示例:
GET /_search
{
"query": {
"type": {
"value": "_doc"
}
}
}
10.wildcard:通配符查询,允许使用 * 或 ? 通配符进行词项的模糊匹配。
a.介绍
wildcard query (opens new window)即通配符查询,返回与通配符模式匹配的文档。
? 用来匹配一个任意字符,* 用来匹配零个或者多个字符。
b.示例
以下搜索返回 user.id 字段包含以 ki 开头并以 y 结尾的术语的文档。这些匹配项可以包括 kiy、kity 或 kimchy。
GET /_search
{
"query": {
"wildcard": {
"user.id": {
"value": "ki*y",
"boost": 1.0,
"rewrite": "constant_score"
}
}
}
}
注意:如果配置了search.allow_expensive_queries (opens new window),则wildcard query (opens new window)会被禁用。
3.4 复合查询:bool
00.总结
a.介绍
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外,复合查询还可以控制另外一个查询的行为。
b.汇总
bool:允许将多个查询条件组合在一起,通过 must、should、must_not 和 filter 条件控制查询逻辑。
boosting:用于执行加权查询,提升匹配特定条件的文档得分,同时降低其他条件下文档的得分。
constant_score:忽略查询的相关性评分,返回固定评分的结果,通常用于过滤查询。
dis_max:在多个查询之间选择得分最高的文档,适合组合多个子查询并返回最相关的结果。
function_score:允许通过定义评分函数来调整文档的相关性得分,用于复杂的得分计算。
indices:根据索引名称来执行不同的查询,当索引符合特定条件时,应用不同的查询逻辑(在新版本中逐渐被弃用)。
-------------------------------------------------------------------------------------------------------------
01.bool:允许将多个查询条件组合在一起,通过 must、should、must_not 和 filter 条件控制查询逻辑。
a.介绍
bool 查询可以把任意多个简单查询组合在一起,
使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,
每个选项都可以出现 0 次到多次,它们的含义如下:
-----------------------------------------------------------------------------------------------------
must 文档必须匹配 must 选项下的查询条件,相当于逻辑运算的 AND,且参与文档相关度的评分。
should 文档可以匹配 should 选项下的查询条件也可以不匹配,相当于逻辑运算的 OR,且参与文档相关度的评分。
must_not 与 must 相反,匹配该选项下的查询条件的文档不会被返回;需要注意的是,must_not 语句不会影响评分,它的作用只是将不相关的文档排除。
filter 和 must 一样,匹配 filter 选项下的查询条件的文档才会被返回,但是 filter 不评分,只起到过滤功能,与 must_not 相反。
-----------------------------------------------------------------------------------------------------
bool query 可以将任意多个简单查询组装在一起,有四个关键字可供选择,四个关键字所描述的条件可以有一个或者多个。
must:文档必须匹配 must 选项下的查询条件。
should:文档可以匹配 should 下的查询条件,也可以不匹配。
must_not:文档必须不满足 must_not 选项下的查询条件。
filter:类似于 must,但是 filter 不评分,只是过滤数据。
b.假设要查询 title 中包含关键词 java,并且 price 不能高于 70,description 可以包含也可以不包含虚拟机的书籍,构造 bool 查询语句如下:
GET books/_search
{
"query": {
"bool": {
"filter": {
"term": {
"status": 1
}
},
"must_not": {
"range": {
"price": {
"gte": 70
}
}
},
"must": {
"match": {
"title": "java"
}
},
"should": [
{
"match": {
"description": "虚拟机"
}
}
],
"minimum_should_match": 1
}
}
}
c.例如查询 name 属性中必须包含 java,同时书价不在 [0,35] 区间内,info 属性可以包含 程序设计 也可以不包含程序设计:
GET books/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "java"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 0,
"lte": 35
}
}
}
],
"should": [
{
"match": {
"info": "程序设计"
}
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
这里还涉及到一个关键字,minmum_should_match 参数。
minmum_should_match 参数在 es 官网上称作最小匹配度。
在之前学习的 multi_match 或者这里的 should 查询中,都可以设置 minmum_should_match 参数。
d.假设我们要做一次查询,查询 name 中包含 语言程序设计 关键字的文档:
GET books/_search
{
"query": {
"match": {
"name": "语言程序设计"
}
}
}
分词后的 term 会构造成一个 should 的 bool query,每一个 term 都会变成一个 term query 的子句。
-----------------------------------------------------------------------------------------------------
换句话说,上面的查询和下面的查询等价:
GET books/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": {
"value": "语言"
}
}
},
{
"term": {
"name": {
"value": "程序设计"
}
}
},
{
"term": {
"name": {
"value": "程序"
}
}
},
{
"term": {
"name": {
"value": "设计"
}
}
}
]
}
}
}
在这两个查询语句中,都是文档只需要包含词项中的任意一项即可,
文档就回被返回,在 match 查询中,可以通过 operator 参数设置文档必须匹配所有词项。
e.如果想匹配一部分词项,就涉及到一个参数,就是 minmum_should_match,即最小匹配度。即至少匹配多少个词。
GET books/_search
{
"query": {
"match": {
"name": {
"query": "语言程序设计",
"operator": "and"
}
}
}
}
GET books/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": {
"value": "语言"
}
}
},
{
"term": {
"name": {
"value": "程序设计"
}
}
},
{
"term": {
"name": {
"value": "程序"
}
}
},
{
"term": {
"name": {
"value": "设计"
}
}
}
],
"minimum_should_match": "50%"
}
},
"from": 0,
"size": 70
}
-----------------------------------------------------------------------------------------------------
50% 表示词项个数的 50%。
-----------------------------------------------------------------------------------------------------
如下两个查询等价(参数 4 是因为查询关键字分词后有 4 项):
GET books/_search
{
"query": {
"match": {
"name": {
"query": "语言程序设计",
"minimum_should_match": 4
}
}
}
}
GET books/_search
{
"query": {
"match": {
"name": {
"query": "语言程序设计",
"operator": "and"
}
}
}
}
-------------------------------------------------------------------------------------------------------------
02.boosting:用于执行加权查询,提升匹配特定条件的文档得分,同时降低其他条件下文档的得分。
a.介绍
boosting 查询用于需要对两个查询的评分进行调整的场景,
boosting 查询会把两个查询封装在一起并降低其中一个查询的评分。
-----------------------------------------------------------------------------------------------------
boosting 查询包括 positive、negative 和 negative_boost 三个部分,
positive 中的查询评分保持不变,
negative 中的查询会降低文档评分,
negative_boost 指明 negative 中降低的权值。
b.如果我们想对 2015 年之前出版的书降低评分,可以构造一个 boosting 查询,查询语句如下:
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "python"
}
},
"negative": {
"range": {
"publish_time": {
"lte": "2015-01-01"
}
}
},
"negative_boost": 0.2
}
}
}
-----------------------------------------------------------------------------------------------------
boosting 查询中指定了抑制因子为 0.2,publish_time 的值在 2015-01-01 之后的文档得分不变,
publish_time 的值在 2015-01-01 之前的文档得分为原得分的 0.2 倍。
c.介绍
boosting query 中包含三部分:
positive:得分不变
negative:降低得分
negative_boost:降低的权重
d.示例
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"name": "java"
}
},
"negative": {
"match": {
"name": "2008"
}
},
"negative_boost": 0.5
}
}
}
可以看到,id 为 86 的文档满足条件,因此它的最终得分在旧的分数上*0.5。
03.constant_score:忽略查询的相关性评分,返回固定评分的结果,通常用于过滤查询。
a.介绍
constantscore query 包装一个 filter query,并返回匹配过滤器查询条件的文档,
且它们的相关性评分都等于 _boost 参数值(可以理解为原有的基于 tf-idf 或 bm25 的相关分固定为 1.0,
所以最终评分为 1.0 * boost,即等于 boost 参数值)。
b.下面的查询语句会返回 title 字段中含有关键词 elasticsearch 的文档,所有文档的评分都是 1.8:
GET books/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"title": "elasticsearch"
}
},
"boost": 1.8
}
}
}
04.dis_max:在多个查询之间选择得分最高的文档,适合组合多个子查询并返回最相关的结果。
a.介绍
dis_max query 与 bool query 有一定联系也有一定区别,dis_max query 支持多并发查询,
可返回与任意查询条件子句匹配的任何文档类型。与 bool 查询可以将所有匹配查询的分数相结合使用的方式不同,
dis_max 查询只使用最佳匹配查询条件的分数
b.示例
GET books/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"boost": 1.2,
"queries": [{
"term": {
"age": 34
}
},
{
"term": {
"age": 35
}
}
]
}
}
}
c.示例
假设现在有两本书:
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST blog/_doc
{
"title":"如何通过Java代码调用ElasticSearch",
"content":"松哥力荐,这是一篇很好的解决方案"
}
POST blog/_doc
{
"title":"初识 MongoDB",
"content":"简单介绍一下 MongoDB,以及如何通过 Java 调用 MongoDB,MongoDB 是一个不错 NoSQL 解决方案"
}
-----------------------------------------------------------------------------------------------------
现在假设搜索 Java解决方案 关键字,但是不确定关键字是在 title 还是在 content,所以两者都搜索:
GET blog/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java解决方案"
}
},
{
"match": {
"content": "java解决方案"
}
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
肉眼观察,感觉第二个和查询关键字相似度更高,但是实际查询结果并非这样。
要理解这个原因,我们需要来看下 should query 中的评分策略:
首先会执行 should 中的两个查询
对两个查询结果的评分求和
对求和结果乘以匹配语句总数
在对第三步的结果除以所有语句总数
-----------------------------------------------------------------------------------------------------
反映到具体的查询中:
前者
title 中 包含 java,假设评分是 1.1
content 中包含解决方案,假设评分是 1.2
有得分的 query 数量,这里是 2
总的 query 数量也是 2
最终结果:(1.1+1.2)*2/2=2.3
后者
title 中 不包含查询关键字,没有得分
content 中包含解决方案和 java,假设评分是 2
有得分的 query 数量,这里是 1
总的 query 数量也是 2
最终结果:2*1/2=1
在这种查询中,title 和 content 相当于是相互竞争的关系,所以我们需要找到一个最佳匹配字段。
-----------------------------------------------------------------------------------------------------
为了解决这一问题,就需要用到 dis_max query(disjunction max query,分离最大化查询):
匹配的文档依然返回,但是只将最佳匹配的评分作为查询的评分。
GET blog/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "java解决方案"
}
},
{
"match": {
"content": "java解决方案"
}
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
在 dis_max query 中,还有一个参数 tie_breaker(取值在0~1),在 dis_max query 中,
是完全不考虑其他 query 的分数,只是将最佳匹配的字段的评分返回。但是,有的时候,
我们又不得不考虑一下其他 query 的分数,此时,可以通过 tie_breaker 来优化 dis_max query。
tie_breaker 会将其他 query 的分数,乘以 tie_breaker,然后和分数最高的 query 进行一个综合计算。
05.function_score:允许通过定义评分函数来调整文档的相关性得分,用于复杂的得分计算。
a.介绍
function_score query 可以修改查询的文档得分,这个查询在有些情况下非常有用,
比如通过评分函数计算文档得分代价较高,可以改用过滤器加自定义评分函数的方式来取代传统的评分方式。
使用 function_score query,用户需要定义一个查询和一至多个评分函数,评分函数会对查询到的每个文档分别计算得分。
b.示例
下面这条查询语句会返回 books 索引中的所有文档,文档的最大得分为 5,每个文档的得分随机生成,权重的计算模式为相乘模式。
GET books/_search
{
"query": {
"function_score": {
"query": {
"match all": {}
},
"boost": "5",
"random_score": {},
"boost_mode": "multiply"
}
}
}
-----------------------------------------------------------------------------------------------------
使用脚本自定义评分公式,这里把 price 值的十分之一开方作为每个文档的得分,查询语句如下:
GET books/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"script_score": {
"inline": "Math.sqrt(doc['price'].value/10)"
}
}
}
}
c.场景
场景:例如想要搜索附近的肯德基,搜索的关键字是肯德基,但是我希望能够将评分较高的肯德基优先展示出来。
但是默认的评分策略是没有办法考虑到餐厅评分的,他只是考虑相关性,这个时候可以通过 function_score query 来实现。
d.操作
准备两条测试数据:
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"votes":{
"type": "integer"
}
}
}
}
PUT blog/_doc/1
{
"title":"Java集合详解",
"votes":100
}
PUT blog/_doc/2
{
"title":"Java多线程详解,Java锁详解",
"votes":10
}
-----------------------------------------------------------------------------------------------------
现在搜索标题中包含 java 关键字的文档:
GET blog/_search
{
"query": {
"match": {
"title": "java"
}
}
}
默认情况下,id 为 2 的记录得分较高,因为他的 title 中包含两个 java。
如果我们在查询中,希望能够充分考虑 votes 字段,将 votes 较高的文档优先展示,就可以通过 function_score 来实现。
具体的思路,就是在旧的得分基础上,根据 votes 的数值进行综合运算,重新得出一个新的评分。
e.具体有几种不同的计算方式:
weight
random_score
script_score
field_value_factor
f.weight
weight 可以对评分设置权重,就是在旧的评分基础上乘以 weight,他其实无法解决我们上面所说的问题。具体用法如下:
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"weight": 10
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
可以看到,此时的评分,在之前的评分基础上*10
g.random_score
random_score 会根据 uid 字段进行 hash 运算,生成分数,使用 random_score 时可以配置一个种子,
如果不配置,默认使用当前时间。
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"random_score": {}
}
]
}
}
}
h.script_score
自定义评分脚本。假设每个文档的最终得分是旧的分数加上votes。查询方式如下:
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "_score + doc['votes'].value"
}
}
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
现在,最终得分是 (oldScore+votes)*oldScore。
如果不想乘以 oldScore,查询方式如下:
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "_score + doc['votes'].value"
}
}
}
],
"boost_mode": "replace"
}
}
}
-----------------------------------------------------------------------------------------------------
通过 boost_mode 参数,可以设置最终的计算方式。该参数还有其他取值:
multiply:分数相乘
sum:分数相加
avg:求平均数
max:最大分
min:最小分
replace:不进行二次计算
i.field_value_factor
这个的功能类似于 script_score,但是不用自己写脚本。
假设每个文档的最终得分是旧的分数乘以votes。查询方式如下
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes"
}
}
]
}
}
}
-----------------------------------------------------------------------------------------------------
默认的得分就是oldScore*votes。
还可以利用 es 内置的函数进行一些更复杂的运算:
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes",
"modifier": "sqrt"
}
}
],
"boost_mode": "replace"
}
}
}
此时,最终的得分是(sqrt(votes))。
-----------------------------------------------------------------------------------------------------
另外还有个参数 factor ,影响因子。字段值先乘以影响因子,然后再进行计算。以 sqrt 为例,计算方式为 sqrt(factor*votes):
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes",
"modifier": "sqrt",
"factor": 10
}
}
],
"boost_mode": "replace"
}
}
}
-----------------------------------------------------------------------------------------------------
还有一个参数 max_boost,控制计算结果的范围:
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes"
}
}
],
"boost_mode": "sum",
"max_boost": 100
}
}
}
max_boost 参数表示 functions 模块中,最终的计算结果上限。如果超过上限,就按照上线计算。
06.indices:根据索引名称来执行不同的查询,当索引符合特定条件时,应用不同的查询逻辑(在新版本中逐渐被弃用)。
a.介绍
indices query 适用于需要在多个索引之间进行查询的场景,
它允许指定一个索引名字列表和内部查询。indices query 中有 query 和 no_match_query 两部分,
query 中用于搜索指定索引列表中的文档,no_match_query 中的查询条件用于搜索指定索引列表之外的文档。
b.示例
下面的查询语句实现了搜索索引 books、books2 中 title 字段包含关键字 javascript,
其他索引中 title 字段包含 basketball 的文档,查询语句如下:
GET books/_search
{
"query": {
"indices": {
"indices": ["books", "books2"],
"query": {
"match": {
"title": "javascript"
}
},
"no_match_query": {
"term": {
"title": "basketball"
}
}
}
}
}
3.5 嵌套查询:nested
00.总结
a.介绍
在 Elasticsearch 这样的分布式系统中执行全 SQL 风格的连接查询代价昂贵,是不可行的。
b.汇总
Elasticsearch 提供了以下两种形式的 join:
nested(嵌套查询):文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来。
has_child(有子查询):父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档
has_parent(有父查询):父子关系可以存在单个的索引的两个类型的文档之间。has_parent 则返回其父文档能满足特定查询的子文档
c.整体上来说
普通子对象实现一对多,会损失子文档的边界,子对象之间的属性关系丢失。
nested 可以解决第 1 点的问题,但是 nested 有两个缺点:更新主文档的时候要全部更新,不支持子文档属于多个主文档。
父子文档解决 1、2 点的问题,但是它主要适用于写多读少的场景。
-------------------------------------------------------------------------------------------------------------
01.nested(嵌套查询):文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来。
a.介绍
文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来(用嵌套查询)。
b.示例
PUT /my_index
{
"mappings": {
"type1": {
"properties": {
"obj1": {
"type": "nested"
}
}
}
}
}
02.has_child(有子查询):父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档
a.介绍
文档的父子关系创建索引时在映射中声明,这里以员工(employee)和工作城市(branch)为例,
它们属于不同的类型,相当于数据库中的两张表,如果想把员工和他们工作的城市关联起来,
需要告诉 Elasticsearch 文档之间的父子关系,这里 employee 是 child type,branch 是 parent type,
b.在映射中声明,执行命令:
PUT /company
{
"mappings": {
"branch": {},
"employee": {
"parent": { "type": "branch" }
}
}
}
c.使用 bulk api 索引 branch 类型下的文档,命令如下:
POST company/branch/_bulk
{ "index": { "_id": "london" }}
{ "name": "London Westminster","city": "London","country": "UK" }
{ "index": { "_id": "liverpool" }}
{ "name": "Liverpool Central","city": "Liverpool","country": "UK" }
{ "index": { "_id": "paris" }}
{ "name": "Champs Elysees","city": "Paris","country": "France" }
-----------------------------------------------------------------------------------------------------
添加员工数据:
POST company/employee/_bulk
{ "index": { "_id": 1,"parent":"london" }}
{ "name": "Alice Smith","dob": "1970-10-24","hobby": "hiking" }
{ "index": { "_id": 2,"parent":"london" }}
{ "name": "Mark Tomas","dob": "1982-05-16","hobby": "diving" }
{ "index": { "_id": 3,"parent":"liverpool" }}
{ "name": "Barry Smith","dob": "1979-04-01","hobby": "hiking" }
{ "index": { "_id": 4,"parent":"paris" }}
{ "name": "Adrien Grand","dob": "1987-05-11","hobby": "horses" }
-----------------------------------------------------------------------------------------------------
通过子文档查询父文档要使用 has_child 查询。
d.例如,搜索 1980 年以后出生的员工所在的分支机构,employee 中 1980 年以后出生的有 Mark Thomas 和 Adrien Grand,他们分别在 london 和 paris,执行以下查询命令进行验证:
GET company/branch/_search
{
"query": {
"has_child": {
"type": "employee",
"query": {
"range": { "dob": { "gte": "1980-01-01" } }
}
}
}
}
e.例如,搜索哪些机构中有名为 “Alice Smith” 的员工,因为使用 match 查询,会解析为 “Alice” 和 “Smith”,所以 Alice Smith 和 Barry Smith 所在的机构会被匹配,执行以下查询命令进行验证:
GET company/branch/_search
{
"query": {
"has_child": {
"type": "employee",
"score_mode": "max",
"query": {
"match": { "name": "Alice Smith" }
}
}
}
}
-----------------------------------------------------------------------------------------------------
可以使用 min_children 指定子文档的最小个数。例如,搜索最少含有两个 employee 的机构,查询命令如下:
GET company/branch/_search?pretty
{
"query": {
"has_child": {
"type": "employee",
"min_children": 2,
"query": {
"match_all": {}
}
}
}
}
03.has_parent(有父查询):父子关系可以存在单个的索引的两个类型的文档之间。has_parent 则返回其父文档能满足特定查询的子文档
a.介绍
通过父文档查询子文档使用 has_parent 查询。比如,搜索哪些 employee 工作在 UK,查询命令如下:
b.示例
GET company/employee/_search
{
"query": {
"has_parent": {
"parent_type": "branch",
"query": {
"match": { "country": "UK }
}
}
}
}
-------------------------------------------------------------------------------------------------------------
00.嵌套文档
a.示例
假设:有一个电影文档,每个电影都有演员信息:
PUT movies
{
"mappings": {
"properties": {
"actors":{
"type": "nested"
}
}
}
}
-----------------------------------------------------------------------------------------------------
PUT movies/_doc/1
{
"name":"霸王别姬",
"actors":[
{
"name":"张国荣",
"gender":"男"
},
{
"name":"巩俐",
"gender":"女"
}
]
}
-----------------------------------------------------------------------------------------------------
注意 actors 类型要是 nested
b.缺点
查看文档数量:GET _cat/indices?v
-----------------------------------------------------------------------------------------------------
查看结果如下:
这是因为 nested 文档在 es 内部其实也是独立的 lucene 文档,只是在我们查询的时候,es 内部帮我们做了 join 处理,
所以最终看起来就像一个独立文档一样。因此这种方案性能并不是特别好。
01.嵌套查询
a.代码
GET movies/_search
{
"query": {
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.name": "张国荣"
}
},
{
"match": {
"actors.gender": "男"
}
}
]
}
}
}
}
}
b.结果
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.61532,
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "1",
"_score" : 2.61532,
"_source" : {
"name" : "霸王别姬",
"actors" : [
{
"name" : "张国荣",
"gender" : "男"
},
{
"name" : "巩俐",
"gender" : "女"
}
]
}
}
]
}
}
02.父子文档
a.相比于嵌套文档,父子文档主要有如下优势:
更新父文档时,不会重新索引子文档
创建、修改或者删除子文档时,不会影响父文档或者其他的子文档。
子文档可以作为搜索结果独立返回。
b.数据准备
例如学生和班级的关系:
PUT stu_class
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"s_c":{
"type": "join",
"relations":{
"class":"student"
}
}
}
}
}
s_c 表示父子文档关系的名字,可以自定义。
join 表示这是一个父子文档。relations 里边,class 这个位置是 parent,student 这个位置是 child。
-----------------------------------------------------------------------------------------------------
接下来,插入两个父文档:
PUT stu_class/_doc/1
{
"name":"一班",
"s_c":{
"name":"class"
}
}
PUT stu_class/_doc/2
{
"name":"二班",
"s_c":{
"name":"class"
}
}
-----------------------------------------------------------------------------------------------------
再来添加三个子文档:
PUT stu_class/_doc/3?routing=1
{
"name":"zhangsan",
"s_c":{
"name":"student",
"parent":1
}
}
PUT stu_class/_doc/4?routing=1
{
"name":"lisi",
"s_c":{
"name":"student",
"parent":1
}
}
PUT stu_class/_doc/5?routing=2
{
"name":"wangwu",
"s_c":{
"name":"student",
"parent":2
}
}
-----------------------------------------------------------------------------------------------------
首先大家可以看到,子文档都是独立的文档。特别需要注意的地方是,子文档需要和父文档在同一个分片上,
所以 routing 关键字的值为父文档的 id。另外,name 属性表明这是一个子文档。
-----------------------------------------------------------------------------------------------------
父子文档需要注意的地方:
1.每个索引只能定义一个 join filed
2.父子文档需要在同一个分片上(查询,修改需要routing)
3.可以向一个已经存在的 join filed 上新增关系
c.has_child
通过子文档查询父文档使用 has_child query
GET stu_class/_search
{
"query": {
"has_child": {
"type": "student",
"query": {
"match": {
"name": "wangwu"
}
}
}
}
}
查询 wangwu 所属的班级。
d.has_parent
通过父文档查询子文档:
GET stu_class/_search
{
"query": {
"has_parent": {
"parent_type": "class",
"query": {
"match": {
"name": "二班"
}
}
}
}
}
查询二班的学生。但是大家注意,这种查询没有评分。
-----------------------------------------------------------------------------------------------------
可以使用 parent id 查询子文档:
GET stu_class/_search
{
"query": {
"parent_id":{
"type":"student",
"id":1
}
}
}
通过 parent id 查询,默认情况下使用相关性计算分数。
3.6 位置查询:geo
00.总结
a.介绍
Elasticsearch 可以对地理位置点 geo_point 类型和地理位置形状 geo_shape 类型的数据进行搜索。
为了学习方便,这里准备一些城市的地理坐标作为测试数据,每一条文档都包含城市名称和地理坐标这两个字段,
这里的坐标点取的是各个城市中心的一个位置。
b.汇总
geo_distance:用于计算两个地理位置(经纬度坐标)之间的距离。此查询可以用于基于距离的过滤,帮助用户找到特定半径内的文档。
geoboundingbox:表示一个矩形区域,由西南和东北两个角的经纬度坐标定义。使用此查询可以快速找到位于该矩形范围内的文档。
geo_polygon:用于定义一个多边形区域,该区域由一系列经纬度坐标构成。此查询可以用于查找位于多边形内部的文档,适用于更复杂的地理区域。
geo_shape:支持多种形状(如点、线、面等)的地理查询。使用此查询可以匹配复杂的地理形状,适合于对地理数据有更高需求的应用场景。
-------------------------------------------------------------------------------------------------------------
00.数据准备
a.首先把下面的内容保存到 geo.json 文件中:
{"index":{ "_index":"geo","_type":"city","_id":"1" }}
{"name":"北京","location":"39.9088145109,116.3973999023"}
{"index":{ "_index":"geo","_type":"city","_id": "2" }}
{"name":"乌鲁木齐","location":"43.8266300000,87.6168800000"}
{"index":{ "_index":"geo","_type":"city","_id":"3" }}
{"name":"西安","location":"34.3412700000,108.9398400000"}
{"index":{ "_index":"geo","_type":"city","_id":"4" }}
{"name":"郑州","location":"34.7447157466,113.6587142944"}
{"index":{ "_index":"geo","_type":"city","_id":"5" }}
{"name":"杭州","location":"30.2294080260,120.1492309570"}
{"index":{ "_index":"geo","_type":"city","_id":"6" }}
{"name":"济南","location":"36.6518400000,117.1200900000"}
b.创建一个索引并设置映射
PUT geo
{
"mappings": {
"city": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}
}
c.然后执行批量导入命令
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @geo.json
01.geo_distance:用于计算两个地理位置(经纬度坐标)之间的距离。此查询可以用于基于距离的过滤,帮助用户找到特定半径内的文档。
a.介绍
geo_distance query 可以查找在一个中心点指定范围内的地理点文档。
b.示例
例如,查找距离天津 200km 以内的城市,搜索结果中会返回北京
GET geo/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"location": {
"lat": 39.0851000000,
"lon": 117.1993700000
}
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
按各城市离北京的距离排序:
GET geo/_search
{
"query": {
"match_all": {}
},
"sort": [{
"_geo_distance": {
"location": "39.9088145109,116.3973999023",
"unit": "km",
"order": "asc",
"distance_type": "plane"
}
}]
}
其中 location 对应的经纬度字段;unit 为 km 表示将距离以 km 为单位写入到每个返回结果的 sort 键中;distance_type 为 plane 表示使用快速但精度略差的 plane 计算方式。
02.geoboundingbox:表示一个矩形区域,由西南和东北两个角的经纬度坐标定义。使用此查询可以快速找到位于该矩形范围内的文档。
a.介绍
geo_bounding_box query 用于查找落入指定的矩形内的地理坐标。查询中由两个点确定一个矩形,然后在矩形区域内查询匹配的文档。
b.示例
GET geo/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 38.4864400000,
"lon": 106.2324800000
},
"bottom_right": {
"lat": 28.6820200000,
"lon": 115.8579400000
}
}
}
}
}
}
}
03.geo_polygon:用于定义一个多边形区域,该区域由一系列经纬度坐标构成。此查询可以用于查找位于多边形内部的文档,适用于更复杂的地理区域。
a.介绍
geo_polygon query 用于查找在指定多边形内的地理点。例如,呼和浩特、重庆、上海三地组成一个三角形,查询位置在该三角形区域内的城市,
b.示例
GET geo/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
},
"filter": {
"geo_polygon": {
"location": {
"points": [{
"lat": 40.8414900000,
"lon": 111.7519900000
}, {
"lat": 29.5647100000,
"lon": 106.5507300000
}, {
"lat": 31.2303700000,
"lon": 121.4737000000
}]
}
}
}
}
}
04.geo_shape:支持多种形状(如点、线、面等)的地理查询。使用此查询可以匹配复杂的地理形状,适合于对地理数据有更高需求的应用场景。
a.介绍
geo_shape query 用于查询 geo_shape 类型的地理数据,地理形状之间的关系有相交、包含、不相交三种。创建一个新的索引用于测试,其中 location 字段的类型设为 geo_shape 类型。
b.示例
PUT geoshape
{
"mappings": {
"city": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_shape"
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
关于经纬度的顺序这里做一个说明,geo_point 类型的字段纬度在前经度在后,但是对于 geo_shape 类型中的点,是经度在前纬度在后,这一点需要特别注意。
把西安和郑州连成的线写入索引:
POST geoshape/city/1
{
"name": "西安-郑州",
"location": {
"type": "linestring",
"coordinates": [
[108.9398400000, 34.3412700000],
[113.6587142944, 34.7447157466]
]
}
}
-----------------------------------------------------------------------------------------------------
查询包含在由银川和南昌作为对角线上的点组成的矩形的地理形状,由于西安和郑州组成的直线落在该矩形区域内,因此可以被查询到。命令如下:
GET geoshape/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[106.23248, 38.48644],
[115.85794, 28.68202]
]
},
"relation": "within"
}
}
}
}
}
}
-------------------------------------------------------------------------------------------------------------
00.数据准备
a.创建一个索引
PUT geo
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"location":{
"type": "geo_point"
}
}
}
}
b.准备一个 geo.json 文件
{"index":{"_index":"geo","_id":1}}
{"name":"西安","location":"34.288991865037524,108.9404296875"}
{"index":{"_index":"geo","_id":2}}
{"name":"北京","location":"39.926588421909436,116.43310546875"}
{"index":{"_index":"geo","_id":3}}
{"name":"上海","location":"31.240985378021307,121.53076171875"}
{"index":{"_index":"geo","_id":4}}
{"name":"天津","location":"39.13006024213511,117.20214843749999"}
{"index":{"_index":"geo","_id":5}}
{"name":"杭州","location":"30.259067203213018,120.21240234375001"}
{"index":{"_index":"geo","_id":6}}
{"name":"武汉","location":"30.581179257386985,114.3017578125"}
{"index":{"_index":"geo","_id":7}}
{"name":"合肥","location":"31.840232667909365,117.20214843749999"}
{"index":{"_index":"geo","_id":8}}
{"name":"重庆","location":"29.592565403314087,106.5673828125"}
c.最后,执行如下命令,批量导入 geo.json 数据
curl -XPOST "http://localhost:9200/geo/_bulk?pretty" -H "content-type:application/json" --data-binary @geo.json
01.geo_distance:给出一个中心点,查询距离该中心点指定范围内的文档
a.示例
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "600km",
"location": {
"lat": 34.288991865037524,
"lon": 108.9404296875
}
}
}
]
}
}
}
b.说明
以(34.288991865037524,108.9404296875) 为圆心,以 600KM 为半径,这个范围内的数据。
02.geo_bounding_box:在某一个矩形内的点,通过两个点锁定一个矩形
a.示例
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 32.0639555946604,
"lon": 118.78967285156249
},
"bottom_right": {
"lat": 29.98824461550903,
"lon": 122.20642089843749
}
}
}
}
]
}
}
}
b.说明
以南京经纬度作为矩形的左上角,以舟山经纬度作为矩形的右下角,构造出来的矩形中,包含上海和杭州两个城市。
03.geo_polygon:在某一个多边形范围内的查询。
a.示例
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_polygon": {
"location": {
"points": [
{
"lat": 31.793755581217674,
"lon": 113.8238525390625
},
{
"lat": 30.007273923504556,
"lon":114.224853515625
},
{
"lat": 30.007273923504556,
"lon":114.8345947265625
}
]
}
}
}
]
}
}
}
b.说明
给定多个点,由多个点组成的多边形中的数据。
04.geo_shape:geo_shape 用来查询图形,针对 geo_shape,两个图形之间的关系有:相交、包含、不相交。
a.新建索引
PUT geo_shape
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"location":{
"type": "geo_shape"
}
}
}
}
b.然后添加一条线
PUT geo_shape/_doc/1
{
"name":"西安-郑州",
"location":{
"type":"linestring",
"coordinates":[
[108.9404296875,34.279914398549934],
[113.66455078125,34.768691457552706]
]
}
}
c.接下来查询某一个图形中是否包含该线
GET geo_shape/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
106.5234375,
36.80928470205937
],
[
115.33447265625,
32.24997445586331
]
]
},
"relation": "within"
}
}
}
]
}
}
}
d.relation 属性表示两个图形的关系
within 包含
intersects 相交
disjoint 不相交
3.7 特殊查询:script
00.总结
a.介绍
略
b.汇总
more_like_this:用于查找与给定文档相似的文档。该查询会分析输入文档的内容,提取关键词,并找到与这些关键词匹配的其他文档,从而提供相似性搜索的功能。
script:允许用户使用脚本来自定义查询逻辑。通过脚本,用户可以在查询、过滤或评分阶段执行自定义操作,从而实现更复杂的查询条件和行为。
percolate:用于在一组查询中查找与给定文档匹配的查询。该查询类型适用于监控、通知和事件检测等场景,用户可以预先定义多个查询,然后通过该机制检查新文档是否与任何预定义查询相匹配。
-------------------------------------------------------------------------------------------------------------
01.more_like_this
a.介绍
more_like_this query 可以查询和提供文本类似的文档,通常用于近似文本的推荐等场景
b.示例
GET books/_search
{
"query": {
"more_like_ this": {
"fields": ["title", "description"],
"like": "java virtual machine",
"min_term_freq": 1,
"max_query_terms": 12
}
}
}
-----------------------------------------------------------------------------------------------------
可选的参数及取值说明如下:
fields 要匹配的字段,默认是 _all 字段。
like 要匹配的文本。
min_term_freq 文档中词项的最低频率,默认是 2,低于此频率的文档会被忽略。
max_query_terms query 中能包含的最大词项数目,默认为 25。
min_doc_freq 最小的文档频率,默认为 5。
max_doc_freq 最大文档频率。
min_word length 单词的最小长度。
max_word length 单词的最大长度。
stop_words 停用词列表。
analyzer 分词器。
minimum_should_match 文档应匹配的最小词项数,默认为 query 分词后词项数的 30%。
boost terms 词项的权重。
include 是否把输入文档作为结果返回。
boost 整个 query 的权重,默认为 1.0。
02.script query
a.介绍
Elasticsearch 支持使用脚本进行查询。
b.例如,查询价格大于 180 的文档,命令如下:
GET books/_search
{
"query": {
"script": {
"script": {
"inline": "doc['price'].value > 180",
"lang": "painless"
}
}
}
}
03.percolate query
a.介绍
一般情况下,我们是先把文档写入到 Elasticsearch 中,通过查询语句对文档进行搜索。
percolate query 则是反其道而行之的做法,它会先注册查询条件,根据文档来查询 query。
例如,在 my-index 索引中有一个 laptop 类型,文档有 price 和 name 两个字段,
在映射中声明一个 percolator 类型的 query,命令如下:
b.示例
PUT my-index
{
"mappings": {
"laptop": {
"properties": {
"price": { "type": "long" },
"name": { "type": "text" }
},
"queries": {
"properties": {
"query": { "type": "percolator" }
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
注册一个 bool query,bool query 中包含一个 range query,要求 price 字段的取值小于等于 10000,
并且 name 字段中含有关键词 macbook:
PUT /my-index/queries/1?refresh
{
"query": {
"bool": {
"must": [{
"range": { "price": { "lte": 10000 } }
}, {
"match": { "name": "macbook" }
}]
}
}
}
-----------------------------------------------------------------------------------------------------
通过文档查询 query:
GET /my-index/_search
{
"query": {
"percolate": {
"field": "query",
"document_type": "laptop",
"document": {
"price": 9999,
"name": "macbook pro on sale"
}
}
}
}
文档符合 query 中的条件,返回结果中可以查到上文中注册的 bool query。
percolate query 的这种特性适用于数据分类、数据路由、事件监控和预警等场景。
-------------------------------------------------------------------------------------------------------------
01.more_like_this
a.介绍
more_like_this query 可以实现基于内容的推荐,给定一篇文章,可以查询出和该文章相似的内容。
b.示例
GET books/_search
{
"query": {
"more_like_this": {
"fields": [
"info"
],
"like": "大学战略",
"min_term_freq": 1,
"max_query_terms": 12
}
}
}
-----------------------------------------------------------------------------------------------------
fields:要匹配的字段,可以有多个
like:要匹配的文本
min_term_freq:词项的最低频率,默认是 2。特别注意,这个是指词项在要匹配的文本中的频率,而不是 es 文档中的频率
max_query_terms:query 中包含的最大词项数目
min_doc_freq:最小的文档频率,搜索的词,至少在多少个文档中出现,少于指定数目,该词会被忽略
max_doc_freq:最大文档频率
analyzer:分词器,默认使用字段的分词器
stop_words:停用词列表
minmum_should_match
02.script query
a.介绍
脚本查询,例如查询所有价格大于 200 的图书:
b.示例
GET books/_search
{
"query": {
"bool": {
"filter": [
{
"script": {
"script": {
"lang": "painless",
"source": "if(doc['price'].size()!=0){doc['price'].value > 200}"
}
}
}
]
}
}
}
03.percolate query
a.percolate query 译作渗透查询或者反向查询。
正常操作:根据查询语句找到对应的文档 query->document
percolate query:根据文档,返回与之匹配的查询语句,document->query
b.应用场景
价格监控
库存报警
股票警告
...
例如阈值告警,假设指定字段值大于阈值,报警提示。
c.示例
percolate mapping 定义:
PUT log
{
"mappings": {
"properties": {
"threshold":{
"type": "long"
},
"count":{
"type": "long"
},
"query":{
"type":"percolator"
}
}
}
}
percolator 类型相当于 keyword、long 以及 integer 等。
-----------------------------------------------------------------------------------------------------
插入文档:
PUT log/_doc/1
{
"threshold":10,
"query":{
"bool":{
"must":{
"range":{
"count":{
"gt":10
}
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
最后查询:
GET log/_search
{
"query": {
"percolate": {
"field": "query",
"documents": [
{
"count":3
},
{
"count":6
},
{
"count":90
},
{
"count":12
},
{
"count":15
}
]
}
}
}
查询结果中会列出不满足条件的文档。
查询结果中的 _percolator_document_slot 字段表示文档的 position,从 0 开始计。
4 ElasticSearch查询2
4.1 汇总
00.使用
a.结果过滤:select a1, a2
GET /test1/_search
{
"query": {
"match_all": {}
},
"_source": [
"name",
"age"
]
}
b.范围查询:gt, lt
range 过滤允许我们按照指定范围查找一批数据,范围操作符包含:
gt:大于,相当于关系型数据库中的 >
gte:大于等于,相当于关系型数据库中的 >=
lt:小于,相当于关系型数据库中的 <
lte:小于等于,相当于关系型数据库中的 <=
c.布尔查询:must, filter
must:多个查询条件必须完全匹配,相当于关系型数据库中的 and。
should:至少有一个查询条件匹配,相当于关系型数据库中的 or。
must_not:多个查询条件的相反匹配,相当于关系型数据库中的 not。
filter:过滤满足条件的数据。
range:条件筛选范围。
gt:大于,相当于关系型数据库中的 >。
gte:大于等于,相当于关系型数据库中的 >=。
lt:小于,相当于关系型数据库中的 <。
lte:小于等于,相当于关系型数据库中的 <=。
d.限制查询:limit
POST /test2/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "张三 OR 七七"
}
},
"size": 100
}
e.排序查询:order desc
GET /test1/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
f.分页查询:from, size
GET /test1/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
g.高亮查询:highlighter
自定义高亮片段
多字段高亮
h.聚合查询:group by, sum
a.指标聚合
指标聚合:指标聚合对一个数据集求最大、最小、和、平均值等
单值分析,只输出一个分析结果——avg:求平均、max:最大值、min:最小值、sum:求和、cardinality:值去重计数。
多值分析,输出多个分析结果
stats:统计了count max min avg sum5个值
extended_stats:extended_stats比stats多很多更加高级的统计结果:如平方和、方差、标准差、平均值加/减两个标准差的区间等
percentile:占比百分位对应的值统计,默认返回【1,5,25,50,75,95,99】分位上的值
-------------------------------------------------------------------------------------------------
Max (最大值):计算指定字段的最大值,通常用于获取某个字段的最高值。
Min (最小值):计算指定字段的最小值,用于获取某个字段的最低值。
Avg (平均值):计算指定字段的平均值,通过汇总所有字段值并计算它们的平均值来提供数据的整体概况。
Sum (总和):计算指定字段的所有值的总和,常用于统计数据的累计值或总额。
Value Count (值计数):统计某个字段出现的次数,类似于计数,通常用于获取文档中非空字段的个数。
Cardinality (基数):计算某个字段中不同值的个数,用于获取该字段中的唯一值数量,常用于去重统计。
-------------------------------------------------------------------------------------------------
Stats (统计):提供一系列基础统计信息,包括最大值、最小值、平均值、总和以及文档计数,汇总了常用的统计信息。
Extended Stats (扩展统计):在基础统计的基础上,增加了标准差和方差等高级统计信息,用于更详细的数据分析。
Percentiles (百分位数):计算某个字段的多个百分位数,帮助了解数据分布情况,比如数据集中95%的值在什么范围内。
Percentile Ranks (百分位排名):计算某个值在数据集中所处的百分比位置,通常用于判断一个具体值相对于数据集的表现情况。
b.分桶聚合
分桶聚合:除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。
-------------------------------------------------------------------------------------------------
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,
分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,
即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
-------------------------------------------------------------------------------------------------
| 种类 | 描述/场景
|----------------------------------------------|----------------------------------------------------
| 词项聚合(Terms Aggregation) | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。
| 差异词项聚合(Significant Terms Aggregation) | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。
| 过滤器聚合(Filter Aggregation) | 指定过滤器匹配的所有文档到单个桶(bucket),通常这将用于将当前聚合上下文缩小到一组特定的文档。
| 多过滤器聚合(Filters Aggregation) | 指定多个过滤器匹配所有文档到多个桶(bucket)。
| 范围聚合(Range Aggregation) | 范围聚合,用于反映数据的分布情况。
| 日期范围聚合(Date Range Aggregation) | 专门用于日期类型的范围聚合。
| IP 范围聚合(IP Range Aggregation) | 用于对 IP 类型数据范围聚合。
| 直方图聚合(Histogram Aggregation) | 可能是数值,或者日期型,和范围聚集类似。
| 时间直方图聚合(Date Histogram Aggregation) | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。
c.管道聚合
管道聚合相当于在之前聚合的基础上,再次聚合。
Avg Bucket Aggregation:计算聚合平均值
Max Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值
Min Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值
Sum Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值之和
Stats Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据
Extended Stats Bucket Aggregation
Percentiles Bucket Aggregation
d.矩阵聚合
矩阵聚合(Matrix Aggregations)用于在多个数值字段之间进行复杂的数学分析,
特别适用于需要计算多维数据的统计关系的场景,比如协方差或相关性分析。
4.2 结果过滤:select a1, a2
00.总结
a.介绍
我们在查询数据的时候,返回的结果中,所有字段都给我们返回了,
但是有时候我们并不需要那么多,所以可以对结果进行过滤处理。
b.代码
GET /test1/_search
{
"query": {
"match_all": {}
},
"_source": [
"name",
"age"
]
}
4.3 范围查询:gt, lt
00.总结
a.介绍
range 过滤允许我们按照指定范围查找一批数据,范围操作符包含:
gt:大于,相当于关系型数据库中的 >
gte:大于等于,相当于关系型数据库中的 >=
lt:小于,相当于关系型数据库中的 <
lte:小于等于,相当于关系型数据库中的 <=
b.查询年龄在20-30岁之间的用户信息
POST /test1/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
4.4 布尔查询:must, filter
00.总结
a.must
多个查询条件必须完全匹配,相当于关系型数据库中的 and。
b.should
至少有一个查询条件匹配,相当于关系型数据库中的 or。
c.must_not
多个查询条件的相反匹配,相当于关系型数据库中的 not。
d.filter:过滤满足条件的数据。
range:条件筛选范围。
gt:大于,相当于关系型数据库中的 >。
gte:大于等于,相当于关系型数据库中的 >=。
lt:小于,相当于关系型数据库中的 <。
lte:小于等于,相当于关系型数据库中的 <=。
01.must
a.介绍
多个查询条件必须完全匹配,相当于关系型数据库中的 and。如果有一个条件不满足则不返回数据。
b.示例:查询用户名称满足叫 李四 的用户信息
GET /test1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
}
]
}
}
}
c.示例:查询用户名称满足叫 李四 并且年龄为29 的用户信息
GET /test1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 29
}
}
]
}
}
}
02.should
a.介绍
至少有一个查询条件匹配,相当于关系型数据库中的 or。只要符合其中一个条件就返回
b.查询用户名称叫 李四 或者 年龄为27岁的用户信息
GET /test1/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 27
}
}
]
}
}
}
03.must_not
a.介绍
多个查询条件的相反匹配,相当于关系型数据库中的 not
b.查询名称不包含李四并且年龄不包含30岁的用户信息
GET /test1/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 30
}
}
]
}
}
}
04.filter
a.介绍
条件过滤查询,过滤满足条件的数据。
过滤条件的范围用range表示gt表示大于、lt表示小于、gte表示大于等于、lte表示小于等于
b.查询出用户年龄在20-30岁之间名称为 李四 的用户
GET /test1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
}
],
"filter": {
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
}
}
4.5 限制查询:limit
00.总结
a.介绍
size参数确实类似于SQL中的LIMIT操作。它用于限制搜索结果的数量。
b.示例
POST /test2/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "张三 OR 七七"
}
},
"size": 100
}
4.6 排序查询:order desc
00.总结
a.sort字段
需要分词的字段不可以直接排序,比如:text类型,
如果想要对这类字段进行排序,需要特别设置:对字段索引两次,一次索引分词(用于搜索)一次索引不分词(用于排序),
es默认生成的text类型字段就是通过这样的方法实现可排序的。
-----------------------------------------------------------------------------------------------------
GET /test1/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
-----------------------------------------------------------------------------------------------------
es 同时也支持多字段排序。
GET books/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
},
{
"_doc": {
"order": "desc"
}
}
],
"size": 20
}
b.默认是按照查询文档的相关度来排序的,即_score 字段
GET books/_search
{
"query": {
"term": {
"name": {
"value": "java"
}
}
}
}
-----------------------------------------------------------------------------------------------------
等价于:
GET books/_search
{
"query": {
"term": {
"name": {
"value": "java"
}
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
-----------------------------------------------------------------------------------------------------
match_all 查询只是返回所有文档,不评分,默认按照添加顺序返回,可以通过 _doc 字段对其进行排序
GET books/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_doc": {
"order": "desc"
}
}
],
"size": 20
}
4.7 分页查询:from, size
00.总结
a.介绍
Elasticsearchde 的分页查询和 SQL 使用 LIMIT 关键字返回只有一页的结果一样,
Elasticsearch 接受 from 和 size 参数:
-----------------------------------------------------------------------------------------------------
size: 结果数,默认10
from: 跳过开始的结果数,即从哪一行开始获取数据,默认0
b.示例:从第一页开始获取两条数据
GET /test1/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
c.示例:分页查询用户名为Jack的用户信息
GET /test1/_search
{
"query": {
"match_phrase_prefix": {
"name": "Jack"
}
},
"from": 0,
"size": 2
}
4.8 高亮查询:highlighter
00.总结
a.介绍
我们平时在使用百度的时候,输入关键字查询内容后,关键字一般都是高亮显示的。
所以ES作为一个专业的搜索框架肯定也提供了这样的功能。
b.高亮搜索
| 参数 | 说明
|-------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| boundary_chars | 包含每个边界字符的字符串。默认为,! ?\ \ n。
| boundary_max_scan | 扫描边界字符的距离。默认为 20。
| boundary_scanner | 指定如何分割突出显示的片段,支持 chars、sentence、word 三种方式。
| boundary_scanner_locale | 用来设置搜索和确定单词边界的本地化设置,此参数使用语言标记的形式(“en-US”, “fr-FR”, “ja-JP”)
| encoder | 表示代码段应该是 HTML 编码的:默认(无编码)还是 HTML (HTML-转义代码段文本,然后插入高亮标记)
| fields | 指定检索高亮显示的字段。可以使用通配符来指定字段。例如,可以指定 comment**来获取以 comment*开头的所有文本和关键字字段的高亮显示。
| force_source | 根据源高亮显示。默认值为 false。
| fragmenter | 指定文本应如何在突出显示片段中拆分:支持参数 simple 或者 span。
| fragment_offset | 控制要开始突出显示的空白。仅在使用 fvh highlighter 时有效。
| fragment_size | 字符中突出显示的片段的大小。默认为 100。
| highlight_query | 突出显示搜索查询之外的其他查询的匹配项。这在使用重打分查询时特别有用,因为默认情况下高亮显示不会考虑这些问题。
| matched_fields | 组合多个匹配结果以突出显示单个字段,对于使用不同方式分析同一字符串的多字段。所有的 matched_fields 必须将 term_vector 设置为 with_positions_offsets,但是只有将匹配项组合到的字段才会被加载,因此只有将 store 设置为 yes 才能使该字段受益。只适用于 fvh highlighter。
| no_match_size | 如果没有要突出显示的匹配片段,则希望从字段开头返回的文本量。默认为 0(不返回任何内容)。
| number_of_fragments | 返回的片段的最大数量。如果片段的数量设置为 0,则不会返回任何片段。相反,突出显示并返回整个字段内容。当需要突出显示短文本(如标题或地址),但不需要分段时,使用此配置非常方便。如果 number_of_fragments 为 0,则忽略 fragment_size。默认为 5。
| order | 设置为 score 时,按分数对突出显示的片段进行排序。默认情况下,片段将按照它们在字段中出现的顺序输出(order:none)。将此选项设置为 score 将首先输出最相关的片段。每个高亮应用自己的逻辑来计算相关性得分。
| phrase_limit | 控制文档中所考虑的匹配短语的数量。防止 fvh highlighter 分析太多的短语和消耗太多的内存。提高限制会增加查询时间并消耗更多内存。默认为 256。
| pre_tags | 与 post_tags 一起使用,定义用于突出显示文本的 HTML 标记。默认情况下,突出显示的文本被包装在和标记中。指定为字符串数组。
| post_tags | 与 pre_tags 一起使用,定义用于突出显示文本的 HTML 标记。默认情况下,突出显示的文本被包装在和标记中。指定为字符串数组。
| require_field_match | 默认情况下,只突出显示包含查询匹配的字段。将 require_field_match 设置为 false 以突出显示所有字段。默认值为 true。
| tags_schema | 设置为使用内置标记模式的样式。
| type | 使用的高亮模式,可选项为**unified、plain或fvh**。默认为 unified。
c.自定义高亮片段
如果我们想使用自定义标签,在高亮属性中给需要高亮的字段加上 pre_tags 和 post_tags 即可。
例如,搜索 title 字段中包含关键词 javascript 的书籍并使用自定义 HTML 标签高亮关键词,查询语句如下:
GET /books/_search
{
"query": {
"match": { "title": "javascript" }
},
"highlight": {
"fields": {
"title": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
d.多字段高亮
关于搜索高亮,还需要掌握如何设置多字段搜索高亮。
比如,搜索 title 字段的时候,我们期望 description 字段中的关键字也可以高亮,
这时候就需要把 require_field_match 属性的取值设置为 fasle。require_field_match 的默认值为 true,
只会高亮匹配的字段。多字段高亮的查询语句如下:
GET /books/_search
{
"query": {
"match": { "title": "javascript" }
},
"highlight": {
"require_field_match": false,
"fields": {
"title": {},
"description": {}
}
}
}
e.高亮性能分析
Elasticsearch 提供了三种高亮器,
分别是默认的 highlighter 高亮器、postings-highlighter 高亮器和 fast-vector-highlighter 高亮器。
-----------------------------------------------------------------------------------------------------
默认的 highlighter 是最基本的高亮器。
highlighter 高亮器实现高亮功能需要对 _source 中保存的原始文档进行二次分析,
其速度在三种高亮器里最慢,优点是不需要额外的存储空间。
-----------------------------------------------------------------------------------------------------
postings-highlighter 高亮器实现高亮功能不需要二次分析,
但是需要在字段的映射中设置 index_options 参数的取值为 offsets,
即保存关键词的偏移量,速度快于默认的 highlighter 高亮器。
例如,配置 comment 字段使用 postings-highlighter 高亮器,映射如下:
PUT /example
{
"mappings": {
"doc": {
"properties": {
"comment": {
"type": "text",
"index_options": "offsets"
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
fast-vector-highlighter 高亮器实现高亮功能速度最快,但是需要在字段的映射中设置 term_vector 参数的取值为
with_positions_offsets,即保存关键词的位置和偏移信息,占用的存储空间最大,是典型的空间换时间的做法。
例如,配置 comment 字段使用 fast-vector-highlighter 高亮器,映射如下:
PUT /example
{
"mappings": {
"doc": {
"properties": {
"comment": {
"type": "text",
"term_vector": "with_positions_offsets"
}
}
}
}
}
01.高亮查询1
a.ES的默认高亮显示
GET /test1/_search
{
"query": {
"match": {
"name": "李四"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
b.ES自定义高亮显示
在highlight中,pre_tags用来实现我们的自定义标签的前半部分,在这里,我们也可以为自定义的 标签添加属性和样式。
post_tags实现标签的后半部分,组成一个完整的标签。至于标签中的内容,则还是交给fields来完成
GET /test1/_search
{
"query": {
"match": {
"remark": "中国"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"remark": {}
}
}
}
-----------------------------------------------------------------------------------------------------
GET /test1/_search
{
"query": {
"match": {
"remark": "中国"
}
},
"highlight": {
"fields": {
"remark": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>"
}
}
}
}
02.高亮查询2
a.ES的默认高亮显示,默认会自动添加 em 标签
GET books/_search
{
"query": {
"match": {
"name": "大学"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
b.ES自定义高亮显示
GET books/_search
{
"query": {
"match": {
"name": "大学"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
-----------------------------------------------------------------------------------------------------
有的时候,虽然我们是在 name 字段中搜索的,但是我们希望 info 字段中,相关的关键字也能高亮:
GET books/_search
{
"query": {
"match": {
"name": "大学"
}
},
"highlight": {
"require_field_match": "false",
"fields": {
"name": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
},
"info": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
4.9 聚合查询:group by, sum
00.总结
a.介绍
Elasticsearch 是一个分布式的全文搜索引擎,索引和搜索是 Elasticsearch 的基本功能。、
事实上,Elasticsearch 的聚合(Aggregations)功能也十分强大,允许在数据上做复杂的分析统计。
b.汇总
指标聚合(metrics aggregations):指标聚合用于计算和返回基于字段的数值统计信息。常见的指标聚合包括最大值、最小值、平均值、总和以及统计等。这种聚合只关心字段的值,不会对数据进行分组或分类
分桶聚合(bucket aggregations):桶聚合用于将文档分组为“桶”或集合,每个桶可以包含多个文档。这种聚合会创建不同的分组(如基于字段值、时间段、范围等),从而能够在每个分组上进行进一步的操作。每个桶可以包含子聚合,因此可以进行更深入的层次化分析
管道聚合(pipeline aggregations):管道聚合用于处理其他聚合的结果。它不直接操作原始数据,而是基于已有聚合的输出进行进一步计算。常见的管道聚合包括对聚合结果进行计算(如求和、移动平均、差异等)
矩阵聚合(matrix aggregations):矩阵聚合用于多维数据的统计分析,它可以在多个数值字段之间计算复杂的数学操作。常见的矩阵聚合包括协方差、相关系数等。矩阵聚合通常用于机器学习或金融领域的高级分析
-----------------------------------------------------------------------------------------------------
管道聚合和矩阵聚合官方说明是在试验阶段,后期会完全更改或者移除,这里不再对管道聚合和矩阵聚合进行讲解。
c.指标聚合
指标聚合:指标聚合对一个数据集求最大、最小、和、平均值等
单值分析,只输出一个分析结果——avg:求平均、max:最大值、min:最小值、sum:求和、cardinality:值去重计数。
多值分析,输出多个分析结果
stats:统计了count max min avg sum5个值
extended_stats:extended_stats比stats多很多更加高级的统计结果:如平方和、方差、标准差、平均值加/减两个标准差的区间等
percentile:占比百分位对应的值统计,默认返回【1,5,25,50,75,95,99】分位上的值
-----------------------------------------------------------------------------------------------------
Max (最大值):计算指定字段的最大值,通常用于获取某个字段的最高值。
Min (最小值):计算指定字段的最小值,用于获取某个字段的最低值。
Avg (平均值):计算指定字段的平均值,通过汇总所有字段值并计算它们的平均值来提供数据的整体概况。
Sum (总和):计算指定字段的所有值的总和,常用于统计数据的累计值或总额。
Value Count (值计数):统计某个字段出现的次数,类似于计数,通常用于获取文档中非空字段的个数。
Cardinality (基数):计算某个字段中不同值的个数,用于获取该字段中的唯一值数量,常用于去重统计。
-----------------------------------------------------------------------------------------------------
Stats (统计):提供一系列基础统计信息,包括最大值、最小值、平均值、总和以及文档计数,汇总了常用的统计信息。
Extended Stats (扩展统计):在基础统计的基础上,增加了标准差和方差等高级统计信息,用于更详细的数据分析。
Percentiles (百分位数):计算某个字段的多个百分位数,帮助了解数据分布情况,比如数据集中95%的值在什么范围内。
Percentile Ranks (百分位排名):计算某个值在数据集中所处的百分比位置,通常用于判断一个具体值相对于数据集的表现情况。
d.分桶聚合
分桶聚合:除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。
-----------------------------------------------------------------------------------------------------
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,
分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,
即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
-----------------------------------------------------------------------------------------------------
| 种类 | 描述/场景
|----------------------------------------------|----------------------------------------------------
| 词项聚合(Terms Aggregation) | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。
| 差异词项聚合(Significant Terms Aggregation) | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。
| 过滤器聚合(Filter Aggregation) | 指定过滤器匹配的所有文档到单个桶(bucket),通常这将用于将当前聚合上下文缩小到一组特定的文档。
| 多过滤器聚合(Filters Aggregation) | 指定多个过滤器匹配所有文档到多个桶(bucket)。
| 范围聚合(Range Aggregation) | 范围聚合,用于反映数据的分布情况。
| 日期范围聚合(Date Range Aggregation) | 专门用于日期类型的范围聚合。
| IP 范围聚合(IP Range Aggregation) | 用于对 IP 类型数据范围聚合。
| 直方图聚合(Histogram Aggregation) | 可能是数值,或者日期型,和范围聚集类似。
| 时间直方图聚合(Date Histogram Aggregation) | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。
e.管道聚合
管道聚合相当于在之前聚合的基础上,再次聚合。
Avg Bucket Aggregation:计算聚合平均值
Max Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值
Min Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值
Sum Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值之和
Stats Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据
Extended Stats Bucket Aggregation
Percentiles Bucket Aggregation
f.矩阵聚合
矩阵聚合(Matrix Aggregations)用于在多个数值字段之间进行复杂的数学分析,
特别适用于需要计算多维数据的统计关系的场景,比如协方差或相关性分析。
00.聚合的具体结构
a.介绍
所有的聚合,无论它们是什么类型,都遵从以下的规则。
使用查询中同样的 JSON 请求来定义它们,而且你是使用键 aggregations 或者是 aggs 来进行标记。需要给每个聚合起一个名字,指定它的类型以及和该类型相关的选项。
它们运行在查询的结果之上。和查询不匹配的文档不会计算在内,除非你使用 global 聚集将不匹配的文档囊括其中。
可以进一步过滤查询的结果,而不影响聚集。
b.聚合的基本结构
"aggregations" : { <!-- 最外层的聚合键,也可以缩写为 aggs -->
"<aggregation_name>" : { <!-- 聚合的自定义名字 -->
"<aggregation_type>" : { <!-- 聚合的类型,指标相关的,如 max、min、avg、sum,桶相关的 terms、filter 等 -->
<aggregation_body> <!-- 聚合体:对哪些字段进行聚合,可以取字段的值,也可以是脚本计算的结果 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!-- 元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!-- 在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!-- 聚合的自定义名字 2 -->
}
-----------------------------------------------------------------------------------------------------
在最上层有一个 aggregations 的键,可以缩写为 aggs。
在下面一层,需要为聚合指定一个名字。可以在请求的返回中看到这个名字。在同一个请求中使用多个聚合时,这一点非常有用,它让你可以很容易地理解每组结果的含义。
最后,必须要指定聚合的类型。
-----------------------------------------------------------------------------------------------------
关于聚合分析的值来源,可以取字段的值,也可以是脚本计算的结果。
但是用脚本计算的结果时,需要注意脚本的性能和安全性;尽管多数聚集类型允许使用脚本,但是脚本使得聚集变得缓慢,因为脚本必须在每篇文档上运行。为了避免脚本的运行,可以在索引阶段进行计算。
此外,脚本也可以被人可能利用进行恶意代码攻击,尽量使用沙盒(sandbox)内的脚本语言。
c.示例:查询所有球员的平均年龄是多少,并对球员的平均薪水加 188(也可以理解为每名球员加 188 后的平均薪水)。
POST /player/_search?size=0
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
},
"avg_salary_188": {
"avg": {
"script": {
"source": "doc.salary.value + 188"
}
}
}
}
}
01.指标聚合
a.概念
指标聚合(又称度量聚合)主要从不同文档的分组中提取统计数据,或者,从来自其他聚合的文档桶来提取统计数据。
这些统计数据通常来自数值型字段,如最小或者平均价格。用户可以单独获取每项统计数据,或者也可以使用 stats 聚合来同时获取它们。更高级的统计数据,如平方和或者是标准差,可以通过 extended stats 聚合来获取。
b.Max
Max Aggregation 用于最大值统计。
-----------------------------------------------------------------------------------------------------
例如,统计 sales 索引中价格最高的是哪本书,并且计算出对应的价格的 2 倍值,查询语句如下:
GET /sales/_search?size=0
{
"aggs" : {
"max_price" : {
"max" : {
"field" : "price"
}
},
"max_price_2" : {
"max" : {
"field" : "price",
"script": {
"source": "_value * 2.0"
}
}
}
}
}
-----------------------------------------------------------------------------------------------------
指定的 field,在脚本中可以用 _value 取字段的值。
聚合结果如下:
{
...
"aggregations": {
"max_price": {
"value": 188.0
},
"max_price_2": {
"value": 376.0
}
}
}
c.Min
Min Aggregation 用于最小值统计。
-----------------------------------------------------------------------------------------------------
例如,统计 sales 索引中价格最低的是哪本书,查询语句如下:
GET /sales/_search?size=0
{
"aggs" : {
"min_price" : {
"min" : {
"field" : "price"
}
}
}
}
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"min_price": {
"value": 18.0
}
}
}
d.Avg
Avg Aggregation 用于计算平均值。
-----------------------------------------------------------------------------------------------------
例如,统计 exams 索引中考试的平均分数,如未存在分数,默认为 60 分,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"field" : "grade",
"missing": 60
}
}
}
}
-----------------------------------------------------------------------------------------------------
如果指定字段没有值,可以通过 missing 指定默认值;若未指定默认值,缺失该字段值的文档将被忽略(计算)。
聚合结果如下:
{
...
"aggregations": {
"avg_grade": {
"value": 78.0
}
}
}
-----------------------------------------------------------------------------------------------------
除了常规的平均值聚合计算外,elasticsearch 还提供了加权平均值的聚合计算,
e.Sum
Sum Aggregation 用于计算总和。
-------------------------------------------------------------------------------------------------2
例如,统计 sales 索引中 type 字段中匹配 hat 的价格总和,查询语句如下:
GET /exams/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : { "field" : "price" }
}
}
}
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"hat_prices": {
"value": 567.0
}
}
}
f.Value Count
Value Count Aggregation 可按字段统计文档数量。
-----------------------------------------------------------------------------------------------------
例如,统计 books 索引中包含 author 字段的文档数量,查询语句如下:
GET /books/_search?size=0
{
"aggs" : {
"doc_count" : {
"value_count" : { "field" : "author" }
}
}
}
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"doc_count": {
"value": 5
}
}
}
g.Cardinality
Cardinality Aggregation 用于基数统计,其作用是先执行类似 SQL 中的 distinct 操作,去掉集合中的重复项,然后统计去重后的集合长度。
-----------------------------------------------------------------------------------------------------
例如,在 books 索引中对 language 字段进行 cardinality 操作可以统计出编程语言的种类数,查询语句如下:
GET /books/_search?size=0
{
"aggs" : {
"all_lan" : {
"cardinality" : { "field" : "language" }
},
"title_cnt" : {
"cardinality" : { "field" : "title.keyword" }
}
}
}
-----------------------------------------------------------------------------------------------------
假设 title 字段为文本类型(text),去重时需要指定 keyword,表示把 title 作为整体去重,即不分词统计。
聚合结果如下:
{
...
"aggregations": {
"all_lan": {
"value": 8
},
"title_cnt": {
"value": 18
}
}
}
h.Stats
Stats Aggregation 用于基本统计,会一次返回 count、max、min、avg 和 sum 这 5 个指标。
-----------------------------------------------------------------------------------------------------
例如,在 exams 索引中对 grade 字段进行分数相关的基本统计,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : { "field" : "grade" }
}
}
}
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
i.Extended Stats
Extended Stats Aggregation 用于高级统计,和基本统计功能类似,但是会比基本统计多出以下几个统计结果,
sum_of_squares(平方和)、variance(方差)、std_deviation(标准差)、
std_deviation_bounds(平均值加/减两个标准差的区间)。
-----------------------------------------------------------------------------------------------------
在 exams 索引中对 grade 字段进行分数相关的高级统计,查询语句如下:
GET /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"extended_stats" : { "field" : "grade" }
}
}
}
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"std_deviation": 25.0,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0
}
}
}
}
j.Percentiles
Percentiles Aggregation 用于百分位统计。
百分位数是一个统计学术语,如果将一组数据从大到小排序,并计算相应的累计百分位,
某一百分位所对应数据的值就称为这一百分位的百分位数。
默认情况下,累计百分位为 [ 1, 5, 25, 50, 75, 95, 99 ]。
-----------------------------------------------------------------------------------------------------
以下例子给出了在 latency 索引中对 load_time 字段进行加载时间的百分位统计,查询语句如下:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time"
}
}
}
}
需要注意的是,如上的 load_time 字段必须是数字类型。
-----------------------------------------------------------------------------------------------------
聚合结果如下:
{
...
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
-----------------------------------------------------------------------------------------------------
百分位的统计也可以指定 percents 参数指定百分位,如下:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents": [60, 80, 95]
}
}
}
}
k.Percentiles Ranks
Percentiles Ranks Aggregation 与 Percentiles Aggregation 统计恰恰相反,
就是想看当前数值处在什么范围内(百分位), 假如你查一下当前值 500 和 600 所处的百分位,
发现是 90.01 和 100,那么说明有 90.01 % 的数值都在 500 以内,100 % 的数值在 600 以内。
-----------------------------------------------------------------------------------------------------
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600]
}
}
}
}
同样 load_time 字段必须是数字类型。
-----------------------------------------------------------------------------------------------------
返回结果大概类似如下:
{
...
"aggregations": {
"load_time_ranks": {
"values" : {
"500.0": 90.01,
"600.0": 100.0
}
}
}
}
可以设置 keyed 参数为 true,将对应的 values 作为桶 key 一起返回,默认是 false。
-----------------------------------------------------------------------------------------------------
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [500, 600],
"keyed": true
}
}
}
}
返回结果如下:
{
...
"aggregations": {
"load_time_ranks": {
"values": [
{
"key": 500.0,
"value": 90.01
},
{
"key": 600.0,
"value": 100.0
}
]
}
}
}
01.指标聚合
a.准备数据
PUT /test2/_doc/1
{
"name":"Jack",
"age":18,
"sex":"男",
"salary":6000,
"bithday":"1997-07-18",
"address":"美国纽约州",
"remark":"美国是世界上军事实力最强大的国家"
}
PUT /test2/_doc/2
{
"name":"李四",
"age":29,
"sex":"男",
"salary":12000,
"bithday":"1997-02-07",
"address":"中国广东省广州市",
"remark":"中国是世界上人口最多的国家"
}
PUT /test2/_doc/3
{
"name":"阿三",
"age":30,
"sex":"男",
"salary":3000,
"bithday":"1995-04-09",
"address":"印度新德里",
"remark":"印度的食品干净又卫生"
}
PUT /test2/_doc/4
{
"name":"王五",
"age":30,
"sex":"男",
"salary":16000,
"bithday":"1997-07-07",
"address":"中国北京市三里屯",
"remark":"中国的首都是北京市"
}
PUT /test2/_doc/5
{
"name":"老六",
"age":29,
"sex":"男",
"salary":15000,
"bithday":"1987-02-02",
"address":"中国上海市浦东新区",
"remark":"老六是中国某不知名小厂的程序员一枚"
}
PUT /test2/_doc/6
{
"name":"七七",
"age":20,
"sex":"女",
"salary":15000,
"bithday":"1999-11-17",
"address":"中国上海市浦东新区",
"remark":"七七是一个漂亮的Web前端程序猿"
}
b.avg示例:查询所有用户的平均年龄
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
},
"_source": [
"name",
"age"
]
}
-----------------------------------------------------------------------------------------------------
上例中,首先匹配查询所有的数据。在此基础上做查询平均值的操作,
这里就用到了聚合函数,其语法被封装在aggs中,而avg_age则是为查询结果起个别名,封装了计算出的平均值。
-----------------------------------------------------------------------------------------------------
如果只想看输出的值,而不关心输出的文档的话可以通过size=0来控制
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0,
"_source": [
"name",
"age"
]
}
c.avg示例:查询地址在中国用户的平均工资
GET /test2/_search
{
"query": {
"match_phrase": {
"address": "中国"
}
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
},
"size": 0
}
d.max示例:查询年龄的最大值
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
},
"size": 0
}
e.min示例:查询年龄的最小值
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_min": {
"min": {
"field": "age"
}
}
},
"size": 0
}
f.sum示例:查询符合条件的年龄之和
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_sum": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
g.示例:查询所有用户不同年龄的数量
POST /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"count_age": {
"cardinality": {
"field": "age"
}
}
},
"size": 0
}
h.示例:查出所有用户的年龄stats信息
POST /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
i.示例:查出所有用户的年龄extended_stats信息
POST /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"extended_stats_age": {
"extended_stats": {
"field": "age"
}
}
},
"size": 0
}
j.示例:查出所有用户的年龄占比
POST /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"pecent_age": {
"percentiles": {
"field": "age"
}
}
},
"size": 0
}
01.指标聚合
a.Max
统计最大值。例如查询价格最高的书:
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
-----------------------------------------------------------------------------------------------------
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price",
"missing": 1000
}
}
}
}
如果某个文档中缺少 price 字段,则设置该字段的值为 1000。
-----------------------------------------------------------------------------------------------------
也可以通过脚本来查询最大值
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
使用脚本时,可以先通过 doc['price'].size()!=0 去判断文档是否有对应的属性。
b.Min
统计最小值,用法和 Max Aggregation 基本一致:
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"field": "price",
"missing": 1000
}
}
}
}
-----------------------------------------------------------------------------------------------------
脚本:
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
c.Avg
统计平均值:
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
-----------------------------------------------------------------------------------------------------
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
d.Sum
求和:
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
-----------------------------------------------------------------------------------------------------
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
e.Cardinality
cardinality aggregation 用于基数统计。类似于 SQL 中的 distinct count(0):
text 类型是分析型类型,默认是不允许进行聚合操作的,如果相对 text 类型进行聚合操作,
需要设置其 fielddata 属性为 true,这种方式虽然可以使 text 类型进行聚合操作,
但是无法满足精准聚合,如果需要精准聚合,可以设置字段的子域为 keyword。
-----------------------------------------------------------------------------------------------------
方式一:
重新定义 books 索引:
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
-----------------------------------------------------------------------------------------------------
定义完成后,重新插入数据(参考之前的视频)。
接下来就可以查询出版社的总数量:
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}
-----------------------------------------------------------------------------------------------------
这种聚合方式可能会不准确。可以将 publish 设置为 keyword 类型或者设置子域为 keyword
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "keyword"
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
对比查询结果可知,使用 fileddata 的方式,查询结果不准确
f.Stats
基本统计,一次性返回 count、max、min、avg、sum:
GET books/_search
{
"aggs": {
"stats_query": {
"stats": {
"field": "price"
}
}
}
}
g.Extends
高级统计,比 stats 多出来:平方和、方差、标准差、平均值加减两个标准差的区间:
GET books/_search
{
"aggs": {
"es": {
"extended_stats": {
"field": "price"
}
}
}
}
h.Percentiles
百分位统计。
GET books/_search
{
"aggs": {
"p": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
10,
15,
25,
50,
75,
95,
99
]
}
}
}
}
i.Value Count
可以按照字段统计文档数量(包含指定字段的文档数量):
GET books/_search
{
"aggs": {
"count": {
"value_count": {
"field": "price"
}
}
}
}
02.分桶聚合
a.Terms Aggregation
Terms Aggregation 用于词项的分组聚合。
最为经典的用例是获取 X 中最频繁(top frequent)的项目,其中 X 是文档中的某个字段,
如用户的名称、标签或分类。由于 terms 聚集统计的是每个词条,而不是整个字段值,
因此通常需要在一个非分析型的字段上运行这种聚集。原因是, 你期望“big data”作为词组统计,
而不是“big”单独统计一次,“data”再单独统计一次。
-----------------------------------------------------------------------------------------------------
用户可以使用 terms 聚集,从分析型字段(如内容)中抽取最为频繁的词条。还可以使用这种信息来生成一个单词云。
{
"aggs": {
"profit_terms": {
"terms": { // terms 聚合 关键字
"field": "profit",
......
}
}
}
}
-----------------------------------------------------------------------------------------------------
在 terms 分桶的基础上,还可以对每个桶进行指标统计,也可以基于一些指标或字段值进行排序。示例如下:
{
"aggs": {
"item_terms": {
"terms": {
"field": "item_id",
"size": 1000,
"order":[{
"gmv_stat": "desc"
},{
"gmv_180d": "desc"
}]
},
"aggs": {
"gmv_stat": {
"sum": {
"field": "gmv"
}
},
"gmv_180d": {
"sum": {
"script": "doc['gmv_90d'].value*2"
}
}
}
}
}
}
返回的结果如下:
{
...
"aggregations": {
"hospital_id_agg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 260,
"buckets": [
{
"key": 23388,
"doc_count": 18,
"gmv_stat": {
"value": 176220
},
"gmv_180d": {
"value": 89732
}
},
{
"key": 96117,
"doc_count": 16,
"gmv_stat": {
"value": 129306
},
"gmv_180d": {
"value": 56988
}
},
...
]
}
}
}
默认情况下返回按文档计数从高到低的前 10 个分组,可以通过 size 参数指定返回的分组数。
b.Filter Aggregation
Filter Aggregation 是过滤器聚合,可以把符合过滤器中的条件的文档分到一个桶中,即是单分组聚合。
{
"aggs": {
"age_terms": {
"filter": {"match":{"gender":"F"}},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
c.Filters Aggregation
Filters Aggregation 是多过滤器聚合,可以把符合多个过滤条件的文档分到不同的桶中,
即每个分组关联一个过滤条件,并收集所有满足自身过滤条件的文档。
{
"size": 0,
"aggs": {
"messages": {
"filters": {
"filters": {
"errors": { "match": { "body": "error" } },
"warnings": { "match": { "body": "warning" } }
}
}
}
}
}
在这个例子里,我们分析日志信息。聚合会创建两个关于日志数据的分组,一个收集包含错误信息的文档,
另一个收集包含告警信息的文档。而且每个分组会按月份划分。
{
...
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
}
}
}
}
}
d.Range Aggregation
Range Aggregation 范围聚合是一个基于多组值来源的聚合,可以让用户定义一系列范围,
每个范围代表一个分组。在聚合执行的过程中,从每个文档提取出来的值都会检查每个分组的范围,
并且使相关的文档落入分组中。注意,范围聚合的每个范围内包含 from 值但是排除 to 值。
{
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [{
"to": 25
},
{
"from": 25,
"to": 35
},
{
"from": 35
}]
},
"aggs": {
"bmax": {
"max": {
"field": "balance"
}
}
}
}
}
}
}
返回结果如下:
{
...
"aggregations": {
"age_range": {
"buckets": [{
"key": "*-25.0",
"to": 25,
"doc_count": 225,
"bmax": {
"value": 49587
}
},
{
"key": "25.0-35.0",
"from": 25,
"to": 35,
"doc_count": 485,
"bmax": {
"value": 49795
}
},
{
"key": "35.0-*",
"from": 35,
"doc_count": 290,
"bmax": {
"value": 49989
}
}]
}
}
}
02.分桶聚合
a.准备数据
PUT /test2/_doc/1
{
"name":"Jack",
"age":18,
"sex":"男",
"salary":6000,
"bithday":"1997-07-18",
"address":"美国纽约州",
"remark":"美国是世界上军事实力最强大的国家"
}
PUT /test2/_doc/2
{
"name":"李四",
"age":29,
"sex":"男",
"salary":12000,
"bithday":"1997-02-07",
"address":"中国广东省广州市",
"remark":"中国是世界上人口最多的国家"
}
PUT /test2/_doc/3
{
"name":"阿三",
"age":30,
"sex":"男",
"salary":3000,
"bithday":"1995-04-09",
"address":"印度新德里",
"remark":"印度的食品干净又卫生"
}
PUT /test2/_doc/4
{
"name":"王五",
"age":30,
"sex":"男",
"salary":16000,
"bithday":"1997-07-07",
"address":"中国北京市三里屯",
"remark":"中国的首都是北京市"
}
PUT /test2/_doc/5
{
"name":"老六",
"age":29,
"sex":"男",
"salary":15000,
"bithday":"1987-02-02",
"address":"中国上海市浦东新区",
"remark":"老六是中国某不知名小厂的程序员一枚"
}
PUT /test2/_doc/6
{
"name":"七七",
"age":20,
"sex":"女",
"salary":15000,
"bithday":"1999-11-17",
"address":"中国上海市浦东新区",
"remark":"七七是一个漂亮的Web前端程序猿"
}
b.分桶group by示例:根据年龄聚合查询
GET /test2/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"terms": {
"field": "age"
}
}
}
}
c.分桶group by示例:根据年龄段聚合查询
GET /test2/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
}
}
}
}
d.分桶group by示例:根据用户出生日期的年月分组分段聚合查询
POST /test2/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"bithday_range": {
"date_range": {
"field": "bithday",
"format": "yyy-MM",
"ranges": [
{
"to": "1989-01"
},
{
"from": "1989-01",
"to": "1999-01"
},
{
"from": "1999-01",
"to": "2005-01"
},
{
"from": "2005-01"
}
]
}
}
}
}
e.分桶group by 进阶示例:按照年龄聚合,并且查询出这些年龄段的这些人的平均薪资
#其实就是aggs里面又加了一个aggs,第二个aggs根据第一个aggs聚合后的结果在聚合
GET /test2/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "salary"
}
}
}
}
},
"size": 0
}
f.分桶group by 进阶示例:查出所有年龄分布,并且这些年龄段中 性别为男 的平均薪资和 性别为女 的平均薪资以及这个年龄的用户信息
GET /test2/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"age_agg": {
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"sex_agg": {
"terms": {
"field": "sex.keyword",
"size": 10
},
"aggs": {
"salary_avg": {
"avg": {
"field": "salary"
}
}
}
},
"salary_avg": {
"avg": {
"field": "salary"
}
}
}
}
}
}
02.分桶聚合
a.Terms Aggregation 用于分组聚合,例如,统计各个出版社出版的图书总数量:
GET books/_search
{
"aggs": {
"NAME": {
"terms": {
"field": "publish",
"size": 20
}
}
}
}
在 terms 分桶的基础上,还可以对每个桶进行指标聚合。
-----------------------------------------------------------------------------------------------------
统计不同出版社所出版的图书的平均价格:
GET books/_search
{
"aggs": {
"NAME": {
"terms": {
"field": "publish",
"size": 20
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
b.Filter Aggregation
过滤器聚合。可以将符合过滤器中条件的文档分到一个桶中,然后可以求其平均值。
例如查询书名中包含 java 的图书的平均价格:
GET books/_search
{
"aggs": {
"NAME": {
"filter": {
"term": {
"name": "java"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
c.Filters Aggregation
多过滤器聚合。过滤条件可以有多个。
例如查询书名中包含 java 或者 office 的图书的平均价格:
GET books/_search
{
"aggs": {
"NAME": {
"filters": {
"filters": [
{
"term":{
"name":"java"
}
},{
"term":{
"name":"office"
}
}
]
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
d.Range Aggregation
按照范围聚合,在某一个范围内的文档数统计。
例如统计图书价格在 0-50、50-100、100-150、150以上的图书数量:
GET books/_search
{
"aggs": {
"NAME": {
"range": {
"field": "price",
"ranges": [
{
"to": 50
},{
"from": 50,
"to": 100
},{
"from": 100,
"to": 150
},{
"from": 150
}
]
}
}
}
}
e.Date Range Aggregation
Range Aggregation 也可以用来统计日期,但是也可以使用 Date Range Aggregation,后者的优势在于可以使用日期表达式。
造数据:
PUT blog/_doc/1
{
"title":"java",
"date":"2018-12-30"
}
PUT blog/_doc/2
{
"title":"java",
"date":"2020-12-30"
}
PUT blog/_doc/3
{
"title":"java",
"date":"2022-10-30"
}
-----------------------------------------------------------------------------------------------------
统计一年前到一年后的博客数量:
GET blog/_search
{
"aggs": {
"NAME": {
"date_range": {
"field": "date",
"ranges": [
{
"from": "now-12M/M",
"to": "now+1y/y"
}
]
}
}
}
}
-----------------------------------------------------------------------------------------------------
12M/M 表示 12 个月。
1y/y 表示 1年。
d 表示天
f.Date Histogram Aggregation
时间直方图聚合。
例如统计各个月份的博客数量
GET blog/_search
{
"aggs": {
"NAME": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
}
}
g.Missing Aggregation
空值聚合。
统计所有没有 price 字段的文档:
GET books/_search
{
"aggs": {
"NAME": {
"missing": {
"field": "price"
}
}
}
}
h.Children Aggregation
可以根据父子文档关系进行分桶。
查询子类型为 student 的文档数量:
GET stu_class/_search
{
"aggs": {
"NAME": {
"children": {
"type": "student"
}
}
}
}
i.Geo Distance Aggregation
对地理位置数据做统计。
例如查询(34.288991865037524,108.9404296875)坐标方圆 600KM 和 超过 600KM 的城市数量。
GET geo/_search
{
"aggs": {
"NAME": {
"geo_distance": {
"field": "location",
"origin": "34.288991865037524,108.9404296875",
"unit": "km",
"ranges": [
{
"to": 600
},{
"from": 600
}
]
}
}
}
}
j.IP Range Aggregation
IP 地址范围查询。
GET blog/_search
{
"aggs": {
"NAME": {
"ip_range": {
"field": "ip",
"ranges": [
{
"from": "127.0.0.5",
"to": "127.0.0.11"
}
]
}
}
}
}
03.管道聚合
a.Avg Bucket Aggregation
计算聚合平均值。例如,统计每个出版社所出版图书的平均值,然后再统计所有出版社的平均值:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"avg_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
b.Max Bucket Aggregation
统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"max_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
c.Min Bucket Aggregation
统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"min_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
d.Sum Bucket Aggregation
统计每个出版社所出版图书的平均值,然后再统计平均值之和:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"sum_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
e.Stats Bucket Aggregation
统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
f.Extended Stats Bucket Aggregation
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"extended_stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
g.Percentiles Bucket Aggregation
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"percentiles_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
04.矩阵聚合
a.概念
矩阵聚合(Matrix Aggregations)用于在多个数值字段之间进行复杂的数学分析,
特别适用于需要计算多维数据的统计关系的场景,比如协方差或相关性分析。
b.假设我们有一个包含多个字段的索引,比如price、quantity和discount,我们希望了解这些字段之间的统计关系
以下查询在 price、quantity 和 discount 字段之间计算协方差和相关性:
POST /sales/_search
{
"size": 0,
"aggs": {
"matrix_stats_example": {
"matrix_stats": {
"fields": ["price", "quantity", "discount"]
}
}
}
}
-----------------------------------------------------------------------------------------------------
请求路径:对索引sales执行搜索。
size:设为0,表示不需要返回文档,只关注聚合结果。
aggs:定义了一个名为matrix_stats_example的矩阵聚合。
matrix_stats:针对price、quantity和discount字段,计算它们之间的协方差、相关性、平均值、最小值、最大值和其他相关统计信息。
-----------------------------------------------------------------------------------------------------
Elasticsearch 将返回包含这些字段之间的协方差、相关性系数等矩阵统计信息,可以帮助分析字段之间的线性关系,判断它们的正相关或负相关程度。
5 ElasticSearch使用
5.1 汇总
01.介绍
a.ElasticSearch Vs 关系型数据库
a.对比
关系型数据库 ElasticSearch
数据库 索引(index) 倒排索引:词条、词条所在文档id、位置、...
表 类型(type) 废弃
表结构 映射(mapping)
行,一条数据 文档(document)
列,字段的值 字段(filed)
-------------------------------------------------------------------------------------------------
SQL DSL(Domain Specific Language)
Select * from xxx GET http://
update xxx set xx=xxx PUT http://
Delete xxx DELETE http://
索引 全文索引
b.说明
在ES中索引是有不同上下文含义的,它既可以是名词也可以是动词。
索引为名词是就是上文中提到的它是document的集合,索引为动词的时候表示将document数据保存到ES中,也就是数据写入。
在ES中,为了屏蔽语言的交互差异,ES直接对外的交互都是通过Rest API进行的。
b.分词器
a.ik_smart:为最少切分
描述:该分词器为智能分词器,适合快速分词,适用于搜索时对速度要求较高的场景。
特点:
使用较少的词典,分词效果较为简单。
能够对常见的词进行合理的分词,但可能会忽略一些细节。
b.ik_max_word:为最细粒度划分
描述:该分词器为最大词长分词器,适合对分词精度要求较高的场景。
特点:
会生成尽可能多的词条,提供更细粒度的分词结果。
能够捕捉到更多的短语和组合,但相对速度较慢。
c.默认standard
它基于 Unicode 文本分割标准,适用于多种语言。
-----------------------------------------------------------------------------------------------------
具体特点包括:
处理多语言:standard 分词器可以处理多种语言的文本,自动识别并处理词边界。
过滤:它会去除一些常见的标点符号和停用词(如“the”、“is”等)。
小写转换:分词器会将所有输入的文本转换为小写,从而进行大小写不敏感的搜索。
-----------------------------------------------------------------------------------------------------
使用示例
如果你在创建索引时不指定分析器,standard 分词器将被自动应用。以下是创建索引的示例:
PUT /my_index
{
"settings": {
"analysis": {
// 此处未指定分析器,将使用默认的 standard 分词器
}
}
}
02.组成
a.索引:表
创建索引库和映射
查询索引库
索引打开/关闭
复制索引
索引别名
修改索引库-字段
删除索引库
-----------------------------------------------------------------------------------------------------
修改索引库-副本数
修改索引库-切片数
修改索引库-读写权限
其他权限
b.映射:表结构
mapping组成
23个映射参数
动态映射
动态模板
静态映射
c.文档:行,一条数据
INSERT
QUERY
UPDATE
DELETE
Bulk
-----------------------------------------------------------------------------------------------------
文档路由
文档路由-指定routing
d.字段:列,字段的值
字符串类型:string、text、keyword、数字类型、long、integer、short、byte、double、float、half_float、scaled_float
日期类型
布尔类型
二进制类型
范围类型:integer_range、float_range、long_range、double_range、date_range、ip_range
复合类型
地理类型
特殊类型
03.使用1
a.全文查询:match
intervals:基于间隔查询,用于匹配特定词语或短语在指定位置间隔内出现的文档。
match:用于全文匹配,将查询字符串分词后,与字段的倒排索引进行匹配。
match_bool_prefix:类似于 match 查询,但支持前缀匹配,特别适用于补全查询。
match_phrase:用于匹配整个短语,要求短语中的词按顺序出现在文档中。
match_phrase_prefix:类似于 match_phrase 查询,但支持最后一个词的前缀匹配,适合处理未完整输入的短语。
multi_match:扩展的 match 查询,允许在多个字段上同时进行匹配。
combined_fields:将多个字段组合为一个字段进行匹配,以提高相关性计算。
common_terms:处理频繁出现的常用词,控制这些词的影响,以提升查询的效率和准确度。
query_string:允许使用查询字符串语法进行查询,支持布尔操作符、通配符等高级查询。
simple_query_string:类似于 query_string,但更简化,具有更严格的语法控制,适合用户直接输入。
b.词项查询:term
exists:用于检查某个字段是否存在于文档中。
fuzzy:执行模糊匹配查询,允许对词项进行少量的编辑操作(如插入、删除、替换或移动字符)以匹配近似的词。
ids:根据文档的 _id 字段进行查询,返回指定 ID 的文档。
prefix:用于前缀匹配,查询以指定前缀开头的词项。
range:用于范围查询,允许基于数字、日期或字符串字段指定上下限。
regexp:执行正则表达式查询,用于匹配符合正则表达式的词项。
term:精确匹配查询,用于查找字段中包含精确值的文档。
terms:类似于 term 查询,但允许指定多个精确值进行查询。
type:用于查询指定 _type 字段的文档(在 7.x 版本后逐渐被弃用)。
wildcard:通配符查询,允许使用 * 或 ? 通配符进行词项的模糊匹配。
c.复合查询:bool
bool:允许将多个查询条件组合在一起,通过 must、should、must_not 和 filter 条件控制查询逻辑。
boosting:用于执行加权查询,提升匹配特定条件的文档得分,同时降低其他条件下文档的得分。
constant_score:忽略查询的相关性评分,返回固定评分的结果,通常用于过滤查询。
dis_max:在多个查询之间选择得分最高的文档,适合组合多个子查询并返回最相关的结果。
function_score:允许通过定义评分函数来调整文档的相关性得分,用于复杂的得分计算。
indices:根据索引名称来执行不同的查询,当索引符合特定条件时,应用不同的查询逻辑(在新版本中逐渐被弃用)。
d.嵌套查询:nested
Elasticsearch 提供了以下两种形式的 join:
nested(嵌套查询):文档中可能包含嵌套类型的字段,这些字段用来索引一些数组对象,每个对象都可以作为一条独立的文档被查询出来。
has_child(有子查询):父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档能满足特定查询的父文档
has_parent(有父查询):父子关系可以存在单个的索引的两个类型的文档之间。has_parent 则返回其父文档能满足特定查询的子文档
e.位置查询:geo
geo_distance:用于计算两个地理位置(经纬度坐标)之间的距离。此查询可以用于基于距离的过滤,帮助用户找到特定半径内的文档。
geoboundingbox:表示一个矩形区域,由西南和东北两个角的经纬度坐标定义。使用此查询可以快速找到位于该矩形范围内的文档。
geo_polygon:用于定义一个多边形区域,该区域由一系列经纬度坐标构成。此查询可以用于查找位于多边形内部的文档,适用于更复杂的地理区域。
geo_shape:支持多种形状(如点、线、面等)的地理查询。使用此查询可以匹配复杂的地理形状,适合于对地理数据有更高需求的应用场景。
f.特殊查询:script
more_like_this:用于查找与给定文档相似的文档。该查询会分析输入文档的内容,提取关键词,并找到与这些关键词匹配的其他文档,从而提供相似性搜索的功能。
script:允许用户使用脚本来自定义查询逻辑。通过脚本,用户可以在查询、过滤或评分阶段执行自定义操作,从而实现更复杂的查询条件和行为。
percolate:用于在一组查询中查找与给定文档匹配的查询。该查询类型适用于监控、通知和事件检测等场景,用户可以预先定义多个查询,然后通过该机制检查新文档是否与任何预定义查询相匹配。
04.使用2
a.结果过滤:select a1, a2
GET /test1/_search
{
"query": {
"match_all": {}
},
"_source": [
"name",
"age"
]
}
b.范围查询:gt, lt
range 过滤允许我们按照指定范围查找一批数据,范围操作符包含:
gt:大于,相当于关系型数据库中的 >
gte:大于等于,相当于关系型数据库中的 >=
lt:小于,相当于关系型数据库中的 <
lte:小于等于,相当于关系型数据库中的 <=
c.布尔查询:must, filter
must:多个查询条件必须完全匹配,相当于关系型数据库中的 and。
should:至少有一个查询条件匹配,相当于关系型数据库中的 or。
must_not:多个查询条件的相反匹配,相当于关系型数据库中的 not。
filter:过滤满足条件的数据。
range:条件筛选范围。
gt:大于,相当于关系型数据库中的 >。
gte:大于等于,相当于关系型数据库中的 >=。
lt:小于,相当于关系型数据库中的 <。
lte:小于等于,相当于关系型数据库中的 <=。
d.限制查询:limit
POST /test2/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "张三 OR 七七"
}
},
"size": 100
}
e.排序查询:order desc
GET /test1/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
f.分页查询:from, size
GET /test1/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
g.高亮查询:highlighter
自定义高亮片段
多字段高亮
h.聚合查询:group by, sum
a.指标聚合
指标聚合:指标聚合对一个数据集求最大、最小、和、平均值等
单值分析,只输出一个分析结果——avg:求平均、max:最大值、min:最小值、sum:求和、cardinality:值去重计数。
多值分析,输出多个分析结果
stats:统计了count max min avg sum5个值
extended_stats:extended_stats比stats多很多更加高级的统计结果:如平方和、方差、标准差、平均值加/减两个标准差的区间等
percentile:占比百分位对应的值统计,默认返回【1,5,25,50,75,95,99】分位上的值
-------------------------------------------------------------------------------------------------
Max (最大值):计算指定字段的最大值,通常用于获取某个字段的最高值。
Min (最小值):计算指定字段的最小值,用于获取某个字段的最低值。
Avg (平均值):计算指定字段的平均值,通过汇总所有字段值并计算它们的平均值来提供数据的整体概况。
Sum (总和):计算指定字段的所有值的总和,常用于统计数据的累计值或总额。
Value Count (值计数):统计某个字段出现的次数,类似于计数,通常用于获取文档中非空字段的个数。
Cardinality (基数):计算某个字段中不同值的个数,用于获取该字段中的唯一值数量,常用于去重统计。
-------------------------------------------------------------------------------------------------
Stats (统计):提供一系列基础统计信息,包括最大值、最小值、平均值、总和以及文档计数,汇总了常用的统计信息。
Extended Stats (扩展统计):在基础统计的基础上,增加了标准差和方差等高级统计信息,用于更详细的数据分析。
Percentiles (百分位数):计算某个字段的多个百分位数,帮助了解数据分布情况,比如数据集中95%的值在什么范围内。
Percentile Ranks (百分位排名):计算某个值在数据集中所处的百分比位置,通常用于判断一个具体值相对于数据集的表现情况。
b.分桶聚合
分桶聚合:除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。
-------------------------------------------------------------------------------------------------
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,
分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,
即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
-------------------------------------------------------------------------------------------------
| 种类 | 描述/场景
|----------------------------------------------|----------------------------------------------------
| 词项聚合(Terms Aggregation) | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。
| 差异词项聚合(Significant Terms Aggregation) | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。
| 过滤器聚合(Filter Aggregation) | 指定过滤器匹配的所有文档到单个桶(bucket),通常这将用于将当前聚合上下文缩小到一组特定的文档。
| 多过滤器聚合(Filters Aggregation) | 指定多个过滤器匹配所有文档到多个桶(bucket)。
| 范围聚合(Range Aggregation) | 范围聚合,用于反映数据的分布情况。
| 日期范围聚合(Date Range Aggregation) | 专门用于日期类型的范围聚合。
| IP 范围聚合(IP Range Aggregation) | 用于对 IP 类型数据范围聚合。
| 直方图聚合(Histogram Aggregation) | 可能是数值,或者日期型,和范围聚集类似。
| 时间直方图聚合(Date Histogram Aggregation) | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。
c.管道聚合
管道聚合相当于在之前聚合的基础上,再次聚合。
Avg Bucket Aggregation:计算聚合平均值
Max Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值
Min Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值
Sum Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值之和
Stats Bucket Aggregation:统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据
Extended Stats Bucket Aggregation
Percentiles Bucket Aggregation
d.矩阵聚合
矩阵聚合(Matrix Aggregations)用于在多个数值字段之间进行复杂的数学分析,
特别适用于需要计算多维数据的统计关系的场景,比如协方差或相关性分析。
5.2 Java客户端:6类
00.介绍
a.RESTful
我们前面分享的 Es 基本操作都是 RESTful 风格的,也就是说,如果你掌握了 Es 基本操作,
即使不学习 Es 的 Java 客户端,利用一些常见的 Java 网络请求工具都可以去操作 Es 了,
例如 JDK 里边的 HttpUrlConnection,或者一些外部工具如 HttpClient、RestTemplate、OkHttp 等。
-----------------------------------------------------------------------------------------------------
以 HttpUrlConnection 为例,请求方式如下:
public class HttpRequestTest {
public static void main(String[] args) throws IOException {
URL url = new URL("http://localhost:9200/books/_search?pretty=true");
HttpURLConnection con = (HttpURLConnection) url.openConnection();
if (con.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
}
}
}
-----------------------------------------------------------------------------------------------------
前面视频跟大家分享的 Es 所有操作,都可以套用上面这段代码。
自己构造 Http 请求、构造请求参数、构造请求体等,然后手动发送请求,
再去手动解析请求结果(JSON 字符串解析而已)。只要掌握了基本操作,再去用 Java 操作 Es 就是 So Easy 了!
b.为什么还要去学习 Java API 呢?
学习 Java API 的意义在于,它帮我们将很多操作封装成了 API,不用自己再去手动拼 JSON 字符串了,
也不用手动解析字符串了,这是它的方便之处。如果不用 Java API 的话,请求参数 JSON、响应 JSON
都需要我们手动去拼接并解析,简单的 JSON 字符串还好,复杂的 JSON 字符串就很头大了。
01.目前 ElasticSearch 的 Java 客户端还是蛮多选择的
a.汇总
TransportClient
Jest
Spring Data Elasticsearch
Java Low Level REST Client
Java High Level REST Client
Elasticsearch Java API Client
b.TransportClient
大家在网上搜索 ElasticSearch 资料时,如果找到的是两年前的资料,应该会很容易看到 TransportClient。
不过从 ElasticSearch7.0 开始,官方已经不再推荐使用 TransportClient,
并且表示会在 ElasticSearch8.0 中完全移除相关支持。所以如果你是刚刚开始接触 ElasticSearch,
那么我觉得 TransportClient 目前可以放弃了。
c.Jest
Jest 提供了更流畅的 API 和更容易使用的接口,并且它的版本是遵循 ElasticSearch 的主版本号的,
这样可以确保客户端和服务端之间的兼容性。
早期的 ElasticSearch 官方客户端对 RESTful 支持不够完美, Jest 在一定程度上弥补了官方客户端的不足,
但是随着近两年官方客户端对 RESTful 功能的增强,Jest 早已成了明日黄花,
最近的一次更新也停留在 2018 年 4 月,所以 Jest 小伙伴们也不必花时间去学了,知道曾经有过这么一个东西就行了。
d.Spring Data Elasticsearch
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和关系数据存储。
其主要目标是使数据库的访问变得方便快捷。
-----------------------------------------------------------------------------------------------------
Spring Data 项目支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库)
ElasticSearch
Spring Data 项目所支持的关系数据存储技术:
JDBC
JPA
-----------------------------------------------------------------------------------------------------
Spring Data 其实是对一些既有的框架进行封装,从而使对数据的操作变得更加容易。
Spring Data Elasticsearch 其实也是如此,它底层封装的就是官方的客户端 Java High Level REST Client,
这个我们从它的依赖关系中就可以看出来:
老实说,Spring Data Elasticsearch 用起来还是蛮方便的,这个松哥后面会和大家分析。
-----------------------------------------------------------------------------------------------------
总结:
这里需要说一下,能使用RestHighLevelClient尽量使用它,
为什么不推荐使用 Spring 家族封装的 spring-data-elasticsearch。
主要原因是灵活性和更新速度,Spring 将 ElasticSearch 过度封装,
让开发者很难跟 ES 的 DSL 查询语句进行关联。再者就是更新速度,ES 的更新速度是非常快,
但是 spring-data-elasticsearch 更新速度比较缓慢。
并且spring-data-elasticsearch在Elasticsearch6.x和7.x版本上的Java API差距很大,
如果升级版本需要花点时间来了解。
TIPS:spring-data-elasticsearch的底层其实也是否则了elasticsearch-rest-high-level-client的api。
e.Java Low Level REST Client
从字面上来理解,这个叫做低级客户端。
它允许通过 Http 与一个 Elasticsearch 集群通信。
将请求的 JSON 参数拼接和响应的 JSON 字符串解析留给用户自己处理。
低级客户端最大的优势在于兼容所有的 ElasticSearch 的版本(因为它的 API 并没有封装 JSON 操作,
所有的 JSON 操作还是由开发者自己完成),同时低级客户端要求 JDK 为 1.7 及以上。
-----------------------------------------------------------------------------------------------------
低级客户端主要包括如下一些功能:
最小的依赖
跨所有可用节点的负载均衡
节点故障和特定响应代码时的故障转移
连接失败重试(是否重试失败的节点取决于它失败的连续次数;失败次数越多,客户端在再次尝试同一节点之前等待的时间越长)
持久连接
跟踪请求和响应的日志记录
可选自动发现集群节点
-----------------------------------------------------------------------------------------------------
Java Low Level REST Client 的操作其实比较简单,松哥后面会录制一个视频和大家分享相关操作。
f.Java High Level REST Client
从字面上来理解,这个叫做高级客户端,也是目前使用最多的一种客户端。它其实有点像之前的 TransportClient。
这个所谓的高级客户端它的内部其实还是基于低级客户端,只不过针对 ElasticSearch 它提供了更多的 API,将请求参数和响应参数都封装成了相应的 API,开发者只需要调用相关的方法就可以拼接参数或者解析响应结果。
Java High Level REST Client 中的每个 API 都可以同步或异步调用,同步方法返回一个响应对象,而异步方法的名称则以 Async 为后缀结尾,异步请求一般需要一个监听器参数,用来处理响应结果。
相对于低级客户端,高级客户端的兼容性就要差很多(因为 JSON 的拼接和解析它已经帮我们做好了)。高级客户端需要 JDK1.8 及以上版本并且依赖版本需要与 ElasticSearch 版本相同(主版本号需要一致,次版本号不必相同)。
-----------------------------------------------------------------------------------------------------
举个简单例子:7.0 客户端能够与任何 7.x ElasticSearch 节点进行通信,
而 7.1 客户端肯定能够与 7.1,7.2 和任何后来的 7.x 版本进行通信,
但与旧版本的 ElasticSearch 节点通信时可能会存在不兼容的问题。
g.Elasticsearch Java API Client
从 ElasticSearch7.17 这个版本开始,原先的 Java 高级客户端
Java High Level REST Client 废弃了,不支持了。
老实说,ElasticSearch 算是我用过的所有 Java 工具中,更新最为激进的一个了,
在 Es7 中废弃了 TransportClient,7.17 又废弃了 TransportClient,那么现在用啥呢?
现在的客户端叫做 Elasticsearch Java API Client。
5.3 对象映射工具:ModelMapper
00.总结
在 Java 中,可以使用一些工具类来实现 Java 对象和 Elasticsearch 对象之间的映射。
最常用的库是 MapStruct 和 ModelMapper
01.MapStruct
a.依赖
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>1.5.3.Final</version>
</dependency>
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.5.3.Final</version>
<scope>provided</scope>
</dependency>
b.对象
// Java对象
public class Product {
private String id;
private String name;
private double price;
// getters 和 setters
}
// Elasticsearch对象
public class ProductES {
private String id;
private String productName;
private double productPrice;
// getters 和 setters
}
e.映射接口
import org.mapstruct.Mapper;
import org.mapstruct.Mapping;
@Mapper
public interface ProductMapper {
@Mapping(source = "name", target = "productName")
@Mapping(source = "price", target = "productPrice")
ProductES toES(Product product);
@Mapping(source = "productName", target = "name")
@Mapping(source = "productPrice", target = "price")
Product toJava(ProductES productES);
}
d.使用 ProductMapper 进行对象转换
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
public ProductES convertToES(Product product) {
return productMapper.toES(product);
}
public Product convertToJava(ProductES productES) {
return productMapper.toJava(productES);
}
}
02.ModelMapper
a.依赖
<dependency>
<groupId>org.modelmapper</groupId>
<artifactId>modelmapper</artifactId>
<version>3.1.0</version>
</dependency>
b.对象
// Java对象
public class Product {
private String id;
private String name;
private double price;
// getters 和 setters
}
// Elasticsearch对象
public class ProductES {
private String id;
private String productName;
private double productPrice;
// getters 和 setters
}
c.ModelMapper
import org.modelmapper.ModelMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ProductService {
private final ModelMapper modelMapper;
@Autowired
public ProductService(ModelMapper modelMapper) {
this.modelMapper = modelMapper;
}
public ProductES convertToES(Product product) {
return modelMapper.map(product, ProductES.class);
}
public Product convertToJava(ProductES productES) {
return modelMapper.map(productES, Product.class);
}
}
d.配置 ModelMapper Bean
import org.modelmapper.ModelMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public ModelMapper modelMapper() {
return new ModelMapper();
}
}
5.4 Java High Level REST Client
01.依赖
a.ES依赖
<!--引入es-high-level-client的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
b.完整依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.thr.elasticsearch</groupId>
<artifactId>elasticsearch-rest-high-level-client-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>elasticsearch-rest-high-level-client-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.3.7.RELEASE</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入es-high-level-client的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.3.7.RELEASE</version>
<configuration>
<mainClass>com.thr.elasticsearch.ESRestHighLevelClientApplication</mainClass>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
02.项目配置
a.创建索引
PUT /goods
{
"mappings": {
"properties": {
"brandName": {
"type": "keyword"
},
"categoryName": {
"type": "keyword"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"id": {
"type": "keyword"
},
"price": {
"type": "double"
},
"saleNum": {
"type": "integer"
},
"status": {
"type": "integer"
},
"stock": {
"type": "integer"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
b.application.yml
elasticsearch:
host: 127.0.0.1
port: 9200
spring:
# 应用名称
application:
name: elasticsearch-spring-data
datasource:
username: root
password: 123456
url: jdbc:mysql://127.0.0.1/es?useSSL=false&serverTimezone=UTC&characterEncoding=utf8&allowMultiQueries=true
driver-class-name: com.mysql.cj.jdbc.Driver
elasticsearch:
rest:
# 定位ES的位置
uris: http://127.0.0.1:9200
mybatis:
type-aliases-package: com.thr.elastisearch.domain
mapper-locations: classpath:mapper/*.xml
c.java连接配置类
@Data
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
private String host;
private Integer port;
/**
* 如果@Bean没有指定bean的名称,那么这个bean的名称就是方法名
*/
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(
new HttpHost(host, port, "http")
)
);
}
}
d.mybatis配置
/**
* Mapper接口
*
* @author tanghaorong
*/
@Repository
@Mapper
public interface GoodsMapper {
/**
* 查询所有
*/
List<Goods> findAll();
}
-----------------------------------------------------------------------------------------------------
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.elasticsearch.dao.GoodsMapper">
<select id="findAll" resultType="com.thr.elasticsearch.domain.Goods">
select `id`,
`title`,
`price`,
`stock`,
`saleNum`,
`createTime`,
`categoryName`,
`brandName`,
`status`
from goods
</select>
</mapper>
e.实体对象
@Data
@Accessors(chain = true) // 链式赋值(连续set方法)
@AllArgsConstructor // 全参构造
@NoArgsConstructor // 无参构造
public class Goods {
/**
* 商品编号
*/
private Long id;
/**
* 商品标题
*/
private String title;
/**
* 商品价格
*/
private BigDecimal price;
/**
* 商品库存
*/
private Integer stock;
/**
* 商品销售数量
*/
private Integer saleNum;
/**
* 商品分类
*/
private String categoryName;
/**
* 商品品牌
*/
private String brandName;
/**
* 上下架状态
*/
private Integer status;
/**
* 商品创建时间
*/
@JSONField(format = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
}
f.测试类
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESRestHighLevelClientApplicationTests {
@Test
public void test1() throws IOException {
}
}
03.索引操作
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESRestHighLevelClientApplicationTests2 {
/**
* 创建索引库和映射表结构
* 注意:索引一般不会怎么创建
*/
@Test
public void indexCreate() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建索引
CreateIndexRequest indexRequest = new CreateIndexRequest("goods111");
// 创建表 结构
String mapping = "{\n" +
" \"properties\": {\n" +
" \"brandName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"categoryName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"createTime\": {\n" +
" \"type\": \"date\",\n" +
" \"format\": \"yyyy-MM-dd HH:mm:ss\"\n" +
" },\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"double\"\n" +
" },\n" +
" \"saleNum\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"status\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"stock\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"title\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"search_analyzer\": \"ik_smart\"\n" +
" }\n" +
" }\n" +
" }";
// 把映射信息添加到request请求里面
// 第一个参数:表示数据源
// 第二个参数:表示请求的数据类型
indexRequest.mapping(mapping, XContentType.JSON);
// 请求服务器
CreateIndexResponse response = indicesClient.create(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
/**
* 获取表结构
* GET goods/_mapping
*/
@Test
public void getMapping() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建get请求
GetIndexRequest request = new GetIndexRequest("goods");
// 发送get请求
GetIndexResponse response = indicesClient.get(request, RequestOptions.DEFAULT);
// 获取表结构
Map<String, MappingMetaData> mappings = response.getMappings();
for (String key : mappings.keySet()) {
System.out.println("key--" + mappings.get(key).getSourceAsMap());
}
}
/**
* 删除索引库
*/
@Test
public void indexDelete() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建delete请求方式
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("goods");
// 发送delete请求
AcknowledgedResponse response = indicesClient.delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
/**
* 判断索引库是否存在
*/
@Test
public void indexExists() throws Exception {
IndicesClient indicesClient = restHighLevelClient.indices();
// 创建get请求
GetIndexRequest request = new GetIndexRequest("goods");
// 判断索引库是否存在
boolean result = indicesClient.exists(request, RequestOptions.DEFAULT);
System.out.println(result);
}
}
04.文档操作
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class ESRestHighLevelClientApplicationTests3 {
/**
* 增加文档信息
*/
@Test
public void addDocument() throws IOException {
// 创建商品信息
Goods goods = new Goods();
goods.setId(1L);
goods.setTitle("Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机");
goods.setPrice(new BigDecimal("8799.00"));
goods.setStock(1000);
goods.setSaleNum(599);
goods.setCategoryName("手机");
goods.setBrandName("Apple");
goods.setStatus(0);
goods.setCreateTime(new Date());
// 将对象转为json
String data = JSON.toJSONString(goods);
// 创建索引请求对象
IndexRequest indexRequest = new IndexRequest("goods").id(goods.getId() + "").source(data, XContentType.JSON);
// 执行增加文档
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
}
/**
* 获取文档信息
*/
@Test
public void getDocument() throws IOException {
// 创建获取请求对象
GetRequest getRequest = new GetRequest("goods", "1");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
/**
* 更新文档信息
*/
@Test
public void updateDocument() throws IOException {
// 设置商品更新信息
Goods goods = new Goods();
goods.setTitle("Apple iPhone 13 Pro Max (A2644) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机");
goods.setPrice(new BigDecimal("9999"));
// 将对象转为json
String data = JSON.toJSONString(goods);
// 创建索引请求对象
UpdateRequest updateRequest = new UpdateRequest("goods", "1");
// 设置更新文档内容
updateRequest.doc(data, XContentType.JSON);
// 执行更新文档
UpdateResponse response = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("创建状态:{}", response.status());
}
/**
* 删除文档信息
*/
@Test
public void deleteDocument() throws IOException {
// 创建删除请求对象
DeleteRequest deleteRequest = new DeleteRequest("goods", "1");
// 执行删除文档
DeleteResponse response = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除状态:{}", response.status());
}
}
05.导入测试数据
https://files.cnblogs.com/files/tanghaorong/goods.zip?t=1654416464
---------------------------------------------------------------------------------------------------------
/**
* 批量导入测试数据
*/
@Test
public void importData() throws IOException {
//1.查询所有数据,mysql
List<Goods> goodsList = goodsMapper.findAll();
//2.bulk导入
BulkRequest bulkRequest = new BulkRequest();
//2.1 循环goodsList,创建IndexRequest添加数据
for (Goods goods : goodsList) {
//将goods对象转换为json字符串
String data = JSON.toJSONString(goods);//map --> {}
IndexRequest indexRequest = new IndexRequest("goods");
indexRequest.id(goods.getId() + "").source(data, XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
}
06.DSL高级查询操作
a.精确查询(term)
term查询:不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配,也就是精确查找,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型)
terms查询:terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去 做匹配:
-----------------------------------------------------------------------------------------------------
/**
* 精确查询(termQuery)
*/
@Test
public void termQuery() {
try {
// 构建查询条件(注意:termQuery 支持多种格式查询,如 boolean、int、double、string 等,这里使用的是 string 的查询)
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("title", "华为"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info("=======" + userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* terms:多个查询内容在一个字段中进行查询
*/
@Test
public void termsQuery() {
try {
// 构建查询条件(注意:termsQuery 支持多种格式查询,如 boolean、int、double、string 等,这里使用的是 string 的查询)
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termsQuery("title", "华为", "OPPO", "TCL"));
// 展示100条,默认只展示10条记录
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
b.全文查询(match)
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
term和match的区别是:match是经过analyer的,也就是说,文档首先被分析器给处理了。
根据不同的分析器,分析的结果也稍显不同,然后再根据分词结果进行匹配。term则不经过分词,
它是直接去倒排索引中查找了精确的值了。
-----------------------------------------------------------------------------------------------------
match 查询语法汇总:
match_all:查询全部。
match:返回所有匹配的分词。
match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配。其实默认是50.......
multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
-----------------------------------------------------------------------------------------------------
/**
* 匹配查询符合条件的所有数据,并设置分页
*/
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* 匹配查询数据
*/
@Test
public void matchQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "华为"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* 词语匹配查询
*/
@Test
public void matchPhraseQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("title", "三星"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* 内容在多字段中进行查询
*/
@Test
public void matchMultiQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("手机", "title", "categoryName"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
c.通配符查询(wildcard)
wildcard查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
-----------------------------------------------------------------------------------------------------
/**
* 查询所有以 “三” 结尾的商品信息
* <p>
* *:表示多个字符(0个或多个字符)
* ?:表示单个字符
*/
@Test
public void wildcardQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.wildcardQuery("title", "*三"));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
d.模糊查询(fuzzy)
/**
* 模糊查询所有以 “三” 结尾的商品信息
*/
@Test
public void fuzzyQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.fuzzyQuery("title", "三").fuzziness(Fuzziness.AUTO));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
e.排序查询(sort)
注意:需要分词的字段不可以直接排序,比如:text类型,如果想要对这类字段进行排序,
需要特别设置:对字段索引两次,一次索引分词(用于搜索)一次索引不分词(用于排序),
es默认生成的text类型字段就是通过这样的方法实现可排序的。
-----------------------------------------------------------------------------------------------------
/**
* 排序查询(sort) 代码同matchAllQuery
* 匹配查询符合条件的所有数据,并设置分页
*/
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
f.分页查询(page)
Elasticsearchde 的分页查询和 SQL 使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch 接受 from 和 size 参数:
size: 结果数,默认10
from: 跳过开始的结果数,即从哪一行开始获取数据,默认0
-----------------------------------------------------------------------------------------------------
/**
* 分页查询(page) 代码同matchAllQuery
* 匹配查询符合条件的所有数据,并设置分页
*/
@Test
public void matchAllQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 设置分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 设置排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
g.滚动查询(scroll)
滚动查询可以优化ES的深度分页,但是需要维护scrollId
-----------------------------------------------------------------------------------------------------
/**
* 根据查询条件滚动查询
* 可以用来解决深度分页查询问题
*/
@Test
public void scrollQuery() {
// 假设用户想获取第70页数据,其中每页10条
int pageNo = 70;
int pageSize = 10;
// 定义请求对象
SearchRequest searchRequest = new SearchRequest("goods");
// 构建查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
searchRequest.source(builder.query(QueryBuilders.matchAllQuery()).size(pageSize));
String scrollId = null;
// 3、发送请求到ES
SearchResponse scrollResponse = null;
// 设置游标id存活时间
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(2));
// 记录所有游标id
List<String> scrollIds = new ArrayList<>();
for (int i = 0; i < pageNo; i++) {
try {
// 首次检索
if (i == 0) {
//记录游标id
searchRequest.scroll(scroll);
// 首次查询需要指定索引名称和查询条件
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 下一次搜索要用到该游标id
scrollId = response.getScrollId();
// 记录所有游标id
}
// 非首次检索
else {
// 不需要在使用其他条件,也不需要指定索引名称,只需要使用执行游标id存活时间和上次游标id即可,毕竟信息都在上次游标id里面呢
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
scrollResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
// 下一次搜索要用到该游标id
scrollId = scrollResponse.getScrollId();
// 记录所有游标id
}
scrollIds.add(scrollId);
} catch (Exception e) {
e.printStackTrace();
}
}
//清除游标id
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.scrollIds(scrollIds);
try {
restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
System.out.println("清除滚动查询游标id失败");
e.printStackTrace();
}
// 4、处理响应结果
System.out.println("滚动查询返回数据:");
assert scrollResponse != null;
SearchHits hits = scrollResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
}
}
h.范围查询(range)
/**
* 查询价格大于等于10000的商品信息
*/
@Test
public void rangeQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.rangeQuery("price").gte(10000));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
log.info(hits.getTotalHits().value + "");
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* 查询距离现在 10 年间的商品信息
* [年(y)、月(M)、星期(w)、天(d)、小时(h)、分钟(m)、秒(s)]
* 例如:
* now-1h 查询一小时内范围
* now-1d 查询一天内时间范围
* now-1y 查询最近一年内的时间范围
*/
@Test
public void dateRangeQuery() {
try {
// 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// includeLower(是否包含下边界)、includeUpper(是否包含上边界)
searchSourceBuilder.query(QueryBuilders.rangeQuery("createTime")
.gte("now-10y").includeLower(true).includeUpper(true));
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods userInfo = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(userInfo.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
i.布尔查询(bool)
must:多个查询条件必须完全匹配,相当于关系型数据库中的 and。
should:至少有一个查询条件匹配,相当于关系型数据库中的 or。
must_not: 多个查询条件的相反匹配,相当于关系型数据库中的 not。
filter:过滤满足条件的数据。
range:条件筛选范围。
gt:大于,相当于关系型数据库中的 >。
gte:大于等于,相当于关系型数据库中的 >=。
lt:小于,相当于关系型数据库中的 <。
lte:小于等于,相当于关系型数据库中的 <=。
-----------------------------------------------------------------------------------------------------
/**
* boolQuery 查询
* 案例:查询从2018-2022年间标题含 三星 的商品信息
*/
@Test
public void boolQuery() {
try {
// 创建 Bool 查询构建器
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 构建查询条件
boolQueryBuilder.must(QueryBuilders.matchQuery("title", "三星"))
.filter().add(QueryBuilders.rangeQuery("createTime").format("yyyy").gte("2018").lte("2022"));
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
j.queryString查询
会对查询条件进行分词, 然后将分词后的查询条件和词条进行等值匹配,默认取并集(OR),可以指定单个字段也可多个查询字段
-----------------------------------------------------------------------------------------------------
/**
* queryStringQuery查询
* 案例:查询出必须包含 华为手机 词语的商品信息
*/
@Test
public void queryStringQuery() {
try {
// 创建 queryString 查询构建器
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("华为手机").defaultOperator(Operator.AND);
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryStringQueryBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
k.查询结果过滤
我们在查询数据的时候,返回的结果中,所有字段都给我们返回了,但是有时候我们并不需要那么多,所以可以对结果进行过滤处理。
-----------------------------------------------------------------------------------------------------
/**
* 过滤source获取部分字段内容
* 案例:只获取 title、categoryName和price的数据
*/
@Test
public void sourceFilter() {
try {
//查询条件(词条查询:对应ES query里的match)
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("title", "金立"))
.must(QueryBuilders.matchQuery("categoryName", "手机"))
.filter(QueryBuilders.rangeQuery("price").gt(1000).lt(2000));
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
// 如果查询的属性很少,那就使用includes,而excludes设置为空数组
// 如果排序的属性很少,那就使用excludes,而includes设置为空数组
String[] includes = {"title", "categoryName", "price"};
String[] excludes = {};
searchSourceBuilder.fetchSource(includes, excludes);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 输出查询信息
log.info(goods.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
l.高亮查询
/**
* 高亮查询
* 案例:把标题中为 三星手机 的词语高亮显示
*/
@Test
public void highlightBuilder() {
try {
//查询条件(词条查询:对应ES query里的match)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "三星手机");
//设置高亮三要素 field: 你的高亮字段 // preTags :前缀 // postTags:后缀
HighlightBuilder highlightBuilder = new HighlightBuilder().field("title").preTags("<font color='red'>").postTags("</font>");
// 构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.size(100);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status()) && searchResponse.getHits().getTotalHits().value > 0) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
Goods goods = JSON.parseObject(hit.getSourceAsString(), Goods.class);
// 获取高亮的数据
HighlightField highlightField = hit.getHighlightFields().get("title");
System.out.println("高亮名称:" + highlightField.getFragments()[0].string());
// 替换掉原来的数据
Text[] fragments = highlightField.getFragments();
if (fragments != null && fragments.length > 0) {
StringBuilder title = new StringBuilder();
for (Text fragment : fragments) {
//System.out.println(fragment);
title.append(fragment);
}
goods.setTitle(title.toString());
}
// 输出查询信息
log.info(goods.toString());
}
}
} catch (IOException e) {
log.error("", e);
}
}
m.指标聚合
/**
* 聚合查询
* Metric 指标聚合分析
* 案例:分别获取最贵的商品和获取最便宜的商品
*/
@Test
public void metricQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 获取最贵的商品
AggregationBuilder maxPrice = AggregationBuilders.max("maxPrice").field("price");
searchSourceBuilder.aggregation(maxPrice);
// 获取最便宜的商品
AggregationBuilder minPrice = AggregationBuilders.min("minPrice").field("price");
searchSourceBuilder.aggregation(minPrice);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedMax max = aggregations.get("maxPrice");
log.info("最贵的价格:" + max.getValue());
ParsedMin min = aggregations.get("minPrice");
log.info("最便宜的价格:" + min.getValue());
} catch (IOException e) {
log.error("", e);
}
}
/**
* 聚合查询
* Bucket 分桶聚合分析
* 案例:根据品牌进行聚合查询
*/
@Test
public void bucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询
TermsAggregationBuilder aggBrandName = AggregationBuilders.terms("brandNameName").field("brandName");
searchSourceBuilder.aggregation(aggBrandName);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
}
} catch (IOException e) {
log.error("", e);
}
}
n.分桶聚合
/**
* 聚合查询
* Bucket 分桶聚合分析
* 案例:根据品牌进行聚合查询
*/
@Test
public void bucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询
TermsAggregationBuilder aggBrandName = AggregationBuilders.terms("brandNameName").field("brandName");
searchSourceBuilder.aggregation(aggBrandName);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
}
} catch (IOException e) {
log.error("", e);
}
}
/**
* 子聚合聚合查询
* Bucket 分桶聚合分析
* 案例:根据商品分类进行分组查询,并且获取分类商品中的平均价格
*/
@Test
public void subBucketQuery() {
try {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 根据商品分类进行分组查询,并且获取分类商品中的平均价格
TermsAggregationBuilder subAggregation = AggregationBuilders.terms("brandNameName").field("brandName")
.subAggregation(AggregationBuilders.avg("avgPrice").field("price"));
searchSourceBuilder.aggregation(subAggregation);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms aggBrandName1 = aggregations.get("brandNameName");
for (Terms.Bucket bucket : aggBrandName1.getBuckets()) {
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("avgPrice");
System.out.println(bucket.getKeyAsString() + "====" + avgPrice.getValueAsString());
}
} catch (IOException e) {
log.error("", e);
}
}
o.综合聚合查询
/**
* 综合聚合查询
* 根据商品分类聚合,获取每个商品类的平均价格,并且在商品分类聚合之上子聚合每个品牌的平均价格
*/
@Test
public void subSubAgg() throws IOException {
// 构建查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchAllQueryBuilder);
// 注意这里聚合写的位置不要写错,很容易搞混,错一个括号就不对了
TermsAggregationBuilder subAggregation = AggregationBuilders.terms("categoryNameAgg").field("categoryName")
.subAggregation(AggregationBuilders.avg("categoryNameAvgPrice").field("price"))
.subAggregation(AggregationBuilders.terms("brandNameAgg").field("brandName")
.subAggregation(AggregationBuilders.avg("brandNameAvgPrice").field("price")));
searchSourceBuilder.aggregation(subAggregation);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest("goods");
searchRequest.source(searchSourceBuilder);
// 执行查询,然后处理响应结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//获取总记录数
System.out.println("totalHits = " + searchResponse.getHits().getTotalHits().value);
// 获取聚合信息
Aggregations aggregations = searchResponse.getAggregations();
ParsedStringTerms categoryNameAgg = aggregations.get("categoryNameAgg");
//获取值返回
for (Terms.Bucket bucket : categoryNameAgg.getBuckets()) {
// 获取聚合后的分类名称
String categoryName = bucket.getKeyAsString();
// 获取聚合命中的文档数量
long docCount = bucket.getDocCount();
// 获取聚合后的分类的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("categoryNameAvgPrice");
System.out.println(categoryName + "======平均价:" + avgPrice.getValue() + "======数量:" + docCount);
ParsedStringTerms brandNameAgg = bucket.getAggregations().get("brandNameAgg");
for (Terms.Bucket brandeNameAggBucket : brandNameAgg.getBuckets()) {
// 获取聚合后的品牌名称
String brandName = brandeNameAggBucket.getKeyAsString();
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg brandNameAvgPrice = brandeNameAggBucket.getAggregations().get("brandNameAvgPrice");
System.out.println(" " + brandName + "======" + brandNameAvgPrice.getValue());
}
}
}
5.5 Elasticsearch Java API Client
01.Elasticsearch Java API Client 示例
a.介绍
Elasticsearch Java API Client 是 Elasticsearch 的官方 Java API,
这个客户端为所有 Elasticsearch APIs 提供强类型的请求和响应。
-----------------------------------------------------------------------------------------------------
Elasticsearch Java API Client 具有如下特性:
1.为所有 Elasticsearch APIs 提供强类型的请求和响应。
2.所有 API 都有阻塞和异步版本。
3.使用构建器模式,在创建复杂的嵌套结构时,可以编写简洁而可读的代码。
4.通过使用对象映射器(如 Jackson 或任何实现了 JSON-B 的解析器),实现应用程序类的无缝集成。
5.将协议处理委托给一个 http 客户端,如 Java Low Level REST Client,它负责所有传输级的问题。HTTP 连接池、重试、节点发现等等由它去完成。
b.强类型的请求和响应
因为所有的 Elasticsearch APIs 本质上都是一个 RESTful 风格的 HTTP 请求,
所以当我们调用这些 Elasticsearch APIs 的时候,可以就当成普通的 HTTP 接口来对待,
例如使用 HttpUrlConnection 或者 RestTemplate 等工具来直接调用,如果使用这些工具直接调用,
就需要我们自己组装 JSON 参数,然后自己解析服务端返回的 JSON。
而强类型的请求和响应则是系统把请求参数封装成一个对象了,我们调用对象中的方法去设置就可以了,
不需要自己手动拼接 JSON 参数了,请求的结果系统也会封装成一个对象,不需要自己手动去解析 JSON 参数了。
c.查询 books 索引中,书名中包含 Java 关键字的图书
public class EsDemo02 {
public static void main(String[] args) throws IOException {
URL url = new URL("http://localhost:9200/books/_search?pretty");
HttpURLConnection con = (HttpURLConnection) url.openConnection();
con.setRequestMethod("GET");
con.setRequestProperty("content-type","application/json;charset=utf-8");
//允许输出流/允许参数
con.setDoOutput(true);
//获取输出流
OutputStream out = con.getOutputStream();
String params = "{\n" +
" \"query\": {\n" +
" \"term\": {\n" +
" \"name\": {\n" +
" \"value\": \"java\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
out.write(params.getBytes());
if (con.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
br.close();
}
}
}
d.说明
这就是一个普通的 HTTP 请求,请求参数就是查询的条件,这个条件是一个 JSON 字符串,需要我们自己组装,
请求的返回值也是一个 JSON 字符串,这个 JSON 字符串也需要我们自己手动去解析,这种可以算是弱类型的请求和响应。
02.代码
a.依赖
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.5.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
-----------------------------------------------------------------------------------------------------
如果是 Spring Boot 项目,就不用添加第二个依赖了,因为 Spring Boot 的 Web 中默认已经加了这个依赖了,
但是 Spring Boot 一般需要额外添加下面这个依赖,出现这个原因是由于从 JavaEE 过渡到 JakartaEE 时衍生
出来的一些问题,这里我就不啰嗦了,咱们直接加依赖即可:
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
b.建立连接
a.阻塞的Java客户端
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
-------------------------------------------------------------------------------------------------
这里一共有三个步骤:
首先创建一个低级客户端,这个其实松哥之前的视频中和大家讲过低级客户端的用法,这里就不再赘述。
接下来创建一个通信 Transport,并利用 JacksonJsonpMapper 做数据的解析。
最后创建一个阻塞的 Java 客户端。
-------------------------------------------------------------------------------------------------
利用阻塞的 Java 客户端操作 Es 的时候会发生阻塞,也就是必须等到 Es 给出响应之后,代码才会继续执行;
非阻塞的 Java 客户端则不会阻塞后面的代码执行,非阻塞的 Java 客户端一般通过回调函数处理请求的响应值。
b.非阻塞的Java客户端
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
ElasticsearchAsyncClient client = new ElasticsearchAsyncClient(transport);
-------------------------------------------------------------------------------------------------
只有第三步和前面的不一样,其他都一样。
-------------------------------------------------------------------------------------------------
利用阻塞的 Java 客户端操作 Es 的时候会发生阻塞,也就是必须等到 Es 给出响应之后,代码才会继续执行;
非阻塞的 Java 客户端则不会阻塞后面的代码执行,非阻塞的 Java 客户端一般通过回调函数处理请求的响应值。
c.和 Es 之间建立 HTTPS 连接,那么需要在前面代码的基础之上,再套上一层 SSL
String fingerprint = "<certificate fingerprint>";
SSLContext sslContext = TransportUtils.sslContextFromCaFingerprint(fingerprint);
BasicCredentialsProvider credsProv = new BasicCredentialsProvider();
credsProv.setCredentials(
AuthScope.ANY, new UsernamePasswordCredentials(login, password)
);
RestClient restClient = RestClient
.builder(new HttpHost(host, port, "https"))
.setHttpClientConfigCallback(hc -> hc
.setSSLContext(sslContext)
.setDefaultCredentialsProvider(credsProv)
)
.build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
c.创建索引
a.方式1
@Test
public void test99() throws IOException {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
CreateIndexResponse createIndexResponse = client.indices().create(
c ->
c.index("javaboy_books")
.settings(s ->
s.numberOfShards("3")
.numberOfReplicas("1"))
.mappings(m ->
m.properties("name", p -> p.text(f -> f.analyzer("ik_max_word")))
.properties("birthday", p -> p.date(d -> d.format("yyyy-MM-dd"))))
.aliases("books_alias", f -> f.isWriteIndex(true)));
System.out.println("createResponse.acknowledged() = " + createIndexResponse.acknowledged());
System.out.println("createResponse.index() = " + createIndexResponse.index());
System.out.println("createResponse.shardsAcknowledged() = " + createIndexResponse.shardsAcknowledged());
}
-------------------------------------------------------------------------------------------------
这里都是建造者模式和 Lambda 表达式,方法名称其实都很好理解(前提是你得熟悉 ElasticSearch 操作脚本),例如:
index 方法表示设置索引名称
settings 方法表示配置 setting 中的参数
numberOfShards 表示索引的分片数
numberOfReplicas 表示配置索引的副本数
mapping 表示配置索引中的映射规则
properties 表示配置索引中的具体字段
text 方法表示字段是 text 类型的
analyzer 表示配置字段的分词器
aliases 表示配置索引的别名
b.方式2
PUT javaboy_books
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"birthday":{
"type": "date",
"format": "yyyy-MM-dd"
}
}
},
"aliases": {
"xxxx":{
}
}
}
c.方式3
@Test
public void test98() throws IOException {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
StringReader json = new StringReader("{\n" +
" \"settings\": {\n" +
" \"number_of_replicas\": 1,\n" +
" \"number_of_shards\": 3\n" +
" },\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"birthday\":{\n" +
" \"type\": \"date\",\n" +
" \"format\": \"yyyy-MM-dd\"\n" +
" }\n" +
" }\n" +
" },\n" +
" \"aliases\": {\n" +
" \"xxxx\":{\n" +
" \n" +
" }\n" +
" }\n" +
"}");
CreateIndexResponse createIndexResponse = client.indices().create(
c ->
c.index("javaboy_books").withJson(json));
System.out.println("createResponse.acknowledged() = " + createIndexResponse.acknowledged());
System.out.println("createResponse.index() = " + createIndexResponse.index());
System.out.println("createResponse.shardsAcknowledged() = " + createIndexResponse.shardsAcknowledged());
}
d.删除索引
@Test
public void test06() throws IOException {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
//删除一个索引
DeleteIndexResponse delete = client.indices().delete(f ->
f.index("my-index")
);
System.out.println("delete.acknowledged() = " + delete.acknowledged());
}
e.文档操作
a.添加文档:给一个名为 books 的索引中添加一个 id 为 890 的书
@Test
public void test07() throws IOException {
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
Book book = new Book();
book.setId(890);
book.setName("深入理解Java虚拟机");
book.setAuthor("xxx");
//添加一个文档
//这是一个同步请求,请求会卡在这里
IndexResponse response = client.index(i -> i.index("books").document(book).id("890"));
System.out.println("response.result() = " + response.result());
System.out.println("response.id() = " + response.id());
System.out.println("response.seqNo() = " + response.seqNo());
System.out.println("response.index() = " + response.index());
System.out.println("response.shards() = " + response.shards());
}
b.删除文档:删除 books 索引中 id 为 891 的文档
@Test
public void test09() {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchAsyncClient client = new ElasticsearchAsyncClient(transport);
client.delete(d -> d.index("books").id("891")).whenComplete((resp, e) -> {
System.out.println("resp.result() = " + resp.result());
});
}
c.查询文档
@Test
public void test03() throws IOException {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
SearchResponse<Book> search = client.search(s -> {
s.index("books")
.query(q -> {
q.match(m -> {
m.field("name").query("美术计算机");
return m;
});
return q;
});
return s;
}, Book.class);
System.out.println("search.toString() = " + search.toString());
long took = search.took();
System.out.println("took = " + took);
boolean b = search.timedOut();
System.out.println("b = " + b);
ShardStatistics shards = search.shards();
System.out.println("shards = " + shards);
HitsMetadata<Book> hits = search.hits();
TotalHits total = hits.total();
System.out.println("total = " + total);
Double maxScore = hits.maxScore();
System.out.println("maxScore = " + maxScore);
List<Hit<Book>> list = hits.hits();
for (Hit<Book> bookHit : list) {
System.out.println("bookHit.source() = " + bookHit.source());
System.out.println("bookHit.score() = " + bookHit.score());
System.out.println("bookHit.index() = " + bookHit.index());
}
}
-------------------------------------------------------------------------------------------------
等价于
GET books/_search
{
"query": {
"match": {
"name": "美术计算机"
}
}
}
-------------------------------------------------------------------------------------------------
等价于
@Test
public void test04() throws IOException {
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
String key = "java";
StringReader sr = new StringReader("{\n" +
" \"query\": {\n" +
" \"term\": {\n" +
" \"name\": {\n" +
" \"value\": \"" + key + "\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}");
SearchRequest request = new SearchRequest.Builder()
.withJson(sr)
.build();
SearchResponse<Book> search = client.search(request, Book.class);
System.out.println("search.toString() = " + search.toString());
long took = search.took();
System.out.println("took = " + took);
boolean b = search.timedOut();
System.out.println("b = " + b);
ShardStatistics shards = search.shards();
System.out.println("shards = " + shards);
HitsMetadata<Book> hits = search.hits();
TotalHits total = hits.total();
System.out.println("total = " + total);
Double maxScore = hits.maxScore();
System.out.println("maxScore = " + maxScore);
List<Hit<Book>> list = hits.hits();
for (Hit<Book> bookHit : list) {
System.out.println("bookHit.source() = " + bookHit.source());
System.out.println("bookHit.score() = " + bookHit.score());
System.out.println("bookHit.index() = " + bookHit.index());
}
}
6 ElasticSearch场景
6.1 ELK实战
01.介绍
a.概念
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
-----------------------------------------------------------------------------------------------------
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;
是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。
它构建于Apache Lucene搜索引擎库之上。
b.elasticsearch
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
Elasticsearch:Elasticsearch是一个分布式、实时的搜索和分析引擎。它使用倒排索引来快速存储、搜索和分析大量的数据。
Elasticsearch提供了强大的全文搜索、复杂查询、聚合和地理空间搜索等功能。
c.Logstash
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,
包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,
这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,
它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
-----------------------------------------------------------------------------------------------------
Logstash是一个开源的数据收集和处理工具。它可以从不同的数据源收集数据,
并对数据进行过滤、转换和格式化,然后将数据发送到目标存储(如Elasticsearch)中。
-----------------------------------------------------------------------------------------------------
一般工作方式为c/s架构,client端安装在需要收集日志的主机上,
server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
d.Kibana
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。
它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
-----------------------------------------------------------------------------------------------------
Kibana是一个用于数据可视化和分析的开源工具。
它提供了一个用户友好的界面,可以实时地搜索、分析和可视化存储在Elasticsearch中的数据。
e.为什么用到ELK
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。
但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、
如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。
-----------------------------------------------------------------------------------------------------
常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,
大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,
构建一套集中式日志系统,可以提高定位问题的效率。
-----------------------------------------------------------------------------------------------------
一个完整的集中式日志系统,需要包含以下几个主要特点:
①收集-能够采集多种来源的日志数据
②传输-能够稳定的把日志数据传输到中央系统
③存储-如何存储日志数据
④分析-可以支持 UI 分析
⑤警告-能够提供错误报告,监控机制
-----------------------------------------------------------------------------------------------------
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。
目前主流的一种日志系统。
02.使用Java代码实现ELK的入门示例
a.第1步:安装和配置Elasticsearch
从Elasticsearch官方网站(https://www.elastic.co/downloads/elasticsearch)下载并安装最新版本的Elasticsearch。
启动Elasticsearch,并确保它正常运行在默认端口9200上。
b.第2步:安装和配置Logstash
从Logstash官方网站(https://www.elastic.co/downloads/logstash)下载并安装最新版本的Logstash。
创建一个名为logstash.conf的配置文件,用于定义数据源、过滤器和输出目标的配置。例如:
input {
file {
path => "/path/to/your/log/file.log"
start_position => "beginning"
}
}
filter {
# 添加过滤器配置,例如对日志进行解析、转换或过滤
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logs"
}
}
-----------------------------------------------------------------------------------------------------
启动Logstash并指定配置文件:bin/logstash -f logstash.conf
c.第3步:安装和配置Kibana
从Kibana官方网站(https://www.elastic.co/downloads/kibana)下载并安装最新版本的Kibana。
启动Kibana,并确保它正常运行在默认端口5601上。
在Kibana中创建索引模式,指定Elasticsearch中的索引名称和字段映射。
d.第4步:在Java应用程序中记录日志
在Java项目中使用日志框架(如Log4j、Slf4j等)记录日志。
配置日志输出到Logstash的IP和端口。
e.第5步:查看和分析日志数据
打开Kibana的Web界面(通常是http://localhost:5601)。
创建可视化图表和仪表板,用于展示和分析存储在Elasticsearch中的日志数据。
03.将SpringBoot日志实时输入到Es中
a.配置Logstash
在 config 目录下,添加 logstash-springboot.conf 文件,内容如下:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
filter {
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"]
index => "log-javaboy-dev-%{+yyyy.MM.dd}"
}
}
-----------------------------------------------------------------------------------------------------
在 config/pipelines.yml 文件中,加载 logstash-springboot.conf 配置文件
- pipeline.id: log_dev
path.config: "/Users/sang/workspace/elasticsearch/logstash-7.10.2/config/logstash-springboot.conf"
-----------------------------------------------------------------------------------------------------
启动 Logstash
进入到 bin 目录下,执行 ./logstash 命令启动即可(启动之前确保 Es 已经启动)。看到如下内容表示启动成功:
b.SpringBoot日志
a.依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.6</version>
</dependency>
b.然后在 resources 目录下创建 logback-spring.xml 文件,将日志输出到 logstash 中
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!--应用名称-->
<property name="APP_NAME" value="logstash"/>
<!--日志文件保存路径-->
<property name="LOG_FILE_PATH" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/logs}"/>
<contextName>${APP_NAME}</contextName>
<!--每天记录日志到文件appender-->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE_PATH}/${APP_NAME}-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>127.0.0.1:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
c.创建一个 HelloController 用来测试
@RestController
public class HelloController {
private static final Logger logger = LoggerFactory.getLogger(HelloController.class);
@GetMapping("/hello")
public void hello() {
logger.info("hello logstash!");
}
}
c.Kibana
在 Kibana 中,点击创建一个索引规则:log-javaboy-dev-*
然后点击下一步,选择 @timestamp。
最后,在 discover 中可以查看日志信息
6.2 ES与DB同步
00.介绍
a.概念
elasticsearch中的酒店数据来自于mysql数据库,
因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
b.三种方法
同步调用
异步通知
监听binlog
c.方式一:同步调用
概念:在将数据写到 MySQL 时,同时将数据写到 ES。
优点:实现简单,粗暴
缺点:业务耦合度高
d.方式二:异步通知【常用】
概念:针对多数据源写入的场景,可以借助 MQ 实现异步的多源写入
优点:低耦合,实现难度一般
缺点:依赖mq的可靠性
e.方式三:监听MySQL的binlog
优点:完全解除服务间耦合
缺点:开启binlog增加数据库负担、实现复杂度高
01.实现数据同步
a.介绍
当数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
单机部署并启动MQ(单机部署在MQ部分有讲)
接收者中声明exchange、queue、RoutingKey
在hotel-admin发送者中的增、删、改业务中完成消息发送
在hotel-demo接收者中完成消息监听,并更新elasticsearch中数据
启动并测试数据同步功能
b.对发送者和消费者都添加依赖和yaml信息
a.引入依赖
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
b.yaml
spring:
rabbitmq: #MQ配置
host: 192.168.194.131 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: itcast # 用户名
password: 123321 # 密码
c.声明交换机、队列
a.声明队列交换机名称
在hotel-admin发送者和hotel-demo消费者中的cn.itcast.hotel.constatnts包下新建一个类MqConstants
package cn.itcast.hotel.constatnts;
public class MqConstants {
/**
* 交换机
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 监听新增和修改的队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
b.声明队列交换机
在hotel-demo消费者中,定义配置类,声明队列、交换机:
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);
}
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
c.发送MQ消息
在hotel-admin发送者中的增、删、改业务中分别发送MQ消息
-----------------------------------------------------------------------------------------------------
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HoTEL_INSERT_KEY, hotel.getId());
}
-----------------------------------------------------------------------------------------------------
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());
}
-----------------------------------------------------------------------------------------------------
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id")Long id){
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_DELETE_KEY, id);
}
d.接收MQ消息
a.介绍
hotel-demo接收到MQ消息要做的事情包括:
新增消息:根据传递的hotel的id查询hotel信息,然后新增一条数据到索引库
删除消息:根据传递的hotel的id删除索引库中的一条数据
b.写SDL业务
首先在hotel-demo的cn.itcast.hotel.service包下的IHotelService中新增新增、删除业务
void deleteById(Long id);
void insertById(Long id);
-------------------------------------------------------------------------------------------------
给hotel-demo中的cn.itcast.hotel.service.impl包下的HotelService中实现业务:
@Override
public void deleteById(Long id) {
try {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", id.toString());
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void insertById(Long id) {
try {
// 0.根据id查询酒店数据
Hotel hotel = getById(id);
// 转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 2.准备Json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
c.编写监听器
在hotel-demo中的cn.itcast.hotel.mq包新增一个类:
package cn.itcast.hotel.mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 监听酒店新增或修改的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/**
* 监听酒店删除的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}
d.测试
用postman调用增加/删除/修改mysql数据库的接口,然后去页面搜索看看删除的数据还是否能查到,
或者修改/增加的数据能不能查出来