1 完全分布式
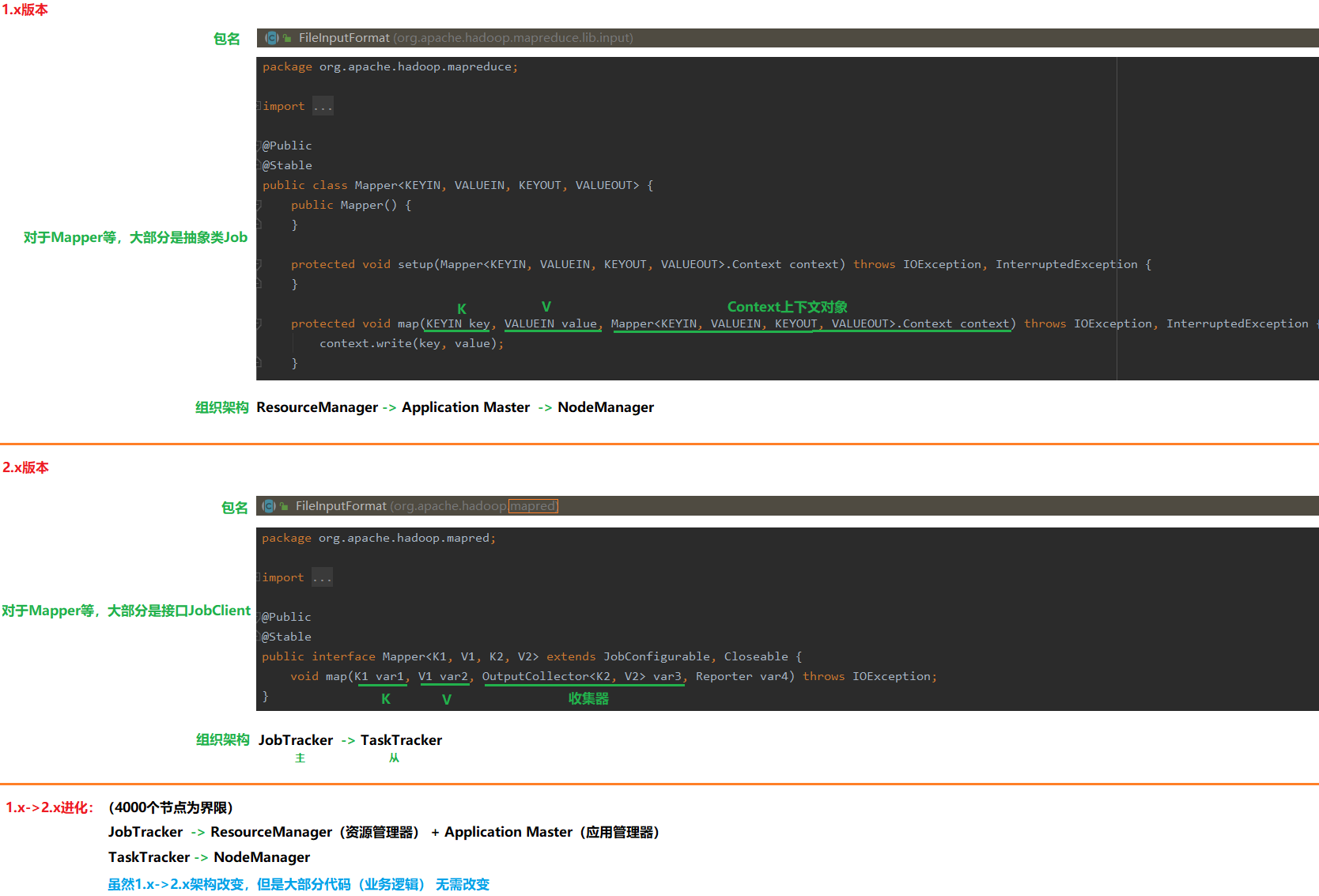
1.1 bigdata01
01.安装hadoop
a.上传、解压、重命名
cd /usr/local
tar -zxvf hadoop-2.9.2.tar.gz
mv hadoop-2.9.2 hadoop292
b.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
c.刷新环境变量
source /etc/profile
02.配置hadoop /usr/local/hadoop292/etc/hadoop,共7个
1.slaves:配置从节点
bigdata02
bigdata03
2.hadoop-env.sh:追加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
3.yarn-env.sh:追加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
4.core-site.xml
<configuration>
<!--hdfs -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop292/temp</value>
</property>
</configuration>
5.hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop292/temp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop292/temp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
6.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata01:19888</value>
</property>
</configuration>
7.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bigdata01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bigdata01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bigdata01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata01:8088</value>
</property>
</configuration>
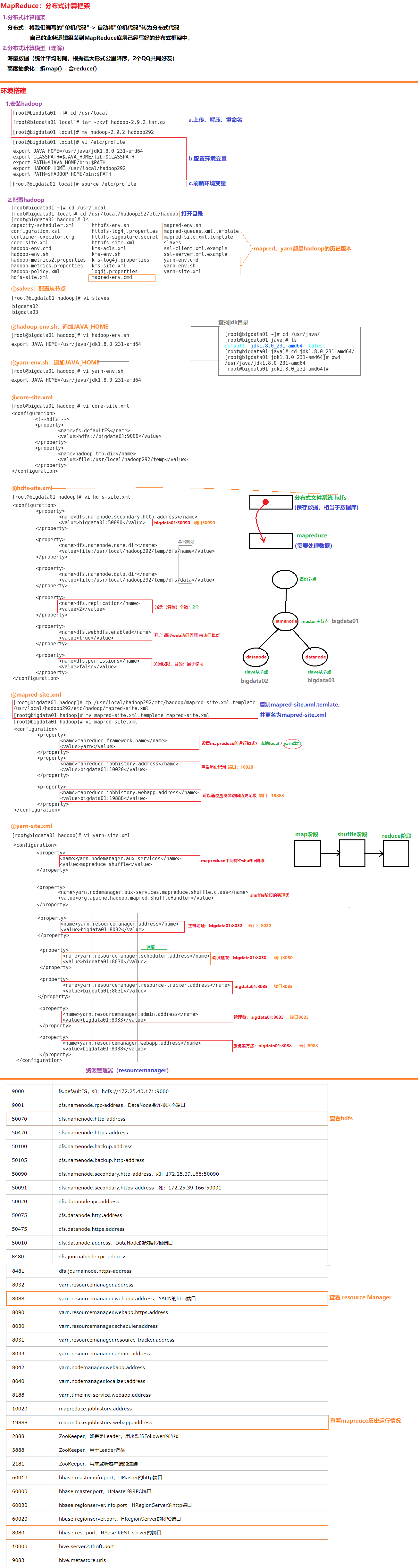
1.2 bigdata02/bigdata03
01.bigdata01
cd /usr/local
scp -r hadoop292/ root@bigdata02:/usr/local/
scp -r hadoop292/ root@bigdata03:/usr/local/
02.bigdata02
a.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
b.刷新环境变量
source /etc/profile
03.bigdata03
a.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop292
export PATH=$HADOOP_HOME/bin:$PATH
b.刷新环境变量
source /etc/profile
1.3 验证Hadoop
01.第一次使用,bigdata01格式化hdfs
a.打开目录
cd /usr/local/hadoop292
b.只格式化bigdata01
bin/hdfs namenode -format
c.重启
reboot
02.主节点启动hadoop
a.打开目录
cd /usr/local/hadoop292
b.启动hadoop
sbin/start-dfs.sh --启动Hdfs
sbin/start-yarn.sh --启动MapReduce
03.测试是否启动成功
a.jps
bigdata01:NameNode(hdfs主节点) 、 SecondaryNameNode(hdfs备份节点)
bigdata02:DataNode(hdfs从节点)
bigdata03:DataNode(hdfs从节点)
b.浏览器
http://192.168.2.128:50070/
c.通过命令查看状态
cd /usr/local/hadoop292
bin/hdfs dfsadmin -report
04.主节点关闭hadoop
a.打开目录
cd /usr/local/hadoop292
b.关闭hadoop
sbin/stop-dfs.sh --关闭Hdfs
sbin/stop-yarn.sh --关闭MapReduce
05.免密钥登陆
1.生成密钥
ssh-keygen -t rsa
2.发送私钥(本机)
ssh-copy-id localhost
3.发送公钥(其他计算机)
ssh-copy-id bigdata02
4.测试免密钥登陆
ssh bigdata02
06.防火墙
systemctl stop firewalld
systemctl disable firewalld
07.日志级别
export HADOOP_ROOT_LOGGER=DEBUG,console

1.4 验证MapReduce
01.MapReduce示例程序
a.打开MapReduce示例程序
/usr/local/hadoop292/share/hadoop/mapreduce
b.class字节码文件
hadoop-mapreduce-examples-2.9.2.jar中的WordCount.java程序
c.java文件
hadoop-mapreduce-examples-2.9.2-source.jar
02.上传文件
a.编写test1.txt
hello world
hello hadoop
b.编写test2.txt
hello china
03.运行WordCount.java程序
a.打开目录
cd /usr/local/hadoop292
b.用WordCount.java程序执行test1.txt、test2.txt文件
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /myinput/ /myoutput
c.查看执行后的结果
bin/hadoop fs -text /myoutput/part-r-00000
04.Hadoop的一些端口
a.hdfs
启动 sbin/start-dfs.sh
关闭 sbin/stop-dfs.sh
网站 http://192.168.2.128:50070
b.MapReduce
启动 sbin/start-yarn.sh
关闭 sbin/stop-yarn.sh
网站 http://192.168.2.128:8088
c.historyserver
启动 sbin/mr-jobhistory-daemon.sh start historyserver
网站 http://192.168.2.128:19888

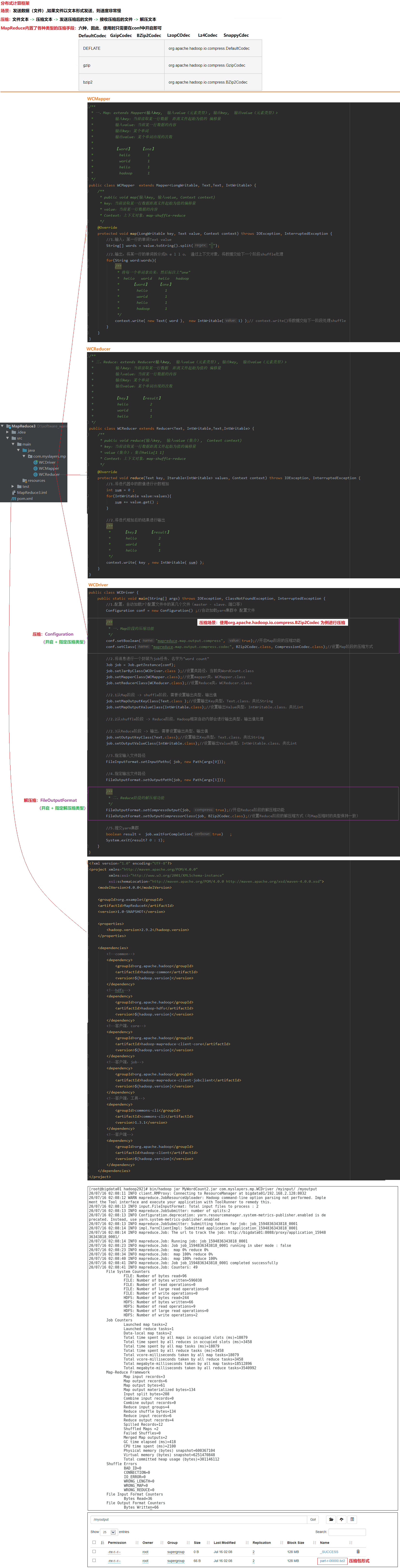
2 WordCount
2.1 WordCount自定义程序
00.自己编写的WordCount
a.仿照系统自带的WordCount.java进行编写
WCMapper、WCReducer、WCDriver
b.终端打包
mvn package
c.jar重命名
MyWordCount.jar
d.将jar放到虚拟机中的hadoop292目录
cd /usr/local/hadoop292
sbin/start-dfs.sh --启动Hdfs
sbin/start-yarn.sh --启动MapReduce
e.用jar包程序执行test1.txt、test2.txt文件
bin/hadoop jar MyWordCount.jar com.myslayers.mp.WCDriver /myinput/ /myoutput
f.查看执行后的结果
bin/hadoop fs -text /myoutput/part-r-00000

2.2 MapReduce内部流程
01.InputFormat
输入文件路径
02.OutputFormat
输出文件路径
03.MapOutputCollector
收集器
04.MapOutputBuffer
环形缓冲区,该类实现MapOutputBuffer,而且是MapTask的一个内部类
05.MRJobConfig
环形缓冲区的参数设置
String IO_SORT_MB = "mapreduce.task.io.sort.mb"; --默认100
String MAP_SORT_SPILL_PERCENT = "mapreduce.map.sort.spill.percent"; --默认80%
06.SpillRecord:溢出文件
a.同一个MapTask-x中,
a.快速排序(待排序的类,实现Comparable接口中的compareTo方法)
b.分区(将溢出文件中的数据,分成多个区;实现Partitioner中的getPartition方法,返回值就是区号)
分区号不能乱写:假设shuffle:设置2个区,reduce:设置1个区,则区号数不同,系统无法执行
默认使用HashPartitoner实现类,已经将reduce的数量和分区个数设置为一致
默认numReduceTasks的值为1,则默认分区个数为1
c.多个溢出文件合并(根据区号 ,第一次归并排序)
b.不同的MapTask-x中,
多个溢出文件合并(根据区号 ,第二次归并排序)
07.合成key:写出数组形式,默认将相同的A进行合并为一个数组
自定义合并规则:org.apache.hadoop.mapreduce.Job的setGroupingComparatorClass()方法
2.3 Combiner本地局部运算
00.汇总
Configuration:集群环境(集群大环境)
job:当前任务的环境(项目小环境)
01.Combiner
a.自定义combiner类:WCReducer extends Reducer<Text, IntWritable,Text,IntWritable>
b.告知MpReduce使用了自定义combiner类:job.setReducerClass(WCReducer.class)
02.Combiner本地运算(本地reduce,局部求和)的触发时机?
同一个MapTask-x中,多个溢出文件合并(根据区号 ,第一次归并排序),(从环形缓冲区中溢出文件时触发)
不同的MapTask-x中,多个溢出文件合并(根据区号 ,第二次归并排序),(不同合并多个溢出文件时触发)
03.测试程序
bin/hadoop jar MyWordCount2.jar com.myslayers.mp.WCDriver /myinput/ /myoutput
04.combiner本地求和(求和可以使用,但平均值可能出错)

2.4 压缩优化传输
01.MapReduce内置了各种类型的压缩手段:六种,因此,使用时只需要在conf中开启即可
个别可能需要额外操作:Lzo,必须先创建索引并指定输入格式
DefaultCodec
GzipCodec
BZip2Codec
LzopCOdec
Lz4Codec
SnappyCdec
02.压缩场景:使用org.apache.hadoop.io.compress.BZip2Codec为例进行压缩
压缩:Configuration(开启 + 指定压缩类型)
解压缩:FileOutputFormat(开启 + 指定解压缩类型)
03.测试程序
bin/hadoop jar MyWordCount3.jar com.myslayers.mp.WCDriver /myinput/ /myoutput
3 本地单机版
3.1 本地文件系统
01.常见的三种使用方式
a.完全分布式
IDEA编写代码 -> 打成jar包 -> yarn集群
b.单机版
极端情况不合适,只能保证本地OK,但yarn集群的实施环境中情况未知
c.远程
理论可以,但是不推荐,可能会存在插件升级、跨平台编译问题
本地windows -> 兼容插件(麻烦,存在升级问题)-> centos7集群(跨平台,存在跨平台编译问题)
本地centos7 -> centos7集群,则可以直接远程调试
02.单机版MapReduce,默认本地文件系统
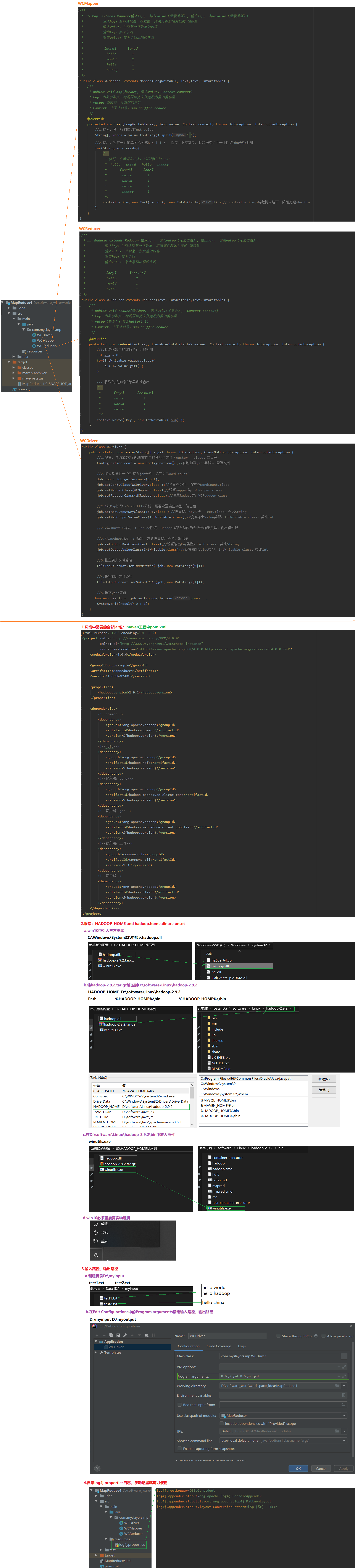
a.环境中需要的全部jar包
maven工程中pom.xml
b.报错:HADOOP_HOME and hadoop.home.dir are unset
a.win10中引入三方类库
C:\Windows\System32\中加入hadoop.dll
b.将hadoop-2.9.2.tar.gz解压到D:\software\Linux\hadoop-2.9.2
HADOOP_HOME D:\software\Linux\hadoop-2.9.2
Path %HADOOP_HOME%\bin %HADOOP_HOME%\sbin
c.在D:\software\Linux\hadoop-2.9.2\bin中放入插件
winutils.exe
d.win10必须重启真实物理机
重启
c.输入路径、输出路径
a.新建目录D:\myinput
test1.txt test2.txt
b.在Edit Configurations中的Program arguments指定输入路径、输出路径
D:\myinput D:\myoutput
d.自带log4j.properties日志,手动配置就可以使用
log4j.rootLogger=DEBUG, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
3.2 HDFS文件系统
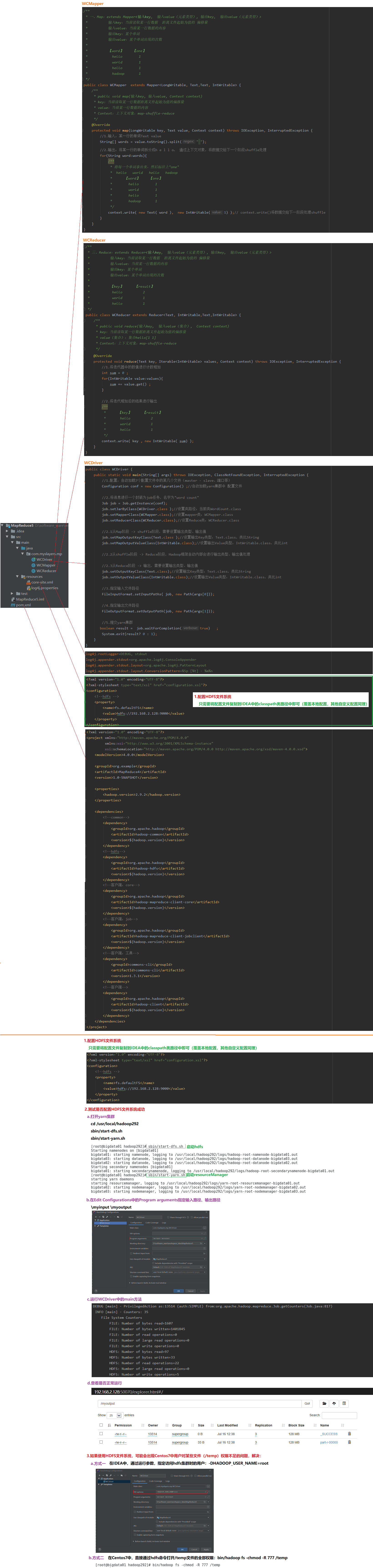
01.配置HDFS文件系统
只需要将配置文件复制到IDEA中的classpath类路径中即可(覆盖本地配置,其他自定义配置同理)
02.测试是否配置HDFS文件系统成功
a.打开yarn集群
cd /usr/local/hadoop292
sbin/start-dfs.sh
sbin/start-yarn.sh
b.在Edit Configurations中的Program arguments指定输入路径、输出路径
\myinput \myoutput
c.运行WCDriver中的main方法
启动
d.查看是否正常运行
http://192.168.2.128:50070/
03.如果使用HDFS文件系统,可能会出现Centos7中用户对某些文件(/temp)权限不足的问题,解决:
a.方式一
在IDEA中,通过运行参数,指定访问hdfs集群时的用户:-DHADOOP_USER_NAME=root
b.方式二
在Centos7中,直接通过hdfs命令打开/temp文件的全部权限:bin/hadoop fs -chmod -R 777 /temp
4 作业执行流程
4.1 角度一:组织架构2.x版
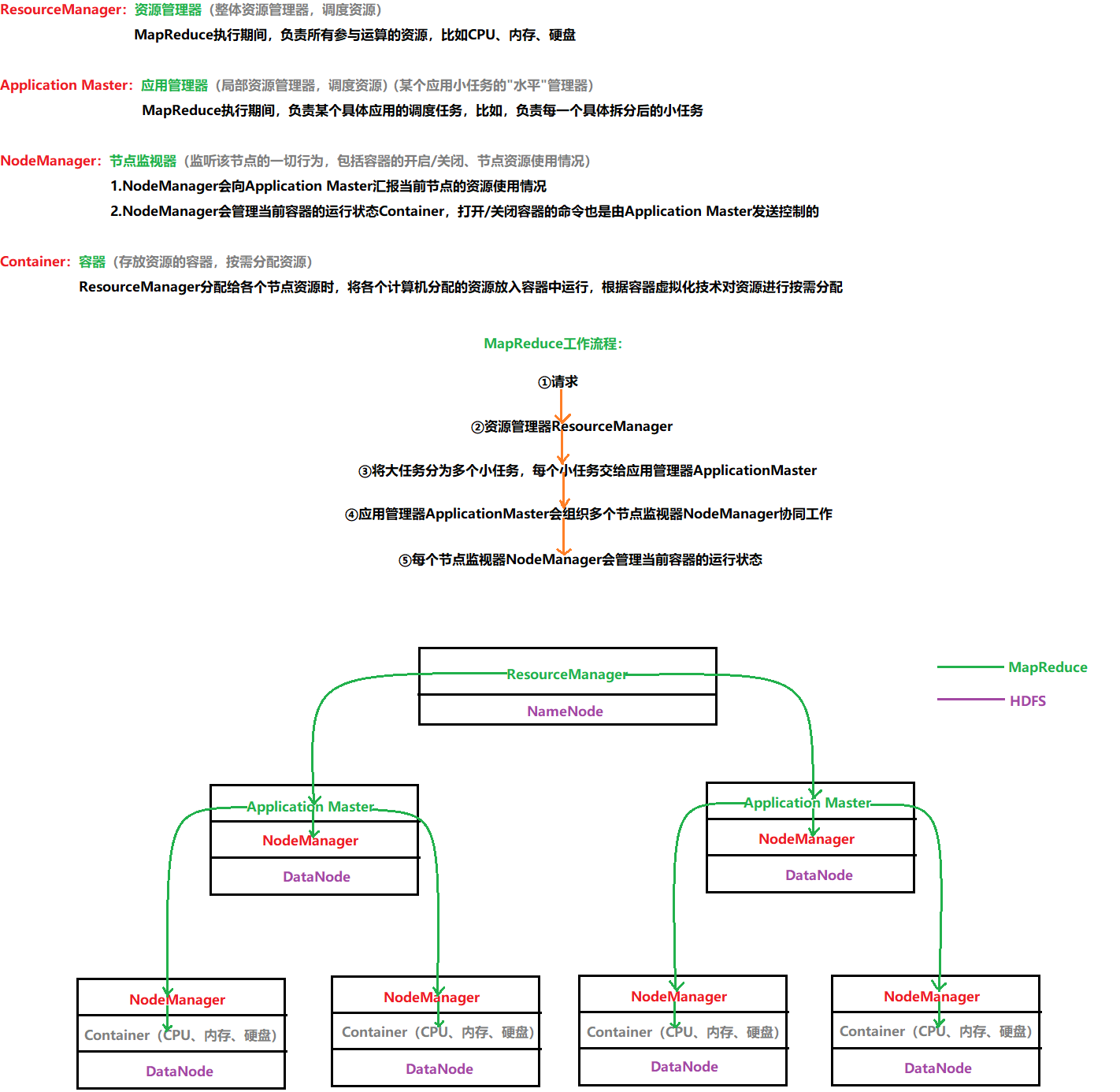
4.2 角度二:请求映射2.x版
01.clientProtocol接口实现类(YARNRunner/LocalJobRunner)
a.作用一
如果有配置文件,则返回一个YarmRunner对象
如果没有配置文件,则返回null
b.作用二
通过配置文件感知当前环境时Yarn(YARNRunner)还是Local(LocalJobRunner)
02.submitJobInternal():用于将任务"真正地提交"到Yarn/Local(MapReduce运行环境中)
a.确保输出路径不能存在,否则报异常,例如在执行以下命令时:/myoutput不能存在
this.checkSpecs(job)方法中调用一个接口方法checkOutputSpecs()
b.获取"暂存区"
JobSubmissionFiles.getStagingDir(cluster, conf)
file:/tmp/hadoop-YANQUN/mapred/staging/YANQUN1195299999/.staging
c.获取"jobid"
JobID jobId = this.submitClient.getNewJobID()
job_local1195299999_0001
d.给暂存区中设置一个名字为jobid的子文件夹
Path submitJobDir = new Path(jobStagingArea, jobId.toString())
e.将当前的job任务中 拷贝到 暂存区中 job(当前执行的MapReduce任务)
submitJobDir:当前任务在暂存区中的路径
this.copyAndConfigureFiles(job, submitJobDir);
f.将当前任务的切片信息放入暂存区中,共后续使用(第7步:AM从暂存区中获取job的相关切片信息)
this.writeSplits(job, submitJobDir);
g.切片的数量有限制
if (maxMaps >= 0 && maxMaps < maps) :
h.将配置文件(job.xml) 写入暂存区 (job.xml包含了job的相关配置信息 以及一些环境信息)
this.writeConf(conf, submitJobFile);
i.提交 ->YARN
submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
j.执行完毕之后,清空暂存区的数据
this.jtFs.delete(submitJobDir, true);

5 配置文件问题和版本问题
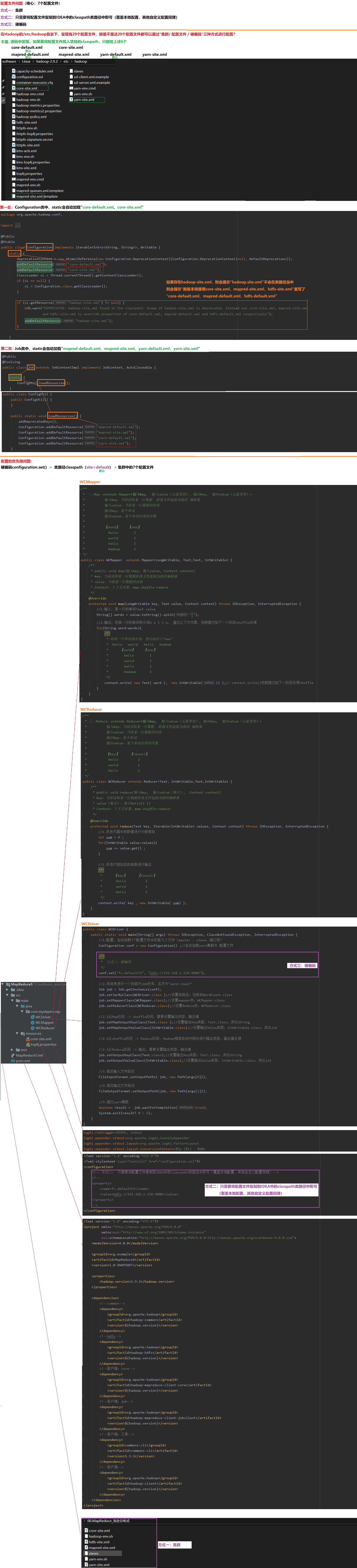
5.1 配置文件问题
01.配置文件问题(核心:7个配置文件)
a.方式一
集群
b.方式二
只需要将配置文件复制到IDEA中的classpath类路径中即可(覆盖本地配置,其他自定义配置同理)
c.方式三
硬编码
02.源码中发现,如果要将配置文件放入项目的classpath,只能放6个配置文件
core-default.xml
core-site.xml
mapred-default.xml
mapred-site.xml
yarn-default.xml
yarn-site.xml
03.优先级问题
硬编码configuration.set() > 类路径classpath(site>default) > 集群中的7个配置文件
5.2 版本问题